 |


■後藤弘茂のWeekly海外ニュース■明瞭になった「Core Microarchitecture」の全貌 |
●Pentium M時と大きく異なるCore Microarchitectureの技術公開
Intelは、米サンフランシスコで開催された技術カンファレンス「Intel Developer Forum(IDF)」で、次世代CPUマイクロアーキテクチャ「Core Microarchitecture(コアマイクロアーキテクチャ)」の概要を明らかにした。IDFの1日目(3月7日)は、大まかな姿が明かされただけだったが、2日目と3日目の技術セッションでは、ある程度突っ込んだ情報が公開された。ほとんど技術概要を明らかにしなかった、前回のPentium M(Banias)アーキテクチャの時とは、かなり姿勢に違いがある。
新たに明確になった情報をベースに、まずパイプラインの概要をまとめてみたい。あわせて、これまでのレポートにあった間違いを訂正したい。
下は、Core Microarchitectureの“最終的に確認された”ブロックダイアグラムだ。IDF中には、これとは異なるダイアグラムが示されたが、この構成が正確なものだという。フロムスクラッチ(ゼロから)で開発されたCore Microarchitectureは、従来の「NetBurst(Pentium 4)」や「Banias(Pentium M)」のどちらとも異なる構成を取る。しかし、ベースラインはBanias系の流れを継承している。
 |
| Core Architecture Block Diagram PDF版はこちら |
パイプラインの最初にあるのは、「インストラクション(命令)フェッチ(Instruction Fetch)」と「プリデコード(PreDecode)」。x86命令のフェッチ(取り込み)を行なう命令フェッチャには、1ユニットの命令プリフェッチャ(Instruction Prefetcher)が付属する。プリデコードでは、可変長のx86命令の区切りを明確にし、また命令タイプを判別する。後述するMacro-Fusionが可能かどうかも、このステージで検出する。
フェッチャ/プリデコーダからは、最大6命令/サイクルで「インストラクションキュー(Instruction Queue)」にx86命令が送られる。キューに待機した命令は、最大5命令/サイクルで「命令デコーダ(Decoder)」に読み込まれる。
Pentium III/Banias/Yonah系では、デコーダは2個のシンプルデコーダと、1個のコンプレックスデコーダで構成されている。NetBurst系はL1命令キャッシュであるトレースキャッシュの前に、大型のデコーダを備える。それに対して、Core Microarchitectureでは、4個のデコーダを備え、そのうちの1個がコンプレックスデコーダとなっている。
下はデコーダ回りの図だ。Intelは、デコーダの概要のチャートは示していない。しかし、この図については、アーキテクトの1人Bob Valentine氏(Architect, Intel Architecture Group)氏に直接見せて、同氏の指摘を入れて修正、確認を取っているため、間違いはないと思われる。
 |
| Core Architecture Decoder PDF版はこちら |
●4個のデコーダはいずれもフュージョンが可能
デコーダについては、後のレポートでもう少し詳しく説明するが、1個のデコーダだけが最大4個のuOPsを生成可能で、このデコーダがマイクロコードシーケンサとも接続されている。残り3個のデコーダも、後述する融合uOPs「Fused uOPs」を生成できるため、従来的な意味のシンプルデコーダとは異なるという。
Core Microarchitectureのデコーダは、「Macro-Fusion(またはMacro-OPs Fusion)」と「Micro-OPs Fusion」の2つのフュージョンテクニックを実装する。x86系のout-of-order(命令順序を並べ替えて実行する)型CPUアーキテクチャでは、通常、x86命令をRISC風の内部命令「Micro-OPs(uOPs)」に変換する。Micro-OPs Fusionは、通常2個のuOPsを1個の融合uOP「Fused uOP」に融合させる。
もう1つのMacro-Fusionでは、複数のx86命令(Macro-OPs)を1個のFused uOPに融合させる。最初のCore Microarchitectureの実装では、x86命令のうち比較命令であるcmpまたはtestと、条件分岐命令(jcc)の組み合わせだけを融合させる。これにより、多くのプログラムで、最大15%のuOPsの削減が可能になるという。
デコーダは、Micro-OPs FusionとMacro-Fusionの両方を組み合わせることが可能だ。例えば、レジスタとメモリ上の値を比較して、その結果でジャンプするケースでは、これまでのアーキテクチャ(NetBurstなど)では、通常3個のuOPsが生成されていた。メモリからレジスタへの「ロードuOP」、2つのレジスタ値を比較する「比較uOP」、結果によってジャンプを行なう「条件分岐uOP」の3個だ。Core Microarchitectureでは、Micro-OPs FusionとMacro-Fusionによって、3個のuOPsを1個のFused uOPにまとめることができる。前の記事では、Macro-Fusionをできる組み合わせは1組/サイクルだろうという推測を書いたが、これは間違いで、最大2組/サイクルまでのMacro-Fusionが可能だ。
●スケジューラで分離して発行されるFused uOPs
デコーダからは、最大4uOPs/サイクルの帯域で命令が下段のパイプに送られる。リネーム(Rename)とアロケート(Allocate)でリソースの割り当てが行なわれた後は、uOPsはout-of-order部のスケジューラに送られる。スケジューラではuOPsを実行できる順番から実行ユニットに発行する。x86系CPUの場合、整数演算パイプと浮動小数点演算パイプでスケジューラが分離されていることが多いが、Core Microarchitectureでは統合されたスケジューラを持つ。
スケジューラが読み込むuOPsは最大4uOPs/サイクルであるにもかかわらず、演算ユニットアレイに発行されるuOPs数は4uOPs/サイクルより多くなる。Fused uOPsが実行時に事実上分解されるからだ。1個のFused uOP中の複数のファンクションは、それぞれ異なるタイミングで実行ユニットに発行される。例えば、レイテンシの長いロードは先にロードユニットに発行され、レジスタにデータがロードされたのを検知した後で、演算系命令が発行される。Macro-Fusionで融合された比較uOPと条件分岐uOPに関しては同じ実行ユニットに1サイクルで発行される。
Valentine氏によると、実行ユニット群のうち、Macro-Fusionで融合されたFused uOPを実行できるのは、図中の一番左側の1個のみ。これは、左端の実行ユニットだけが分岐ユニットを備えるためだ。
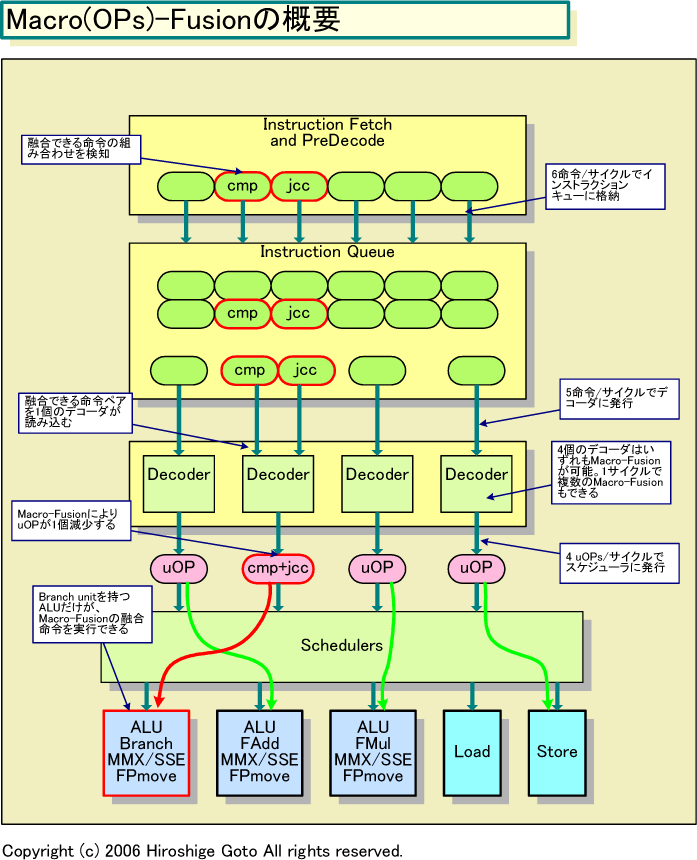 |
| Macro(OPs)-Fusionの概要 PDF版はこちら |
実行ユニットの構成は5組。演算系ユニット群が3、ロードとストアがそれぞれ1個ずつ。前に書いた通り、SIMD(Single Instruction, Multiple Data)系の浮動小数点演算は2個の実行ユニットで可能だ。左から2個目のユニットで128bit SIMDの加算、中央のユニットで128bit SIMDの乗算ができる。どちらも、1サイクルスループットで、単精度(32bit)の浮動小数点データ4個に対して、加算と乗算を並列に行なうことが可能だ。最大で8オペレーションが並列できる。
プレレポートでCore Microarchitectureでは、SIMDの積和算が可能と書いたが、これは間違いだ。実は、Core Microarchitectureについては、以前から積和算が可能になるという噂があり、クエスチョンつきながらも、乗算uOPと加算uOPを融合させることができる可能性があると言われていた。最初にIntelがIDFのセッションで示したCore Microarchitectureのブロック図では、浮動小数点演算ユニットが1個に描かれており、それを示唆していた。明瞭には書かなかったが、1ユニットで、8個の浮動小数点演算オペレーションが1サイクルスループットで可能になるとしたら、SIMD積和演算を実行できると推測することになる。しかし、正確なCore Microarchitectureの構成が明らかになったことで、これは間違いであることが明確になった。最初のMacro-Fusionの実装では、比較プラスジャンプのみ可能だ。
●投機ロードを可能にする予測機構を搭載
データロードでは、ハードウェアベースのデータプリフェッチが可能だ。Core Microarchitectureでは、2ユニットのデータプリフェッチャ(Data Prefetcher)を備える。また、この他、L2キャッシュのコントローラにも共有のプリフェッチャが2ユニット実装されている。各CPUコアが、それぞれ1ユニットの命令プリフェッチャと2ユニットのデータプリフェッチャを備え、L2に2ユニットのプリフェッチャがあり、トータルで8個のプリフェッチャがデュアルコアの中に存在する。
また、Core Microarchitectureは、メモリ上のデータ依存関係の曖昧さ(ambiguity)を解決する「Memory Disambiguation(メモリディスアンビギュエイション)」を実装する。そのため、ロード命令をストア命令よりも前に投機的に実行することができる。Core Microarchitectureでは、これは完全にハードウェアベースで行なう。そのため、Memory Disambiguationの予測ユニット「Memory Disambiguation Predictor」が実装されている。
Memory Disambiguationでは、条件分岐命令に対する分岐予測と同じように、ロード命令に対して真のデータ依存が発生するかどうかを予測。データ依存が発生しないと予測されたロード命令は、スケジューラによって可能な限り前に実行される。投機的に実行されたロードは、リタイヤメント時にチェックされ(つまり、チェックが終わるまではリタイヤされない)、予測が外れた場合は、再びロード命令が実行される。Core Microarchitectureでは、Memory Disambiguationの結果をモニタし、自動的に機能をON/OFFする。予測ミスが続いた場合には、一定時間OFFにすることでロスを抑える。
アウトオーダ部からのuOPsのリタイヤメントは、4uOPs/サイクル。リタイヤしたuOPsはリオーダされインオーダとなる。つまり、Core Microarchitectureは、5命令デコードでフロントエンド部は4uOPs/サイクルの帯域、out-of-order部へは4uOPs/サイクルの帯域でuOPsのスケジュール&リタイヤができるマシンということになる。
□IDF Spring 2006のホームページ(英文)
http://www.intel.com/idf/us/spring2006/
□IDF Spring 2006レポートリンク集
http://pc.watch.impress.co.jp/docs/2006/link/idfs.htm
□関連記事
【3月9日】【海外】Intelの次世代CPUアーキテクチャ「Core Microarchitecture」
http://pc.watch.impress.co.jp/docs/2006/0309/kaigai248.htm
【3月7日】【IDF】次世代CPU「Conroe」の内部構成が明らかに
http://pc.watch.impress.co.jp/docs/2006/0307/idf01.htm
【3月6日】【海外】IDFでいよいよ公開「Meromアーキテクチャ」
http://pc.watch.impress.co.jp/docs/2006/0306/kaigai247.htm
(2006年3月11日)
[Reported by 後藤 弘茂(Hiroshige Goto)]
【PC Watchホームページ】
PC Watch編集部 pc-watch-info@impress.co.jp ご質問に対して、個別にご回答はいたしません
Copyright (c) 2006 Impress Watch Corporation, an Impress Group company. All rights reserved.