 |


■後藤弘茂のWeekly海外ニュース■Intelの次世代CPUアーキテクチャ
|
●セッションによって異なるダイアグラム図
Intelが、次世代CPUのマイクロアーキテクチャ「Core Microarchitecture」の概要を公式に明かした。
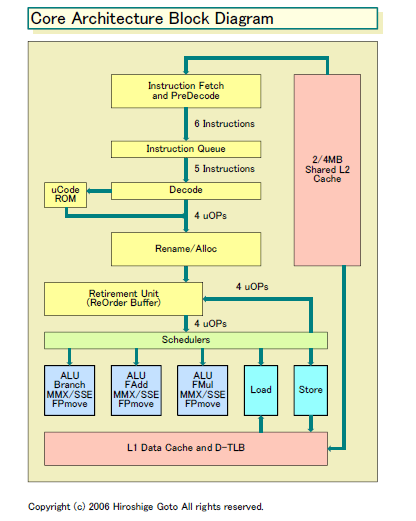
下が、Intelから正式に公開されたCore Microarchitectureのブロックダイアグラム図だ。演算ユニットアレイにはALU群が3グループと、ロードユニットが1、ストアユニットが1の合計5グループが並ぶ。演算系ユニットは、3ユニットそれぞれが整数演算スカラとMMX/SSEのユニットを含み、浮動小数点演算は加算(FAdd)と乗算(FMul)がそれぞれ別の命令発行ポートに配されている。分岐はいちばん左側のユニットだけに実装されている。
 |
| Core Architecture Block Diagram PDF版はこちら |
実は、この図は、7日の記事で示したものと構成が異なっている。7日の記事では、IDFの「Intel Multi-Core Architecture and Implementations」セッションのスライドからブロック図を引き出したが、あの構成だとFPUが1ユニットしかなく、疑問が残る構成だった。しかし、現地時間の3月7日に、Intelが報道関係者向けに行なった「Mobility Mega-Briefing」セッションで改めて、新しい図が公開された。
この構成では、SIMD(Single Instruction, Multiple Data)系の浮動小数点オペレーションが強化されており、非常にロジカルで納得ができる。SSE系命令も、128bit SIMDの乗算、128bit SIMDの加算、128bit SIMDのロード、128bit SIMDのストアを並列に行なうことができると見られる。つまり、SSE SIMDでも最大4命令並列のバックエンド帯域を持つと推測される。FPUが1基だと、どうやってSIMD乗算とSIMD加算を1サイクルスループットで行なうのか疑問だったが、この構成なら各ユニットが1サイクルスループットなら可能だ。
Intelでモバイル系の技術を担当するMooly Eden(ムーリー・エデン)氏(Corporate Vice President & General Manager, Mobile Platforms Group)も、昨日掲載したダイアグラム図は「見たことがない」と笑っていた。異なる事業グループが主導するプレゼンになると、統一が取れてないようだ。しかも、実際のIDFのセッションでは、さらに異なるダイアグラム図が示された。その図では、ALUが2個、FPUが1個の構成になっていた。よりおかしな図になっていたわけだ。こうした混乱は、Intelの内部でも、「Core Microarchitecture」の理解がまだ浸透していないことを示している。
●Macro-Fusionでは比較と分岐を1個のuOPに融合
Intelは、IDF中にCore Microarchitectureの詳細を小出しにしていく予定で、明日(3月8日)には、技術的な詳細が明かされる予定だ。今日の段階では、「Macro-Fusion」と呼ぶ(前回の記事でMacro-OPs Fusionと書いたものと同じ技術)複数のx86命令の融合技術の一部や命令帯域などが明かされたに留まる。しかし、現在明かされているだけでも、重要な情報を含んでいる。
もっとも大きなトピックスは、Macro-Fusionの内容だ。今回は、Macro-Fusionでは、x86命令のうち比較命令であるcmpまたはtestと、条件分岐命令(jcc)の組み合わせを融合させることが明らかになった。以前の記事で推測したほど複雑な融合を行なうわけではなさそうだ。この2命令は、命令ストリームの中ではほぼ確実に続いている。そのため、融合させるには、連続する2命令が融合可能かどうかをチェックすればいいと見られる。
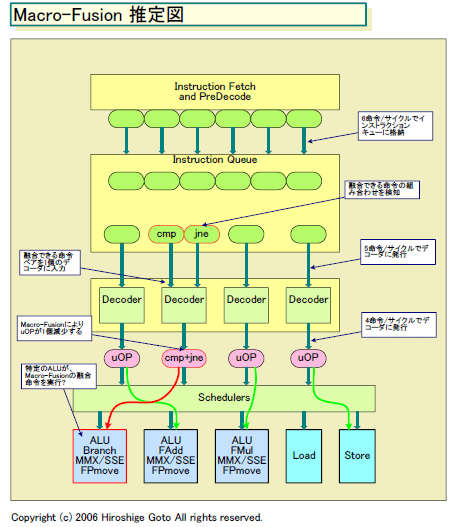
下が、新しい推定によるMacro-Fusionのフロー図だ。
 |
| Macro-Fusion 推定図 PDF版はこちら |
まず、Intelの説明によると、Core Microarchitectureでは、x86命令を6命令フェッチできる。フェッチした6命令はインストラクションキューに格納される。キューの深さはわからない。キューからは、最大5命令が命令デコーダに送られるとIntelは説明する。
しかし、デコーダは4ユニットしかないため、何もしなければ最大4命令しかデコードできない。だが、融合させることができるx86命令を検知した場合には、その命令ペアが1個のデコーダに送られ、Macro-Fusionが行なわれると見られる。Eden氏によるとデコーダに入れる前の段階で、Macro-Fusionが決定されるという。おそらく、キューの中の命令を検査すると予想される。
デコーダは、図に示した例のように、比較命令と条件分岐命令を、1個の内部命令(uOP)に融合させる。今のところ、この組み合わせしか示されていない。
Intelによると、デコーダから下のフロントエンドの帯域は、4 uOPs/サイクルとなっている。デコーダへのx86命令の入力が最大5命令ということは、同時には1組のMacro-Fusionしかできないと推測される。
uOPsはスケジューラを経て実行ユニット群に発行される。おそらく、この際に、比較+条件分岐のuOPが、そのままの単位で1基のALUに発行されると見られる。ALU側は、オペランドを比較し、分岐が成立したらジャンプするところまでを1サイクルで実行すると推測される。となると、ALU側にはブランチユニットが必要なはずで、だとしたら、Macro-Fusionの融合命令(Fused OP)は、1番左側の演算ユニットでしか実行できないことになる。また、もし比較するオペランドにメモリアドレスが含まれていたら、その部分はロードuOPとして分離され、Fused uOPよりも前にスケジュールされると推測される。そうしないと、データのロード待ちが発生してしまうからだ。
Core Microarchitectureではパイプライン段数が少ないため、1ステージのレイテンシが比較的長く、原理的には実行ステージでもロジックをある程度複雑にすることが容易だ。そのため、こうした実装が可能になったのかもしれない。
●最大5命令並列実行と同等のMacro-Fusion
新たに判明したMacro-Fusionが示すのは、これが推測したような命令の削減ではないと見られることだ。ただし、uOPs数を減らし、実行する段階でもuOPsは増えない。そのため、実質的に1命令分が減る。その意味では、削減する技術だ。逆を言えば、Core Microarchitectureは最大5命令を並列できるのと同じことになる。
Intelには、比較と分岐を組み合わせた複合命令を、命令セットに増やすという選択肢もあった。しかし、それでは既存のコードには意味がない上に、命令セットの複雑性も増やしてしまう。だが、Macro-Fusionにより、デコーダの段階で、実質的に新命令を増やしたのと同じことができれば、話は違ってくる。これは、一種の命令セットの仮想化と言っていいかもしれない。
この他、今日は、クアッドコアの「Kentsfield(ケンツフィールド)」を含む、各CPUの実物や動作デモも公開された。クアッドコアCPUは、デスクトップのKentsfield、DP(Dual-Processor)の「Clovertown(クローバタウン)」、それに、MP(Multi-Processor)向けのTigerton(タイガートン)と見られるClovertown-MPとラベルされたCPUの3種類。いずれも、2個のCPUダイ(半導体本体)を組み合わせた、マルチダイパッケージとなっている。
このことから、2007年のMPサーバー向けチップセット「Clarksboro(クラークスボロ)」は、4個のFSB(Front Side Bus)を備えることがわかる。1個のMCHに4個のFSBを実装することは不可能なので、実際には2個のMCHを何らかの広帯域ポートで接続、MCH 2個で4 FSBを実現すると見られる。
 |
 |
| ClovertownとKentsfield | 65nm製品のコア |
□IDF Spring 2006のホームページ(英文)
http://www.intel.com/idf/us/spring2006/
□IDF Spring 2006レポートリンク集
http://pc.watch.impress.co.jp/docs/2006/link/idfs.htm
□関連記事
【3月7日】【IDF】次世代CPU「Conroe」の内部構成が明らかに
http://pc.watch.impress.co.jp/docs/2006/0307/idf01.htm
【3月6日】【海外】IDFでいよいよ公開「Meromアーキテクチャ」
http://pc.watch.impress.co.jp/docs/2006/0306/kaigai247.htm
(2006年3月9日)
[Reported by 後藤 弘茂(Hiroshige Goto)]
【PC Watchホームページ】
PC Watch編集部 pc-watch-info@impress.co.jp ご質問に対して、個別にご回答はいたしません
Copyright (c) 2006 Impress Watch Corporation, an Impress Group company. All rights reserved.