 |


■後藤弘茂のWeekly海外ニュース■IDFでいよいよ公開「Meromアーキテクチャ」 |
●高効率を狙うMeromアーキテクチャ
Intelは、3月7日(現地時間)から始まる技術カンファレンス「Intel Developer Forum(IDF)」で、いよいよ次世代CPUマイクロアーキテクチャについて明らかにする見込みだ。新アーキテクチャは、デスクトップ「Conroe(コンロー)」、モバイル「Merom(メロン)」、サーバー「Woodcrest(ウッドクレスト)」として、一斉に投入される。IDFでは、アーキテクチャの概要やスペックが明らかになる。
また、Pentium 4の「NetBurst」アーキテクチャのような、マイクロアーキテクチャの正式名称も明らかになるようだ。ここでは、名称が発表されるまでは、仮に「Meromアーキテクチャ」としておく。新アーキテクチャCPU群のベースとなったのがMeromだからだ。
では、IDFでの正式発表前に、現在わかっている限りのMeromアーキテクチャの概要を整理しておこう。
Meromアーキテクチャは、Banias(Pentium M)/Yonah(Core)アーキテクチャを開発した、Intelイスラエルのチームが開発した。ロングパイプラインによる高クロック化でパフォーマンスを上げるNetBurstアーキテクチャとは対照的に、比較的短いパイプで高効率を追求した設計を採り、パフォーマンス/消費電力、パフォーマンス/周波数、パフォーマンス/トランジスタ数に優れる。
Meromアーキテクチャ系CPUの動作周波数は、Woodcrestで3GHz(TDP 80W)、Conroeで2.66GHz(TDP 65W)、Meromで2.33GHz(TDP 35W)と、NetBurst系より低い。しかし、周波数当たりの効率が高いため、パフォーマンスは相対的に高い。NetBurst系は、TDPさえ考慮しなければ4GHz以上の動作が可能だが、TDPの制約で、実際には性能が発揮できない。Meromアーキテクチャは、一定のTDP枠の中で最高性能を狙った設計だ。
●MeromアーキテクチャのカギとなるMacro-OPs Fusion
効率を上げるために、Meromアーキテクチャではいくつかの新テクニックを導入している。その中でも目立つのは「Macro-OPs Fusion(マクロオプスフュージョン)」だ。
MeromアーキテクチャのMacro-OPs Fusionは、内部命令(uOPs)の制御機能だ。Banias系で採用された「Micro-OPs Fusion(マイクロオプスフュージョン)」と同様に、uOPs数を減らす技術だ。しかし、uOPsを減らす手法は全く異なっていると推定される。
まず、Micro-OPs Fusionから整理しよう。今のPC向けx86系CPUは、x86命令を内部命令「Micro-OPs(uOPs)」に変換して実行する。これは、複雑なx86命令をRISCライクな単純なuOPsに置き換えた方が、アウトオブオーダ(out-of-order)型の命令スケジューリングが容易になるからだ。x86命令には、複数のオペレーションを含んだ命令(例えば、メモリからデータをロードして演算する)が数多くある。CPUの命令デコーダは、こうしたx86命令を、1オペレーションしか含まないuOPsに置き換える。後段のスケジューラや命令発行(Issue)メカニズムはuOPs単位で実行する。
「マシンはuOPsだけをネイティブ実行する。マシンからは、MacroOPs(x86命令)は見えず、MacroOPsがトランスレートされた結果(uOPs)しか見えない」とIntelのPatrick P. Gelsinger(パット・P・ゲルシンガー)氏(Senior Vice President and General Manager, Digital Enterprise Group)は以前NetBurstアーキテクチャについて説明していた。
この方法は非常に有効だが、難点もある。x86命令を分解することで多くのuOPsが生成され、CPU内部のリソースや命令(uOPs)帯域が消費されてしまうことだ。つまり、ムダが多いわけだ。
そこで、BaniasやYonahでは、命令によってはuOPsに分解しないまま、パイプラインで扱えるようにした。複数のオペレーションを含むx86命令を、複数のオペレーションを含む融合uOPs(Fused uOPs)へと変換する。例えば、ロードを含む演算命令を、NetBurstのようにロードと演算に分離しないで、1つのFused uOPとして扱う。それによって、パイプラインで扱うuOPs数を減らし、uOPsが占有するリソースを節約、負担を軽くする。Banias/Dothanでは、Micro-OPs Fusionによって、約10%のMicro-OPsを減らすことができたという。Yonahではそれをさらに発展、例えば、Banias/DothanではMicro-OPs Fusionを行なっていなかったSSEパイプラインでも同様の操作を可能にした。
Micro-OPs Fusionは、実際には“フュージョン(融合)”というより、“分解しない”と表現した方が合っている。もっとも、効率を考えると、実行ユニット側に命令を発行(Issue)する際には、オペレーション単位に分解する方がいい。そのため、命令発行ステージで分解されていると推測される。Fused uOPは、複合オペレーションと説明されており、後でオペレーション単位に分解されることを前提にした命令フォーマットとなっているようだ。
●Macro-OPs Fusionは複数のx86命令にまたがる融合か
Meromアーキテクチャでは、Micro-OPs Fusionに加えて、Macro-OPs Fusionが導入される。Macro-OPs Fusionの詳細はまだわからないが、ある程度の概要はIntelの顧客に明かされている。そこから、多少の推定はできる。
Intelはx86命令のことを「Macro-OPs」と呼んでいる。Micro-OPs Fusionでは、1つのMacro-OPs内の複数のオペレーションを、1つまたは複数の複合内部命令(Fused uOPs)に融合させていた。それに対して、Macro-OPs Fusionでは複数のMacro-OPsを1つまたは複数の複合内部命令(Fused uOPs)に融合させるようだ。つまり、Macro-OPs間にまたがる融合であるため、Macro-OPs Fusionと呼んでいると見られる。
ちなみに、AMDのK7/K8アーキテクチャでは、1個の複合内部命令「MacroOPs」に最大2個のオペレーションを複合させることができる。そのため、IntelのMacro-OPs Fusionと混同しやすいが、両技術はおそらく異なる。言葉の定義の問題だが、K7/K8アーキテクチャの“MacroOPs”と、Intelの一般的な“Macro-OPs”の使い方は、違うものを指しているからだ。K7/K8のMacroOPsは、複数のオペレーションを含むことが可能な内部命令で、Intelの言うFused uOPsに近い。つまり、K7/K8は、技術的には、Micro-OPs Fusionとある程度似たようなことをずっと以前からやっている。それに対して、IntelのMacro-OPsはx86命令を指し、複数のx86命令にまたがる融合を行なうと推測される。
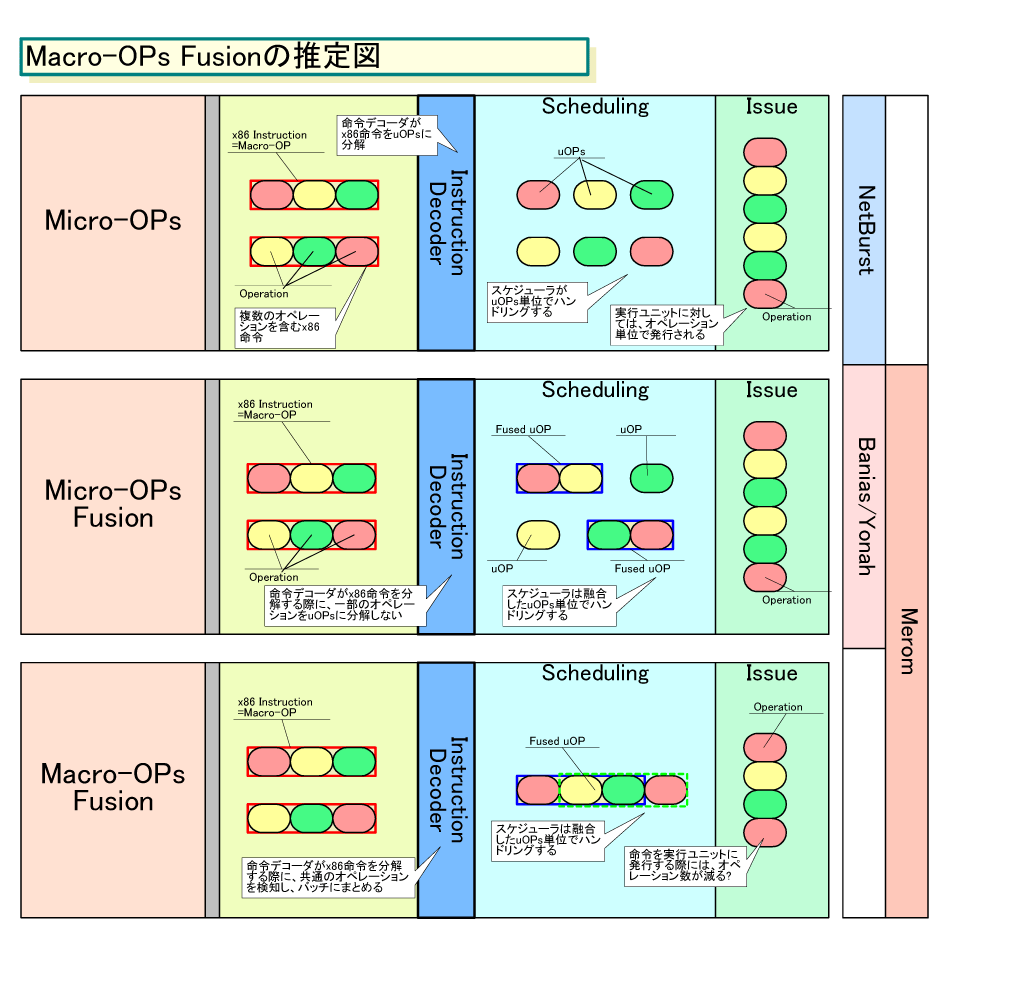
Intelは、顧客に対して、Macro-OPs Fusionでは、共通の命令群(Common Instructions)を検知、それをバッチにまとめて1つの内部命令として扱うことで効率を上げると説明している。下が、Intelの説明をベースにした想定図だ。図中で、4つのオペレーションが1つに融合されているのは、元の説明がそうなっていたからだ。実際には、もう少し粒度の小さな単位で扱われるかもしれない。
 |
| Macro-OPs Fusionの推定図 PDF版はこちら |
●Micro-OPs FusionはデッドuOPsの除去か?
ここからは推定となるが、おそらく、Macro-OPs Fusionでは、複数のx86命令中で同じオペレーションが繰り返されるケースを検知する。図を見る限り、バッチにまとめると言っているのは、重複するオペレーションを除去してまとめることではないかと推測される。
例えば、同じメモリアドレスのデータをオペランドとするx86命令が複数あると、uOPに分解した際に同じロードuOPが重なってしまう。その場合、後ろのx86命令のロードuOPを除去して、前のロードuOPでロードしたレジスタの値をオペランドに使う(またはMoveでレジスタ間移動させる)ことができるかもしれない。こうすれば、複数のx86命令にまたがる複数のオペレーションを1オペレーション(uOP)に減らすことができる。もちろん、こうしたコードの除去はコンパイラの段階で行なえばより効率的だが、動的に行なわないと不可能なケースもある。ある程度似たようなデッドオペレーションの除去は、TransmetaのEfficeonのソフトウェアレイヤ「CMS(Code Morphing Software)」のリアルタイムコンパイラ/スケジューラも行なっている。
この推定が正しいかどうかは、まだわからない。しかし、図を見ると、Macro-OPs Fusionでは、オペレーションが除去される可能性があると思われる。上の図のIssueステージの部分は、その推測を元に加えた。つまり、Issueステージの部分は完全に推測だ。もし、Macro-OPs FusionでデッドuOPsの除去ができるとすると、実際に実行ユニットに発行されるオペレーションも減る。Micro-OPs Fusionでは実行までのプロセスを効率化するが、Macro-OPs Fusionでは加えて実行の効率化を図ることもできるかもしれない。
Meromでは、Micro-OPs FusionとMacro-OPs Fusionの両方を備えていると説明されている。推測が正しければ、両技術はなんらぶつかるものではないため、両方を備えることは可能だ。また、MeromではMicro-OPs Fusionにも何らかの拡張が加えられている可能性もある。
●14ステージと比較的短いパイプライン構成
Meromアーキテクチャでは、Micro/Macro-OPs Fusionによって、uOPsの数を減らしてパイプラインの効率化を図るだけでなく、パイプラインの並列性も広げている。よく知られている通り、Meromは1サイクルに4命令の帯域を持つ。「4wideの(命令)デコーディングと実行ができる。完全に4命令並列だ」と前回のIDFでIntelは説明していた。
NetBurstとBaniasの両アーキテクチャは、どちらも最大3命令/サイクルだが、Merom系アーキテクチャではこの点が拡張されている。もっとも、これは単純化した言い方で、NetBurstはuOPsで3個の帯域。Banias/YonahはPentium IIIのマイクロアーキテクチャを継承し、シンプルデコーダが2、コンプレックスデコーダが1の構成であるため、実質は2命令/サイクルに近いままと推定される。デコードステージから含めて完全に4並列をうたうMeromのパイプラインは大きく異なるはずだ。ただし、Meromの4命令実行パイプについては、デコーダや実行ユニットの構造がまだ全く分からない。
並列性を上げる一方で、MeromではCPUパイプランは14ステージと比較的短く抑えた。CPUの動作周波数を左右する最大の要素はパイプライン段数だ。同じプロセス技術と回路設計技術、同程度のアーキテクチャ複雑度で、という条件がつくが。原理的には、パイプライン段数が多ければ、ある一定までは動作周波数が上がる。各ステージ毎のディレイが短くなるからだ。
Meromアーキテクチャの14ステージというパイプライン段数は「現行世代(のPentium M系)よりも少しパイプラインが深いが、NetBurstよりずっと少ない」(Intel)という。
NetBurst系は、Willametteが20ステージ、Prescottが31ステージ。ただし、これらは分岐予測ミスまでのパイプで、実際には、実行後のリタイヤが加わる。また、NetBurstでは命令デコーダはL1命令キャッシュであるトレースキャッシュの前に出ていてパイプラインにカウントされていない。そのため、本当の意味でのパイプライン(L1ミスでデコードから行なう場合も含める)はさらに深くなる。
Meromの方のパイプライン段数の定義はまだわからない。しかし、IntelのMooly Eden氏(VP & GM, Mobile Platforms Group, Mobile Technology)は、昨年、Baniasのパイプライン数を尋ねた時に「11から13の間」と言っていた。つまり、Baniasの元となったPentium IIIを11、Meromを14と数えていたことになる。おそらく、Meromパイプはリタイヤステージ群も含めて14だと推測される。
いずれにせよ、Merom系はPrescott系の半分程度のステージ数で、そのため各パイプラインステージのディレイは長くなる。その分、高周波数化は難しくなる。
ちなみに、K8パイプラインはL1データキャッシュアクセスを含めて12ステージ。これも数え方が違うのでやっかいだが、リタイヤメントを含めてMeromとそれほど大きくは変わらないパイプラインの深度と推測される。MeromとK8の両アーキテクチャが、同プロセスで同程度の周波数になるのは、決して偶然ではない。
●強化された浮動小数点演算SIMD演算ユニット
パイプラインの制御では、Meromは最大96個の命令をインフライト(In Flight)で制御できる。Yonahでは64命令インフライトだったので、50%増えたことになる。より多くの命令を制御できるようになったことで、パイプラインをより円滑に働かせることができる。
パイプラインの並列性が33%(3→4パイプ)しか増えておらず、パイプライン段数もそれほど深くなっていないのに、インフライトで扱う命令数が50%も増えたのは、よりアグレッシブなスケジューリングのためと推測される。より広い範囲のプログラムフローの中から、並列化するわけだ。ちなみに、NetBurstアーキテクチャでは126命令をインフライトで制御できるが、これはパイプラインが格段に深いことが影響している。
演算ユニット側では、SSE SIMD(Single Instruction, Multiple Data)演算ユニットが大幅に拡充された。4個の単精度(32bit)浮動小数点データで構成される128bit SIMDデータに対して、1サイクルスループットで1回の積和演算を実行できるようになった。つまり、オペレーション数では1サイクルに8浮動小数点オペレーションということになる。
イスラエルチームのCPUは、BaniasからYonahで浮動小数点演算性能が改善されたが、Meromではさらに2倍に強化される。NetBurst系も2サイクルスループットなので、NetBurst系と比較しても2倍の効率となる。Intel CPUは、浮動小数点演算性能が弱かったが、Meromアーキテクチャではようやくこの部分が改良されることになる。むしろ、ようやく先端CPUクラスの浮動小数点演算アーキテクチャになったと言い換えた方がいいかもしれない。
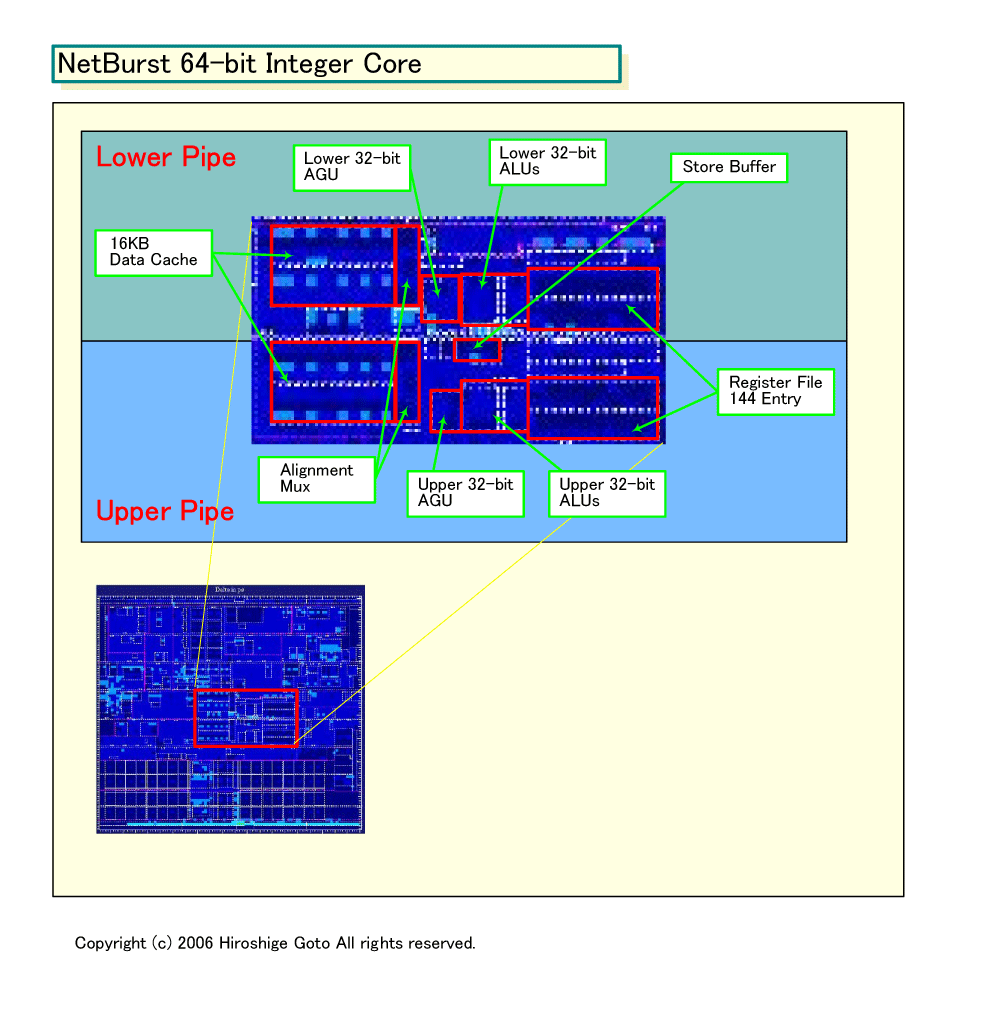
このほか、推測されるのは整数演算ユニットの改良だ。NetBurst系の整数演算ユニットは、Prescott以降は64bitに処理幅が拡張された。しかし、実際の実装は、32bitの整数パイプを2本重ねて64bit処理を実現している。下の図は、今年2月のISSCCで公開されたCedar Millの整数演算ユニットの図をベースに作成した、Prescottの整数演算ユニットの構成図だ。上のパイプがLower 32bitを処理、下のパイプがUpper 32bitを処理する構造になっていることがわかる。
 |
| NetBurst 64bit Integer Core PDF版はこちら |
NetBurst系の64bit整数演算ユニットの構造は、NetBurstの最終進化形である「Tulsa(タルサ)」でも変わっていない。そのためか、NetBurst系では、通常ならより大きな面積を必要とするはずの浮動小数点演算ユニットと、それほど変わらないダイ面積を整数演算ユニットが占めている。おそらく、Meromでは整数演算ユニットの実装は、64bitに最適化した、より効率的な設計になると推測される。
ちなみに、NetBurstの整数演算ユニットは144本(64bit時と見られる)と膨大な数の物理レジスタを備える。論理レジスタは、EM64T時でもGPRが16本なので、NetBurstは膨大なレジスタリネーミング空間(レジスタの衝突を避けるために物理レジスタに振り分ける)を備えていることになる。このあたりも、パイプラインが短いMeromアーキテクチャでは、よりコンパクト化されてくるかもしれない。
●投機ロードを可能にするMemory Disambiguation
Meromアーキテクチャは、各コアがそれぞれL1命令キャッシュ32KB、L1データキャッシュ32KBずつを備える。NetBurstでは、プログラムの中で実際に使われるコードのトレース(実行されるパス)をキャッシュするトレースキャッシュを実装するが、Meromではトレースキャッシュを取らないと推定される。
最初の世代のMeromアーキテクチャは、デュアルコアに最適化した設計を取り、2つのCPUコアでL2キャッシュを共有する。L2キャッシュサイズは、ある程度までスケーラブルに変えることができる構造になっている。また、L2からCPUコア群へのデータ帯域も倍増された。
マルチコアCPUでは、複数のCPUコア間のキャッシュコヒーレンシの保持が重要な課題となる。Meromでは、コヒーレンシのためのL1キャッシュ間のスヌープとデータ転送は、ダイレクトトランスファで行なわれるという。このメカニズムの詳細も、まだ明らかではない。
メモリマネージメントでは、プリフェッチを強化し「Memory Disambiguation」を実装する。この2つは密接な関係にある。データのロードはレイテンシが長いので、できるだけ前もってロードしておきたい。つまり、ロード命令をできるだけ前に実行するように命令順序を並べ替えたい。
しかし、ロード命令より前の方にストア命令がある場合、通常は、それ以上前にロード命令を実行することができない。それは、ストア命令がストアするはずのメモリアドレスから先にデータをロードしてしまうことになるかもしれないからだ。アドレスが前もってわかればコンパイラレベルで最適化が可能だが、実際には実行時にならないとアドレスの依存関係が判明しないことが多い。そのため、ロードをストアの前に出すためには、動的に依存関係を判定するメカニズムが必要になる。Memory Disambiguationは、こうしたデータ依存関係の曖昧さ(ambiguity)を解決する機構だ。何らかの方法で、アドレスの依存関係を解消またはチェックできれば、ロード命令をストア命令よりも前に実行。演算命令が実行される時には、オペランドがレジスタに格納されているように配置することができ、ロードレイテンシを隠蔽できるわけだ。
実は、IA-64アーキテクチャは、似たようなDisambiguationを動的に行なうメカニズムと命令を初めから持っている。そのため、IA-64では、ロード命令を先に出した場合、レジスタにロードしたデータが有効かどうかをチェックできる。具体的には、投機的にロードする時にはld.a命令を使い、ロードしたアドレスを「ALAT」に入れる。その後にストア命令が実行されるとALATをチェック、アドレスが合致した場合にはエントリを除去する。実際にプリロードした値が使われる前に、ld.cまたはchk.cを実行し、ALATミスした場合には、ロードをやり直すという仕組みだ。
MeromのMemory Disambiguationがどんなメカニズムを取るかはまだわかっていない。このほか、Meromではストリーミングデータ転送に適したメモリアクセスを容易にするという。
●Santa-RosaではTurbo Modeで42WにTDPを引き上げ
MeromファミリのFSB(Front Side Bus)は、現行アーキテクチャの延長で、最初のダイ(半導体本体)でも少なくとも1,333MHzまでに対応する。実際にはWoodcrestが1,333MHz、Conroeが1,067MHz、Meromが667MHzでスタートする。Meromは、2007年第1四半期の新プラットフォーム「Santa-Rosa(サンタロサ)」への移行で800MHz FSBへと移行する。
TDPレンジは述べた通りConroeで65W、Meromで35W。つまり、デスクトップPCでは最高のTDPだった、Performance FMB(Flexible Motherboard) 05Bスペックの130Wから半分に下がる。ただし、2007年にクアッドコアの「Kentsfield(ケンツフィールド)」が出てくると、トップエンドはまた同程度のTDPになる。
モバイルはYonah DCの通常電圧版(Tクラス)の31Wから35Wへと10%ちょっとTDPが上がる。さらに、Santa-RosaになるとMerom FSB 800では、「Turbo Mode(ターボモード)」と呼ばれる高速&高TDPモードがオプションで追加される見込みだ。Santa-Rosaでは、通常のTDPは35Wのままだが、Turbo Mode時には最大42WにまでTDPが引き上げられる。つまり、Turbo Modeを実装したノートPCでは、より高パフォーマンスが見込めることになる。Intelは、以前、SpeedStepをさらに上にパフォーマンスを伸ばすために使う可能性があると示唆していたが、それがSanta-Rosaで実現されることになる。
Meromアーキテクチャでは、Intelが「*T(スターT)」と呼ぶCPU拡張技術のうち、Hyper-Threading以外がサポートされる。64bit拡張「EM64T(Extended Memory 64 Technology)」、「Enhanced Intel SpeedStep Technology(EIST)」、「VT(Virtualization Technology)」などだ。現行のNetBurstと同等のフィーチャを備えることになる。また、「Merom New Instruction(MNI)」と呼ばれる新命令群も追加される。命令セットの詳細は、まだ分かっていない。
□関連記事
【2月24日】インテル、次世代コアMerom/Conroeの改良点を公開
http://pc.watch.impress.co.jp/docs/2006/0224/intel.htm
【2月10日】【海外】モバイルCPU「Merom」は年末商戦に登場
http://pc.watch.impress.co.jp/docs/2006/0210/kaigai242.htm
【2005年8月8日】【海外】複雑になったIntelのモバイルCPUロードマップ
http://pc.watch.impress.co.jp/docs/2005/0808/kaigai201.htm
【2004年3月15日】【海外】Intelの次々世代CPU「Merom」の姿
http://pc.watch.impress.co.jp/docs/2004/0315/kaigai074.htm
(2006年3月6日)
[Reported by 後藤 弘茂(Hiroshige Goto)]
【PC Watchホームページ】
PC Watch編集部 [email protected] ご質問に対して、個別にご回答はいたしません
Copyright (c) 2006 Impress Watch Corporation, an Impress Group company. All rights reserved.