
|


●NVIDIAは複数のNV3xファミリを短いスパンで投入
 |
| NVIDIA推定ロードマップ |
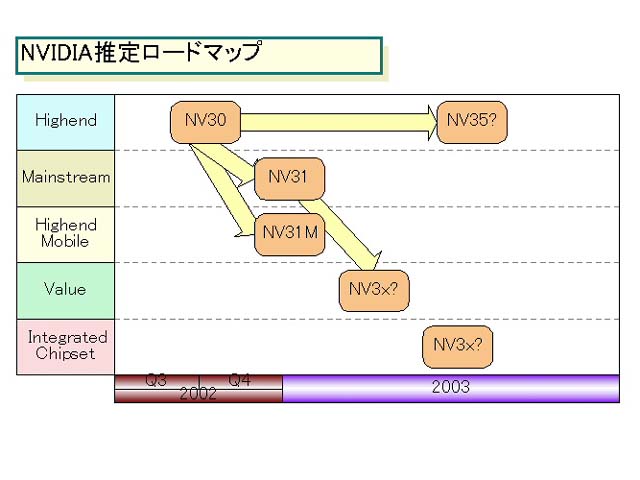
NVIDIAのDirectX 9世代GPU「NV3x」ファミリの概要が見えてきた。NVIDIAは早い段階で2系列のDirectX 9世代GPUコアを投入すると思われる。1系列はハイエンドデスクトップ向けの「NV30」、もう1系列はメインストリームデスクトップやモバイル向けチップ。メインストリーム&モバイル向けチップは、NV30の機能削減版の派生品(derivative)と見られ、多くの業界関係者が「NV31」と呼んでいる。
NVIDIAはNV30を今秋の早い時期に発表する見込みだが、NV31系もNV30に続いて年内に発表されると思われる。また、NVIDIAは、NV3x系コアの統合チップセットやローエンド向け製品も投入する。NVIDIAは、今回のDirectX 9世代では、こうしたNV30の派生品を急ピッチで展開するらしい。
NV30は0.13μmで製造され、トランジスタ数は1億2,000万。NV31はそれよりかなりトランジスタ数は少なくなると見られる。そのため、NV31はレンダリングパイプ数やメモリインターフェイス幅がNV30の半分に削減されていると思われる。製造は従来通りTSMCだ。
NV3xファミリのアーキテクチャは、“DirectX 9のスーパーセット”となっている。つまり、DirectX 9を拡張したもので、プログラム性を大幅に高めている。NVIDIAは明言していないが、NV30の現在公開されているフィーチャを見る限りアーキテクチャはDirectX 9.1相当と思われる。
また、NVIDIAはプログラム性を高めたハードに合わせて、シェーディング言語「Cg」をリリースしてきた。今回NVIDIAは、GPUとコンパイラを連携して(同じチームで)開発することで、プログラムがハードの性能を引き出せるようにする開発手法を取った。これは、CPUでは一般的な開発手法だ。NV3xはCgとセットと見なすのが正しいだろう、CPUのように。
●より高速でフィーチャリッチなNV30
NVIDIAのDavid B. Kirk(デビッド・B・カーク)氏(Chief Scientist)は、7月21日から開催されたコンピュータグラフィックスカンファレンス「SIGGRAPH」でのインタビューで、NV30の発表が間近いことを明かした。ちなみに、NVIDIAは大規模なイベントに合わせて製品発表を行なう傾向がある。
出荷に関しては今秋の見込みだが「安全に言うなら年末」なので、クリスマス商戦に間に合ったとしても、潤沢にモノを揃えられるかどうかは怪しい。つまり、ATI TechnologiesのRADEON 9700(R300)に対しては1~2四半期遅れをとることになる。
ただし、NVIDIAはパフォーマンスとフィーチャではRADEON 9700を凌駕できることに自信を持っている。「NV30はR300より高速になるだろう。R300は0.15μmプロセス技術で製造されているため、高速にするのは難しい。同じ0.15μmプロセス技術のGeForce4との周波数の差は、あまり大きくはないだろう。それに対して、NV30は0.13μmプロセスなので、ずっと速いクロックに出来るだろう」とKirk氏は言う。
また、NV3xファミリは新アーキテクチャ「CineFX」を備える。これは、NVIDIAのシェーディング言語Cgとの組み合わせで、「Real-Time Cinematic Rendering」を可能にするDirectX 9の拡張だ。DirectX 9より命令セットとレジスタを大きく拡張、浮動小数点精度のフレームバッファもサポートする。CineFXとCgについては、またあとでレポートしたい。NVIDIAは、NV30ファミリのCineFXのShaderのバージョンを「2.0+」と表現する。つまり、DirectX 9のShaderの2.0より後のバージョンになりそうだ。ちなみに、NV30もDisplacement Mappingをサポートするが、あまり強調はしない。
●NV30は8パイプ、NV31は4パイプ?また、NVIDIAは、7月16/17日に開催されたPlatform Conferenceで、NV30のトランジスタ数が1億2,000万トランジスタにのぼることを明かした。これは、RADEON 9700(1億1,000万)とほぼ同等だ。そのため、NV30が8レンダリングパイプを備えるのはほぼ確実と見られる。
レンダリングパイプはGPUのなかでもっともトランジスタを食うため、パイプ本数とGPUの総トランジスタ数にはある程度の相関関係がある。ラフに言うと、1パイプにつき1,500万トランジスタ程度で計算できると言われる。つまり、1,500万×8=1億2,000万で、8パイプならちょうど計算が合うわけだ。また、レンダリングパイプ本数とメモリ帯域幅にも相関関係がある。そのため、まだDDR世代のNV30では256bitメモリインターフェイスを備える可能性が高い。
NV31はNV30の派生品だと見られる。概要はまだ一切不明だが、ターゲットがメインストリームデスクトップとモバイルであることから、トランジスタ数を減らして、ダイサイズ(半導体本体の面積)と消費電力を落としたバージョンになることは確実と見られる。
Trident MicrosystemsのLe Trong Nguyen氏(Assistant Vice President, Graphics Marketing)は「NV31M(NV31のモバイル版)は8,000万トランジスタ程度になると見積もっている」と言う。Tridentは、NV31はNV30のフィーチャは備えるものの、4パイプ構成とNV30の半分のレンダリングパイプ本数になると推測する。
NVIDIAはこのNV31の他にも多くのNV3xファミリを用意する。「NV30は、次世代のための最初のコアテクノロジだ。しかし、NV30ファミリには非常に多くの製品がある。モバイル、メインストリームデスクトップ、ローエンド、インテグレートなど。すべてNV30テクノロジーベースで、NV30のあとすぐに出てくる。NV30はほとんどの他の製品よりマスマーケットに迅速に移行して来ると思う。これは、非常に興奮する」とKirk氏は説明する。
NVIDIAでモバイル製品のマーケティングを担当するSunder Velamuri氏(GM, Mobile Business)も「次世代テクノロジは、今年末までにデスクトップPCだけでなく、ノートPCでも手に入るようになるだろう」と語る。
●NV3xでは普及のペースを上げるNVIDIANVIDIAの計画通りなら、おそらく2003年中には、NV3xアーキテクチャは一気にNVIDIAラインナップの普及価格レンジにまで浸透することになる。これは、これまでのNVIDIAの戦略とは大きく異なる。NVIDIAの現在のラインナップでは、ハイエンドとメインストリームの上半分だけがDirectX 8世代のNV2xアーキテクチャで、メインストリームの下半分に位置する「MX」シリーズはまだNV15系アーキテクチャのままだ。つまり、アーキテクチャ的に分断されている。それが、NV3xからは同じアーキテクチャの普及が加速され、一気にアーキテクチャ的に上から下まで統一されるようになる。
「理由はいくつかある。まず、我々自身が素晴らしい技術にエキサイトしていること。顧客にも人気になると思うので、この技術をベースにした(派生)製品を多く作ることに力を入れている。また、ハイエンド製品だけだと、多くの人が持つようになるまでゲーム開発者は新技術に投資するのが非常に難しい。それで、我々が投資してこの技術のマスマーケットバージョンをできるだけ早く作って、開発者が安心して開発できるようにすることが大切だと考えている」とKirk氏は理由を語る。
NVIDIAが、今回、NV3xアーキテクチャの浸透を急ぐ理由は、アーキテクチャを考えるとよくわかる。DirectX 9世代以降は、GPUのプログラム性が大幅に拡張される。そのため、アーキテクチャの統一性を取ることは、これまでよりずっと重要になる。同じシェーダ(シェーディング言語で書かれたプログラム)が実行できる環境を揃える必要があるわけだ。また、そうした戦略によって、NVIDIAにとって最適なコードを吐けるCgの支持を集めることが、将来へつながると考えているようだ。
□関連記事
【6月14日】NVIDIA、グラフィック言語「Cg(C for graphics)」を公開
~GPUの機能に最適化されたコードをコンパイル可能
http://pc.watch.impress.co.jp/docs/2002/0614/nvidia.htm
(2002年7月31日)
[Reported by 後藤 弘茂]