 |


■後藤弘茂のWeekly海外ニュース■2010年以降のIntel CPUが見えてくるLarrabee新命令 |
●Intelの命令アーキテクチャ拡張の流れにあるLarrabee新命令
Intelにとって「Larrabee(ララビー)」とは何か。Larrabeeが、スループットコンピューティングに特化して、ベクタ演算とマルチスレッドパフォーマンスにフォーカスした特殊なプロセッサ製品であるのは明らかだ。しかし、Larrabeeの新命令『Larrabee New Instructions (LNI) 』自体は、もっと汎用的なものだ。おそらく、IntelのメインストリームCPUの、長期の命令セットロードマップ上に位置する。そのままでないとしても、おそらくLarrabeeとよく似た命令セット拡張が、PC&サーバー向けCPUにも実装される日が来るだろう。
Intelは長期ビジョンとして、PC&サーバー向けのCPUでもベクタ演算の機能を高めて行くことを明らかにしている。今年(2008年)春のIDFでは、今後のCPUの性能向上は、命令セットの変革によってなされると説明していた。そして、命令セット変革の核となるのは、ベクタ演算命令の強化だ。
 |
| Patrick(Pat) P. Gelsinger氏 |
ただし、IntelのPatrick(Pat) P. Gelsinger(パット・P・ゲルシンガー)氏(Senior Vice President and General Manager, Digital Enterprise Group)によると、これは新しいアイデアではなく、大きな流れの中に位置するトレンドだという。
「我々は、MMX以降、徐々にベクタ機能と命令セットを(PC&サーバー向けCPUに)導入して来た。64-bit(ベクタ)をMMXで、128-bitをSSEで、そして256-bitをAVX(Intel Advanced Vector Extensions)で、Larrabeeではさらにその先へ。その意味では、ベクタ機能は、我々にとって特に新しいものではなく、漸進的に対応を進めて来たものだ」(Gelsinger氏)。
IntelはSIMD(Single Instruction, Multiple Data)型のベクタ演算ユニットを'97年のMMX Pentiumで実装した。この時はベクタレジスタの幅は64-bitだったが、次のSSEでは128-bitの新レジスタを設けた。SSEでは、32-bit単精度浮動小数点演算で4wideのベクタ演算命令だったが、実際の演算ユニット自体は64-bit幅だった。演算ユニットを128-bit幅に拡張したのはCore 2(Merom:メロン)世代からで、命令セット自体もSSEからSSE2、SSE3、SSE4と拡張を続けてきた。SSE命令にはベクタ命令以外の命令も多数含まれるが、拡張の核がベクタ演算にあることは変わらない。
Intelは、今後、256-bit幅で32-bit単精度なら8wideベクタ演算が可能な「Intel Advanced Vector Extensions (Intel AVX)」を2010年から2011年のCPU「Sandy Bridge(サンディブリッジ)」に実装する。さらに、その先のCPUでは積和算命令「Fused Multiply Add(FMA)」を実装する。これがメインストリームCPUの命令セットのベクタ演算拡張の流れだ。それと平行して、IntelはLarrabeeで512-bit幅で単精度なら16wideベクタ演算が可能なLarrabee新命令を導入する。
こうしてみると、IntelはSSEで128-bitベクタを導入して以来、汎用的なCPUでは、10年もベクタ幅自体の拡張を行なわなかったのが、ここへ来て急に拡張し始めたことがわかる。Gelsinger氏は、PC&サーバー向けCPUでも、いずれ512-bitベクタへと進むことを示唆している。Intelは、どうやら本気でPC&サーバーCPUでのベクタ演算機能を拡張して行くつもりのようだ。
ただし、ベクタ幅を広げると、それを埋めることが難しくなるため、Intelはそれに対する対策も必要となる。その策の1つは、Larrabeeが実装するベクタ条件分岐命令とマスクレジスタのような、ベクタ演算に柔軟性を持たせる新しい仕掛けだ。新しいと言っても、GPUではすでに使われているテクニックで、その意味ではGPUに似つつある。
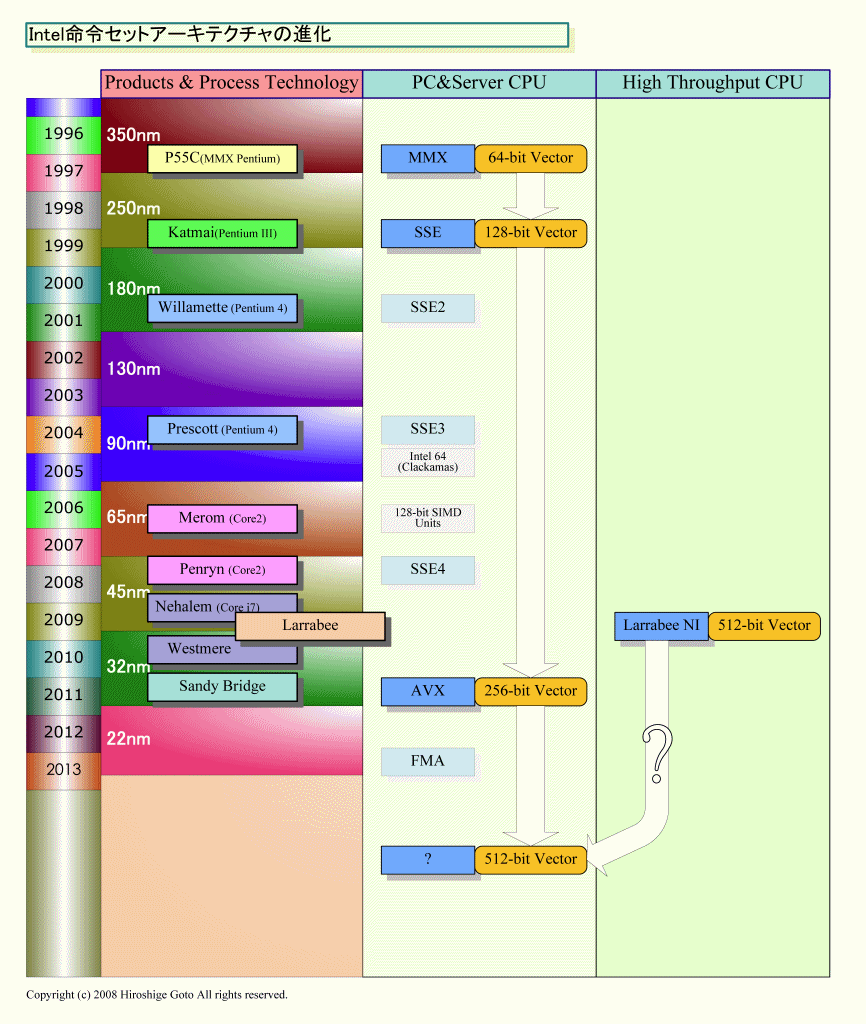 |
| CPU命令セットアーキテクチャの進化 PDF版はこちら |
●マルチスレッド+ベクタ演算の時代に入るIntel CPU
Intelがベクタ演算を強化しようとしている理由は、その方が効率がいいからだ。現在のCPUは、命令レベルの並列性であるILP(Instruction-Level Parallelism)の限界「ILPウォール(ILP Wall)」のために、CPUコアの演算性能を高めることが難しい。ILPを上げるためにハードウェアを追加しても、以前ほどのILP向上は得られないため、消費電力の壁「パワーウォール(Power Wall)」に性能向上を阻まれてしまう。
CPU業界は'86年から2002年までの間、およそ年に52%ずつシングルCPUコアの整数演算パフォーマンス(SPECint)をアップさせて来た。下はCPU研究者として有名なDavid A. Patterson(デヴィッド・A・パターソン)教授(University of California at Berkeley)が、2006年8月のCPUカンファレンス「HotChips 18」で示したプレゼンテーションだ。
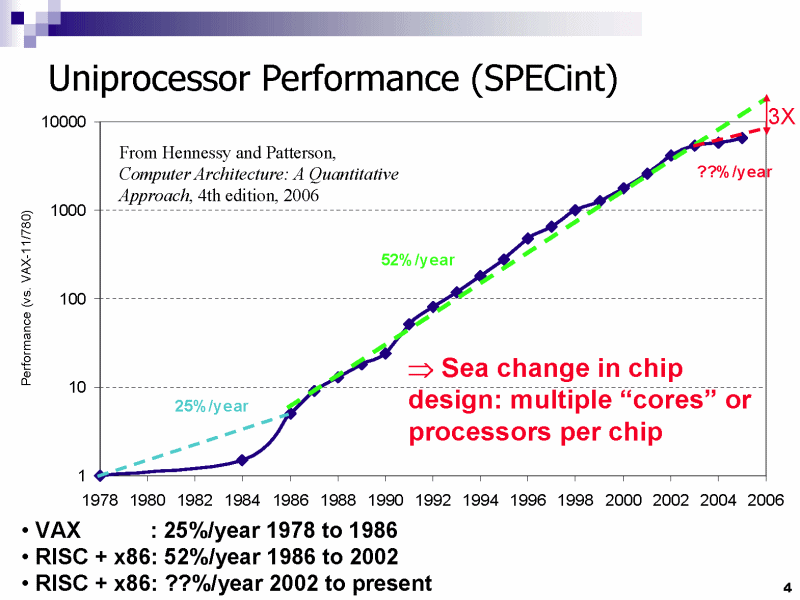 |
 |
| 整数演算性能向上の遷移 | 性能向上におけるいくつかの「壁」 |
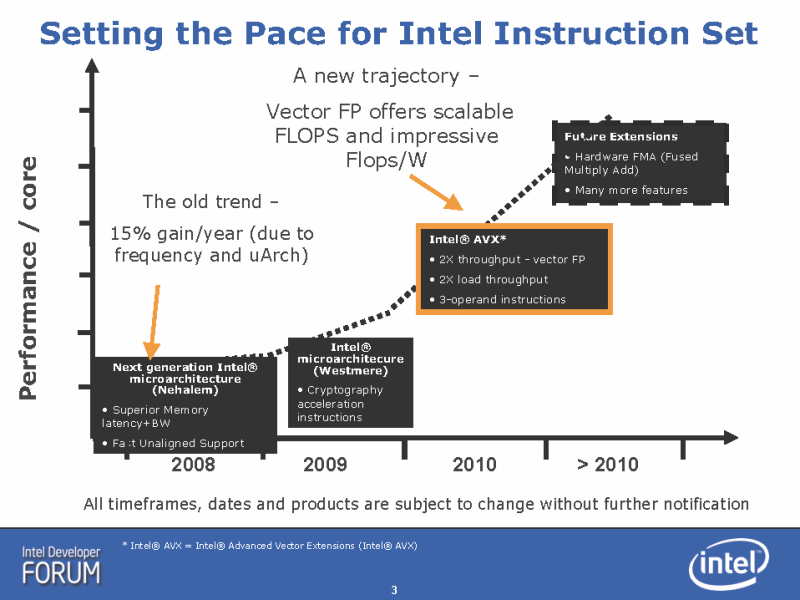 |
| Intel命令セットの変化と性能の関係 |
しかし、Intelは今年春のIDFで、現在のCPUコアの性能向上は年に15%程度にまで落ちてしまっていることを明らかにしている。CPUコア自体のパフォーマンスが上がらなくなったため、CPUベンダーはCPUコア数を増やすことで性能を向上させてきた。これが、現在のマルチコアCPUのトレンドを産み出している。
だが、Intelは2010年以降は、再び、CPUコアのパフォーマンスが大きく向上し始めると説明した。ただし、それは整数演算ではなく、上の図にあるようにベクタ型の浮動小数点演算だ。AVXで256-bitベクタへと拡張することで、ベクタ演算のスループットは2倍になる。次に1命令で積和算を行なうFMAの導入によって、スループットはさらに倍増する。この2つの拡張で、ベクタ演算のスループットは単純計算で4倍となる。もし、4年で4倍のペースで性能を伸ばせるのなら、年に40%以上のパフォーマンス/コアの向上を実現できることになる。Intelのスライドが示しているのは、そうした流れだ。全体の流れを図としてまとめると、下のようになる。
Intelが、この流れでAVXとFMA以降もCPUコアパフォーマンスの急ピッチの向上を果たして行こうとしたら、選択肢は1つしかない。それは、ベクタ幅をさらに広げてLarrabeeと同じ512-bitへと持って行くことだ。そのため、2010年以降は、ベクタ演算ユニットと命令セットの進化はこれまでより急ピッチになると推定される。
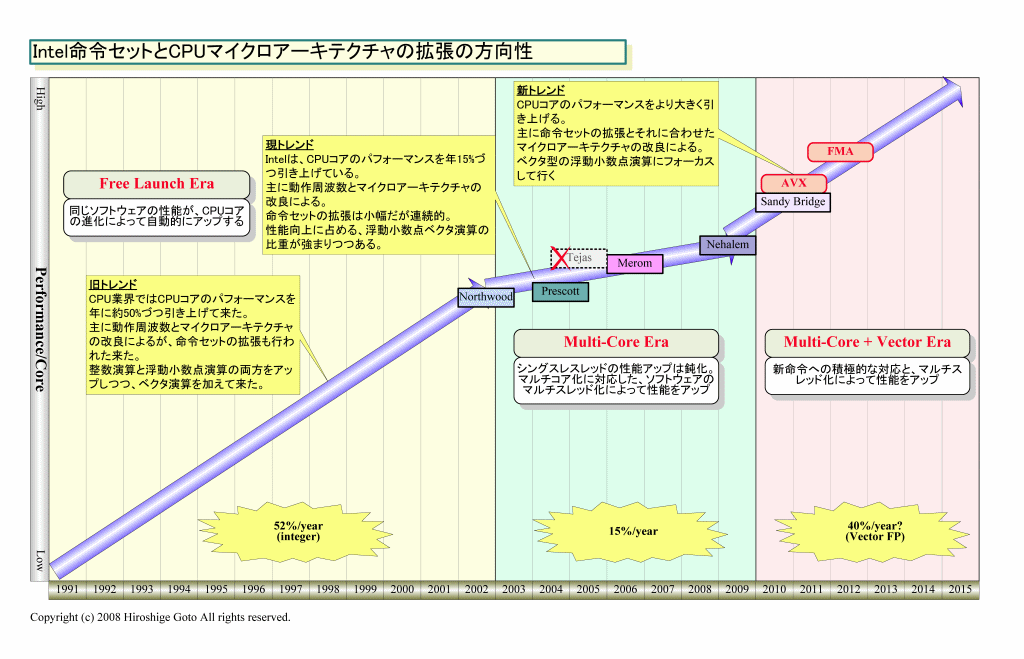 |
| Intel命令セットとCPUアーキテクチャの方向性 PDF版はこちら |
●命令並列とデータ並列、スレッド並列のバランスを取る
ベクタ演算へと比重を移すIntel。では、IntelはメインストリームのCPUをベクタ演算ユニット中心へと作り替えようとしているのか。そうではないと、Gelsinger氏は語る。
「ベクタ機能を強化しながら、より高いレベルでは、我々は、(CPUの)世代間での互換性も保とうとしてきた。高度なベクタアプリケーションが登場しても、依然としてスカラ演算部分が残されるからだ。だから、我々はベクタ機能の強化と同時に、スカラパフォーマンスも必要だと考えている。
また、我々は、(ベクタでの)データ並列機能と同時に(マルチコア/マルチスレッドでの)スレッド並列機能も提供して来た。つまり、素晴らしいベクタ機能をもたらすのと同時に、高いスレッド並列性も同時にもたらし、さらに世代毎にスカラパフォーマンスも漸進的に向上させる。それによって、スカラ、スレッド、データパラレル(ベクタ)の3つの方向で、アーキテクチャ上で妥協のない性能を提供できると考えている。
加えて、我々はツールセットも提供する。Cコンパイラ、Integrated Performance Primitives (IPP)、MPI、Threading Building Blocks、Open-MPなど。こうしたツールによって、データとスレッドの並列化する環境でも、全ての要求に対して互換性を維持しながら、最も整ったソフトウェア開発環境を提供できるだろう」。
Intelの戦略は明瞭だ。ベクタ演算の強化によって「データレベルの並列性(DLP:Data-Level Parallelism)」を上げるが、依然としてスカラ演算の「命令レベルの並列性(ILP:Instruction-Level Parallelism)」も維持し、マルチコア化とハードウェアマルチスレッディングの実装による「スレッドレベルの並列性(TLP:Thread-Level Parallelism)」も高めて行く。DLPとILPとTLPの3つの方向のバランスを取るとGelsinger氏は示している。
逆を言えば、ベクタ演算の強化のために、スカラ演算性能を犠牲にはしない。もちろん、パフォーマンス向上のほとんどはベクタ演算によるものになるだろうが、ソフトウェア側が100%ベクタコードになることはあり得ないので、スカラ演算性能は守り続けるという思想だ。ベクタユニットが大型化する分、マルチコア化の勢いは削がれることになるだろうが、CPU全体の性能はマルチコア&マルチスレッドとより強力なベクタ演算ユニットの組み合わせの方が向上すると踏んでいると思われる。また、スレッドの並列性を増やして行っても、それだけでは性能を得られるアプリケーションが限られてしまう。スレッド並列よりデータ並列が向いた処理も多いため、その両者のバランスを取るつもりだと想定される。
Intelの常として、メインストリームCPUでは極端にはアーキテクチャを振らない。過去5~6年のマルチコア/マルチスレッド化の流れでも、IntelはSun MicrosystemsやCell Broadband Engine(Cell B.E.)陣営のように、マルチコア/マルチスレッドへ一気に振らなかった。もちろん、それはPC&サーバーで膨大なレガシーソフト資産を抱えているからで、それがIntelの重荷でもあり有利な点でもある。
●Larrabeeは同じ命令セットの中で実装を極端に振った?
では、こうした全体の構図の中で、Larrabeeはどこに位置するのか。Gelsinger氏の語る、Intelの命令セットとCPUアーキテクチャの進化の図式の中では、LarrabeeはメインストリームCPUより重心がずれている。メインストリームのPC&サーバーCPUがスカラ演算性能は犠牲にしない方針であるのに対して、Larrabeeではスカラ演算性能はある程度犠牲にして、ベクタ演算とマルチコア&マルチスレッドへと思い切り振っている。
スカラ演算ユニットはPentium(P5)をベースに発展させたものであり、2-wayのIn-OrderパイプラインとAtomと同レベル。しかし、ベクタユニットは16wideでSSEの4倍で、FMA命令もサポートする。演算ユニット当たりのスループットは8倍になる計算だ。CPUコア数は同世代の同サイズのPC&サーバー向けCPUの約4倍と言われている。つまり、ILPはぐっと低いが、DLPとTLPはPC&サーバー向けCPUの4倍程度かそれ以上で、CPU全体の演算パフォーマンスはPC&サーバー向けCPUより1桁高いレンジ。これがLarrabeeの実装だ。
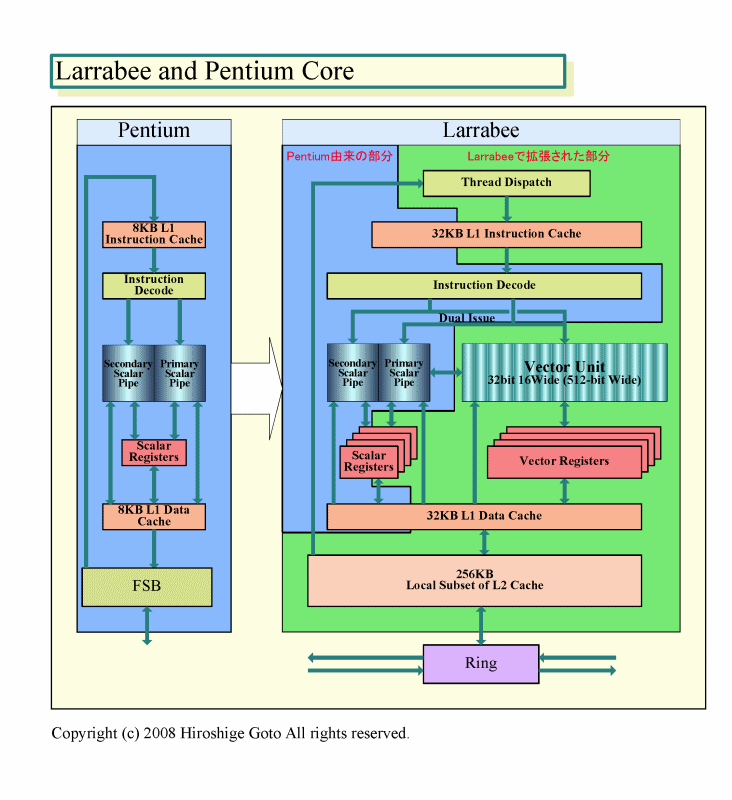 |
| PentiumとLarrabeeコアの比較 |
おそらく、ある程度共通した命令セットアーキテクチャの拡張の枠の中で、実装を汎用のPC&サーバー向けCPUとは大きく変えた実験がLarrabeeだ。命令ロードマップを先取りして、小さなCPUコアと組み合わせたと言い換えてもいいかもしれない。ここで重要な点は、IntelがLarrabeeで、PC&サーバー向けCPUとできる限りプログラミングモデルの統一性を図ろうとしている点だ。
Larrabeeに実装されるLarrabee NI自体は、事実上、x86の新しい命令セット拡張に過ぎない。完全に新しい命令セットをゼロから作ったのではない。メモリモデルも、チップ全体でコヒーレンシが取られたキャッシュアーキテクチャで、通常のCPUと同じように見える。ベクタマシン的な技術も取り込んでいるが、基本はメインストリームCPUの枠にはまる。Gelsinger氏は、次のように説明している。
「ベクタマシンは、過去に(ベクタスーパーコンピュータなどで)優れたピークパフォーマンスを実現した。しかし、汎用性は非常に悪く、データセンタの一部以外では広まらなかった。我々が取るのは、(ベクタマシンに)よく似たラディカルなアーキテクチャだが、キャッシュコヒーレンシの保持といった、より汎用的で互換性があるアーキテクチャを継承することがいいと考えている。
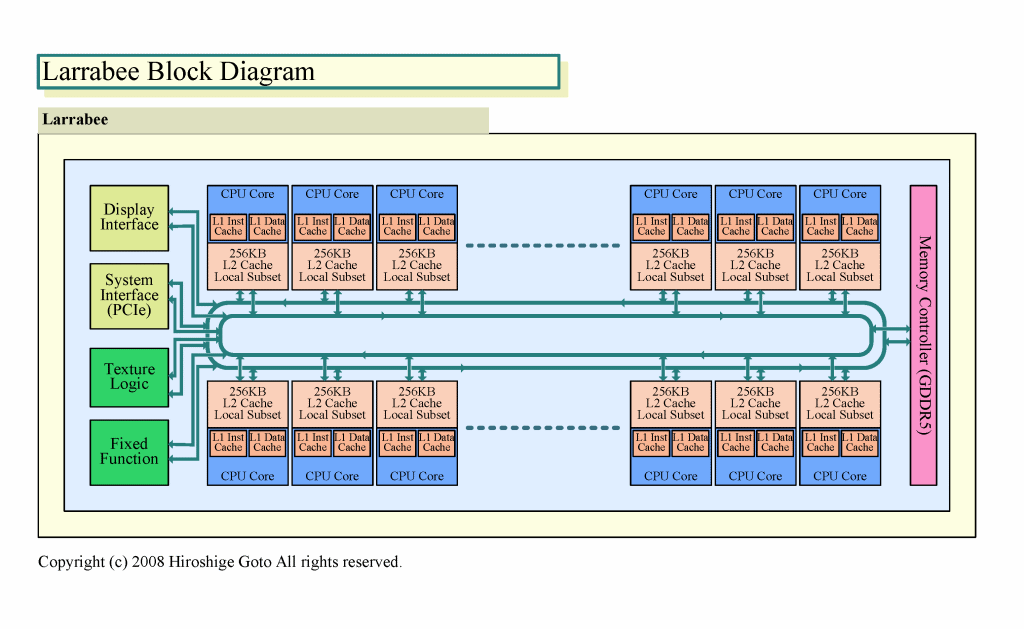 |
| Larrabeeのブロックダイヤグラム |
例えば、Cell B.E.アーキテクチャなどは、その点(キャッシュコヒーレンシなど)で劣っている。また、GPGPUアーキテクチャのように、非常に特殊化されたハードウェアでのプログラムについても、広く成功して普及することはないと予想している。
我々のアプローチは、そうした(ベクタマシン的な)機能を、(従来のCPUと)互換性のある方法で作り上げ、革新的なスループットとビジュアルコンピューティングアプリケーションを実現することだ」。
IntelのLarrabeeのアプローチには利点と難点がある。利点は、命令セットのある程度の統一性が保たれるため、ソフトウェアの移植などが容易になることだ。例えば、もし将来のIntelのPC&サーバー向けCPUが、Larrabee NIを実装した場合、最初の世代のLarrabeeチップ向けに書かれたコードを実行することができるだろう。Intelは、基本的にはこの方法でIA-32/Intel 64アーキテクチャを発展させ成功して来た。その構図を、スループットコンピューティングにも持ち込むことがLarrabeeとLarrabee NIの目的だと推測される。
しかし、命令セットの統一性はCPU実装によっての制約でもある。Intelなどx86系CPUは、x86命令セットの呪縛のために、非常に複雑で規模の大きな命令デコーダや、レジスタ数の少なさによるキャッシュ帯域圧迫といった、CPU実装上の困難を抱え込んでいる。同じことが、今後のベクタ拡張でも発生する可能性がある。命令セットアーキテクチャも一新した方が、より最適化したCPUを作ることができる。
Intelの命令アーキテクチャ拡張の戦略が見えてくる、IntelのLarrabee NI。最大の疑問は、Intelが最初の製品であるLarrabeeをうまく立ち上げることができるかどうか。それが、Intelのベクタ拡張戦略の今後を占う重要なカギとなる。
□関連記事
【10月6日】【海外】CPUに統合できるLarrabeeアーキテクチャ
http://pc.watch.impress.co.jp/docs/2008/1006/kaigai470.htm
【8月22日】【海外】正式発表されたLarrabeeアーキテクチャ
http://pc.watch.impress.co.jp/docs/2008/0822/kaigai461.htm
【8月19日】【海外】LarrabeeがPentiumをベースにしたのはなぜか
http://pc.watch.impress.co.jp/docs/2008/0819/kaigai460.htm
【8月11日】【海外】Cell B.E.と似て非なるLarrabeeの内部構造
http://pc.watch.impress.co.jp/docs/2008/0811/kaigai458.htm
【8月4日】【海外】ついにベールを脱いだIntelのCPU&GPUハイブリッド「Larrabee」
http://pc.watch.impress.co.jp/docs/2008/0804/kaigai457.htm
(2008年10月17日)
[Reported by 後藤 弘茂(Hiroshige Goto)]
【PC Watchホームページ】
PC Watch編集部 pc-watch-info@impress.co.jp ご質問に対して、個別にご回答はいたしません
Copyright (c) 2008 Impress Watch Corporation, an Impress Group company. All rights reserved.