 |


■後藤弘茂のWeekly海外ニュース■ついにベールを脱いだIntelのCPU&GPUハイブリッド「Larrabee」 |
●DirectX 10世代GPUよりCPUに近い構造
Intelがスループットプロセッサ「Larrabee (ララビー)」の概要を公開した。一言で言えば、Larrabeeは、GPUとCPUのハイブリッドだ。NVIDIAの「G80(GeForce 8800」以降や、AMD(旧ATI)の「Radeon HD 2900(R600)」以降の、最新のDirectX 10世代プログラマブルGPUと較べても、Larrabeeの方がよりプログラム性が高い。グラフィックス専用の固定機能ユニットも備えるが、NVIDIAやAMDと較べるとずっと比率が小さく、フルプログラマブルに近いプロセッサとなっている。DirectX 10世代GPUより、さらに汎用コンピューティングへと大きく振ったのがLarrabeeだ。もっとも、Intelは、Larrabeeをまずグラフィックス向け製品としてスタートする。
Larrabeeは、10個のx86上位互換のプロセッサコアを搭載する。各プロセッサコアは、16-wideのSIMD(Single Instruction, Multiple Data)構成のベクタ演算ユニットを備える。1ユニットで、32-bit単精度浮動小数点演算なら、16個のデータに対する演算を並列に1クロックで行なうことができる。
CPUコアはインオーダ実行で、2命令発行/クロック。Intelは、Pentium相当と説明する。ただし、Pentiumにはない、ワイドなSIMDユニットを備えるほか、ハードウェアマルチスレッド機能や、積和算命令(Fused Multiply Add(FMA)、ベクタ型のプロセッシングに特化した機能などを備える。
10個のCPUコアは、双方向の高速リングバスに接続されている。バスには10個のプロセッサのほか、外部インターフェイス、メモリコントローラ、テクスチャユニット、その他の固定機能ユニットなどが接続されている。また、4MBのL2キャッシュメモリも搭載されており、各プロセッサコア毎にパーティションで区切られている。
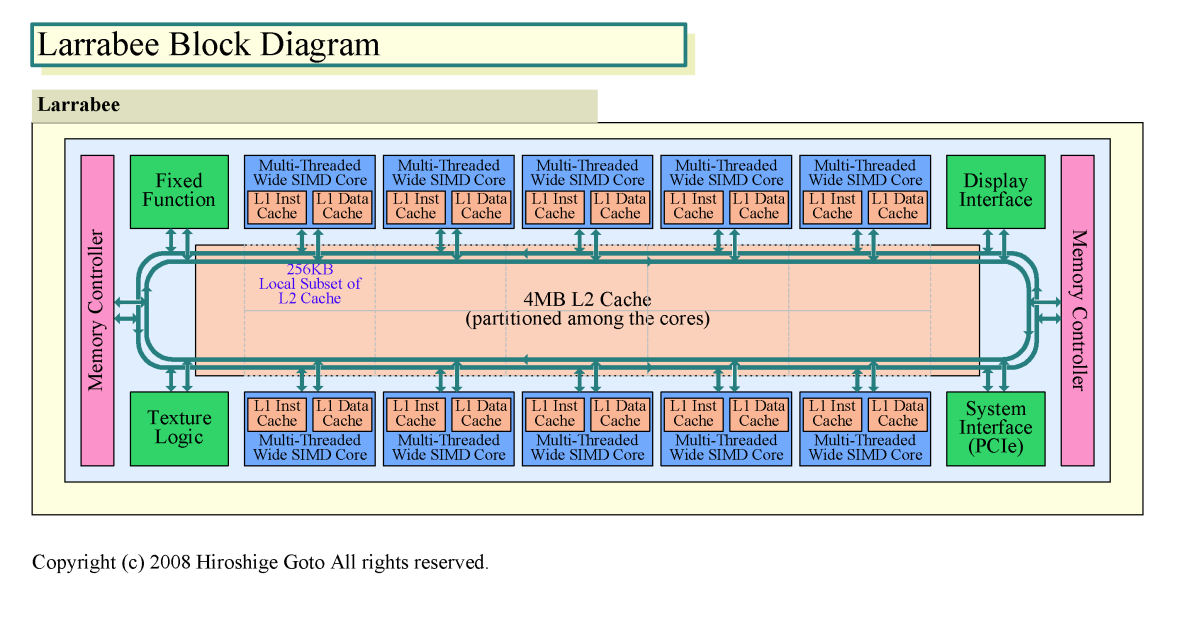 |
| Larrabeeのブロックダイヤグラム PDF版はこちら |
●32-bit単精度で16-wideのワイドなベクタ演算ユニット
キャッシュ階層は2階層で、統合L2キャッシュのほかに、各プロセッサに32KBのL1命令キャッシュと32KBのL1データキャッシュが搭載されている。Larrabee全体で、キャッシュコヒーレンシを保つ。また、L2キャッシュには各プロセッサコアが相互アクセスできるため、コア間のデータ交換や共有に使うことができる。NVIDIAもAMDも、GPUのプロセッサコア間でのデータ交換のために小容量のメモリを備えるが、GPU全体にまたがるハードウェアでのキャッシュコヒーレント機構などは持たない。Larrabeeは、現在のプログラマブルGPUと較べても、ずっとCPU寄りの設計だ。
Larrabeeのプロセッサコアは、インオーダ実行でスカラユニットとベクタユニットの2実行パイプを備える。それぞれ専用のスカラレジスタと、ベクタレジスタを持つ。CPUコアは、L2キャッシュのうち、256KBのローカルサブセット(Local Subset)と直接続されている。プロセッサコア間のコミュニケーションは、リングバスを経由する。
Larrabeeプロセッサの核と言えるベクタ演算ユニットは、16-wide構成となっている。データタイプは、Int32(32-bit整数)、Float32(32-bit浮動小数点)、Float64(64-bit浮動小数点)をサポートする。32-bit時に16-wideのフルスループットで演算ができる。ベクタプロセッサでは、演算する各データ要素のそれぞれで、条件分岐によるプログラムの分岐が生じた場合に効率が悪い。Larrabeeでは、マスクレジスタを備えることで、分岐が生じた場合も、比較的効率がいいフローコントロールが可能になるようにした。この機構は、NVIDIAのG80/GT200系などが備えている機構と似ている。
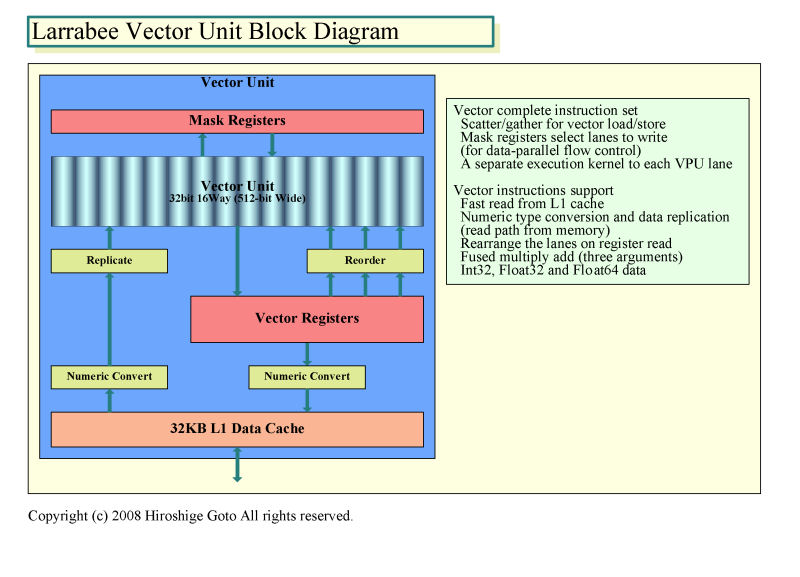 |
| Larrabeeベクタユニットのブロックダイヤグラム PDF版はこちら |
 |
| Larrabee x86コアのブロックダイヤグラム PDF版はこちら |
●固定ハードウェアを極力省いたプログラマブルプロセッサ
一般的なGPUと較べた場合の、Larrabeeパイプラインの最大の特徴は、固定ハードウェア(Fixed Function Hardware)をできる限り排除し、ほぼフルプログラマブルなプロセッサを作り上げたことだ。現在のGPUは、頂点情報をピクセルに変換するまでの、プリミティブセットアップ/ラスタライゼーションは、固定機能ハードウェアで処理している。また、テクスチャフィルタリングなどを行なう専用プロセッサや、カラーやZ処理を行なうレンダーバックエンド、またはROP(Raster Operation Processor)と呼ばれる固定ハードウェアも備える。
Larrabeeでは、このうちテクスチャ関連の専用回路は備えるが、それ以外の固定機能ユニットはほとんどを取り去った。固定機能ユニットで実行していた処理は、プログラマブルなプロセッサでソフトウェア処理を行なう。通常のGPUより、さらに数段ソフトウェア化が進んでいるのがLarrabeeだ。
これは、MicrosoftがDirectX 10以降のハードウェアのトレンドとして考察していた方向と一致する。Microsoftは、徐々に固定機能ハードウェアがプログラマブルプロセッサでのソフトウェアに置き換わって行く傾向にあると見ていた。Microsoft自身は、効率性を考慮した場合、どこまで置き換わるかが不明だとしていた。Intelは踏み込んで、一気にほとんどのパートをプログラマブル化した。一般的なGPUより、よりフレキシブルなハードウェアだが、その分、効率性が問われることになる。
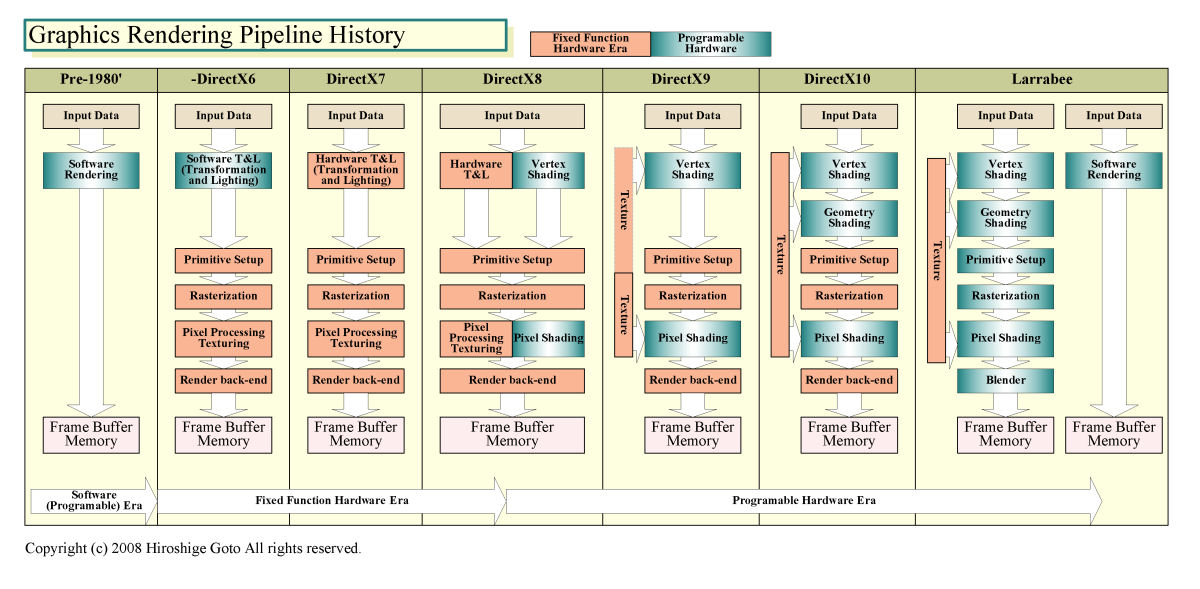 |
| 世代ごとのグラフィックスレンダリングパイプラインの変遷 PDF版はこちら |
●GPUとは異なるプログラミングモデル
Larrabeeでは、ソフトウェアスタックの構造も従来のGPUと異なる。ほとんどのGPUでは、ネイティブ命令セットへのコンパイルを初め、大半のソフトウェア処理をホストCPU側で行なう。それに対して、Larrabeeでは、Larrabee自体の上でマイクロOSが走っており、従来GPUならホストCPU上のドライバで行なっていたような処理を、Larrabee上で行なう。
これも、GPUの今後の方向性と一致している。AMDはすでに、R600世代から汎用的なマイクロコントローラをGPU側に搭載。ドライバの処理の一部をGPU側に移した。NVIDIAも、「GPU上でドライバを走らせるのは、この先の話だ」(David B. Kirk(デビッド・B・カーク)氏(Chief Scientist))と、同様の方向を考えていることを示唆している。よりプログラマブルなLarrabeeは、トレンドを先取りしているとも言える。
Larrabeeは、プログラミングモデルの面でも、プログラマブルGPUと大きく異なる。それは、「Single Program, Multiple Data(SPMD)」モデル以外のプログラミングモデルを用意する点だ。
GPUのSPMD(Single Program, Multiple Data)モデルでは、1データに対するプログラムを書くと、プログラムが自動的に展開され、SIMDハードウェアの上でマルチスレッド実行される。例えば、1ピクセルを扱うシェーダプログラムを書くと、自動的に何百万ものピクセルに対して実行される。プログラム側では、GPUハードウェアのベクタ長を意識する必要がない。ランタイムソフトウェア(ドライバ)が、SPMDモデルでのSIMDの制御を行なう。GPUでは、グラフィックス以外の汎用アプリケーションもSPMDモデルでプログラムする手法が一般的だ。
それに対して、汎用のCPUではSIMDハードウェアに直接アクセスできるようにするのが一般的だ。例えば、x86系CPUでは、SSEなどのSIMD命令で、SIMDハードウェアを直接扱うことができる。Larrabeeでは、「Larrabee Native C/C++」を通じて16 wayのSIMDを直接扱うことができる。言い換えれば、ベクタ長が露出している。Intelは、LarrabeeのネイティブISAを公開するとは言っていないが、SPMD以外のプログラミングモデルを提供する点は大きく異なる。
もっとも、Larrabeeで汎用アプリケーションをプログラムする場合に、16way SIMDを必ず明示的にプログラムしなければならないかというと、そうでもない。C/C++以外に、汎用コンピューティングをSPMDモデルで実現する道も用意する。例えば、DirectX 11で導入される汎用コンピューティング向けシェーダステージ「DirectX 11 Compute Shader」をサポートするという。
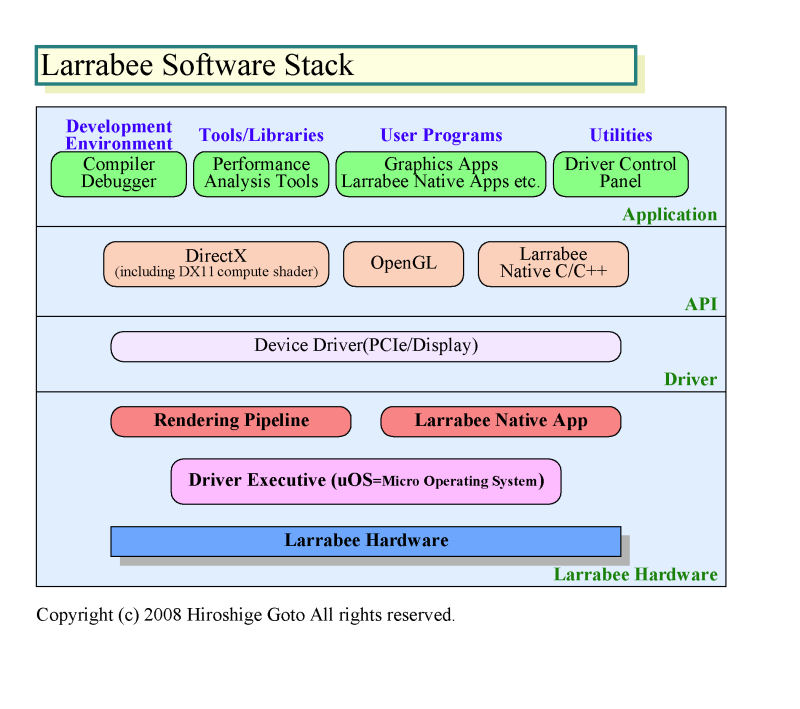 |
| Larrabeeのソフトウェアスタック PDF版はこちら |
□関連記事
【7月16日】【海外】Larrabeeに追われるNVIDIAがGT200に施したGPGPU向け拡張
http://pc.watch.impress.co.jp/docs/2008/0716/kaigai453.htm
【4月7日】【海外】x86からの脱却を図るIntelの新ロードマップ
http://pc.watch.impress.co.jp/docs/2008/0407/kaigai434.htm
【4月3日】【IDF】「Peta FLOPsからミリワットまでカバーするIA」
http://pc.watch.impress.co.jp/docs/2008/0403/idf02.htm
【2007年10月12日】【海外】MIMDのLarrabeeとSIMDのGPUの戦い
http://pc.watch.impress.co.jp/docs/2007/1012/kaigai393.htm
(2008年8月4日)
[Reported by 後藤 弘茂(Hiroshige Goto)]
【PC Watchホームページ】
PC Watch編集部 [email protected] ご質問に対して、個別にご回答はいたしません
Copyright (c) 2008 Impress Watch Corporation, an Impress Group company. All rights reserved.