 |


■後藤弘茂のWeekly海外ニュース■LarrabeeがPentiumをベースにしたのはなぜか |
●ポラックの法則のためPentiumに戻ったLarrabee
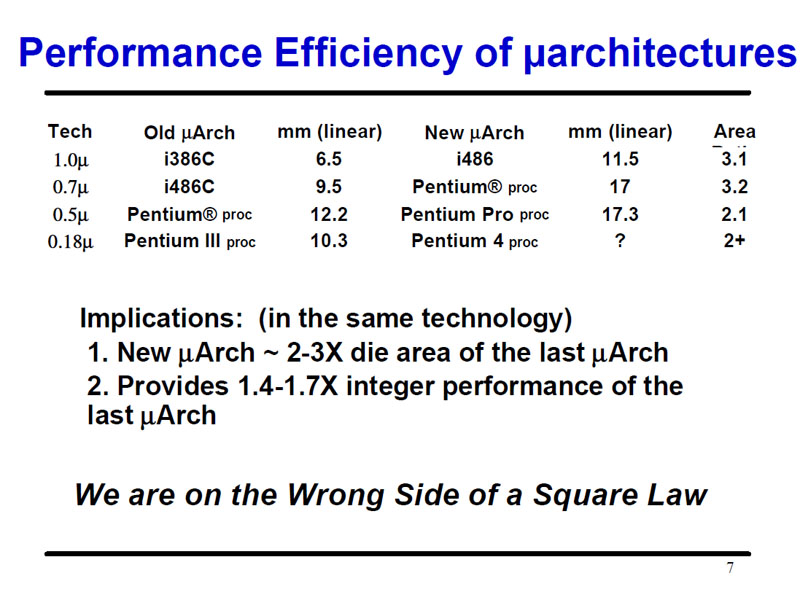
IntelのLarrabee(ララビー)はPentiumを源流としている。オリジナルPentiumとは似ても似つかないように見えるが、基本構成にはよく似た部分がある。IntelがPentiumまでCPUコアのマイクロアーキテクチャを巻き戻した理由は、以前の記事で説明した通り『ポラックの法則(Pollack's Rule)』のためだ。
同法則では、同じプロセスで、CPUのサイズを2~3倍にしても、CPUの整数演算性能は約1.4~1.7倍(前回記事の初出時は1.5倍からとなっていた。訂正する)くらいしか伸びないとされている。CPUの複雑度を上げても、整数演算性能は平方根程度にしか向上しない。逆を言えば、CPUの複雑度を下げると、CPUの整数演算性能は落ちるが、それ以上に電力効率がアップする。そのため、CPUの電力効率を上げて、同じ電力枠の中で性能を伸ばそうとすると、CPUの世代を巻き戻して、CPUの複雑度を下げることは当然の流れとなる。
特に、PentiumのIn-Order実行デュアルイシューという構成は、現在のCPUではスィートスポット的な位置にある。PC向けCPUのように整数演算の絶対性能を追求する分野は別だが、それ以外のハイパフォーマンスCPUは、In-Order実行デュアルイシューへと収束する気配を見せているからだ。もう1つ加えるなら、In-Order実行デュアルイシュー+ハードウェアマルチスレッディングだ。ちなみに、Larrabeeの場合はスカラ命令ストリームはデュアルイシューだと明記されているが、ベクタ命令を2つのスカラ命令と同時発行できるかどうかは今のところわからない。しかし、2命令以上をデコードしようとすると、命令デコーダが複雑になるため、おそらくベクタパイプも含めてデュアルイシューだと推定される。
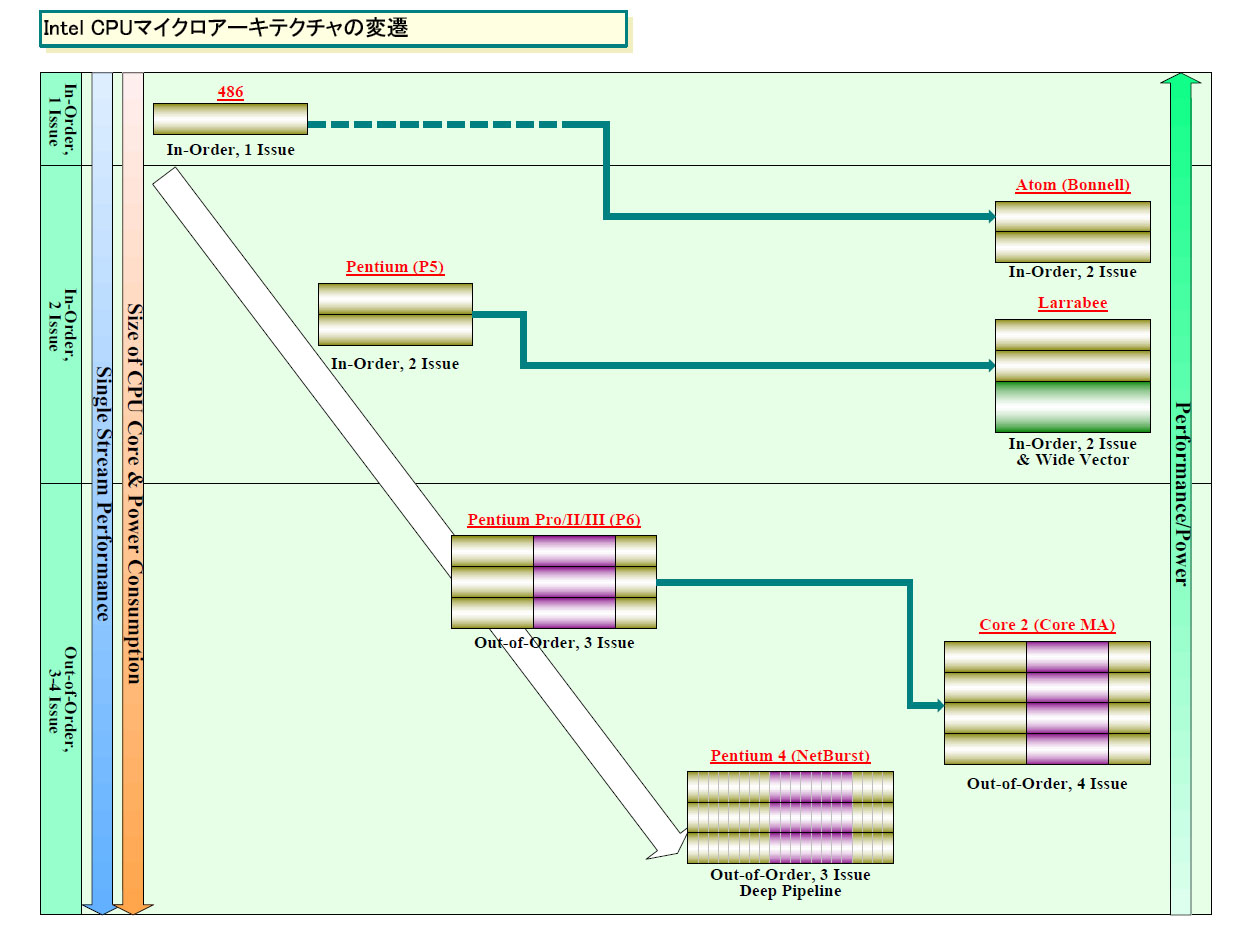
In-Order実行デュアルイシュー+マルチスレッディングが興隆していることは、最近のCPUを見るとわかる。例えば、IntelのAtom(Bonnell:ボンネル)コアは、最も効率が高いIn-Order実行シングルイシューからアーキテクチャの検討をスタートして、In-Order実行デュアルイシュー+マルチスレッディングに落ち着いた。Cell Broadband Engine(Cell B.E.)やXbox 360のXenon CPUもIn-Order実行デュアルイシュー+マルチスレッディング(Cellの場合はPPEがマルチスレッディング)だ。PC向けCPUは、整数演算性能を落とすことができないため、Out-of-Order実行3~4イシューにこだわるが、その必要がない世界では、In-Order実行デュアルイシュー+マルチスレッディングがスタンダードになりつつある。そして、Larrabeeもその波に乗っている。
 |
| 『ポラックの法則(Pollack's Rule)』 ※PDF版はこちら |
 |
| Intel CPUアーキテクチャの変遷 ※PDF版はこちら |
●プライマリパイプとセカンダリパイプに分かれたLarrabeeのスカラユニット
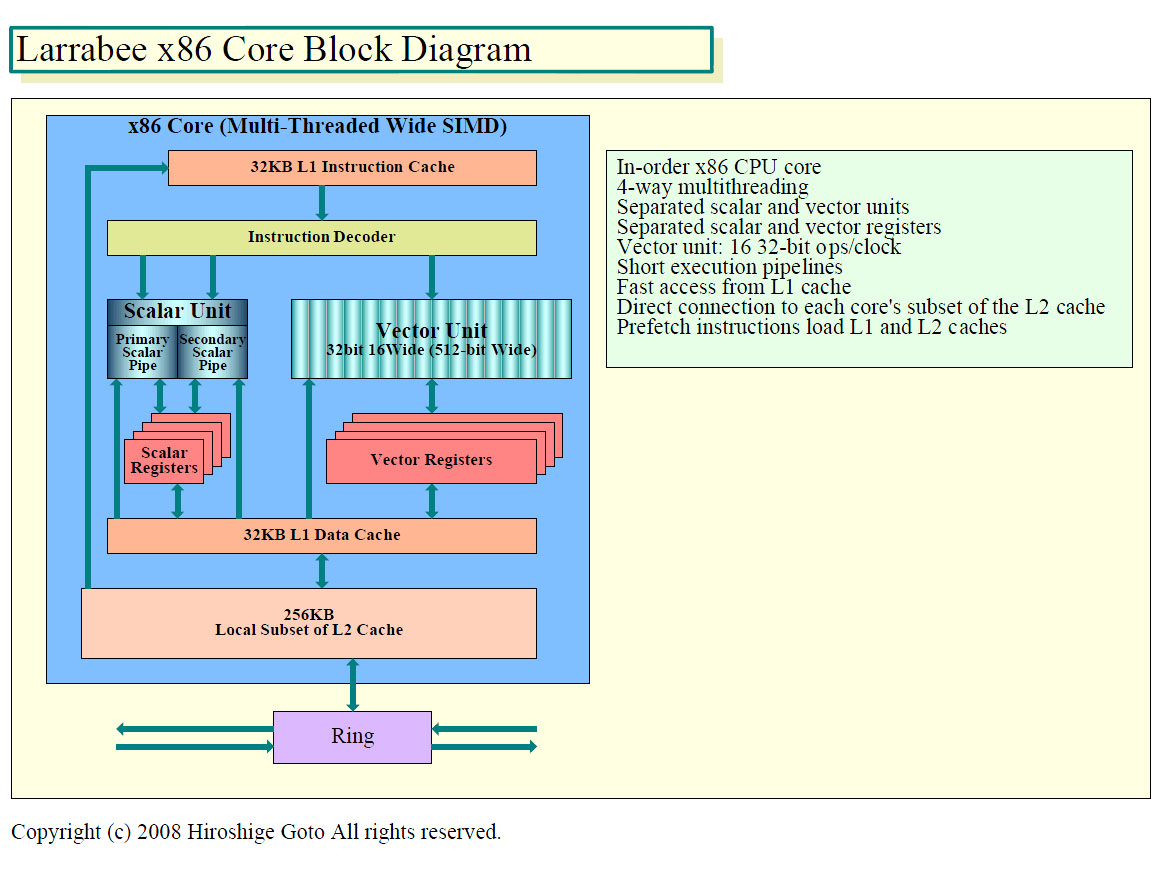
Larrabeeのx86 CPUコアには、スカラ演算ユニットとベクタ演算ユニットがある。このうち、スカラ演算ユニットは、Pentiumの面影を色濃く残している。Pentiumと同様に、パイプライン段数が浅く、コストの低い(トランジスタ数の少ない)パイプライン構成だという。すでに伝えたように、命令デコーダは、Pentium命令セットをフルサポートする。そのため、OSカーネルやアプリケーションなどの既存のコードを走らせる、あるいは簡単に移植することができる。
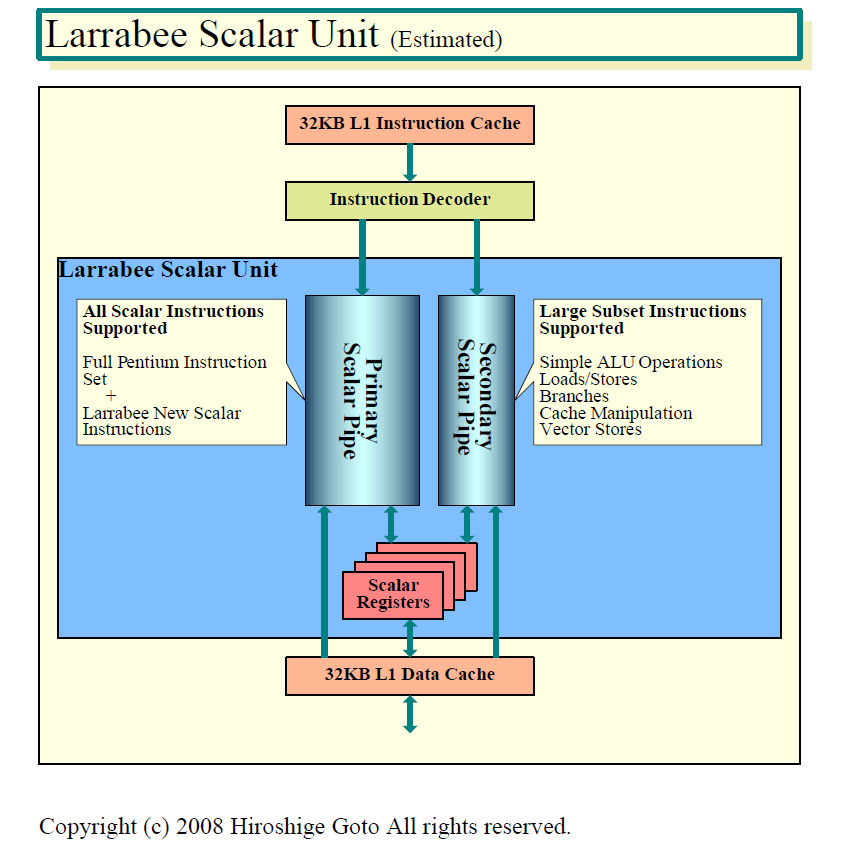
スカラユニット部分は、Pentiumと同様にデュアルパイプラインとなっている。2つのパイプは、プライマリパイプとセカンダリパイプとして非対称の構成を取っている。非対称のパイプ構成にしたのは、In-Order実行のLarrabeeでは、命令ペアリングが限られるためだという。
命令をそのままの順序で実行するIn-Order実行の場合、連続した命令が並列実行できなければペアリングできない。コンパイル時に静的なスケジューリングを行なってペアリングできるように命令を並べるが、命令を動的に並べ替えるOut-of-Order実行と較べると並列実行に制約があり、毎サイクルに2命令を発行できるとは限らない。
Larrabeeではプライマリパイプはフル機能を備えるが、セカンダリパイプはサブセットとして機能を削った小型のユニットとしている。そのため、2命令発行の頻度が小さくてセカンダリパイプが遊ぶケースが多くても、無駄になるトランジスタと消費電力は小さくて済む。電力効率的に有利な構造が、非対称の2パイプ構成だ。
Larrabeeの場合、プラマリパイプはすべてのスカラ命令を実行できる。フルPentium命令セットに加え、ビットカウント/ビットスキャン、キャッシュ制御といったLarrabeeの新命令も全て実行できる。プライマリパイプは完全セットであるため、コンパイラは、命令によって2つのパイプを使い分ける必要がなく、コンパイルもシンプルになる。
セカンダリパイプは、プライマリパイプのような完全なパイプではなく、サブセットだが、広汎な命令を実行できるという。シンプルなALUオペレーション、ロード/ストア、分岐、キャッシュ制御、ベクタストアといった命令の実行が可能だ。実装コストがかかる複雑な命令は省くが、シンプルなオペレーションは網羅したイメージだ。そのため、命令ペアリングができる可能性は高いという。
図中でスカラレジスタが4面あるのは、Larrabeeが4-wayのハードウェアマルチスレッディングをサポートしているからだ。レジスタファイルはそれぞれのスレッド用に4つ用意されている。ただし、In-Order実行のLarrabeeでは、レジスタリネーミングは行なわないと見られるため、物理レジスタ数は論理レジスタ数と同じで、レジスタのサイズは小さいと推定される。32KBのL1命令キャッシュとL1データキャッシュ、命令デコーダはベクタユニットと共用。キャッシュサイズが32KBなのは、ハードウェアマルチスレッディングをサポートしたことで8KBづつのPentiumを4倍化したためだという。
 |
| Larrabee x86 Core Block Diagram ※PDF版はこちら |
 |
| Larrabee Scalar Unit Block Diagram ※PDF版はこちら |
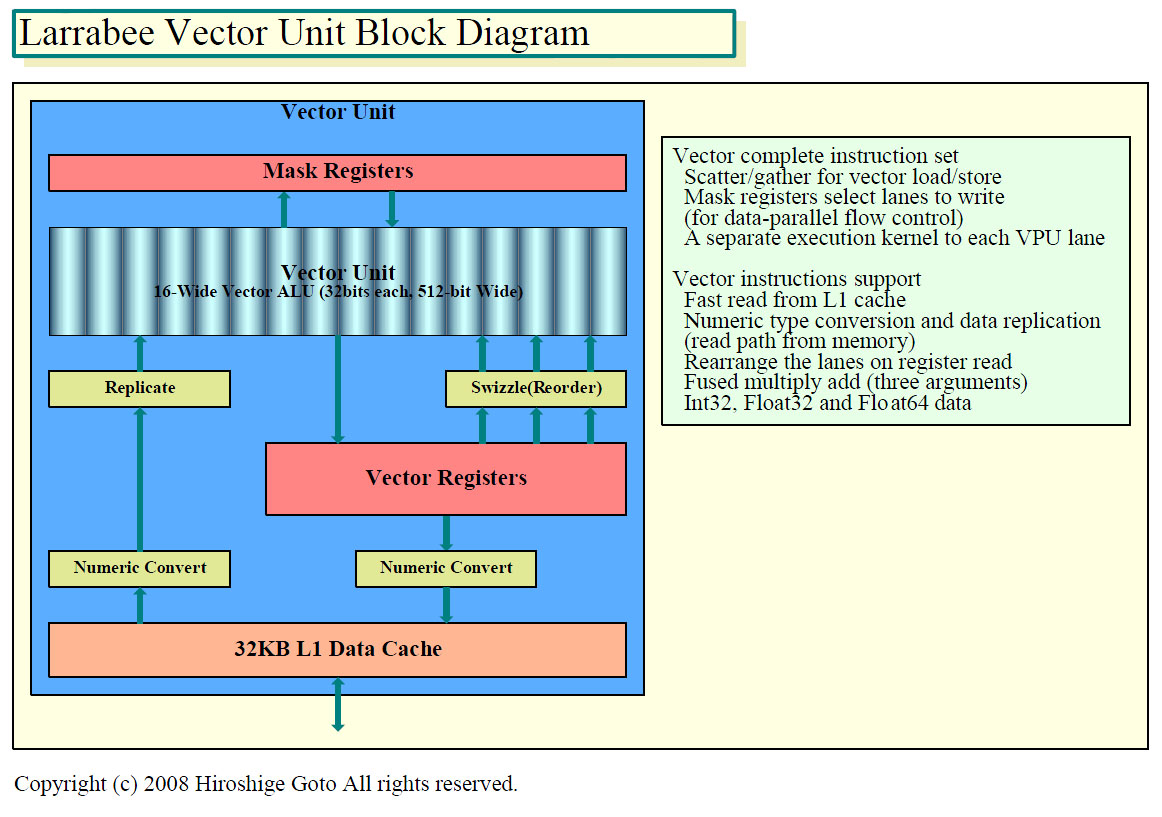 |
| Larrabee Vector Unit Block Diagram ※PDF版はこちら |
●相対的に強力なスカラ演算能力の意味するもの
Larrabeeのスカラユニットを見ると明瞭なのは、Larrabeeのx86 CPUコアがそれなりのスカラ演算能力を持っていることだ。同じIn-Order実行デュアルイシューのAtom(Bonnell:ボンネル)コアと、シングルストリームの整数演算の性能は、原理的には同じ水準になる。実際には、BonnellつまりSilverthorne(シルバーソーン)は、整数演算性能を高めるために様々な工夫が凝らされてるため、Larrabeeの方が周波数当たりのスカラ性能は落ちる可能性が高い。それでも、Pentiumを高クロック化して2GHz台で動作させた程度のスカラ性能は得られそうだ。
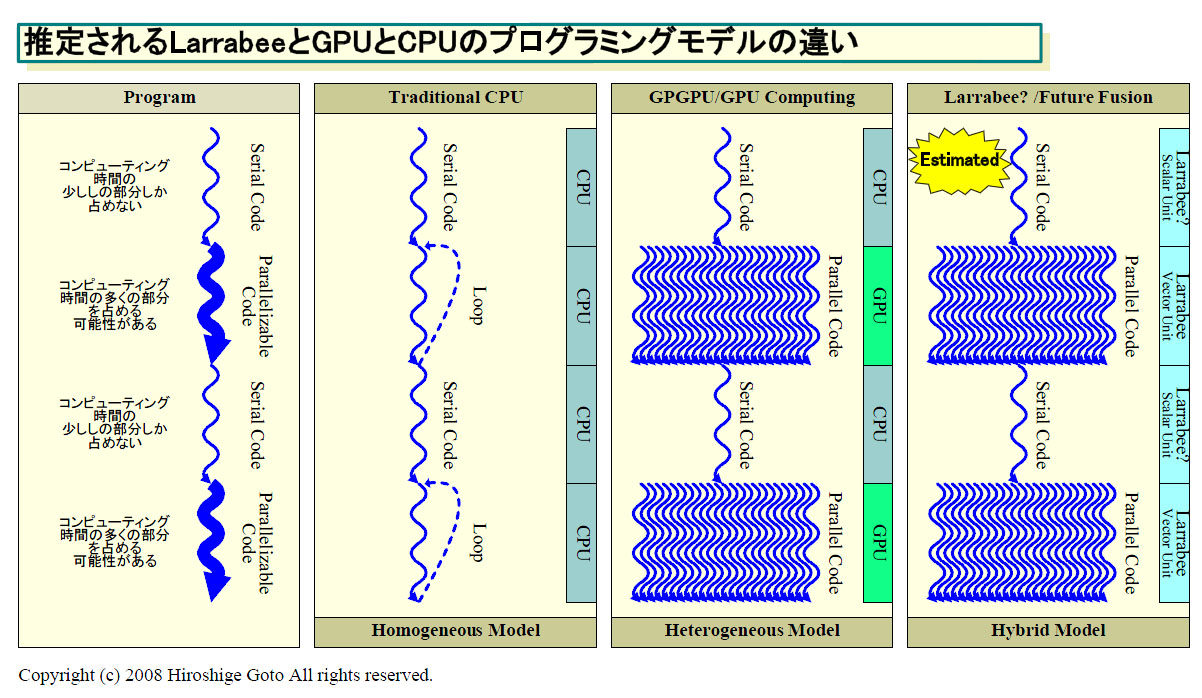
性能的に比較的強力で、しかもベーシックなx86命令が通るスカラユニットを備えたLarrabeeの構造は、グラフィックスよりも汎用コンピューティングで力を発揮すると考えられる。なぜなら、プログラム中のシリアルコード部分とパラレルコード部分の両方を、同じプロセッサで実行することが可能になるからだ。もし、Larrabeeのスカラユニットが、そうした発想で作られているとしたら、基本的なアイデアはAMDのFUSION構想に近い。AMDのFUSIONも、シリアルコードとパラレルコードを、1つのプロセッサ、1つのメモリの中で走らせるという構想を持っているからだ。
例えば、NVIDIAのCUDAの場合、プログラムの中でシリアルに実行しなければならないコード部分はCPUで走らせ、並列化が可能なコード部分だけ抜き出してGPUにカーネルプログラムとしてダウンロードするスタイルを取る。こうしたスタイルは、GPU上での汎用コンピューティングに共通している。ホストに汎用CPUがあることを前提とした、ヘテロジニアス(Heterogeneous:異種混合)タイプのコンピューティングスタイルだ。
GPUが実行するパラレルコードは、通常のCPUではループで処理していたような部分だ。マトリックス処理のように同じ処理を大量のデータに対して行なう部分を、GPU上の多数のプロセッサで並列に行なう。ループで膨大なサイクルをかけていた処理を、並列化してしまうので、全体の性能がグンと上がるという発想だ。
通常、こうした並列化が可能な部分は、プログラム中でコンピューティング時間の大半を占めているため、GPUで並列化することでスピードアップを見込むことができる。問題は、CPU側のメモリとGPU側のメモリの間のデータ転送や、GPUでのベクタ処理のためのセットアップのレイテンシがあることだ。しかし、高速化できるパラレルコード部分が大きければ、全体で見ると処理が速くなるというのが、GPU上での汎用コンピューティングの発想だ。
 |
| 推定されるLarrabeeとGPUとCPUのプログラミングモデルの違い ※PDF版はこちら |
●シリアルコードとパラレルコードの両方を走らせる?
GPU上での汎用コンピューティングでは、CPUでシリアルコード、GPUでパラレルコードと役割分担を行なう。Larrabeeも、そうしたスタイルを取ることが可能(Larrabeeライブラリでホストとの同期のためのプロトコルを提供する)だが、シリアルコードをLarrabee側で実行することも可能だと推定される。もちろん、シリアルコードが複雑で長ければ、LarrabeeのCPUコアを占有する時間が長くなり無駄が発生してしまい現実的ではない。しかし、一部のシリアルコードはLarrabee側で実行できそうだ。
Larrabeeでこうしたシリアルコードとパラレルコードのミックススタイルを取ることができるなら、汎用コンピューティングでは利点がある。GPU上での汎用コンピューティングの弱点の1つが、そこにあるからだ。
GPUでの汎用コンピューティングのスタイルは、パラレルコード部分の粒度が大きいほど有効だ。GPUにいったんデータを転送したら、GPUが膨大な並列処理を行ない、それが終わったらCPUに返す。データトランスファとセットアップに一定の時間が必要となるため、GPUの実行するパラレルコードが大きくないとオーバーヘッドが大きくなる。例えば、シリアルコードと短くて粒度の小さなパラレルコードが入り組んだプログラムでは、オーバーヘッドで性能が発揮できない可能性が出る。
AMDのCTOだったPhil Hester(フィル・へスター)氏は、CTO当時の昨年のインタビュで「GPUで実行できるコード部分の粒度が小さく、CPUでシリアルに実行しなければならない部分とミックスされていると、セットアップなどで性能アップが相殺されてしまう。そこが問題だ。CPUとGPUを密接に統合するのは、そうした問題を解決するためだ」と語っていた。
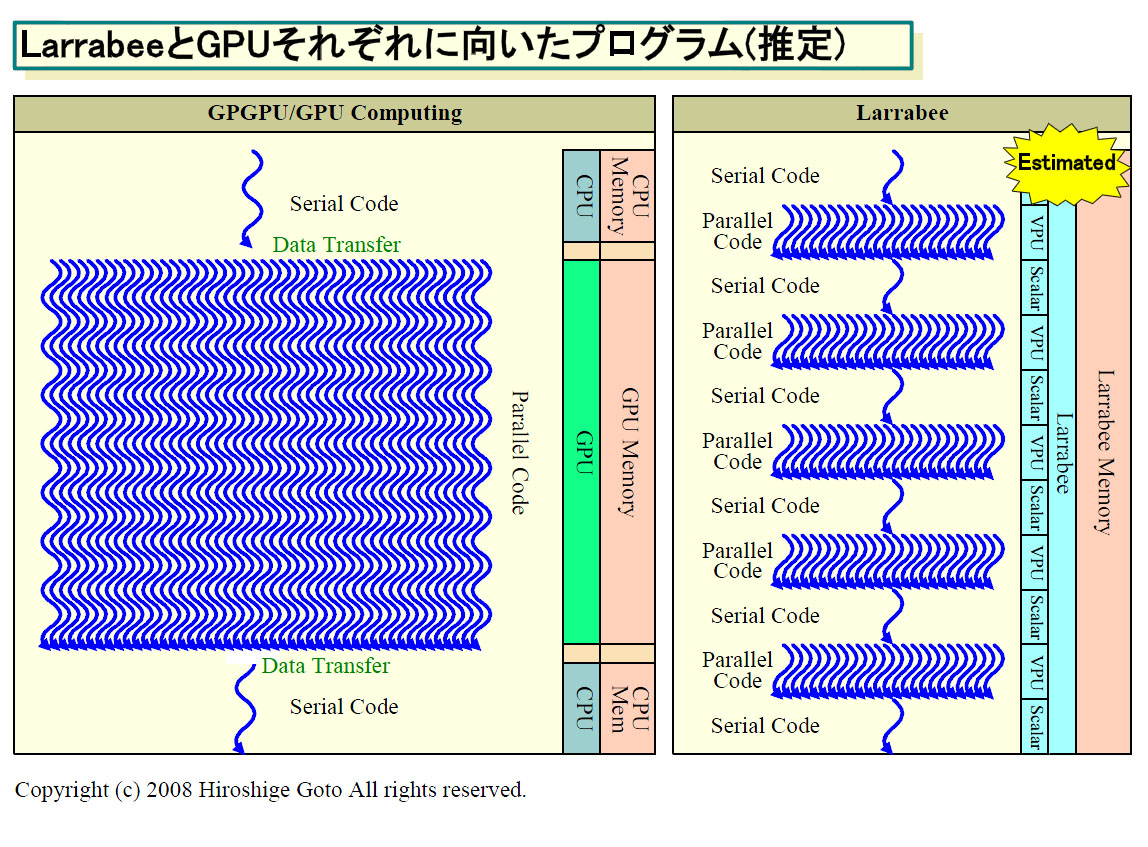
つまり、GPUコンピューティングの問題点は、常にどんなプログラムでも性能アップを見込めるわけではないことにある。GPUに適した、パラレルコード部分の粒度が大きなプログラムでないと性能を発揮できない。それを根本から解決しようとすると、シリアルコードをGPU側で実行する必要がある。しかし、GPUの現状のシリアル命令ストリームの実行性能は低いため、そうした用途には適さない。そのため、シリアルコードの実行に適したプロセッサをGPUに搭載する必要がある。
AMDがロングタームで構想しているのは、まさにこれだ。AMDの場合、将来バージョンのFUSION(最初のバージョンは異なる)では、PC向けCPUとGPUの両コアが密接に結合し、シリアルコードとパラレルコードが入り組んだプログラムも高速に実行できるようにする。
IntelのLarrabeeも、ある程度は同じ路線にあると考えられる。つまり、シリアルコードのある程度の部分はLarrabeeで実行できるようにして、パラレルコードの粒度がより小さなプログラムも、高速に実行できるようにすると推定される。これについては、まだLarrabee関連の説明で明記されていないため、不明な部分があるが、可能性は高いと考えられる。だとすれば、Larrabeeは、汎用化した現在のGPUより、高速化できるアルゴリズムを選ばない、より汎用のアーキテクチャになると考えられる。
 |
| LarrabeeとGPUそれぞれに向いたプログラミム ※PDF版はこちら |
●ストリームプロセッシングに最適化したキャッシュ制御
この他、Larrabeeのスカラ命令で特徴的なのはキャッシュ制御関連の命令とモードだ。以前の記事でも触れたが、Larrabeeの内部メモリは、フルにコヒーレントを取るキャッシュメモリだ。これは、コヒーレントをハードウェアで取らず、明示的に制御するスクラッチパッドメモリを搭載するGPUやCell Broadband Engine(Cell B.E.)との大きな違いとなっている。GPUなどがこうしたメモリ構成を取っているのは、ストリームプロセッシングでは、キャッシュ制御は意味を持たず、リードバッファの方が向いているからだ。
Larrabeeでは、明示的なキャッシュ制御を行なうことで、コヒーレントを保つキャッシュをスクラッチパッドのように使う方法を導入した。まず、Larrabeeでは、L2キャッシュとL1キャッシュのそれぞれにデータを先読みするプリフェッチ命令を備える。さらに、命令モードの設定が可能で、それによって取り込んだキャッシュラインのプライオリティを下げることができる。プライオリティの制御は、ストリーミングプリフェッチを行ないながら、キャッシュの効率を高めるためだ。
プリフェッチによって、ストリーム処理のためのデータをどんどんキャッシュに取り込むと、問題が発生する。CPUコアに読み出してしまえば、不要になるストリーミングデータのために、本来キャッシュに止めておきたい再利用可能性の高いデータが追い出されてしまうからだ。そこで、Larrabeeでは、ストリーミングキャッシュラインをマークして、そのラインのプライオリティを下げる。キャッシュライン単位で、ストリーム処理のためのデータが、コアからのアクセス後に早期に追い出せるように制御する。
ちなみに、ストリームプロセッシングに最適化されたXbox 360 CPUの場合、「データキャッシュブロックタッチ(xDCBT:Data Cache Block Touch)」命令でプリフェッチを行なっていた。データは、L2キャッシュをバイパスしてメインメモリからL1データキャッシュに直接取り込まれ、L2キャッシュに再利用しないデータがキャッシングされることを防いでいる。L1データキャッシュはライトスルーモードになっている。
Larrabeeのスカラユニットは、LarrabeeがGPUとは異なる発想で作られていることを明瞭に示している。OSを走らせることができる柔軟性と性能を備えたLarrabeeのスカラユニットは、LarrabeeとGPUを分ける大きなポイントとなるだろう。
□関連記事
【8月11日】【海外】Cell B.E.と似て非なるLarrabeeの内部構造
http://pc.watch.impress.co.jp/docs/2008/0811/kaigai458.htm
【8月4日】【海外】ついにベールを脱いだIntelのCPU&GPUハイブリッド「Larrabee」
http://pc.watch.impress.co.jp/docs/2008/0806/tawada148.htm
(2008年8月19日)
[Reported by 後藤 弘茂(Hiroshige Goto)]
【PC Watchホームページ】
PC Watch編集部 pc-watch-info@impress.co.jp ご質問に対して、個別にご回答はいたしません
Copyright (c) 2008 Impress Watch Corporation, an Impress Group company. All rights reserved.