 |


■後藤弘茂のWeekly海外ニュース■AMD初のモバイル専用CPU「Griffin」の正体 |
●モバイルとデスクトップに分化するAMDのCPU
AMDのモバイルCPUの今後が見えてきた。AMDは2008年に、モバイル向けに特化した設計の「Griffin(グリフィン)」を投入。2009年にはGPUを統合した「FUSION(フュージョン)」プロセッサの最初のバージョンをモバイルに投入する。AMDのMaurice B. Steinman(モーリス・B・スタインマン)氏(AMD Fellow, Computing Products Group, AMD)は、5月22/23日に開催されたMicroprocessor Forumと、会場で行なわれたインタビューでGriffinの概要とサンプルチップを公開。また、FUSIONプロセッサに向けたステップについても語った。
 |
 |
| Griffinのサンプルチップ | AMDのMaurice B. Steinman(モーリス・B・スタインマン)氏 |
GriffinはAMDの次のデュアルコアモバイルCPUだ。65nmプロセスで製造され、Rev. Gとほぼ同じCPUコアに、新設計のノースブリッジ、デュアルチャネルDDR2メモリインターフェイス、HyperTransport 3インターフェイスを備える。キャッシュは各コア1MBずつの専用L2キャッシュ。概要は先週AMDが公開した通りで、AMDとしては初めてのモバイルに最適化して設計されたCPUとなる。IntelがモバイルCPUとデスクトップCPUと同一アーキテクチャに統合したのとは対照的に、AMDはモバイルとデスクトップにCPUアーキテクチャを分化させる。
上の写真がGriffinのサンプルチップだ。このサンプルを見る限り、ダイサイズ(半導体本体の面積)は概算で160平方mm弱に見える。下の図のように、AMDのメインストリームCPUとしてはやや大きめのダイ(半導体本体)となる。昨年(2006年)、AMD関係者は「モバイルプロセッサ(Griffin)はダイもかなり小さくなる」と語っていたが、実際にはそれほど小さなCPUとは言えない。例えば、IntelのCore 2 Duo(Merom:メロン)は65nmプロセスで4MB版が143平方mmとなっている。ちなみに、CPUにGPUコアを統合したFUSIONの最初のバージョンは180平方mm程度になると言われている。
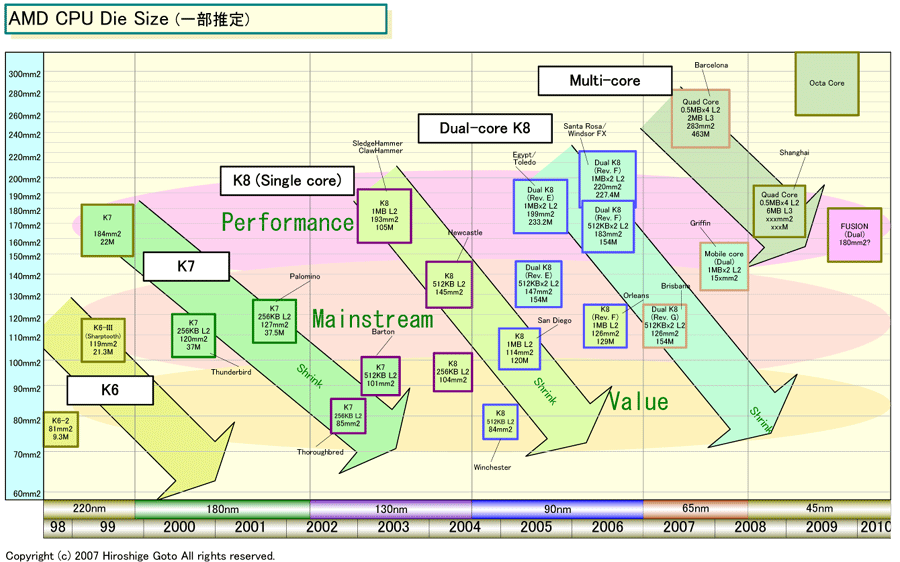 |
| AMD Die Size(一部推定)(※別ウィンドウで開きます) PDF版はこちら |
●計画時よりも大きなCPUになったGriffin
現在の製造プロセス技術では、微細化しても、リニアにはチップサイズが小さくならない。そのため、Griffinのダイが比較的大きいことは、必ずしも不思議ではない。しかし、よく見ると、Griffinではダイの特定のブロックが大型化しているようだ。
これは、Griffinの計画時と現在のダイ(半導体本体)レイアウトを比較するとよくわかる。下の図の右は、昨年6月にAMDが発表した時点のGriffinのダイレイアウト。左は、今回発表されたGriffinのダイレイアウトだ。
 |
| Griffinの計画時と現在のダイレイアウトの違い(※別ウィンドウで開きます) PDF版はこちら |
2つのレイアウトの違いは明瞭だ。CPUコアのサイズが同じだとすると、それ以外のブロックの面積が増えて、ダイが一回り大きくなっている。つまり、計画時点からシリコンが実際にできるまでの間に、ダイ上のCPUコア以外のコンポーネントが大きくなったことになる。もちろん、これから実際の製品化までにはマスクの変更が加わりまだダイが縮小する可能性もある。また、このダイレイアウトチャートとサンプルチップではチップの縦横比も合わない。そのため、正確には言えないが、参考にはなると思われる。
現在のGriffinのダイをよく見ると、まず、2個のCPUコアとL2キャッシュの間の部分、つまりノースブリッジとメモリ、I/Oコントローラとその配線部分の比率がぐっと大きくなっていることがわかる。ノースブリッジ回りの肥大化が、チップサイズの増加の一因となっている。
●I/O関係のブロックが肥大化する現在のCPU
なぜ、Griffinではノースブリッジチップ回りがこんなに拡大しているのだろう。アーキテクチャを担当したAMDのMaurice B. Steinman氏(AMD Fellow, AMD Computing Products Group)は次のように答える。
「いくつかの理由がある。1つは、HyperTransport 3のためだ。HyperTransport 3では、インターフェイスの転送スピードがぐっと上がるため、より多くのバッファリングが必要になる。バッファメモリのため面積は増えるが、ずっと広い帯域を実現していることを考慮して欲しい。バッファを増やさなければ、拡張した帯域をフルに保つことができず、バスがアイドルになってしまう。これはチップセット側の設計も同様だ。
もう1つの理由はモジュラーアプローチだ。このブロックには、HyperTransportリンクコントローラ、メモリコントローラ、ノースブリッジコアがある。これらモジュールの設計スタイルは、複数のバリエーションを迅速に開発するために若干異なっており、それほどカスタム化されていない。そのため、ある程度の、小さなエリアペナルティがある」
CPUでは、インターコネクトの高速化のために、CPU全体の中でI/O回りのユニットの占める面積が増えている。これは、現在のハイパフォーマンスCPUに共通する特徴で、その結果、CPUの中でCPUコアが占める面積比率はますます小さくなり、I/O回りの回路が占める面積比率がどんどん増えている。理由は、パフォーマンスボトルネックがコンピューティングよりデータの移動にあるケースが増えているからだ。CSIを搭載するIntelの「Nehalem(ネハーレン)」も、I/O回りの比率が増えていると推定される。最新のCPUで、I/O回りの回路規模を抑えてパフォーマンスを伸ばすことに成功した例は、ラディカルなRambusのアーキテクチャを採用したCell Broadband Engine(Cell B.E.)程度だ。
また、AMDはGriffin世代からモジュラー設計を採っており、異なるCPUでモジュールをある程度共用化できるようにしている。モジュラー設計によってCPU設計は迅速化できるが、特定のCPUに最適化されない分、モジュールの占めるダイ面積に若干のオーバーヘッドが発生しているようだ。これは、CPUの設計容易性とトレードオフとなる。
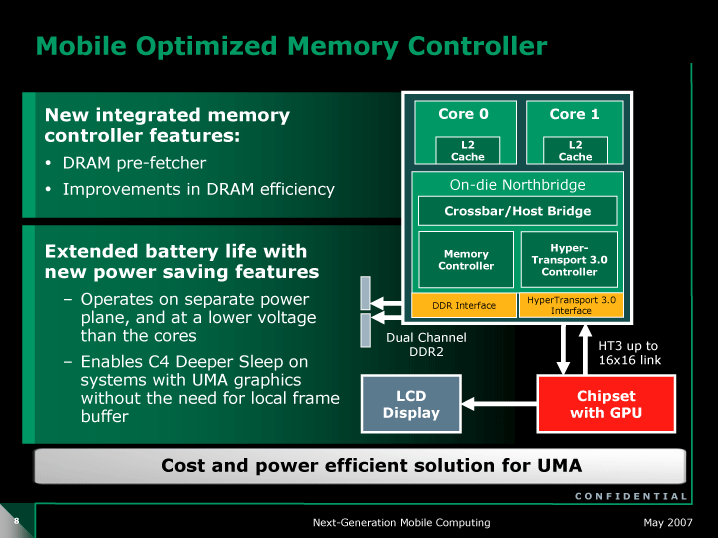 |
| Mobile Optimized Memory Controller(※別ウィンドウで開きます) PDF版はこちら |
●Barcelonaと異なりCPUコア単位で電圧を制御
AMDは、サーバー&デスクトップ向けのBarcelona系では機能拡張したCPUコアを採用した。しかし、Griffinには旧世代のRev. G相当のCPUコアを載せている。Steinman氏は次のように説明する。
「我々はGriffinではモバイルへの最適化を目指した。我々が考慮したのは、モバイルへの最適化は革新的なので設計上のリスクがあることだった。例えば、モバイルへの最適化のため、ノースブリッジ回りは新しく設計し、他にも多くの労力をかけた。そのために、CPUコア自体は安定したものであることが望ましかった。これは設計上のバランスだ」
CPUコアはRev. G世代から大きくは変わらないが、Griffinでは2つのCPUコアを異なる電圧で制御できるようになった。CPUコアの負荷に応じて、コアの動作周波数を変動させるだけでなく、電圧も変動させる。そのため、Griffinでは、CPUコア向けに、電圧が可変の電圧プレーンが2つ用意されている。VDD0がCPUコア0(L2キャッシュを含む)に対する電圧、VDD1がCPUコア1(L2キャッシュを含む)に対するものだ。電圧の方がアクティブ消費電力に与える影響が大きいため、より大きく電力を抑えることが可能になる。
CPUコア単位の電圧の遷移は、IntelのモバイルCPUでも、まだ実装していないフィーチャだ。同じAMD CPUでも、サーバー&デスクトップ向けの新CPU「Barcelona(バルセロナ)」でも採用しない。これは、ボルテージレギュレータ側が複雑になるためだ。
「Barcelonaでは全てのCPUコアが同じ電圧で動作するが、それぞれのコアは異なる周波数で動作できる。また、ノースブリッジはCPUコアとは異なる電圧プレーンを備える」とSteinman氏は説明する。
Barcelona系については、今年2月のISSCC(IEEE International Solid-State Circuits Conference)で、電力供給回りのアーキテクチャが明らかにされた。Barcelonaでは、4個のCPUコアに対して、単数のVDDCOREの電圧プレーンが設定されている。そのため、4個のCPUコアはいずれも同じ電圧で動作する。
GriffinとBarcelonaのどちらも、CPUコアとは分離されたノースブリッジブロック向けの電圧プレーンNDDNBがある(BarcelonaではL3キャッシュへの供給もNDDNB)。そのため、CPUコアがスリープに入り電圧を下げている時も、外部のGPUコアなどから共有メモリへのアクセス要求があった時に、ノースブリッジ部分だけを動作させることができる。AMDアーキテクチャではCPUにメモリが接続されている。そのため、従来は、グラフィックス統合チップセット側にビデオバッファを持たないと、CPUがアイドルに入ることができず、電力消費が増大してしまっていた。
ちなみに、Griffin/Barcelonaでは、この他に、電圧が固定されたアナログ系とI/O向けの電圧プレーンが4系統ある。HyperTransportリンクに供給されるVLDT 1.2V、DDR2 I/Oに供給されるVDDIOとVTT、オンダイPLLに供給されるVDDA 2.5Vの4つだ。
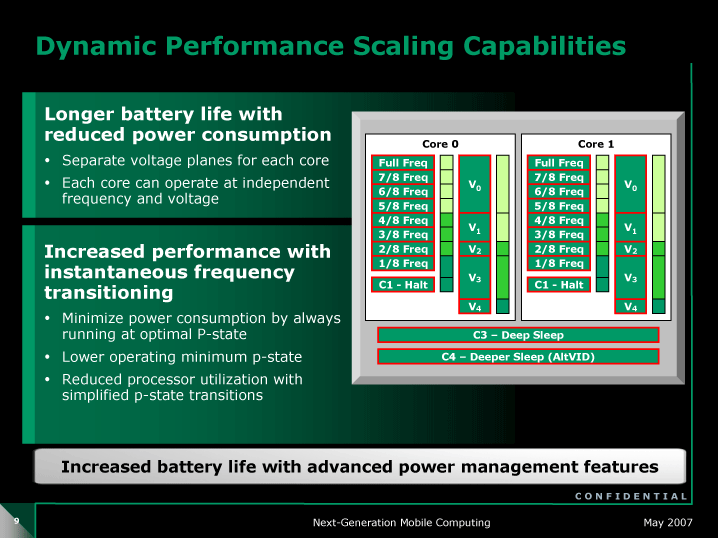 |
| Dynamic Performance Scaling Capabilities (※別ウィンドウで開きます) PDF版はこちら |
 |
| Power-optimized HyperTransprot 3 (※別ウィンドウで開きます) PDF版はこちら |
 |
| Voltage Planes and Control (※別ウィンドウで開きます) PDF版はこちら |
●DRAMコントローラも一新
AMDはBarcelona系ではDDR2-1066に対応する。DDR3への移行を進めるIntelに対して、AMDはDDR2の高速化と延命を図る。そのため、JEDEC(米国の電子工業会EIAの下部組織で、半導体の標準化団体)にDDR2-1066の標準化を提案している。Intelは4月のIntel Developer Forum(IDF)で、DDR3は省電力に効果があるとして、モバイルでの導入を強調していた。また、IDFでは、DRAMベンダーにDDR2-1066は困難が多いというプレゼンテーションを行なわせて、対抗していた。
対するAMDは、2008年のCPUであるGriffinでもDDR2を継続する。DDR3をサポートしなかったのは、DDR3の浸透がまだ先だと判断したからだという。「当社内部のエキスパートが、いつDDR3への移行が起こるかを見積もっている。我々は18カ月先までの見通しを持っており、それに基づいて判断している」とSteinman氏は語る。
実際にDDR3の浸透はかなりずれ込む可能性が高いので、この判断はAMDとしては妥当だろう。
サポートするメモリはデュアルチャネルDDR2のままだが、Griffin世代ではメモリアクセスの効率化が図られている。Barcelona系と同様に、2つのDRAMコントローラが独立して動作できるようになっているためだ。複数のCPUコアが多数のスレッドを並列に走らせると、異なるメモリエリアに対する異なるアクセスパターンが増える。そのため、DRAMコントローラを効率化すると、性能が上がりやすくなる。Steinman氏は次のように説明する。
「Griffinでは2つのモードで(DRAMコントローラを)オペレートできる。1つは、2個のメモリコントローラが独立して動作するモード。メモリシステムにより並列にアクセスし、メモリバンクをよりアクティブにできるという利点がある。もう1つのモードは、2個のメモリコントローラが一緒に動作するモードで、後方互換性のために備えている。
互換性というのは、ボードよりも、レガシアプリケーションのためだ。アプリケーションによっては、(DRAMコントローラが)連携して動作する方がいい場合があるだろう。フレキシビリティのために、我々は、単純に、両方のオペレーティングモードを保持している。しかし、独立したコントローラのモードの方が使われると予期している」
また、GriffinはハードウェアDRAMプリフェッチャを備え、必要なデータをメモリから先読みすることができる。プリフェッチの強化という点は、IntelのCore MAとも共通している。
「データをメモリから先に取り出しておくことで、メモリアクセスを事実上ゼロレイテンシにできる。これはパフォーマンス向上では大きな効果がある。
DRAMプリフェッチャは、8つの異なる独立したストリームをトラックできる。それぞれのコアは異なるスレッドを実行するため、I/Oサブシステムも異なるアクセスパターンとなる。ストリームのプリフェッチは、+1/+2/+3の間隔、あるいはマイナス方向へ-1/-2/-3、あるいはオルタナティブパターンでもフレキシブルに対応できる。
それぞれのストリームは、パターンに合致するかどうかアクセスのカウンタがモニターされる。カウンタがパターンに合致し、あるしきい値を超えると、プリフェッチリクエストが生成される。そして、プリフェッチリクエストは、他のトランザクションとプライオリティが比較されアービトレート(仲裁)される。本当に必要なトランザクションが、投機的な(プリフェッチ)アクセスに置き換えられてしまうと、本末転倒だからだ」(Steinman氏)
●モジュラー設計に移行するAMD CPU
AMDはBarcelonaとGriffinからモジュラー設計を採用した。CPUコアやメモリコントローラといったコンポーネントをモジュラー化し、組み合わせてさまざまなコンフィギュレーションのCPUを迅速かつ低労力に開発できるようにしている。そのために、次世代CPU群では、各モジュール間のインターフェイスを再設計して、よりクリーンでコンポーネント間の接続をしやすい標準インターフェイスにした。
だが、こうしたインターフェイスの標準化は、オーバーヘッドを大きくしてパフォーマンスを削いでしまう場合がある。SoC(System on a Chip)でのインターフェイスで問題になりやすいのは、その点だ。AMDはこの問題にどう対処しているのだろう。Steinman氏はそれについて次のように説明する。
「それは重要なポイントだ。そのため、内部インターフェイスの標準化では、2つの次元での最適化を行なっている。インターフェイスの中には、パフォーマンスがクリティカルではないものがある。そうしたインターフェイスは簡素化し、余計な設計を加えないようにした。
しかし、プロセッサコアとノースブリッジの間のインターフェイスのように、特定のインターフェイスではパフォーマンスが非常にクリティカルだ。ハイパフォーマンスインターフェイスは、複雑なインターフェイスの場合がありうる。そこで、そうしたインターフェイスについては、簡素化してパフォーマンスを落とすよりも、インターフェイスのドキュメンテーションとベリファイに、より注意を払った。フルチップのパーツとしての環境でベリファイするのではなく、コンポーネントレベルでベリフィケーションすることで標準化している。それによって、設計を容易に移すことができるようにした」
つまり、SoC(System on a Chip)型のモジュラー化のように、全てに標準的なインターフェイスを設けてしまうのではなく、パフォーマンスが必要な部分は特殊なインターフェイスも残す。ただし、文書化とベリファイを徹底して行なうことで、そうしたインターフェイスを使いやすくするという路線だ。
Griffinは65nmプロセス世代だが、製造プロセス技術自体もデスクトップ向けCPUとは変える。
「Fab(半導体工場)側でモバイル向けの最適化を行なう。ゲート絶縁膜を変えているはずだ」とAMDのDavid Rooney(デビッド・ルーニィ)氏(Division Product Manager, Mobile Division, Microprocessor Solutions Sector, AMD)は語る。
Griffinは、AMDの次のステップであるFUSIONにつながるCPUだ。Griffinの概要が見えてきたことで、FUSIONへの道筋が見えてきた。AMDはFUSIONをどのように製品化し、ヘテロジニアスマルチコアへとどのように至るのだろう。次回はMPFで明らかになった、AMDのFUSION戦略のアップデートをレポートしたい。
□関連記事
【5月24日】【MPF】【AMD編】Griffinの詳細を発表
http://pc.watch.impress.co.jp/docs/2007/0524/mpf02.htm
【5月18日】AMD、次世代モバイルCPU「Griffin」とプラットフォーム「Puma」を発表
http://pc.watch.impress.co.jp/docs/2007/0518/amd.htm
【3月17日】【CeBIT】AMDがR600の概要とクアッドコアOpteronのウェハを公開
http://pc.watch.impress.co.jp/docs/2007/0317/cebit06.htm
(2007年5月24日)
[Reported by 後藤 弘茂(Hiroshige Goto)]
【PC Watchホームページ】
PC Watch編集部 pc-watch-info@impress.co.jp ご質問に対して、個別にご回答はいたしません
Copyright (c) 2007 Impress Watch Corporation, an Impress Group company. All rights reserved.