 |


■後藤弘茂のWeekly海外ニュース■AMDがRadeon HD 2000で倍速シェーダを採らなかった理由 |
●開発難度が高いチップ内の非同期インターフェイス設計
AMDのRadeon HD 2000(R6xx)ファミリは、NVIDIAのGeForce 8000(G8x)ファミリと比べると低速だ。R600系の動作周波数は、80nmの高速プロセス「80HS」で現在740MHz、65nmの汎用プロセス「65G+」で800MHzだ。従来のGPUコアと比べると高速だが、クロックだけを見るとNVIDIAのG80系の倍速(実際には2倍以上)シェーダプロセッサに見劣りする。G80は90nmプロセスでシェーダコアは1.35GHz動作、GeForce 8800 Ultraでは1.5GHz動作する。
G8x系アーキテクチャのシェーダプロセッサが高速なのは、シェーダプロセッサコアのプログラマブル演算ユニット部分のクロックを分離したからだ。G80の場合は、1.35GHzで動作しているのは、ストリーミングプロセッサとテクスチャユニットの中の数値演算ユニット部分。それ以外のGPUの固定機能ユニット部は575MHzで動作させており、倍速以上の動作となっている。
NVIDIAがクロックを分離したのは、プログラマブルな演算パイプは高速化が容易だが、固定機能部分は高速化が難しいためだ。つまり、GPU全体を高速にすることは不可能だが、高速にできるシェーダプロセッサ部分だけを分離して倍速化することは可能というわけだ。このアプローチは、シェーダプロセッサコアが単一リソース化されたユニファイドシェーダアーキテクチャで容易になった。ユニファイドシェーダに依存した設計だと言える。
 |
| Eric Demers氏(Senior Architect, AMD Graphics Products Group) |
しかし、同じユニファイドシェーダアーキテクチャを採ったにもかかわらず、AMDはシェーダプロセッサコアを倍速動作をさせなかった。AMDは倍速動作させることができなかったのだろうか。R600のアーキテクトであるEric Demers氏(Senior Architect, AMD Graphics Products Group)は次のように説明する。
「それ(倍速シェーダプコア)については、我々も以前から検討していた。R600では、チップ上に38のクロックドメインがある。だから、我々が、クロックドメインの制御を知らないわけではない。
シェーダコアとそれ以外のドメイン(のクロック)を非同期にすることは技術的にはできる。実際、我々は80nmプロセスで、1.6GHz程度にまで(シェーダコアクロックを)引き上げる設計が可能だ。
しかし、その結果として(チップの)設計は複雑になってしまう。多くのユニット間での非同期インターフェイスを実現しなければならないからだ。これは、非常にタフなゲームだ。また、(シェーダコアクロックを上げると)リーク電流(Leakage)が顕著な問題になると考えている。
もちろん、多大な時間を複雑な設計に割いて、ある程度のメリットを得たいならそうした設計をすることも可能だ。しかし、それよりは、予測可能で整然として高いパフォーマンスを得た方がいいと我々は判断した。
我々は、(R600では)スーパースカラ設計をシェーダコアで採った。コアは800MHz近くで動いており、従来と比べると十分に速い。これは設計の選択の問題で、我々は今の選択に満足している。もっとも、将来は(倍速シェーダコアを)採用するかもしれない」
動作クロックを変えたドメイン間のコミュニケーションは、チップ設計上では難度が高い。これはチップ設計では一般的だ。そのため、トレードオフで得られるパフォーマンスと比較すると割に合わないとAMDは見ている。
●多くの演算ユニット対速い演算ユニットのトレードオフ
また、別のAMD関係者は次のように説明する。
「NVIDIAアーキテクチャでは、プロセッサを速く動かすために、どうしてもプロセッサや付属するリソースが大きくなる。そのために、搭載できるプロセッサ数が少なくなる。我々のアーキテクチャなら、プロセッサ数を増やすことが可能だ。少ないプロセッサを速く動かすか、多くのプロセッサをそこそこの速度で動かすかはトレードオフとなる」
シェーダプロセッサコアを高速動作させるには、シェーダの演算パイプのパイプライン段数を深くしなければならない。パイプライン段数を深くすると、ラッチの数が増えるなど、演算ユニットのトランジスタ数が増えてしまう。
また、シェーダコアを高速にすると、実行レイテンシとメモリレイテンシの隠蔽もさらに大きな課題となる。まず、パイプラインが深くなると、実行レイテンシサイクルが増えてしまう。実行レイテンシは、前の命令の実行結果に依存性のある命令を実行する際に問題となる。そのため、カスケード式に実行するといった手段でレイテンシを隠蔽する必要がある。
加えて、演算リソースのクロックが上がると、メモリアクセスレイテンシの際にロスするサイクル数が増えてしまう。そのため、メモリレイテンシを隠蔽するためのマルチスレッディングをより深める必要がある。つまり、高速化にはコストが必要で、そのために演算コアとレジスタなどの周辺リソースが増大してしまう。その結果、1個のGPUに搭載できる演算リソースが減ってしまうというわけだ。実際、G80はR600と比べると半分の演算リソースしか搭載していない。
つまり、演算リソースの数を減らして高速に動作させるか、高速化はある程度に留めて演算リソースの数を増やすか、どちらかの選択となる。倍速動作にした結果、リソースが半減するのでは分が悪いとAMDは判断したわけだ。
もっとも、R600にもトレードオフの設計難度がある。演算リソースの数が増えると配線の複雑度が増してしまうからだ。以前、R520の発表時にATI(現AMD)のBob Drebin氏(CTO, AMD Graphics Products Group)はGPU設計上の最大のハードルは配線にあると説明していた。NVIDIAのDavid B. Kirk(デビッド・B・カーク)氏(Chief Scientist)も、NV30の時にデータパス配線が設計上のチャレンジで、データ精度を上げるとそこが問題になると語っていた。
GPUベンダーの技術幹部がこぞって配線の難しさを挙げるのには理由がある。GPUでは、CPUとは比較にならないほど演算ユニットが多いからだ。100を超える演算ユニットとキャッシュやメモリコントローラなどの間の配線は極めて難しい。配線地獄に近い状態にあり、配線がロジック部のダイ上の面積を押し上げてしまっている。ユニット数の多いR600は、G80よりもこのハードルが高い。
●R600のシェーダプロセッサの演算アレイの構造
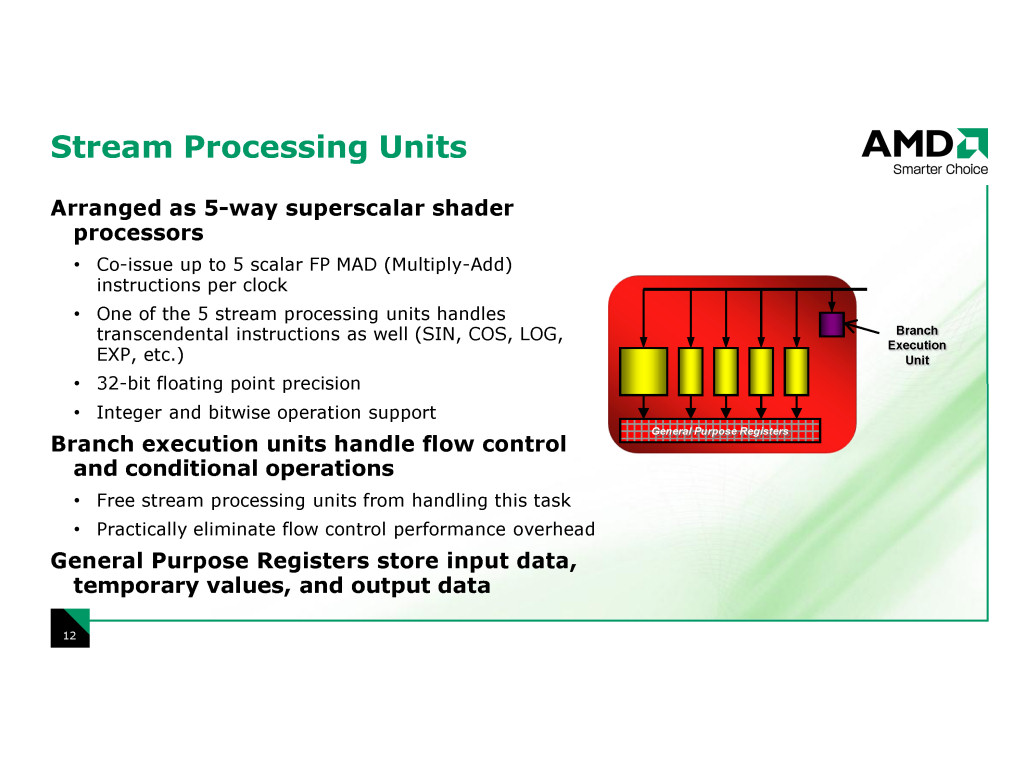
R6xx系のシェーダプロセッサ「5-wayスーパースカラシェーダプロッサ」には演算ユニットが合計5個ある。「5個のスカラユニットがそれぞれ個別に積和算を含む浮動小数点演算と整数オペレーションを実行できる」(Demers氏)構造となっている。
と言っても同じユニットが5個あるわけではない。4ユニットは同じ構成で、32-bit単精度浮動小数点の積和算と整数演算用のシンプルな演算ユニットとなっている。1サイクルスループットで、毎サイクル毎に命令を実行できる。それに対して、5番目のユニットは「他の演算ほど頻繁には使わないスペシャルな機能を持つ」(Demers氏)演算ユニットだ。浮動小数点積和算と整数演算の他に、複雑なオペレーション(sin、cos、log、expなど)や浮動小数点と整数のデータ変換などを実行する。こちらも、ほとんどの命令は1サイクルスループットだ。
5番目のユニットは、NVIDIAのG8xアーキテクチャのスーパーファンクションユニット(SFU)に近い。G8xの場合は、4個のスカラ型のストリーミングプロセッサ(SP)につき、1個のSFUが存在する。個々のSPがそれぞれ個別のピクセルに対して、プロセッシングを行なうアーキテクチャであるため、1個のSFUを4個のSPが共有するアーキテクチャを採っている。ただし、G8xのSFUは、シンプルなオペレーションでは積和算ではなく乗算(MUL)&ムーブ(MOV)ユニットだ。
AMDのシェーダプロセッサの演算ユニットが、4シンプルと1コンプレックスの構造になっているのは、旧来のバーテックスシェーダプロセッサの、Vec4(4-way SIMDユニット)プラス1(スカラユニット)を継承しているからだ。4-way SIMD型のオペレーションを実行する場合は、4個のシンプル演算ユニットで実行するため、SIMD型の処理も効率よく実行できる。
 |
| Stream Processing Unitの概要 PDF版はこちら |
 |
| SIMD発行されるR600のVLIW命令 PDF版はこちら |
●2段階の分岐制御を備えるR600アーキテクチャ
このほかに、R600アーキテクチャで目立つのは、分岐実行ユニットをシェーダプロセッサ内に備えていることだ。これは、Radeon X1000(R5xx)系アーキテクチャから継承している。
GPUの場合、命令カウンタを持つ命令ユニット(命令シーケンサ)はシェーダプロセッサの外にあり、通常、分岐は命令シーケンサのレベルでハンドルする。なぜ、AMDアーキテクチャでは分岐ユニットを内部に備えるのか。これについて、アーキテクトのDemers氏は次のように説明する。
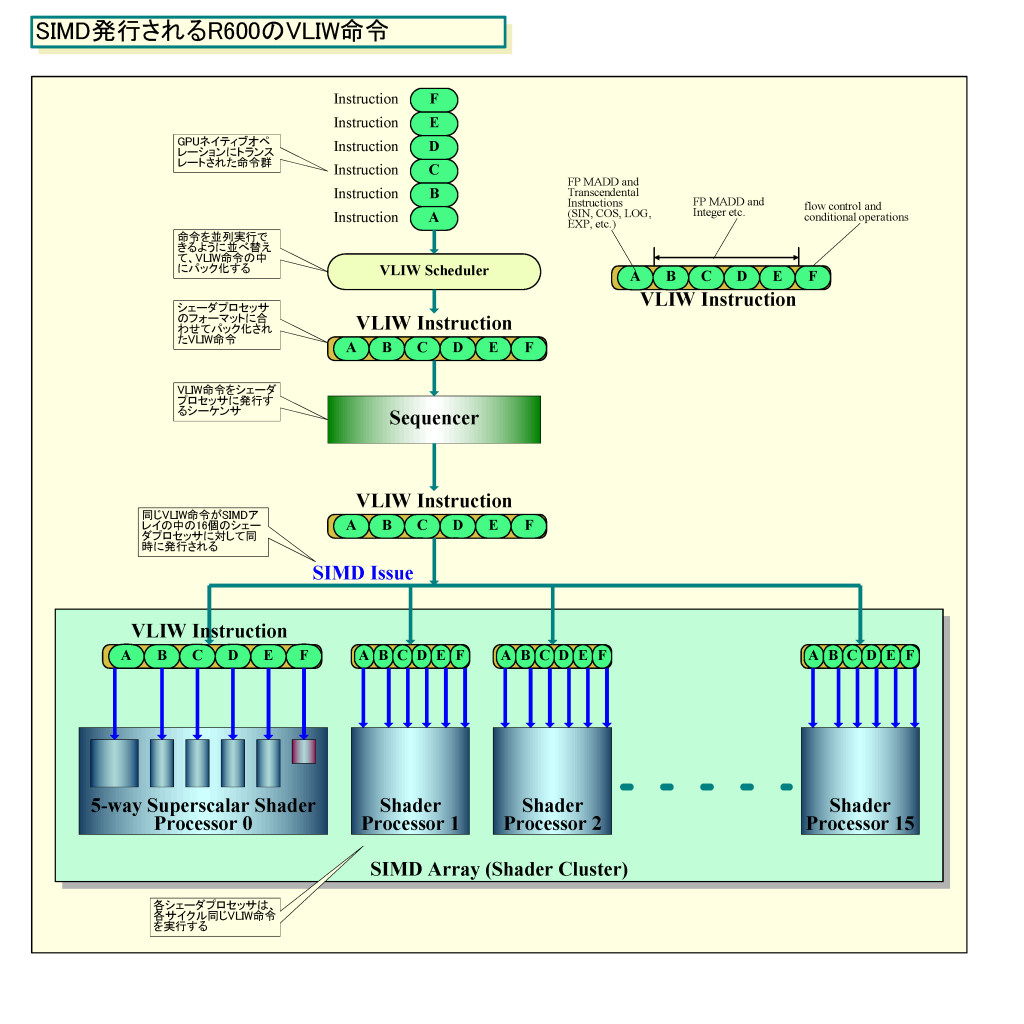
「GPUでは2種類の分岐が存在する。SIMDアレイ(R600のシェーダクラスタ)全体が、コードの別なパートに一緒に分岐するようなヘビーデューティな分岐は、ディスパッチプロセッサの中のシーケンサが制御する。しかし、もっと小さな分岐、コードの中の数命令をスキップするようなシンプルな分岐は、ALU(シェーダプロセッサ)の中でハンドルする。ALU自身が(条件分岐の)オペレーションの典型的な結果を見積る」
つまり、条件分岐によってコードパスが大きく変わるような分岐は、シーケンサ側の制御ユニットで制御する。これは、SIMDアレイに発行する命令ストリーム自体が変わるからだ。プロセッサに対するVLIW命令は、SIMDアレイ内のシェーダプロセッサに対してSIMD発行される。つまり、16個のシェーダプロセッサ全てが同じVLIW命令を実行する。そのため、シーケンサが条件分岐を制御、シェーダプロセッサ全てが分岐する場合には、SIMDアレイに対して発行する命令のコードパスを変更する。例えば、SIMDアレイが全てパスAへと分岐する場合にはパスAの命令ストリームをSIMDアレイに送り込む。
しかし、R600の場合、分岐によって数命令が飛ばされるだけのようなケースでは、シェーダプロセッサ内の分岐ユニットがハンドルする。SIMDアレイに対してシーケンサがシーケンシャルに命令を発行、SIMDアレイ内の各シェーダプロセッサが、条件に応じて命令スキップするかどうかを判定してハンドルするようだ。この手法の場合、命令シーケンサ側の分岐ユニットの負担を軽くできる。数命令がスキップされるだけなら、実行しない命令はノンオペレーションにしても、数サイクルのロスだけなので、ムダはそれほど大きくないという発想だと推定される。
このほか、R600では分岐命令に対する「プレディケーション(Predication)」も行なうという。これについては詳細は分からないが、R600のシェーダプロセッサの命令はVLIW(Very Long Instruction Word)タイプであるため、原理的には、分岐パスを並列に実行するCPUタイプのプレディケーションを行なうことも容易だ。プロセッサ側が、プレディケーションフラグを備えていれば、並列にパスを実行して、条件が成立してフラグが真になった方のパスの演算結果だけをレジスタに書き込むことができる。完全に両パスを並列化できれば、各シェーダプロセッサによって分岐方向が異なる場合にも、実行サイクル数が変わらなくなるため、シェーダプロセッサの効率がアップする。ただし、そのためには、VLIWコンパイラによるプレディケーションのスケジューリングが必要になる。
●演算ユニットよりも広大な汎用レジスタアレイ
R600は膨大なレジスタリソースを備える。レジスタは各シェーダプロセッサ単位で備えられており、汎用に使うことができる汎用レジスタ(GPR)アレイとなっている。NVIDIA G8xと同様に、シェーダプロセッサのスカラ化に対応して、レジスタも32-bitスカラレジスタとなっている。
現在のGPUは、メモリレイテンシの隠蔽のため、多数のスレッドをオンザフライで走らせる。メモリからのデータ待ちのスレッドはスリープしているが、その間のテンポラリバリューは汎用レジスタに保持されている。そのため、GPUのシェーダプロセッサは、一般に、1スレッドの実行に必要なレジスタの数十倍もの物理レジスタを備える。オンザフライで制御している全てのスレッドのレジスタ内容を保持するためだ。
その結果、R600のレジスタアレイは巨大になっており、「ALU(演算ユニット)よりも大きな面積を占めている」(Demers氏)という。実際、前世代のXbox 360 GPU(Xenos)でも、24,576本のベクタレジスタを備えており、レジスタがチップ面積のかなりの部分を占めていた。
R600は、G80やXenosと同様に、各スレッド毎にレジスタ割り当てを固定していない。そのため、各スレッドが使う物理レジスタ数が増えれば、それだけ立ち上げることができるスレッド数が減る。スレッド数と、スレッド当たりのレジスタ割り当て数は、トレードオフの関係にある。
この構造は、現在のマルチスレッディングGPUで共通した特徴となっている。そのため、コンパイラによるスレッドに対するレジスタ割り当てが性能を左右する。例えば、Xenosでは、Xbox 360の初期の段階ではMicrosoftのコンパイラのはき出すネイティブコードが大量に物理レジスタを使ってしまっていた。そのため、スレッドが規定数立ち上がらず、パイプラインがアイドルになるという状態が発生したという。その後、Xenosでは、コンパイラ側の改良によってマルチスレッディングが向上し、シェーダ性能が大幅に上がるという現象になった。
こうした構造にあるため、マルチスレッド性能を上げるためにはレジスタリソースも拡充する必要がある。「DirectX 9ではスレッド当たり16から多分32のGPRにアクセスした。今後はそれ以上になる」(Demers氏)ため、R600ではさらにレジスタを強化したという。
●汎用レジスタスペースを仮想化するキャッシュ
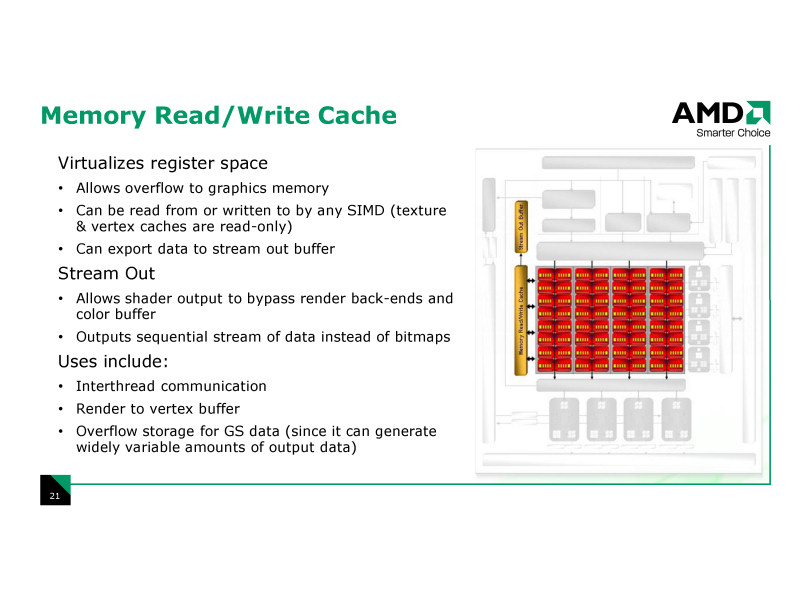
さらに、R600ではこの汎用レジスタアレイを仮想化する「メモリリード/ライトキャッシュ(Memory Read/Write Cache)」も備えている。
「(R600では)新しいキャッシュを採り入れた。これはGPRアレイに対するメモリリード/ライトキャッシュだ。我々は、GPRを増やすために、GPRを仮想化する必要があった。一般的に、リソースを仮想化すれば、以前より大幅にリソースを拡張できる。そのため、我々はGPRの仮想化のための、リード/ライトキャッシュを置いた。
(従来からのGPUのキャッシュである)バーテックスキャッシュとテクスチャキャッシュはどちらも一方向(リードオンリー)だ。しかし、このキャッシュは、シェーダコアから書き込みと読み出しの両方ができる」とDemers氏は説明する。
スレッドを立ち上げるとどんどん消費されるレジスタ。そこでAMDはキャッシュすることでレジスタを仮想的に広げてスレッディングリソースを提供できるようにしたようだ。仮想的にレジスタスペースを広げるとしているので、シェーダコアからは少なくともキャッシュの一部はレジスタスペースに見えると推測される。
また、仮想化された汎用レジスタを、チップ外のグラフィックスメモリにオーバーフローさせることも可能だ。キャッシュからメモリへのアウトプットを持っているからだ。
名前の通り、メモリリード/ライトキャッシュは、シェーダコアからメモリへの直接書き込みのキャッシュにもなっている。GPRの仮想化と、メモリライトのキャッシュの2つの側面を持っていることになる。
「このキャッシュからは、DirectX 10のストリームアウトバッファに出力することもできる。異なるデータをライトコンバインバンチにまとめることもできるので、(メモリライトの)パフォーマンスも向上させることができる。ストリームアウトからバーテックスバッファに出力することも可能だ」(Demers氏)
DirectX 10からは、シェーダプロセッサから直接メモリに書き込む「ストリームアウト」がサポートされた。従来のGPUは、メモリへはレンダーバックエンドを経由して書き込むしかなかったが、DirectX 10 GPUではシェーダプロセッサからメモリへのダイレクトなパスを備える。そして、R600では、ストリームアウトへの書き出しがここでキャッシングされるようだ。
 |
| メモリリード/ライトキャッシュの概要 PDF版はこちら |
●GPU内でのデータの再利用のための仕組みを備えるR600
こうした構造であるため、メモリリード/ライトキャッシュは、GPU内のデータコミュニケーションに使うことができる。
「メモリリード/ライトキャッシュは、完全にコヒーレンシを取ったキャッシュで、どのSIMDアレイからもアクセスができる。だから、スレッド間のコミュニケーションにも使うことができる。1つのスレッドのデータアウトを他のスレッドに入れることができる」とDemers氏は説明する。
GPUで汎用コンピューティングを行なう場合の弱点の1つとして以前から指摘されていたのは、データの局在性を、オンチップメモリで活かせないことだった。伝統的なGPUでは、シェーダプロセッサが自由にリード&ライトアクセスできるのはローカルレジスタに限られていたからだ。そのため、GPUでは、1つのスレッドの処理したデータを、他のスレッドがオンチップで再利用することができなかった。データの再利用には、いったんメモリに書き込んだ後で、再び読み込む必要がある。そのため、せっかく必要なデータが、局在していてもメリットを得られなかった。
この問題を解決するには、GPU内に明示的にアクセスできるメモリやレジスタを設置するか、キャッシュを設置するか、プロセッサのレジスタの相互アクセスを可能にするといった方法が考えられる。汎用ストリームプロセッシングに向けたプロセッサ「Stream Processor」(スタンフォード大学からのスピンアウトであるStream Processorsが開発)では、レジスタファイルを2階層にし、プロセッサコア間で共有するレーンレジスタでこの問題を解決している。NVIDIAのG8xのアプローチもこれに近いと思われる。AMDは、キャッシュするアプローチを取ったようだ。Stream Processorの論文では、ライタブルなメモリによって、「プロデューサ-コンシューマロカリティ(Producer-Consumer Locality)」の活用と「Local Working-set Update」が可能になり、外部メモリアクセスが大幅に減るため、データ依存性のあるストリームプロセッシングの効率が大きくアップするとしている。
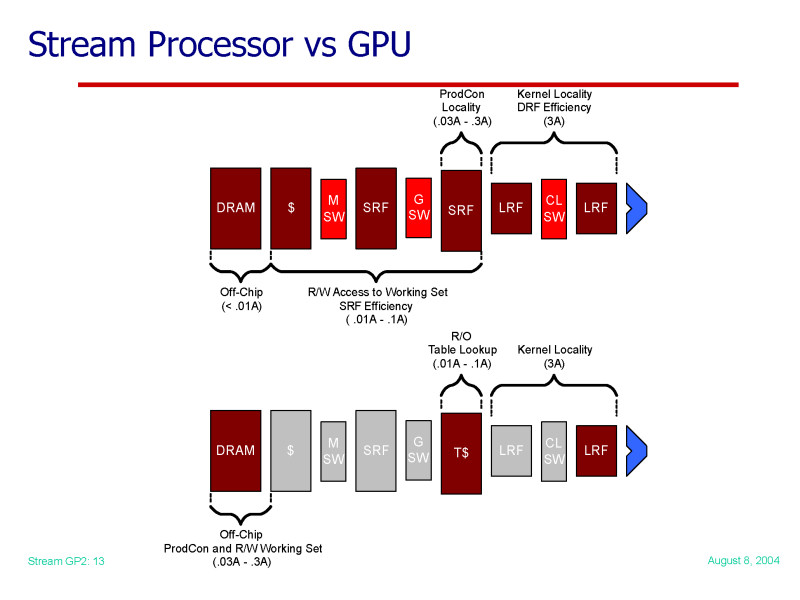 |
| Stream ProcessorとGPUのメモリ階層アーキテクチャの違いのスライド。下が伝統的なGPUで、R600やG80などの最新GPUは上のStream Processorに近づいている PDF版はこちら |
●CPUライクなストアフォワードも備えるR600
ちなみに、R600ではこのほかに、レンダーバックエンドにも、レンダートゥーテクスチャ(Render-to-texture)の結果をGPU内でテクスチャユニットにフォワードする仕組みを備えている。これはCPUのストアフォワードに似た仕組みで、ハードウェアでコヒーレンシを取り、レンダートゥーテクスチャの効率を大幅にアップする。R600では、データの再利用の効率を大きくアップして、よりGPUを効率的にしている。
このほか、メモリリード/ライトキャッシュは、ジオメトリシェーダのボトルネックの解消にも使われている。バーテックスシェーダとピクセルシェーダでは、インプットとアウトプットは1対1の関係にある。1個の頂点(バーテックス)またはピクセルが入力されプロセッシングのあと出力される。
しかし、ジオメトリシェーダでは、平面が分割されるため多数の頂点が生成される可能性がある。つまり、1対多のインプットとアウトプットとなる。そのため、ジオメトリシェーディングでは、アウトプットレジスタに割り当てられた汎用レジスタ枠があふれる可能性がある。その場合、オーバーフローした頂点データを処理しないと、処理が止まってしまう。DirectX 10 GPUでは、これがジオメトリシェーダの性能を制限するハードルの1つになっていると考えられる。
R600アーキテクチャは、メモリリード/ライトキャッシュによって溢れたジオメトリシェーダの頂点データをストア。それを、さらにバーテックスシェーダへと戻すことでジオメトリシェーダの効率を上げている。AMDは、NVIDIAアーキテクチャよりジオメトリシェーダ性能が高いことをR600の利点に挙げているが、その秘密はここにあるのかもしれない。
こうして概観すると、R600はデータパスの構造については、G80系アーキテクチャ以上によく練られていることがわかる。CPUライクな発想が取り入れられており、GPUの効率のアップを助けていると思われる。
□関連記事
【5月18日】【海外】大きく異なるRadeon HD 2000とGeForce 8000のアーキテクチャ
http://pc.watch.impress.co.jp/docs/2007/0518/kaigai359.htm
【5月15日】【海外】ラディカルなAMDの「Radeon HD 2000」アーキテクチャ
http://pc.watch.impress.co.jp/docs/2007/0515/kaigai358.htm
【4月16日】【海外】スケーラブルに展開するNVIDIAのG80アーキテクチャ
http://pc.watch.impress.co.jp/docs/2007/0416/kaigai350.htm
【2006年11月19日】【海外】これがGPUのターニングポイントNVIDIAの次世代GPU「GeForce 8800」
http://pc.watch.impress.co.jp/docs/2006/1109/kaigai316.htm
【2006年7月27日】【海外】正反対の方法論で対決するATIとNVIDIA
http://pc.watch.impress.co.jp/docs/2006/0727/kaigai291.htm
(2007年5月23日)
[Reported by 後藤 弘茂(Hiroshige Goto)]
【PC Watchホームページ】
PC Watch編集部 pc-watch-info@impress.co.jp ご質問に対して、個別にご回答はいたしません
Copyright (c) 2007 Impress Watch Corporation, an Impress Group company. All rights reserved.