 |


■後藤弘茂のWeekly海外ニュース■CPUとGPUの大きな違い |
●汎用コンピューティングで近づくCPUとGPU
AMD(旧ATI Technologies)の、DirectX 10世代ハイエンドGPU「R600」が、いよいよ登場しようとしている。R600ファミリーやそのデモ映像は、先週ドイツで開催された「CeBIT」でリークされた。R600が登場すると、NVIDIAのGeForce 8800(G80)と並んで、DirectX 10世代のGPUが揃うことになる。
両社のDirectX 10 GPUは、いずれも、Unified-Shader型アーキテクチャで、無制限のシェーダプログラム長やシェーダからのメモリアクセスなど、汎用的なコンピューティングに適用できる機能を備える。また、NVIDIAは「CUDA(クーダ:compute unified device architecture)」、AMDは「Close to the Metal(CTM)」で、汎用プログラミングも促進する。GPUが、ますますCPUへと近づきつつある。また、AMDはGPUコアを、Fusion(フュージョン)プロセッサで、CPUに統合し、汎用向けに積極的に使おうとしている。CPUとGPUの融合も始まりつつある。
しかし、CPUとGPUには、まだ大きな違いがある。GPUは、現状では、データパラレル(データ並列)型の演算に特化したプロセッサコアのまま。両プロセッサの構造的な違いは大きく、そのため、得意アプリケーション分野も異なる。そのギャップは歴然としている。
●単純な命令発行の仕組みを持つGPU
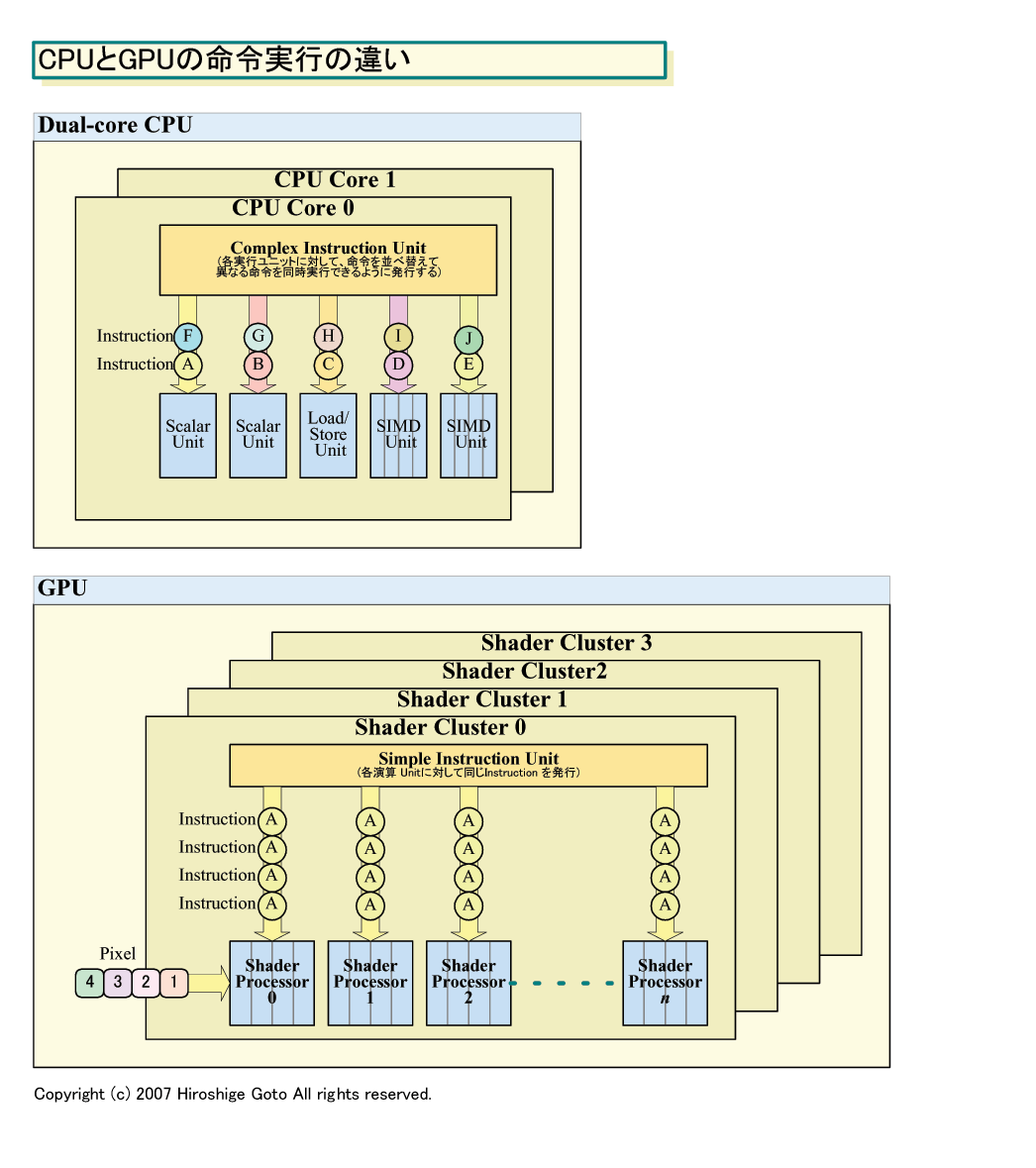
CPUとGPUが大きく異なるのは、命令を発行する仕組みだ。
現在のGPUの命令実行の仕組みは、非常に簡素化されている。GPUの演算ユニットであるプログラマブルシェーダ(Programmable Shader)プロセッサは、数ユニットずつバインドされたクラスタとして管理されている。一般的な構成は4~16個のシェーダクラスタを1クラスタにまとめるものだ。
各シェーダプロセッサはそれぞれ別なデータエレメントに対しての処理を行なうことができる。しかし、シェーダプロセッサの命令ユニット(Instruction Unit)は、クラスタ毎に1個しかない。命令ユニットは、クラスタ内の複数のシェーダプロセッサに対して、同じ命令を発行する。つまり、各サイクル毎に、各シェーダプロセッサは同じ命令を実行する。プログラムカウンタも当然、共有化されている。全体で見ると、シェーダクラスタ全体が、1つの命令で複数のデータに対して処理を行なうSIMD(Single Instruction, Multiple Data)型プロセッサの大型版となっている。
例えば、シェーダプロセッサ0は命令Aをピクセルαに対して実行し、シェーダプロセッサ1はピクセルβに命令Aを、シェーダプロセッサ2はピクセルγに対して命令Aを実行する。このようにして、クラスタ内のn個のシェーダプロセッサはそれぞれ同じ命令Aを異なるエレメントに対して実行する。実際には、シェーダプロセッサの中にも複数の実行ユニットがあり、複数命令を同時に実行することが可能だが、話を単純にするために、それは省いておく。
また、従来のGPUはシェーダクラスタ内のシェーダプロセッサが、数サイクルに渡って同じ命令を実行している。シェーダプロセッサ0は1サイクル目にピクセルα1に対して命令Aを実行、2サイクル目にはピクセルα2に、3サイクル目にはピクセルα3に対して命令Aを実行する。言ってみればカスケード型に、複数ピクセルに対して命令を実行するわけだ。例えば、シェーダクラスタの中に4個のシェーダプロセッサがあり、それぞれが4ピクセルに対して同じ命令を実行する場合、シェーダクラスタは16個のピクセルを1つのバッチとして扱うことになる。
このバッチの単位は、GPUアーキテクチャによって大きく異なっている。AMDのRadeon X1800(R520)では4個のピクセルシェーダプロセッサで構成されるクラスタが、4回に渡り同じ命令を実行する。そのため、R520の場合は、ピクセルシェーダは4プロセッサ×4ピクセル=16個のピクセルを1つのバッチとして扱っていた。AMDでは、このバッチをGPUのスレッドと呼んでいる。
それに対して、NVIDIAの古いGeForce 7(G7x)世代のピクセルシェーダでは、各シェーダプロセッサが220個のピクセルに同じ命令を実行するスタイルを取っていた。G7x世代のピクセルシェーダのクラスタは4個のシェーダプロセッサで構成されていた。そのため、G7xの場合は、このバッチのサイズは4プロセッサ×220ピクセル=880個のピクセルとなっていた。GeForce 8800(G80)ではこの粒度が16または32ピクセルまで縮小されている。
 |
| CPUとGPUの命令実行の違い ※別ウィンドウで開きます (PDF版はこちら) |
●CPUとGPUの違いは個人客か団体客かの違い
CPUの命令実行の仕組みは、GPUとは大きく異なっている。現在のスーパースカラCPUの場合は、多数の異なる実行ユニットを備え、複数の異なる命令を並列に実行できる。例えば、2個のスカラ演算ユニットで整数演算命令AとBを実行。同時に、メモリからのデータ読み出し命令Cをロード/ストアユニットが実行、SIMD演算ユニット0がSIMD演算命令Dを、SIMDユニット1が命令Eを実行するといった形だ。
マルチコアCPUの場合は、それぞれのCPUコアが、それぞれの実行ユニットに対して異なる命令を発行する。GPUのように、同じ命令を4サイクルに渡って実行するといった制約もない。CPU全体で、各サイクル毎に、それぞれの実行ユニットが異なる命令を実行している。
命令発行の面から見ると、CPUとGPUは大きな構造上の違いがある。CPUは柔軟に命令を実行できるのに対して、GPUは一定の粒度のデータに対して同じ命令を実行してゆく。命令実行に、粒度があるのが大きな差だ。
また、現在のCPUの場合、命令ユニットが複数の命令を同時にフェッチする(読み出し)。命令スケジューラが、命令順序を入れ替えるアウトオブオーダ(out-of-order)型実行で、同時に多数の命令を実行できるようにしている。GPUはこうした複雑な命令スケジューリング機構を持たず、基本的にはソフトウェア側のスケジューリングで並列化する。
こうしたアーキテクチャから、CPUでは、命令制御関連のユニットが大きくなる。個々の実行ユニットに対して異なる命令を発行し、しかもアウトオブオーダ実行や分岐予測を行なうためだ。そのため、相対的にCPU内に占める実行ユニットの割合が減ってしまう。それに対してGPUは、命令発行機構は最小限で、実行ユニット自体にダイ(半導体本体)面積を割くことができる。そのため、ダイ面積当たりの演算性能は、GPUの方がはるかに優れる。
これを例えると、CPUは、個々の客(スレッド)が、アラカルトで料理(命令)を、好きな順番(out-of-order)で食べることができる個人客向けレストラン。GPUは、団体客(バッチ)が、コース(プログラム)の順番に出された料理(命令)を一斉に食べる、団体客専用レストランと考えることができる。CPUの場合は、厨房(CPU)がさまざまな料理(命令)を調理(実行)しなければならないので、生産性(パフォーマンス)を上げにくい。それに対して、GPUでは同じ料理(命令)を大量に調理(実行)するので、生産性(パフォーマンス)が高い。
●動的分岐で効率が落ちるGPU
しかし、この構造のためにGPUには弱点がある。実行するプログラムに条件分岐命令が含まれると、性能が大きく削がれる場合がある。そのため、GPUで汎用的なコンピューティングが可能になったと言っても、GPUで実行できるアプリケーションには、まだまだ制約がつきまとっている。
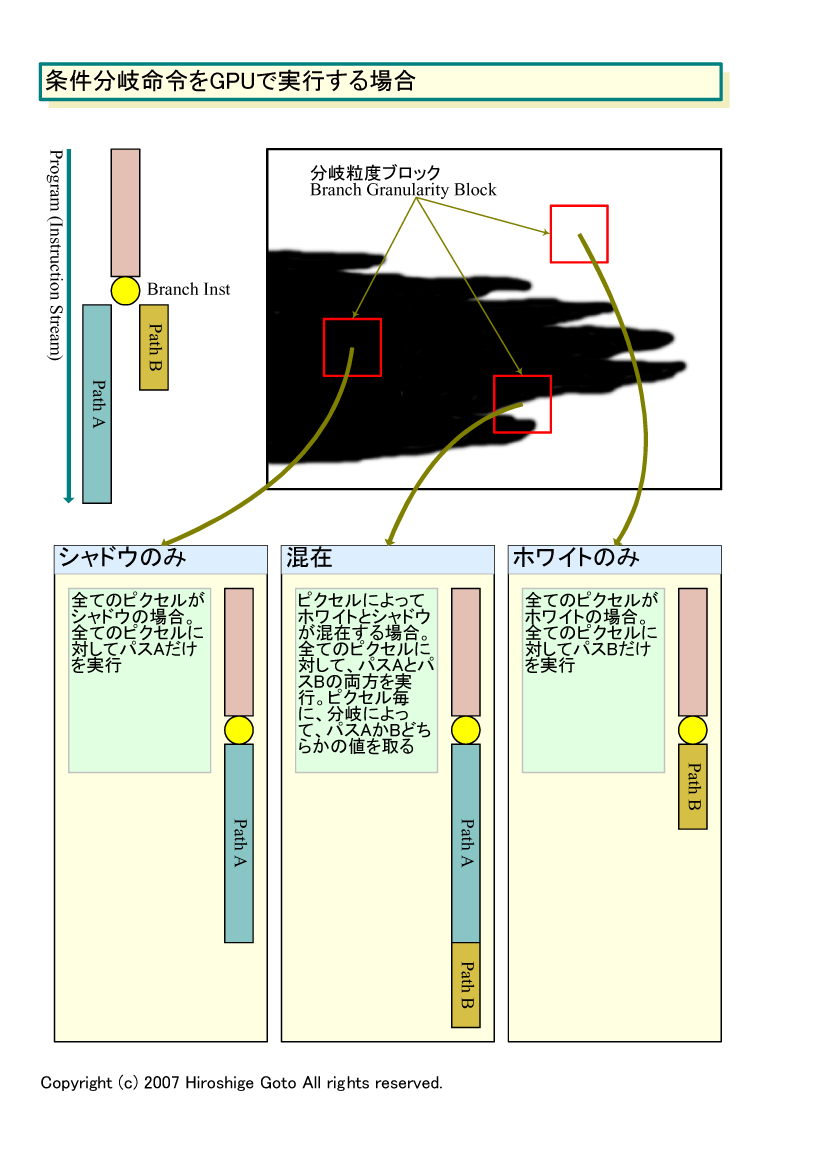
次の図は、AMDがRadeon X1000(R5xx)の技術説明で示したチャートを整理したものだ。単純なシャドウマップで条件分岐するシェーダプログラムの例を示している。ピクセルがシャドウエリアにある場合はプログラムはパスAを実行、ピクセルがシャドウエリアにない場合はパスBに分岐する。
 |
| 条件分岐命令をGPUで実行する場合 ※別ウィンドウで開きます (PDF版はこちら) |
この場合、GPUはピクセルを一定数のバッチで制御している。そのため、そのバッチ内のピクセルに対しては、基本的に同じ命令を実行しなければならない。これが、GPUの「分岐粒度ブロック(Branch Granularity Block)」だ。例えば、R520なら分岐粒度ブロックは16ピクセルとなる。
分岐粒度ブロックの中のピクセルが全てシャドウの場合、シェーダは全てのピクセルに対してパスAの命令だけを実行する。ピクセルが全てシャドウにない場合も同じで、パスBだけを実行する。問題は、分岐粒度ブロックの中に、シャドウのピクセルと、シャドウでないピクセルが混在している場合だ。
PC向けのGPUでは、この場合、シェーダはパスAとパスBの両方のパスを、ブロック内の全てのピクセルに対して実行する。複数パスをシリアル化して実行してしまうわけだ。その上で、各ピクセル毎に分岐をチェック、分岐した方の値を取ってアウトプットレジスタに出力する。つまり、シェーダプロセッサ自体は両方のプログラムパスを実行しなければならないため、そのブロックについては、条件分岐をする意味はほぼなくなってしまう。さらに、分岐オーバーヘッドもこれに加わる。
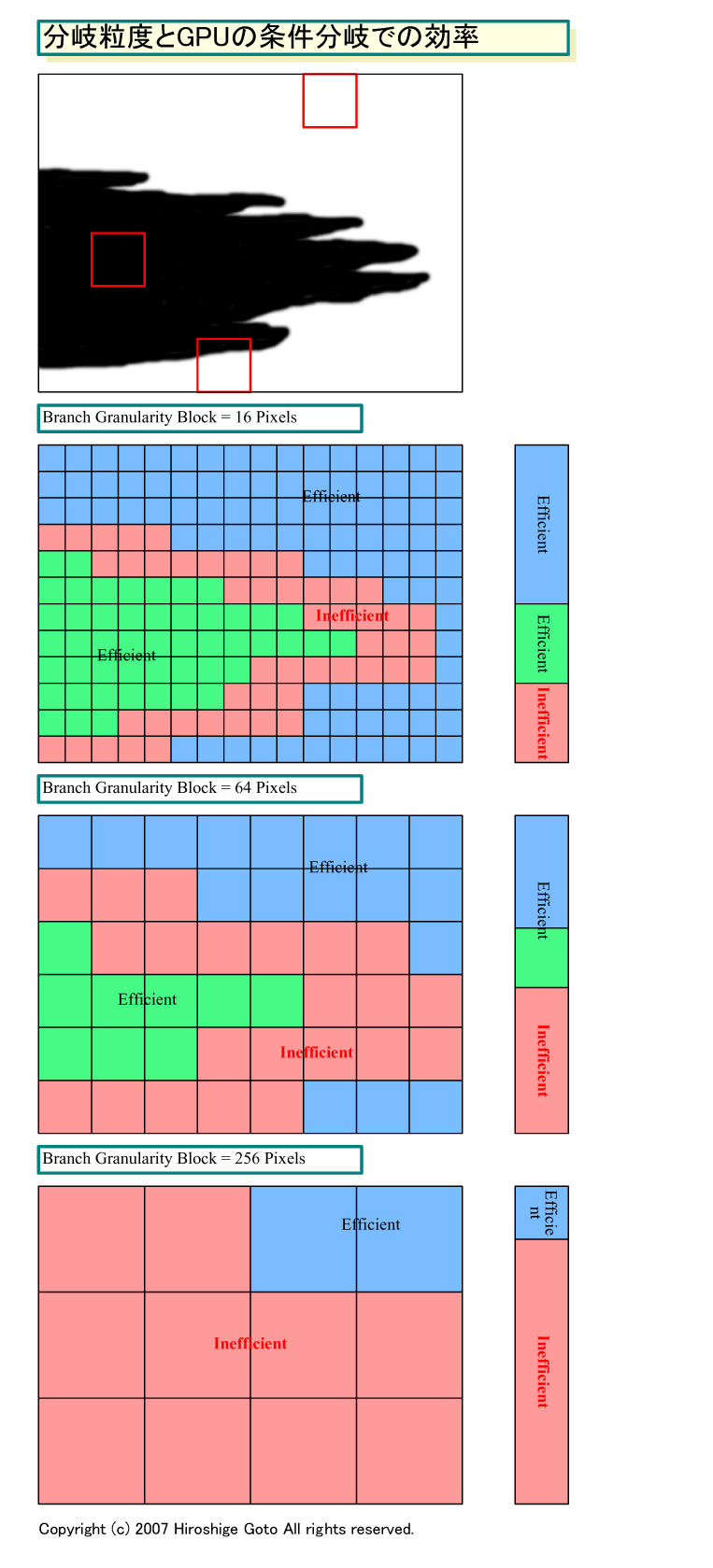
こうした構造にあるため、GPUでは分岐粒度ブロックが大きければ大きいほど、条件分岐時の効率が悪くなる。1つのブロックの中に、異なる分岐が混在する可能性が増えるからだ。下の図は、分岐粒度ブロックが16ピクセルと64ピクセル、256ピクセルの場合の効率を比べたものだ。これを見ると、効率の差が歴然としている。
 |
| 分岐粒度とGPUの条件分岐での効率 ※別ウィンドウで開きます (PDF版はこちら) |
●GPUのトレンドは動的分岐効率の向上
こうした構造であるため、GPUでは、細かく分岐が発生するようなアプリケーションの実行は苦手としている。しかし、シェーダプログラムも進化して、動的な分岐を行なうようになってきた。そして、非グラフィックスアプリケーションでは、動的分岐が必要な分野も多い。分岐時の効率を上げることが求められている。これは、GPUを汎用に使う場合の必須条件と言ってもいい。
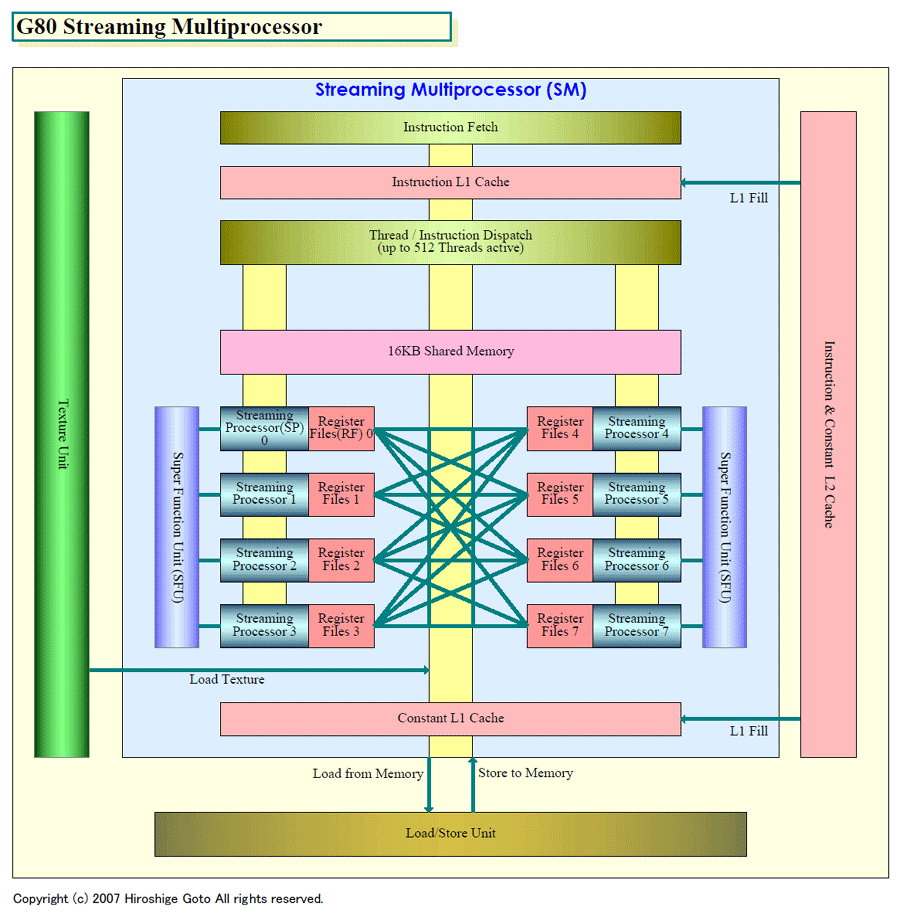
そのため、ここ1~2年のGPUは、いずれも分岐時の効率を上げるために、分岐粒度ブロックを小さくするようにして来た。NVIDIAのG7xからG80への進化は、その典型で、一気に分岐粒度は小さくなった。G80では、スレッドバッチをさらに「WARP」と呼ぶブロックに細分化して制御することで、分岐粒度ブロックを小さくしている。ATIのR600も粒度が小さくなることが、示唆されている。しかし、それでも一定の粒度で制御していること自体は変わらない。
GPUの動的分岐の効率を上げるための理想型は、もちろん1プロセッサ1エレメント単位で分岐制御をできるようにすることだ。CPUと同じように。そうすれば、完全な効率で動的に分岐が大量に発生するプログラムも効率的に実行できるようになる。実際、「Cell Broadband Engine(Cell B.E.)」の「SPU(Synergistic Processor Unit)」は、個々のSPU単位で制御しており、そのためにGPUコアよりも幅広いアプリケーションを柔軟に実行できる。
しかし、これはGPUにとって難しいトレードオフでもある。命令制御の構造を変えて、個々のシェーダプロセッサ単位で制御するとなると、シェーダクラスタが複雑化してしまう。また、データアクセスなど他のボトルネックも発生する。GPUの場合、シェーダプロセッサが一定の粒度でメモリアクセスすることを前提としているからだ。
●GPUのフィロソフィはシンプルなコードを速く実行すること
シェーダクラスタが複雑化すると、結局、GPUに搭載できるシェーダプロセッサの実行ユニット数が減り、その分、GPUのパフォーマンスが削がれてしまう。つまり、GPUの柔軟性を取るか、パフォーマンスを取るかのトレードオフになるわけだ。この選択については、NVIDIAの技術開発部門のトップであるDavid B. Kirk(デビッド・B・カーク)氏(Chief Scientist)が端的に語っている。
「フィロソフィとしては、我々は比較的シンプルなコードをより速く走らせ、その一方で、より複雑なコードについては、やや非効率でもいいと判断した。
もし、分岐予測や命令リオーダリングやレジスタリネーミングといった、(CPUが備える命令制御)機構をGPUに実装したら、シェーダプロセッサは今の10倍の大きさになってしまうだろう。それで、複雑なコードが2倍速く走るだけだとしたら、それはいいトレードオフではない。それよりも、10分の1の小さなシェーダで、(複雑なコードは)2分の1のスピードで走らせる方がいい。これは、GPUとCPUの設計哲学的な違いと言えるだろう」
つまり、GPUは動的に分岐が多発するような複雑なコードは、やや非効率で構わない。犠牲を払ってそこを速くするよりも、シンプルなコードが速く走るように最適化した方がいいと判断しているわけだ。GPUは、あくまでも、多くのデータに同一の処理を行なうことに最適化した、データパラレルプロセッサの枠にある。
もっとも、GPUは従来のアーキテクチャからの進歩も続けている。従来のGPUは、「Embarassingly Parallel」と呼ばれる、依存性のない並列性の処理に特化していた。そのため、演算ユニット間での相互のデータ参照は、遠いメモリを介するしかなかった。しかし、G80ではシェーダプロセッサをバインドした「Streaming Multiprocessor(SM)」単位で、シェーダプロセッサ間で相互アクセスができる共有メモリを16KB備えている。1個のシェーダプロセッサの演算結果を、他のシェーダプロセッサが低レイテンシで参照が可能であり、従来のGPUの制約を軽減している。
 |
| G80 Streaming Multiprocessor ※別ウィンドウで開きます (PDF版はこちら) |
こうしたGPUアーキテクチャの制約の低減は、今後も続くだろう。データパラレルのスタイルは保った上で、許容できるトレードオフの範囲内で、より複雑なプログラムへの対応を図ると見られる。
次の分岐点は、AMDの場合はCPUへの統合だ。最初のFUSIONのステップではわからないが、CPUへのGPUコアの統合を進めて行き、命令セットレベルでの統合を進めると、再びGPUコアの姿は変わって行く。CPUコアとGPUコアが同じメモリ空間を共有し、命令デコードも共有すると、メモリコピーは不要となり低レイテンシでGPUコア機能を使えるようになる。そうした統合に適したGPUコアアーキテクチャを、AMDは模索していると推定される。
□関連記事
【2006年11月27日】【海外】シェーダプログラムの進化と連動するGPUのマルチスレッディング化
http://pc.watch.impress.co.jp/docs/2006/1127/kaigai321.htm
【2006年11月21日】【海外】G80とG7xの最大の違いはマルチスレッディング
http://pc.watch.impress.co.jp/docs/2006/1121/kaigai320.htm
【2006年11月19日】【海外】これがGPUのターニングポイントNVIDIAの次世代GPU「GeForce 8800」
http://pc.watch.impress.co.jp/docs/2006/1109/kaigai316.htm
(2007年3月26日)
[Reported by 後藤 弘茂(Hiroshige Goto)]
【PC Watchホームページ】
PC Watch編集部 pc-watch-info@impress.co.jp ご質問に対して、個別にご回答はいたしません
Copyright (c) 2007 Impress Watch Corporation, an Impress Group company. All rights reserved.