 |


■後藤弘茂のWeekly海外ニュース■GeForce FX 5800とRADEON 9700の明確な方向性の違い |
●ブルートフォースはNVIDIAからATIに移った?
NVIDIAには、これまで明快なGPU開発の思想があった。それは“ブルートフォース(Brute Force:力ずく)”だ。つまり、複雑なアーキテクチャに走るのではなく、ゴリゴリの力押しで解決するのがいい、という考え方だ。これは、勝手に命名したわけではない。実際にNVIDIA自身がそう言っているのだ。例えば、NVIDIAのDavid B. Kirk(デヴィッド・カーク)氏(Chief Scientist)は、以前、次のように語っていた。
「3Dグラフィックスのアルゴリズムが賢い(クレバー)のは素晴らしいが、強い方がもっと素晴らしいと考えている。ほとんどのアルゴリズムは長い目で見ると、ブルートフォースが勝つ。通常のプロセシングは“バリバリ、バン!(crunch, crunch, and bang!)”みたいな、シンプルな方がいい。というのは、シンプルなアプローチを取るなら、どんどん速くできるからだ。結果的に、賢いやり方より速くできる」。
つまり、シンプルなアルゴリズムのハードウェアを高速に動かす方が、効率を上げようとして下手に複雑なハードウェアにするより、結果として処理を速くできるというのがNVIDIAの思想なのだ。これまでは、NVIDIAはボブ・サップばりのGPU業界随一のブルートフォース派で、ほかのメーカーはそれよりは“クレバーネス(知性)”を重視するという色分けだった……これまでは。
今回、DirectX 9世代GPUの戦いでは、まるでNVIDIAとATI Technologiesの位置が入れ替わったように見える。例えば、Platform ConferenceのGPUのパネルディスカッションでは、ATIのRajesh Shakkarwar氏(Director of Marketing)がRADEON 9700(R300)の利点を「ブルートフォースのハードウェアリソースを持つこと」と表現。それに対してNVIDIAのTodd Reddick氏(Sr. Product Manager)は、「プログラマビリティによるGPUの進化」というアーキテクチャ面を強調した。NVIDIAの決まり文句だったブルートフォースを、ATIが奪った格好だ。
もちろん、両社の方向性が完全に入れ替わったわけではない。しかし、今回はATIが自社GPUのブルートフォースパワーに自信を持ち、NVIDIAがアーキテクチャの拡張に注力しているのは確かだ。実際、あるATI関係者は、R300が「GeForce FX 5800(NV30)」に対してパフォーマンスで互角と言っている。かなり近いうちに投入するR300後継GPU「R350」で、NV30を凌駕できると確信しているようだ。対するNVIDIAは、パフォーマンス競争より、自社のシェーダ言語Cgをデベロッパに普及させることに重点を置いているように見える。
●チップの設計に現れる思想の違い
両社のチップの設計を見ても、今回の両社のアプローチの差は感じられる。
R300の構成を見ると、非常にリッチな構成であることがわかる。設計面で冒険は避けつつ、最大の性能を引き出せるように膨大なトランジスタを割いている。
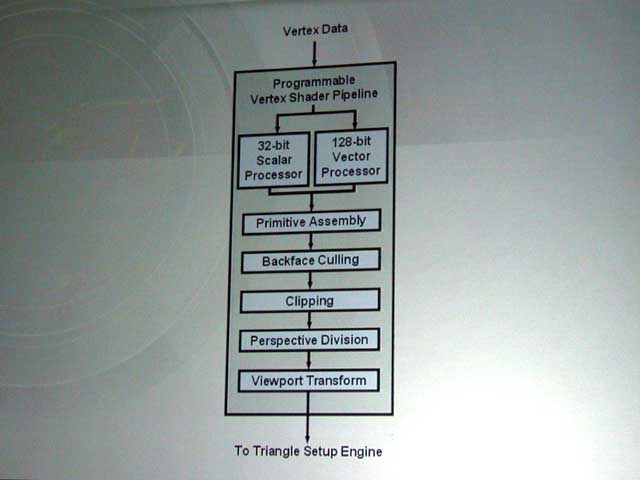
例えば、R300のVertex Shaderは、1Shaderに32bitスカラ演算ユニットと128bit SIMD演算ユニットを1個づつ備える。そのため、SIMD演算ユニットしか持たない通常のGPUと比べると、スカラ演算とSIMD演算を並列に行なうことができる利点を持つ。SIMDユニットを4個の32bit演算ユニット換算だと考えると、4個のVertex Shaderで合計20個分の32bit演算ユニットを持つ計算になる。膨大なリソースだ。ただし、Vertex Shaderは完全に4ユニットに分離しており、スケジューリング(おそらくマルチスレッド化されている)もVertex Shader単位で行なわれるため、効率はNV30ほど高くはできない。
 |
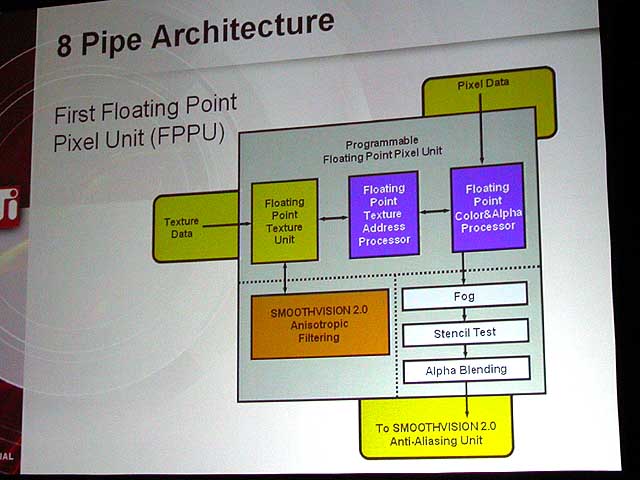 |
| R300のVertex Shader | R300のPixel Shader |
旧来のパイプラインの概念を崩した新アーキテクチャで、効率は高いが、より難しい設計だ。ただしその分、生の演算ユニットの数は、ある程度抑えている可能性が高い。NVIDIAは、NV30のVertex Shader内の演算ユニットの数を明かしていない。しかし、「演算ユニットの総数ではR300より少ないと推測する」とATI以外のあるGPUメーカー関係者は言う。
つまり、Vertex Shaderを見ると、R300はブルートフォース的に拡大しているのに対して、NV30は新アプローチを採って効率を上げようとしているわけだ。
もっとも、「今日のアプリケーションでは、頂点(Vertex)処理はもうボトルネックではない。ピクセルプロセッシングの方がずっとボトルネックになっている。だから、我々はピクセルの方にバリューを加えようとしてきた」とNVIDIAのGeoff Ballew氏(Product Line Manager)は説明している。つまり、NVIDIAのフォーカスはピクセルパイプの方に今はあるというわけだ。
●大きく異なるピクセルパイプのアーキテクチャ
Pixel Shaderでも両チップの設計には、似たような違いがある。例えば、R300はピクセルパイプにテクスチャ処理ユニットとテクスチャアドレス生成ユニットが1個、密接にバインドされている。つまり、従来型のピクセルパイプ構造に近い。もっとも、おそらく、テクスチャユニットもパイプライン化されていて、複数テクスチャの処理をオーバーラップできるようになっている(少なくともテクスチャ処理とアドレス生成は並列できる?)と推測される。ちなみに、DirectX 9の定義では、1パスで最大16テクスチャをサポートする。
それに対して、NV30はテクスチャユニットはパイプから分離。ピクセルパイプから複数のテクスチャユニットにアクセスができるようになっている。また、8個のテクスチャユニットはパイプライン化されていて1テクスチャの処理と1テクスチャのフェッチをオーバーラップして実行できる。そのため、NV30は原理的には、1パスで多くのテクスチャを貼る場合に、動かすパイプを減らして1パイプに割り当てるテクスチャユニット数を増やせば、テクスチャ貼り込みの効率を上げることができる。
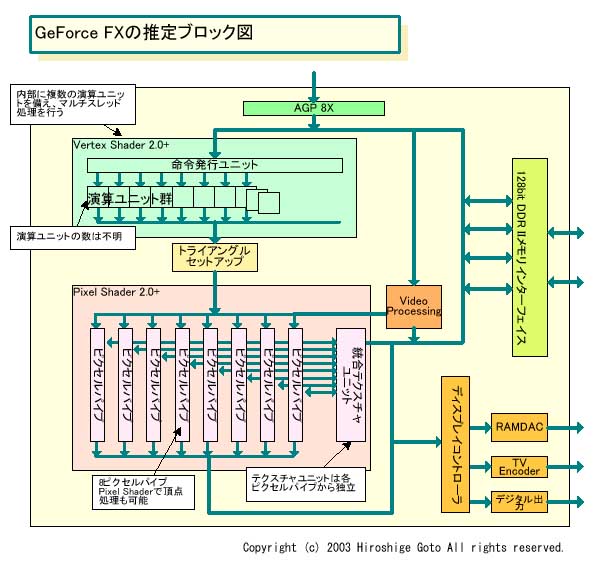 |
| GeForce FXの推定ブロック図 |
いずれにせよ、Pixel Shaderについても、NVIDIAはアーキテクチャ的に拡張してより複雑なアプローチを取り、ATIはシンプルだがブルートフォースのアプローチを取ったと言えそうだ。
●メモリ帯域の必要性に対する2社の認識の違い
メモリインターフェイスにも思想の違いは出ている。ATIは、256bitのDDRメモリインターフェイス(実際にはDDR2メモリにも対応)を採用。それに対して、NVIDIAは128bitのDDR2メモリインターフェイスを採用した。そのため、生メモリ帯域はATI(約20GB/sec)の方がNVIDIA(16GB/sec)に勝っている。そして、今春以降、ATIがDDR2メモリを採用してくると、さらにATIのメモリ帯域はNVIDIAとの差を広げる。
これは、ATIが依然としてメモリ帯域がボトルネックになると見ていることを示している。実際、ATIのDavid E. Orton(デビッド・E・オートン)社長兼COOは「NV30は128bitのメモリインターフェイスであるため、メモリ帯域は絶対に不足する。メモリ帯域は、性能に大きく影響するため、我々が明らかに有利だ」と指摘する。
それに対して、NVIDIAのKirk氏は「現状では、私はメモリ帯域がそんなにボトルネックだとは思わない。バランスとしては、拡張された(今の)メモリ帯域に合わせるには、もっとパワフルなパイプラインを作る必要がある」という。なぜこんなに意見が食い違うのか?
この相違が示しているのも、GPUのあり方だ。ATIはブルートフォース、つまり、解像度を上げ重いFSAAやフィルタリングをかけるといった処理の性能を重視する方向にあるように見える。メモリ帯域が必要になる、そうした性能を重視するために、メモリインターフェイスを拡張したと見られる。
それに対して、NVIDIAはGPUの方向性はシェーダプログラムの実行性能にあると考えているようだ。つまり、解像度や固定機能のFSAAやフィルタリングはそこそこでいいから、それよりもShader上でより高度で複雑なシェーダプログラムを走らせられるようにしようというわけだ。GPUのサイクルタイムを、Shader内部でシェーダプログラムを実行するのに費やすなら、相対的にメモリ帯域拡張の必要性の度合いは薄まる。だからNV30では、このメモリ帯域で十分と言っているのだと推測される。
こうしてみると、R300は従来アプローチの延長でブルートフォースを目指し、それに対してNVIDIAはアーキテクチャの拡張を目指したという路線の違いが浮き彫りになってくる。NVIDIAとしては、GPUの0.13μmプロセス化とDDR2メモリによって周波数が上がる分で、十分パフォーマンスで他社を引き離せると踏んだのだと思う。誤算は、今回ATIがここまでブルートフォースに迫って、既存のベンチマークでのパフォーマンスを伸ばしたことにあったと思う。
だが、これまでの例を見ると、市場で成功したのは、必ずブルートフォース派だった。アーキテクチャを拡張したうんぬんというのは、市場でユーザーを惹きつける要素には必ずしもならなかった。今回は、どうなのだろうか。
もちろん、状況の違いはある。DirectX 9はアーキテクチャの転換点で、デベロッパはアーキテクチャの拡張を歓迎する雰囲気にある。Carmack氏だって、R300ではShaderの制約にもうぶつかってしまっていると指摘している。だから、NVIDIAのアプローチの方がデベロッパに支持される可能性はかなりある。
それから、NVIDIAがこれまで築いてきた資産も大きい。ここ数年で同社は、ゲーマーとデベロッパの両方に食い込んできた。高いドライバの品質も支持を得ているポイントで、これはライバルがまだ追いつけない点のひとつだ。というわけで、まだ状況は混沌としている。
□関連記事
【2月6日】【海外】期待はずれ? それとも期待通り? GeForce FXの性能の謎
http://pc.watch.impress.co.jp/docs/2003/0206/kaigai01.htm
【1月16日】【海外】GeForce FXのピクセルパイプは8本、テクスチャユニットは分離
http://pc.watch.impress.co.jp/docs/2003/0116/kaigai01.htm
【2002年12月20日】【海外】GeForce FXの秘密
http://pc.watch.impress.co.jp/docs/2002/1220/kaigai01.htm
【2002年12月18日】【海外】製造コストが非常に高い? GeForce FXの勝算
http://pc.watch.impress.co.jp/docs/2002/1218/kaigai01.htm
【2002年12月11日】【海外】NVIDIAインタビュー(上)
~GeForce FXの高クロックと高パフォーマンスの秘密
http://pc.watch.impress.co.jp/docs/2002/1211/kaigai01.htm
【2002年12月11日】【海外】NVIDIAインタビュー(下)
~プログラム性と性能の両立を重視するGeForce FX
http://pc.watch.impress.co.jp/docs/2002/1211/kaigai02.htm
【2002年11月20日】【海外】ついにベールを脱いだNVIDIAの次世代GPU「GeForce FX(NV30)」
http://pc.watch.impress.co.jp/docs/2002/1120/kaigai01.htm
【2002年11月19日】【COMDEX】NVIDIAが次世代GPUのNV30をGeForce FXとして正式発表
http://pc.watch.impress.co.jp/docs/2002/1119/comdex04.htm
(2003年2月7日)
[Reported by 後藤 弘茂]
【PC Watchホームページ】
PC Watch編集部 pc-watch-info@impress.co.jp 個別にご回答することはいたしかねます。
Copyright (c) 2003 Impress Corporation All rights reserved.