 |


■後藤弘茂のWeekly海外ニュース■ついにベールを脱いだNVIDIAの次世代GPU「GeForce FX(NV30)」 |
●NV30のデモを大々的に行なう
NVIDIAのNV30がいよいよ姿を現した……といってもまだ完全ではないが。
NVIDIAは、NV30のコードネームで呼ばれていた次世代GPU「GeForce FX」の公開デモを、COMDEX第1日目に合わせてLas Vegasで行なった。今回のイベントは、実際に発売する製品の発表というより、技術デモに近い。OEMボードの展示もなければ、価格や製品ラインナップの発表もない。正式な“製品発表”は、まだ先という雰囲気だ。
 |
 |
| GeForce FXを発表するNVIDIAのJen-Hsun Huang社長兼CEO | GeForce FXを搭載したリファレンスカード |
しかし、それでも衝撃は大きい。ATI TechnologiesのRADEON 9700に王者の座を奪われたNVIDIAが、反撃ののろしを上げたのだから。コア500MHz、メモリ1GHzというスペックも、インパクトが強い。加えて、NVIDIAは今回の発表に際して、シェーダプログラムを使った印象的なデモを準備。GeForce FXの高度なプログラマビリティが、実際にどんなグラフィックスを作れるのかをアピールした。NVIDIAの見せ方のうまさは、ATIをはるかに上回っており、デモ自体はインパクトが強かった。
まず、発表内容を整理すると、今回発表されたのは次世代アーキテクチャ「NV3xファミリ」の最初のハイエンドGPU「NV30」だけだ。後続の製品はまだ発表されていない。
NV3xファミリは、Microsoftの次世代マルチメディアAPI「DirectX9」に準拠したGPU世代。GPUの処理の多くを、プログラマブルな演算ユニット「Programable Shader」で実行する新世代のGPUだ。Shaderには、ジオメトリ処理用のVertex Shaderと、テクスチャ処理用のPixel Shaderがある。DirectX9世代GPUは、このProgramable Shader上で走らせるシェーダプログラムによって、従来よりはるかに複雑で高品質のグラフィックスを実現する。NVIDIAでは、シェーダを記述するためのシェーディング言語(グラフィックス向け言語)「Cg」も提供する。
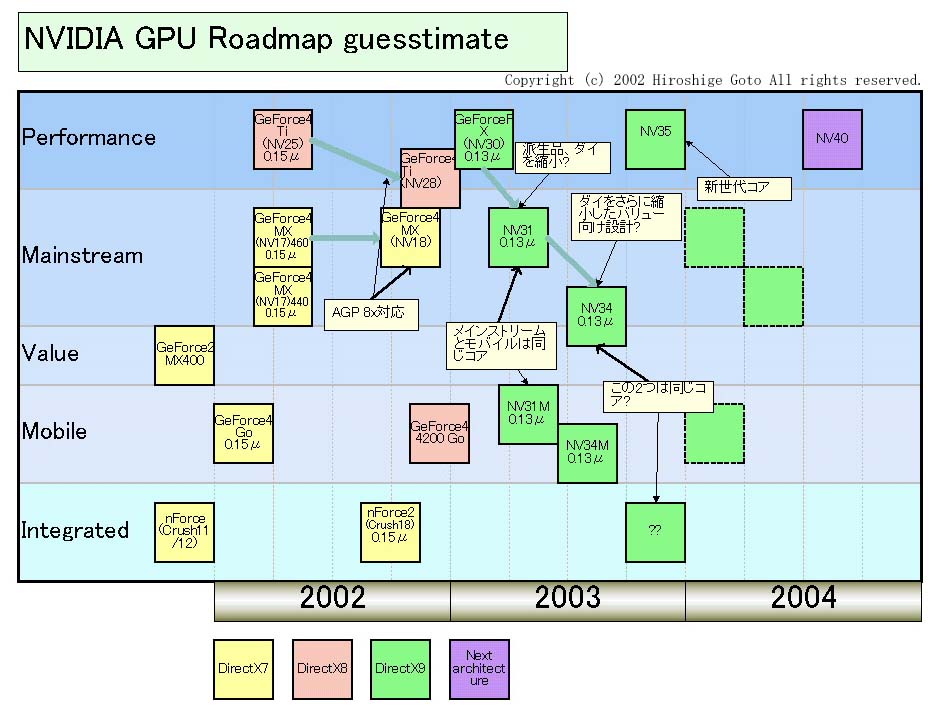 |
| NVIDIA GPU 推定ロードマップ (別ウィンドウで開きます) |
●コアクロックを500MHzへ
 |
| トランジスタ数は1億2,500万となった |
今回はGeForce FXのクロックやパイプライン数などの概要も明らかになった。コアクロックの500MHzは、2003年前半のGPUとしては、おそらく最強だ。0.15μm→0.13μmへのプロセス微細化だけでは、単純計算では1.3~1.5倍程度しかクロックが上がらない。NV25から計算すると450MHzがせいぜいとなり、500MHzには到達できない。そのため、GeForce FXでは高クロック化のために、処理パイプラインにかなり手が加えられていると考えられる。パイプラインをすっきり作り、できるだけスピードを上げるという『ブルートフォース』派のアーキテクチャは、NVIDIAの伝統だ。
ピクセルパイプは8本とNV25までの世代の2倍になった。これは予想通りだ。というのは、倍増させないと速くならないからだ。GPUに限らずプログラム性と性能は、ある程度トレードオフの関係にある。一般に、同じ処理を実行する場合、プログラマブルユニットでの性能は、ハードワイヤド実装の場合より落ちる。そのため、プログラム性を強化するDirectX9世代のハイエンドGPUは、前世代よりもユニット数を増やすことで、そのトレードオフをカバーしなければならない。おそらく、Vertex Shader数も2倍になっているはずだ。
●メモリにDDR II 1GHzを採用
メモリは予想に反して128bitインターフェイス。通常、ピクセルパイプの本数とメモリインターフェイスの幅は連動するため、8パイプのハイエンドGPUは256bit幅インターフェイスになると見られていた。
その代わりNVIDIAはDDR IIをNV30に採用、メモリを1GHzに高速化した。DRAMベンダーはSamsung Electronicsで、ピーク帯域は17.1GB/secとなる。256bitインターフェイスのRADEON 9700(R300)の20.8GB/secには及ばないが、これまでのDDR 600MHz台クラスの10GB/sec前後と比べると大幅に高速化されている。
4カ月前は、DDR IIの採用はもう少し先になるとNVIDIAは説明していたので、路線が変わった可能性がある。DDRベースのグラフィックスメモリは700MHz台が限界と言われており、それ以上の帯域を求めるためにDDR IIに移行したと見られる。
もっとも、ここで言うDDR IIは、JEDEC規格のDDR IIではない。グラフィックス用DDR IIで、以前Samsung Electronicsに聞いた時は、JEDECのメインメモリ規格のDDR IIが含む「OCD(Off Chip Driver) Calibration」や「On-Die Termination(ODT)」など、後からDDR IIに加わった機能は持っていないと説明していた。これらの機能は、グラフィックスではほぼ必要がないと言われる。ちなみに、現在、高速のグラフィックス用DDR IIの量産準備を整えているのは、Samsungだけだ。
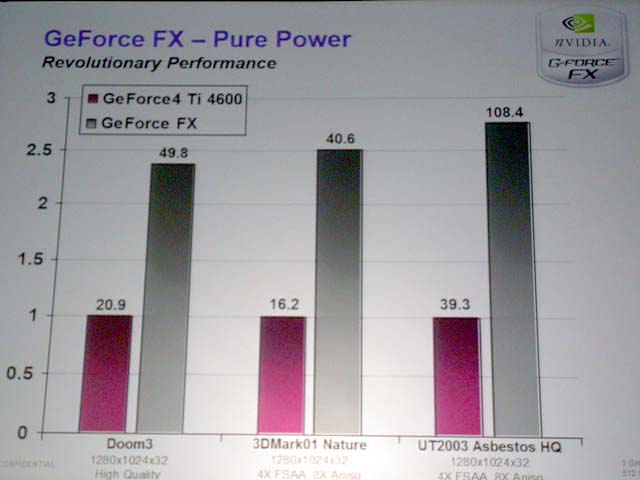
●劇的なパフォーマンス
GeForce FXのパフォーマンスは、劇的に速い。下が、発表会のプレゼンテーションで示されたパフォーマンスだ。しかし、性能が高いのは当然で、コア500MHzで8ピクセルパイプで処理をすれば、速くないわけはない。もっとも、DirectX9世代のGPUの真の性能は、既存のベンチではほぼ測ることができない。DirectX9世代GPUの真髄はプログラマビリティにあるためだ。
 |
 |
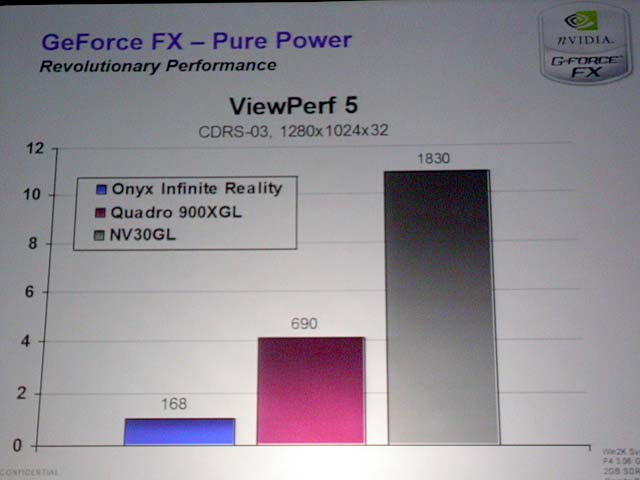 |
| Quak IIIのパフォーマンスをGeForce 4 Ti 4600と比較 | Doom3、3DMark2001、Unreal Tournament 2003のパフォーマンスをGeForce 4 Ti 4600と比較 | Open GLのベンチマーク「ViewPerf 5」のパフォーマンスをQuadroらと比較 |
 |
 |
 |
| 【ムービー】(約3.2MB/MPEG-1) GeForce FXのデモ(1) 解説(英文) |
【ムービー】(約4.2MB/MPEG-1) GeForce FXのデモ(2) 解説(英文) |
【ムービー】(約5.9MB/MPEG-1) GeForce FXのデモ(3) 解説(英文) |
DirectX9世代GPUでは、性能はイコールクオリティになる。高速なGPUでは、シェーダの実行により多くのクロックサイクルをかけられるため、より大きなシェーダプログラムを実行できるようになるからだ。例えば、あるGPUではピクセルシェーダで100命令をリアルタイムに処理できるだけだが、あるGPUでは300命令をリアルタイムに処理できるといった違いが出てくる。後者のGPUの方が、より複雑なシェーダプログラムを実行することで、より高クオリティの絵を作り出せるようになる。
これは、ちょうど高速なCPUになると、より重いアプリケーションも快適に利用できるようになるのと同じことだ。そのため、ここに出ている性能は、ベーシックな機能を示す単なる指標に過ぎない。
●強力なGeForce FXのアーキテクチャ
その意味で重要なのはGeForce FXのアーキテクチャだ。GeForce FXは、これから来年にかけて登場するDirectX9世代GPUの中でも、際だってユニークなアーキテクチャを備えている。
GeForce FXのアーキテクチャは、NVIDIAが「CineFX」と呼ぶ新世代のものだ。CineFXは、NVIDIA流に言えば“映画品質のレンダリングをリアルタイムに可能にする”アーキテクチャとなる。実態は、Microsoftの次世代マルチメディアAPI「DirectX9」をベースにさらに拡張を加えたものだ。DirectX9と比べて、命令セットやレジスタなどを大きく拡張した、DirectX9のスーパーセットとなっている。今のところ、DirectX9の拡張を公言しているのは、NVIDIAだけだ。
例えば、DirectX9ではVertex Shaderはループを含めても最大で1,024命令しかサポートできないが、CineFXでは最大で65,536命令をサポートできる。データディペンデントなループと分岐により、よりプロセッサライクなプログラミングができる。また三角関数など新たな演算命令がサポートされるために、波打つ海面のようなエフェクトをVertex Shader上の数値演算だけで表現できるようになる。
Pixel Shaderも同様に拡張されている。DirectX9ではテクスチャ命令が最大32、カラー命令が最大64だったが、CineFXでは最大1,024のシェーダ命令がサポートされる。また、依存テクスチャ読み出し(dependent texture read)回数はDirectX9では4に制限されているのに対して、CineFXでは制約がなく完全にプログラマブルとなっている。さらに、CineFXでは、Vertex Shaderの命令のほとんどもPixel Shader側にインプリメントされる。そのため、やろうと思えば、Pixel Shader側でジオメトリプロセッシングを行なうことも可能になるという。
CineFXではデータ精度も上がる。64/128bit浮動小数点カラーがサポートされる。つまり、各色16bitまたは32bitの浮動小数点のカラーデータフォーマットをNV30は扱うことができる。そのため、現在グラフィックスワークステーションのCPUを使って行なっているシェーディング処理が、そのままの精度でNV30に移植できるとNVIDIAはいう(反論もある)。
こうした拡張は、大規模化するシェーダプログラムを実行できるだけのパフォーマンスを前提としなければできない。パフォーマンスが低ければ、シェーダプログラムの規模が大きくなると、リアルタイムに実行できなくなってしまうからだ。つまり、NVIDIAは、パフォーマンスを引き上げることがイコール高品質のグラフィックスになるという、シェーダ時代のGPUのあり方を目指しているわけだ。
実際、今回のNVIDIAは、こうしたシェーダの性能を見せるタイプのデモに集中した。つまり、“どれだけ速い”とアピールするのではなく、“どれだけきれい”かを打ち出すことに専念した。映画品質のレンダリングをリアルタイムに可能にすると強調した格好だ。その目論みが本当に成功するかどうかは、まだわからないが。
□NVIDIAのホームページ(英文)
http://www.nvidia.com/
□ニュースリリース(英文)
http://www.nvidia.com/view.asp?IO=IO_20021117_7139
□関連記事
【11月19日】NVIDIAが次世代GPUのNV30をGeForce FXとして正式発表
http://pc.watch.impress.co.jp/docs/2002/1119/comdex04.htm
(2002年11月20日)
[Reported by 後藤 弘茂]
【PC Watchホームページ】
PC Watch編集部 pc-watch-info@impress.co.jp 個別にご回答することはいたしかねます。
Copyright (c) 2002 Impress Corporation All rights reserved.