 |


■後藤弘茂のWeekly海外ニュース■GeForce FXのピクセルパイプは8本、テクスチャユニットは分離 |
●構造も変わったGeForce FXのピクセルパイプ
NVIDIAが「GeForce FX(NV30)」の投入準備を進めている。予定よりはずれ込みそうだが、いちおうカウントダウンは始まった。前回のコラム「GeForce FXの秘密-Vertex Shaderは完全に新アーキテクチャに」では、NVIDIAのVertex ShaderやDisplacement Mappingの仕組みを説明した。今回は、ピクセルパイプの仕組みを見てみたい。
GeForce FXのピクセルパイプは8本。GeForce4 Ti(NV25)の4本から2倍に増えた。しかし、数が増えただけでなく、ピクセル部の構造自体が、以前のアーキテクチャとは変わっている。
「過去の(固定テクスチャユニットの)アーキテクチャでは、各パイプラインは専用のテクスチャユニットを備えていた。しかし、前世代から、パイプラインとテクスチャユニットという形に変え始めた。シングルピクセルパイプでより多くのテクスチャを貼れるようにするためだ。よりプロシージュアル(手続き)型のシェーディングとフルプログラマビリティ(プログラム性)へと、移行するためでもある」NVIDIAでGeForce FXを担当するGeoff Ballew氏(NVIDIA, Product Line Manager)氏は説明する。
つまり、従来の固定テクスチャユニットアーキテクチャでは、1パイプ当たり2テクスチャと言った場合には、実際にテクスチャユニットを各パイプごとに2ユニットづつ備えていた。しかし、GeForce FXの場合には、まず固定テクスチャユニットは一切持たない。また、Pixel Shaderにテクスチャデータを供給するテクスチャユニット群も、パイプラインから独立している。8本のパイプラインが複数のテクスチャユニットをフレキシブルに利用できるようになっている。これは、ちょうど現在のCPUが、演算ユニットからロード/ストアユニット(データの読み出し書き込みを処理するユニット)を分離しているのと似ている。
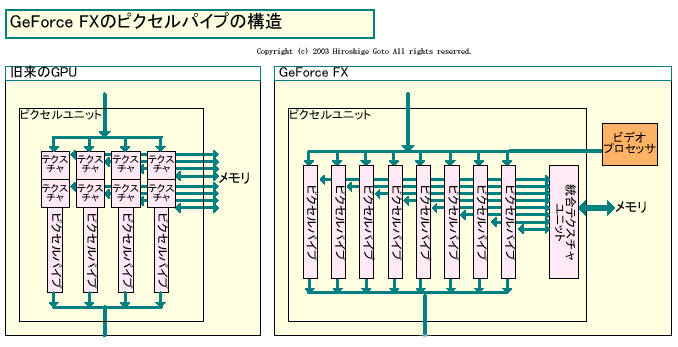 |
では、このGeForce FXのテクスチャユニットの処理性能はどの程度なのか。
「(GeForce FXでは)最大8テクスチャ/クロックが可能だ。しかし、テクスチャアドレシングリソース自体は16テクスチャ分ある。つまり、クロック当たりは8テクスチャしか適用できなくとも、16のアクティブテクスチャを扱うことができる」とBallew氏は言う。
つまり、テクスチャユニット群は1クロック当たりでは合計8テクスチャ処理しかできない。だが、各ユニットごとに平行して1テクスチャ分(合計で16テクスチャ)のアドレス生成が可能となる。そのため、1つのテクスチャ群を貼り込んでいる間に、オーバーラップして次のテクスチャ群のフェッチが可能だ。
この効用のひとつは、テクスチャ読み出しのレイテンシを隠蔽することだ。
「16テクスチャアドレッシングを備える理由のひとつはそれだ。8テクスチャを読み出している間に、次の8テクスチャのセットのアドレッシングができる。例えば、4ピクセルを扱っていて2テクスチャを一度に貼りたいとする。その場合、4ピクセルパイプをアクティブにして、8テクスチャユニットをアクティブにする。するとテクスチャユニットはフルに詰まっているが、その間も次の8テクスチャのアドレッシングを行なうことができる」とBallew氏は説明する。
API側であるDirectX9アーキテクチャでは、パイプライン当たり最大16テクスチャがサポートされる。GeForce FXのユニット構成でそれもカバーされる。実際、GeForce FXの発表でNVIDIAが見せた妖精のデモでは「最大で14テクスチャを使っている」(Ballew氏)という。つまり、この構成はテクスチャユニットをフレキシブルにすることで、より多くのテクスチャをシェーディングプログラムの中で使えるようにすると言うわけだ。
●重要性が低くなったパイプラインの本数
GeForce FXではピクセルパイプラインが2倍になった点に目を奪われる。しかし、Ballew氏はパイプライン数の重要性はそれほどではなくなったと言う。
「プロシージュアルシェーディングへ移行したために、パイプラインの数は以前ほど重要ではなくなった。より重要なのは、シェーディング演算の速度(Shaderの効率)だ。より多くのテクスチャや命令を使おうとすると、Shaderがより速く動かなければならない。8ピクセルシェーダで、多分最大で300~400命令を扱うことができる」
単純なパイプ数ではなく、Shaderの演算ユニットとしての性能が重要になるというわけだ。実際にGeForce FXの構造だと必ず8ピクセル/クロックでパイプラインが動作できるわけではない。テクスチャユニットの制約から同時処理は4ピクセル/クロックや2ピクセル/クロックに留まるケースも出てくる。そのため、パイプライン数はピクセル部でのスループットのピークを示す指標にしかならない。
おそらく、これはDirectX9世代のGPUに共通したことだと推測される。また、今後のGPUの性能は、扱えるピクセル数ではなく、実行できるシェーディングプログラムの規模や複雑さで測られるようになるだろう。そして、どれだけ複雑なシェーディングプログラムを実行できるかはShaderの実効性能に左右される。そうすると、今後のGPUのスペックでは、パイプライン数よりもShader効率が重要になるかもしれない。
そうした背景から、今後はShaderの効率を上げるためのアーキテクチャが重要となる。「Shaderの効率化のためには、(GPUの)キャッシュサイズなども適正にする必要がある。テクスチャをキューに留めておくことで、効率よく、次々にテクスチャデータのフェッチ要求を出すことができる」(Ballew氏)というわけだ。
●トレードオフで妥協した? 128bitピクセルデータサポート
NVIDIAはGeForce FXではPixel Shaderの機能をDirectX9スペックより大きく拡大した。中でも目立つのは128bit(各色32bit)の浮動小数点精度ピクセル(フロートピクセル)のサポートだ。しかし、128bit時には大きな制約がある。例えば、グラフィックスに詳しいライターの西川善司氏は、フィルタリングやブレンディング、MIPマッピングなどが128bit時にサポートされない点を指摘する。
実際、GeForce FXではこうした処理を行なうユニットは、128bit浮動小数点に対応していない。DirectX9の定義でもそうなっている。これについてBallew氏は次のように説明する。
「(128bit幅の)ハードウェアのフィルタリングユニットは備えていない。しかし、ある程度似たようなエフェクトはPixel Shaderで加えることができる。また、128bit環境になったら、伝統的なフィルタリングアルゴリズムはあまり適していないだろう」
だが、この制約のためせっかくの128bitフォーマットも使いにくいのは確かだ。
もっとも、これらの機能は、NVIDIAが不要と考えて省いたというより、トランジスタ数の制約で入れることができなかった部分もあると推測される。
「まだ128bitのエントリポイントの段階で、トレードオフがあるのは仕方がない。開発者の中にはフル機能を望む人もいるだろうし、今すぐにこの機能を使い始める人もいるだろう。3Dグラフィックスはトランジスタを消費するため、全ての機能を実現はできない、ある機能は後回しになったりする」(Ballew氏)
つまり、今回のNVIDIAの128bitピクセルデータタイプのサポートは第1段階に過ぎず、今後のGPUで拡張していく可能性が高い。実際のところ、128bit化については、Vertex Shaderと同等のデータタイプにすることで、Displacement MappingなどをPixel Shader側で実行できるようにするところにもかなりの比重があった可能性がある。つまり、ピクセル/テクスチャ処理のフル機能を128bit化するのは後回しになったということかもしれない。各パイプに備えられているフィルタリングやブレンディングの固定機能ユニットをそれぞれ128bit化することは、トランジスタ数をかなり増やすことになると推測される。ただでさえダイサイズ(半導体本体の面積)の大きいGeForce FXにとっては、コスト増の影響は大きい。
もうひとつの考え方としては、NVIDIAは最終的にフィルタリングなどもShader側で処理する方向へ持っていく可能性もある。
□関連記事
【2002年12月20日】【海外】GeForce FXの秘密
~Vertex Shaderは完全に新アーキテクチャに
http://pc.watch.impress.co.jp/docs/2002/1220/kaigai01.htm
(2003年1月16日)
[Reported by 後藤 弘茂]
【PC Watchホームページ】
PC Watch編集部 pc-watch-info@impress.co.jp 個別にご回答することはいたしかねます。
Copyright (c) 2003 Impress Corporation All rights reserved.