 |


■後藤弘茂のWeekly海外ニュース■Cell B.E.と似て非なるLarrabeeの内部構造 |
●L2キャッシュを各コアに持つLarrabee
Intelは、グラフィックス製品として投入する「Larrabee(ララビー)」のベースアーキテクチャを明らかにし始めた。Larrabeeについては、8月中に行なわれる「SIGGRAPH」、「Intel Developer Forum (IDF)」、「HotChips」の3つのカンファレンスを通じて明らかにされて行くと見られる。
まず、前回の記事の訂正から。最初の世代のLarrabeeのCPUコア数は、16コアと見られ、前回に10コアと書いたのは間違いだ。Larrabeeでは、4MBのL2キャッシュが、それぞれCPUコアと直結した256KBのL2キャッシュのローカルサブセット(Local Subset)に分割されている。合計では16コアのサブセットL2で、4MBのL2キャッシュを構成する計算となる。65nmプロセス換算で10コアであるため、45nmのLarrabeeで16コアは妥当な数字だ。各固定機能ユニットがL2を持つ可能性は低いため、CPUコア数は計算上16コアで、従って推定されるブロック図は下のようになる。
 |
| Larrabeeのブロックダイヤグラム(筆者推測) ※PDF版はこちら |
Larrabeeの固定機能ユニットであるテクスチャフィルタリングユニットは、各コアにつき32KBのテクスチャキャッシュを提供することができるとされている。しかし、このキャッシュはテクスチャキャッシュに付属するのではなく、各コアのキャッシュ上にエリアを取ると推定される。もし、テクスチャユニットが、フィルタ前のテクスチャデータ用に専用L2キャッシュを備えており、それが4MBにカウントされているとしたら、CPUコアの数は減ることになるが、現在の推定では16コアとなる。
16コアはアーキテクチャ上の限界ではなく、コア数を増やすことも可能だ。CPUコア数を増やす場合に、問題となるのは、コア間を接続するリングバスの帯域だが、それも解決する手段があるという。SIGGRAPHの論文「Larrabee: A Many-Core x86 Architecture for Visual Computing」によると、16コアまでは双方向の1ペアリング(各512bits幅)で接続するが、それ以上にコアが増えた場合は2リングに分けて接続するという。ちなみに、同じくリングバスを採用するCell Broadband Engine(Cell B.E.)でも、CPUコアの数を増やす場合には似たような構成を取ることができると説明していた。初代Larrabeeの後に控える、プロセス微細化版のLarrabee 2の主目的は、消費電力とコストの低減だが、24コア版の噂もある。
LarrabeeのL2キャッシュは分割されていると言うより、実質的には、各コアの占有L2キャッシュの合計が4MBと表現した方が正しいと思われる。各CPUコアがそれぞれ密接に接続された比較的低レイテンシの占有L2キャッシュを持つ構成だと見られる。各コアとL2キャッシュローカルサブセットのノードが、広帯域のリングバスに接続されており、キャッシュメモリのコヒーレンシがハードウェアで保たれている。
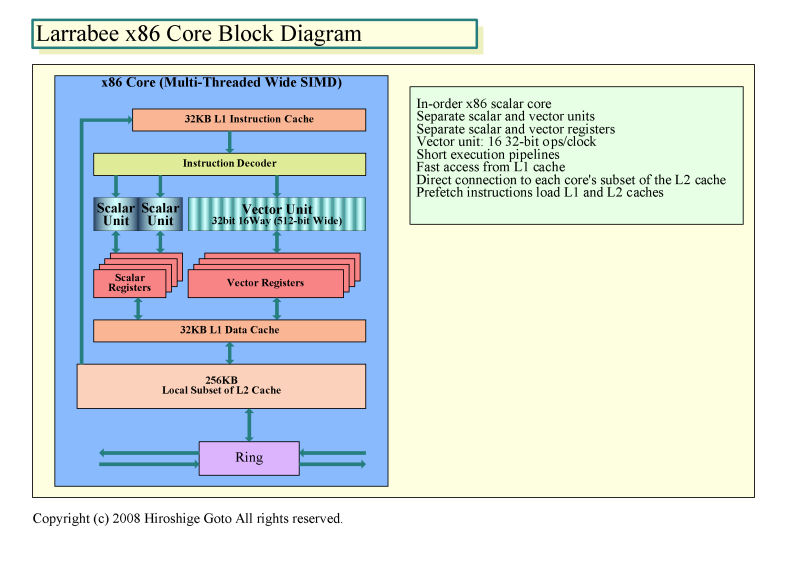 |
| Larrabee x86コアのブロックダイヤグラム ※PDF版はこちら |
●キャッシュとスクラッチパッドの違い
リングバスに接続されたCPUコアがそれぞれ比較的小容量のメモリを持つ構成はCell B.E.によく似ている。Cell B.E.では、リングバス「Element Interconnect Bus (EIB)」に、1個の制御用CPUコア「PPE (Power Processor Element)」と、各256KBのメモリを備えた8個のデータプロセッシング用CPUコア「SPE (Synergistic Processor Element)」が接続されている。しかし、大きな違いもある。Cell B.E.では各CPUコアに用意されたローカルストアメモリは、キャッシュではなく、ハードウェアでのコヒーレンシ制御は行なっていない。完全にソフトウェア制御であり、通常はプログラマがマネージを考える必要がある。
これは、最新のGPUアーキテクチャでも同じだ。NVIDIAのGeForce 8800(G80)/GTX 200(GT200)アーキテクチャでは、プロセッサクラスタである「Streaming Multiprocessor (SM)」毎に16KBの共有メモリを持っている。この共有メモリは、明示的にアクセス可能なスクラッチパッドメモリであり、コヒーレンシを保つハードウェアメカニズムは持たない。G80/GT200と同様の共有メモリを備えるAMD(旧ATI)のRadeon HD 4800(RV770)でも同じだ。
Cell B.E.やGPUがキャッシュではなくスクラッチパッドメモリにした理由は、ストリームプロセッシングではキャッシュが有効ではないためだ。有効でない機能にリソースを割くことは無駄だと判断したという。これについては、Cell B.E.アーキテクトもGPUアーキテクトも、同じ説明をしていた。
Intelは、データプリフェッチ命令と、キャッシュ制御の命令モードを加えることで、Larrabeeではキャッシュをスクラッチパッドのように使うことができるようにしたという。ストリームプロセッシングに多い、CPUコアにいったん読み込んでしまえば、不要なデータはキャッシュからすぐに追い出すことができるようにプライオリティを下げたマーキングを行なう。この手法は、L2キャッシュメモリが各コア256KBと少ないIntelの次期PC向けCPUマイクロアーキテクチャ「Intel Core i7 (Nehalem:ネハーレン)」のヒントになるかもしれない。
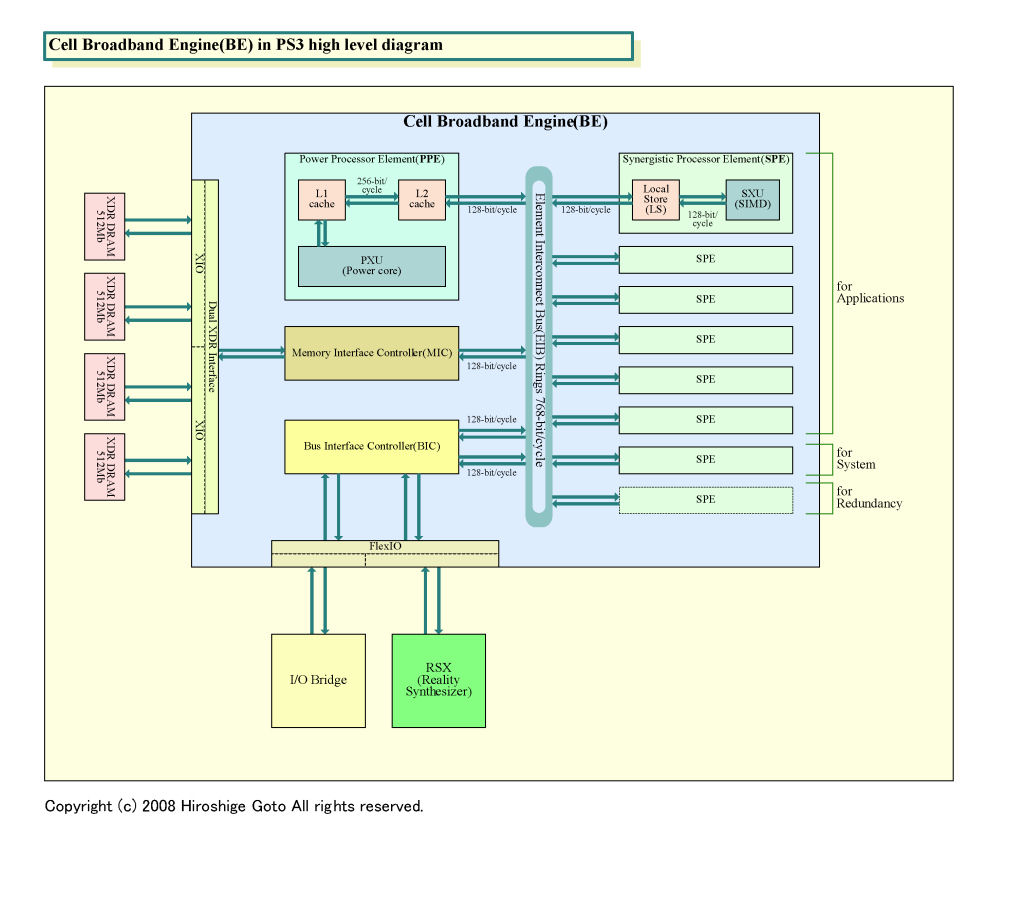 |
| PS3用Cell B.E.の高次元ダイヤグラム ※PDF版はこちら |
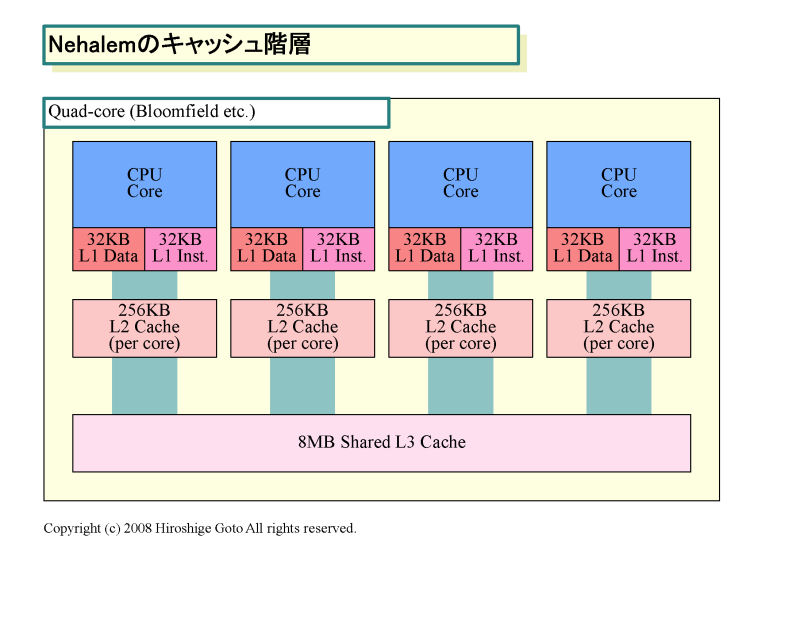 |
| Nehalemのキャッシュ階層 ※PDF版はこちら |
●Pentiumを出発点に発展させたLarrabeeアーキテクチャ
LarrabeeのCPUコアのマイクロアーキテクチャ自体は、Pentium (P5)をアイデアの基本にして、発展させたものだ。Pentiumからはかけ離れて、大きく拡張されているが、基本ラインは似ている。インオーダ実行のデュアルイシューパイプラインであり、アウトオブオーダ実行の3~4イシューパイプラインであるPentium Pro (P6)以降のマイクロアーキテクチャとはベースラインが大きく異なる。Larrabeeは、ラフに言えばPentiumのデュアルイシューのスカラパイプラインに、16-wayベクタのベクタプロセッシングユニットを付け加えたような構成となっている。
興味深いのは、この先祖返り現象だ。IntelのPentium M (Banias:バニアス)マイクロアーキテクチャはPentium Pro/IIIから発展し、Core Microarchitecture (Core MA)にまで進化した。また、Atom (Silverthorne:シルバーソーン)はシングルイシューのインオーダ実行のマイクロアーキテクチャからスタートしてアイデアを発展させた。言ってみれば486世代をベースに膨らませて、Larrabeeと同じインオーダ実行のデュアルイシューパイプラインにたどり着いた。
このところ登場したIntelの新しいCPUマイクロアーキテクチャが、ことごとく旧世代のCPUをベースにしている。これは、もちろん偶然ではない。
理由は明白で、『ポラックの法則(Pollack's Rule)』とIntelが呼んでいるCPU開発の経験則があるためだ。ポラックの法則では、同じプロセス技術でCPUのダイサイズ(=トランジスタ数)を2~3倍に増やしても、整数演算パフォーマンスはその平方根程度の約1.5~1.7倍にしか伸びないとされている。
SIGGRAPHでのLarrabeeの論文でも、ポラックの法則が引用されている。シングルストリームのパフォーマンスを向上させるために、ポラックの法則によって、パフォーマンス/消費電力の悪化を招いているのが、現在の汎用CPUだという。ポラックの法則によって増えたCPUコアの面積と電力を減らすには、CPUマイクロアーキテクチャの世代を巻き戻すのが一番というわけだ。
CPUマイクロアーキテクチャを1世代巻き戻せば、CPUコアのサイズを1/2~1/3にすることができる。そのため、電力効率が重視される現在のCPUマイクロアーキテクチャでは、古い世代のアーキテクチャをベースとするようになっている。
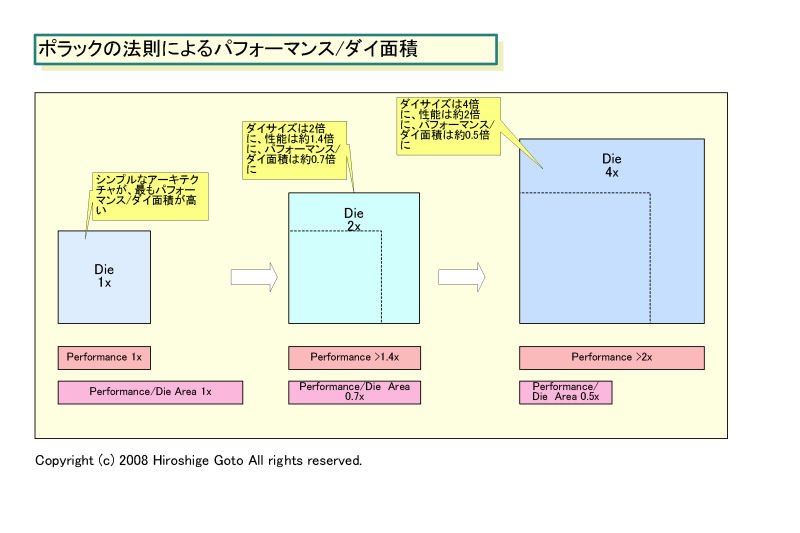 |
| ポラックの法則によるパフォーマンスダイ/面積 ※PDF版はこちら |
●Pentium命令セットをベースにLarrabee命令を拡張
LarrabeeとPentiumは、基本のストラクチャーが同じというだけではない。Larrabee CPUコアの命令デコーダがサポートするx86命令セットも、基本は標準的なPentium世代のx86命令だという。MMX Pentium以降のMMX/SSE系の拡張命令は、サポートしないと推測される。これは、同じ“巻き戻し型”CPUでも、Silverthorne系との大きな違いとなっている。Silverthorneは、Core 2 (Merom:メロン)互換の「Supplemental SSE3 (Merom New Instructions)」命令までをサポートし、将来のPC CPUの命令セットもサポートして行くという。
SilverthorneがPC向けCPUの命令セットサポートにこだわるのは、PCソフトウェア環境との完全互換が重要だとIntelが考えている携帯コンピューティング機器や低価格PC「Nettop/Netbook」をターゲットとしているからだ。それに対して、Larrabeeのx86互換は、x86ソフトウェア資産をフルに活かしたいというニーズではなく、プログラミングモデル上での親和性を高めたいという要因から来ている。x86の強味を活かすという基本路線は同じでも、その内容は大きく異なっている。
Larrabeeアーキテクチャは、Pentium命令そのものではなく、独自の命令拡張が加えられている。3オペランドスタイルの16-Wideベクタ命令(積和算命令を含む)のほか、ストリームプロセッシングに最適化したキャッシュ制御命令やデータフォーマット変換命令、最大16のデータをまとめるベクタ型のデータフォーマットへのギャザ/スキャッタオペレーションを行なう命令、ベクタの各要素の条件分岐命令などだ。また、64-bit命令も加えられているという。つまり、プログラマ人口の多いx86の基本命令セットをベースに、ストリームプロセッシング向けの命令を加えたのがLarrabeeという位置づけだ。
ちなみに、現在のGPUのネイティブ命令セットも、CPU命令セットと非常によく似ているという。その意味では、ネイティブ命令セットを、独自仕様にしたのがGPUで、x86ベースにしたのがLarrabeeとも言える。ただし、アセンブラコーディング時代からの遺産を引きずるx86命令セットの方が、より複雑となっている。
Intelは、Larrabee拡張命令のフォーマットの詳細については明らかにしてない。しかし、想定できる点がいくつかある。まず、命令フォーマットはデコードしやすいものでなければならない。x86命令のデコード時の複雑さの多くは、x86命令が可変長であることに起因している。この問題を軽減するためには、Larrabee拡張命令を、固定長にすることが望ましいと推定される。
●GPUより狭いハードウェアマルチスレッディング
Larrabeeはまた、4-wayのハードウェアマルチスレッディングもサポートする。Larrabeeは、レジスタファイルを4セットづつ備え、スレッドをCPUコア内部でハードウェア的に切り替えることができる。ちなみに、LarrabeeのL1キャッシュは、L1命令キャッシュが32KB、L1データキャッシュが32KBと、それぞれ8KBづつだったPentiumより4倍に増量されている。これは、4つの実行スレッドでL1キャッシュをするため、4倍にしたと言う。
Intel CPUでは、NehalemとSilverthorneが、それぞれ2-wayのマルチスレッディングをサポートする。Larrabeeの4-wayマルチスレッドはCPUとしては多い。しかし、GPUとしてはこのマルチスレッディングの数は非常に少ない。GPUは、通常、数十以上のスレッドのハードウェア切り替え機能を持つからだ。例えば、GeForce GTX 200(GT200)の場合は、32レジスタ/スレッド時に16warp(NVIDIA用語でのスレッド)を切り替える。
Larrabeeの説明では、ハードウェアマルチスレッディングは、コンパイル時にスケジューリングで隠蔽できなかったストールやL2キャッシュからのロードレイテンシを隠蔽することを主目的としているという。これは、プロセッサ外部の外付けビデオメモリへのアクセスのレイテンシを隠蔽することを目的とした、GPUのハードウェアマルチスレッディングとは異なる。
LarrabeeのハードウェアマルチスレッディングがGPUより狭い理由は、スケジューリングのアーキテクチャにある。コンパイル時に予測できる長いレイテンシは、Larrabeeの場合はソフトウェアでスケジュールする。予測ができない短いレイテンシ、例えば、L1キャッシュミスでL2キャッシュからロードするようなケースはハードウェアでスイッチする。GPUとは、マルチスレッディングのアーキテクチャが異なっている。LarrabeeはGPUと較べると、よりソフトウェア制御的で、コンパイラ(ランタイム)によるスケジューリングに頼る比率が高い。それだけコンパイラに自信を持っていることになる。
□関連記事
【8月4日】【海外】ついにベールを脱いだIntelのCPU&GPUハイブリッド「Larrabee」
http://pc.watch.impress.co.jp/docs/2008/0806/tawada148.htm
【7月16日】【海外】Larrabeeに追われるNVIDIAがGT200に施したGPGPU向け拡張
http://pc.watch.impress.co.jp/docs/2008/0716/kaigai453.htm
【4月7日】【海外】x86からの脱却を図るIntelの新ロードマップ
http://pc.watch.impress.co.jp/docs/2008/0407/kaigai434.htm
【4月3日】【IDF】「Peta FLOPsからミリワットまでカバーするIA」
http://pc.watch.impress.co.jp/docs/2008/0403/idf02.htm
【2007年10月12日】【海外】MIMDのLarrabeeとSIMDのGPUの戦い
http://pc.watch.impress.co.jp/docs/2007/1012/kaigai393.htm
(2008年8月11日)
[Reported by 後藤 弘茂(Hiroshige Goto)]
【PC Watchホームページ】
PC Watch編集部 pc-watch-info@impress.co.jp ご質問に対して、個別にご回答はいたしません
Copyright (c) 2008 Impress Watch Corporation, an Impress Group company. All rights reserved.