 |


■後藤弘茂のWeekly海外ニュース■Nettop/Netbookを超えた先にある
|
●COMPUTEXで目立ったAtomプロセッサ
先週、台北で開催されたCOMPUTEXでは、IntelのAtom(Silverthorne/Diamondville)プロセッサを搭載した、超低価格PC「Nettop」「Netbook」やモバイルデバイス「MID(Mobile Internet Devices)」が溢れた。今回のCOMPUTEXは、通常のPC CPUやチップセット、GPUが今1つパッとしなかったこともあり、Atom搭載マシンは話題となった。
しかし、ショウでは華やかだったものの、現実のAtomマシンの動向はというと、急拡大とは行きそうにない。COMPUTEXで台湾ベンダーがこぼしていたように、IntelからのAtomの供給は非常にタイトで、実際に製品を提供できるベンダーは限られそうだ。あんなにダイ(半導体本体)が小さく、生産性が高いチップを、どうしてIntelはハイペースで量産できないのか。
理由は簡単だ。Intelが意図的に供給を抑えているからだ。ある関係者は「Intelは、Atomの供給過剰によるカニバライゼーション(共食い現象)を恐れている」という。多くのベンダーから市場ニーズ以上のAtom搭載マシンが供給され、ベンダーが利益のない価格競争の嵐に呑まれてしまうことを避けようとしていると考えられる。
以前の記事で、Atomなどローパワーのx86 CPUがPC市場を侵食するシナリオを書いた。しかし、そうしたシナリオが現実化する可能性があるのは長期に渡る変化であり、短期間に地滑り的に起きる可能性は少ない。スタート段階の現在は、一般的には様子見で、Atomマシンに飛びつくユーザー層は限られているだろう。まずは、PCをよく知った高スキルユーザーの2台目3台目マシン需要で、限定的な市場で、Intelもそれを理解していると思われる。
また、Intelとしても、ここでAtomが猛ダッシュで成功を納めても困る。IntelとしてはAtomマシン、特に、通常のPCに近い形態のNettop/Netbookの導入には慎重にならざるを得ない理由がある。通常のPCとの線引きを明確に維持し続けることが、今後のPC向けCPUビジネスの維持に欠かせないからだ。Microsoftにとっても事情は同じで、ハードウェア価格がある一定に保たれればこそ、OSやアプリケーションの価格も一定水準を維持できる。より低い価格レベルに水準線が引き直されることは避けたい。だから両社とも、ディスプレイサイズといったフィーチャで、PCとNettop/Netbookが差別化されることを望んでいる。
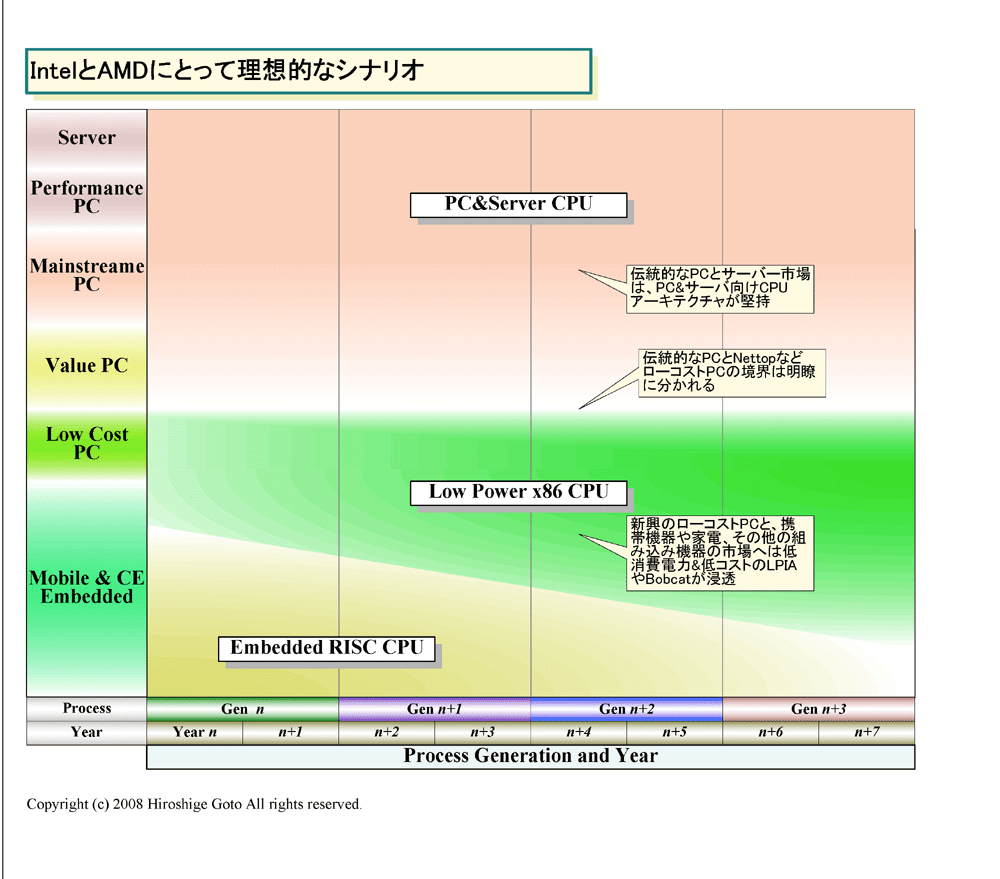 |
| IntelとAMDにとって理想的なシナリオ PDF版はこちら |
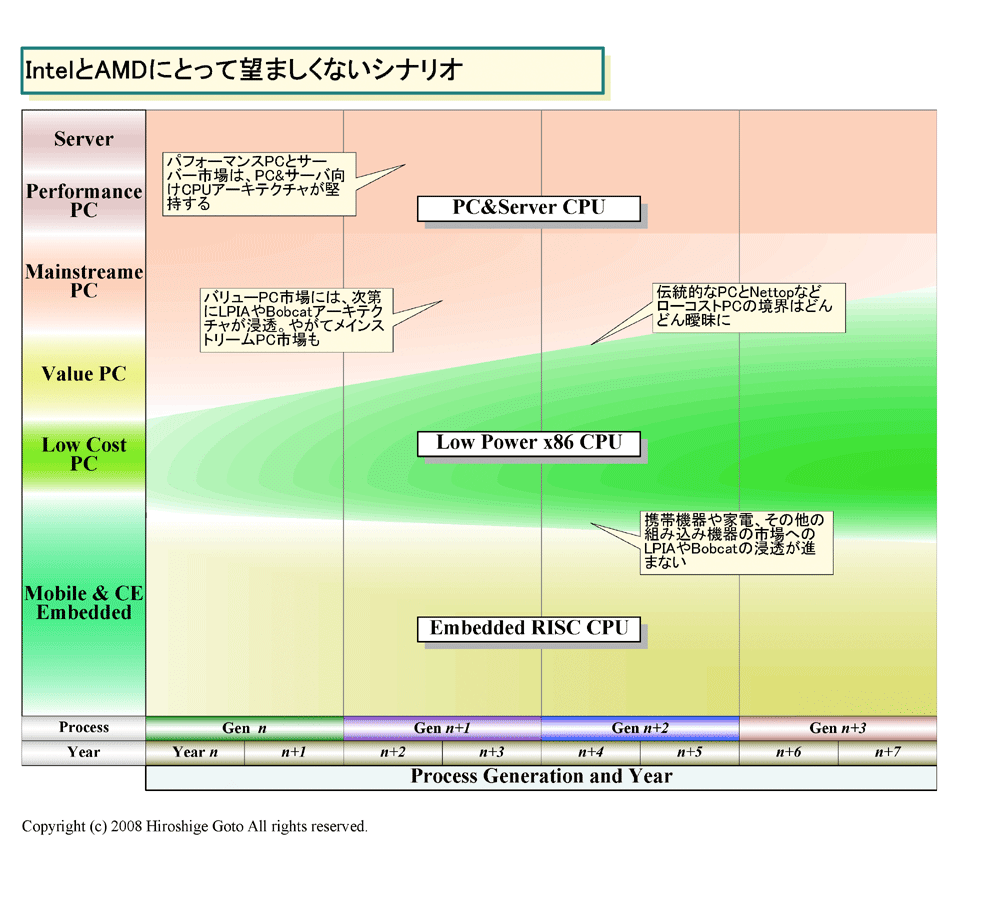 |
| IntelとAMDにとって望ましくないシナリオ PDF版はこちら |
●整数演算と浮動小数点演算のバランス
しかし、IntelやMicrosoftの思惑とは裏腹に、Silverthorne/Diamondville、つまり、IntelのLPIA(Low Power Intel Architecture)系CPUは可能性を秘めている。むしろ、可能性があるから、IntelやMicrosoftが慎重になっている。純粋にCPUアーキテクチャとして見るなら、LPIAが取ったシンプルコア自体は、時代の重要なキーワードとなっている。
シンプルコアCPUの流れは、今のCPUの大きなトレンドの1つであり、低消費電力&低価格デバイスだけでなく、より広い市場へと適用できる可能性も持っている。アーキテクチャを発展させれば、ある程度の部分のメインストリームPCはもちろん、サーバーやゲーム機などにも充分に応用できる。今までのPC向けCPUとは、違う方向へと進化するCPUの土台となれるアーキテクチャだ。Intelが、もしLPIAを発展させる気になれば、シンプルコアを多様に使うことができるだろう。
ただし、それは従来のPC&サーバー向けCPUとは異なる流れとなる。ポイントは、(1)シングルスレッド対マルチスレッド、(2)スカラ対ベクタ(この場合はSIMD)、(3)整数演算対浮動小数点演算の各性能バランスだ。現在のPC&サーバー向けCPUは、マルチスレッド性能を世代ごとに高め、SIMD浮動小数点演算の拡張に注力しながら、シングルスレッドのスカラ整数演算性能も高く維持する方向で発展しようとしている。それに対して、シングルスレッドのスカラ整数演算性能は比較的低い水準に止め、マルチスレッドとSIMD浮動小数点演算の性能にフォーカスするという選択肢を取るという選択肢もありうる。その近道にいるのがLPIAのシンプルコア路線だ。
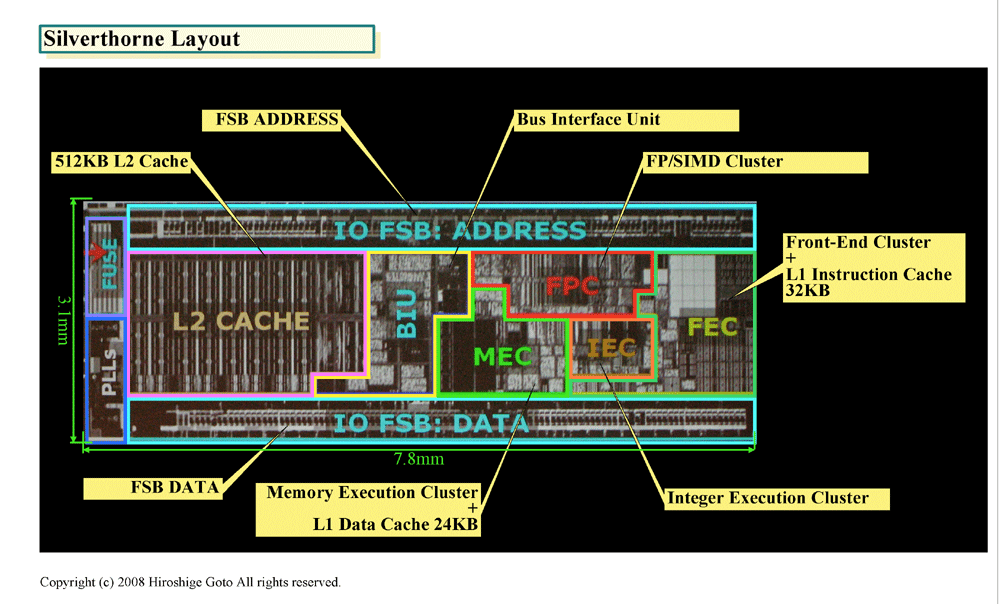 |
| Silverthorne レイアウト PDF版はこちら |
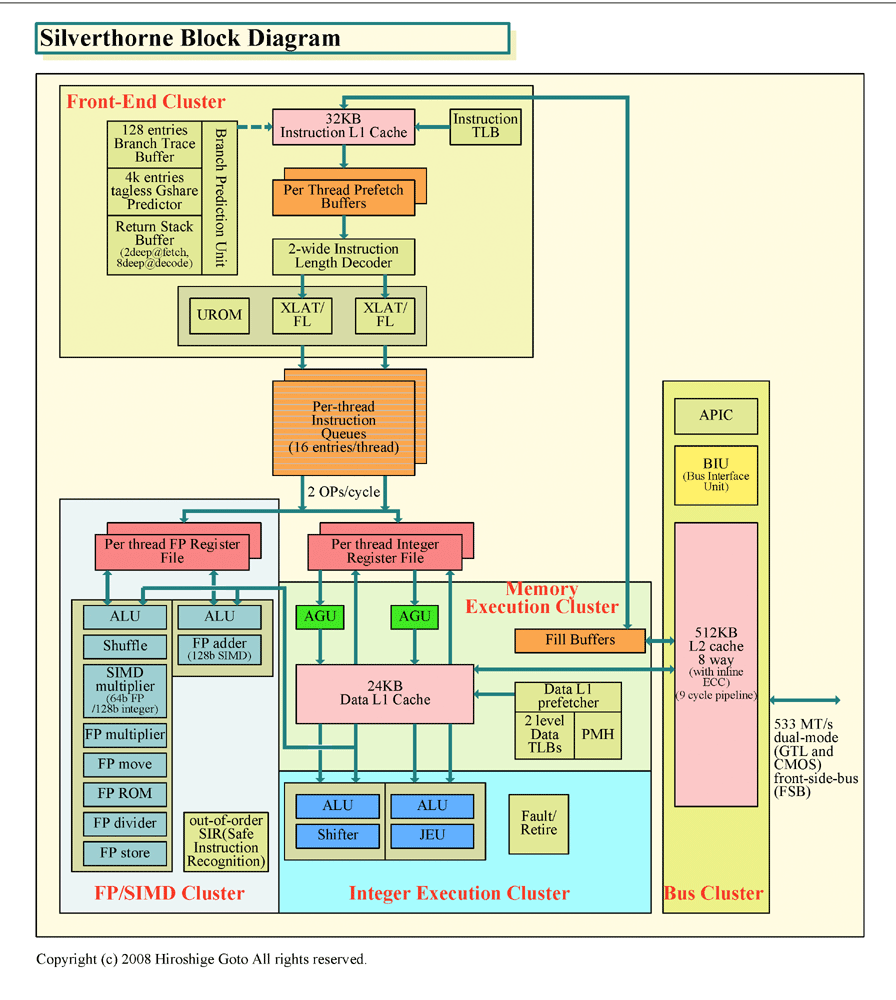 |
| Silverthorne ブロックダイヤグラム PDF版はこちら |
LPIA系を発展させれば、原理的には、次のようなニーズに合ったマシンを作ることができる。従来型のアプリケーション性能は追求しないので、シングルスレッドの整数演算の性能は低くてもいい。でも、メディアアプリケーションはよく使うため、浮動小数点演算の性能は普通のPCレベルに近いものがいい。同様の理由で、ある程度のマルチスレッド性能も求める。しかし、消費電力は低く、半導体製造コストも低く、価格レンジは従来型PCよりずっと安い。LPIAベースなら、原理的にはそうしたニーズに応え、従来のPC&サーバー向けCPUより、高い電力効率を達成したCPUを作ることができる。
Intelは、来年(2009年)、第2世代のAtomとして「Lincroft(リンクロフト)」を投入する。Lincroftは、現在のSilverthorne/Diamondville系のCPUコア「Bonnell(ボンネル)」に、メモリコントローラとGPUコアを統合した製品になると言われる。この段階では、CPUコア自体の拡張は行なわれないと見られる。今のIntelのLPIA系CPUの発展の方向は、CPUコアを小さく保ったまま、電力消費を減らし、スマートフォンに入れることだ。しかし、IntelはLPIAをベースに、よりハイパフォーマンスの派生CPUを作ることができる。
●CPU業界で流行のIn-Order 2wayスーパースカラパイプライン
現在のBonnell CPUコアが取ったIn-Order実行の2命令スーパースカラパイプラインは、電力効率の面で非常に優れている。特に、Out-of-Order実行で3~4命令のスーパースカラパイプラインを持つ、現在のx86系PC&サーバー向けCPUと較べると、電力効率がいい。パフォーマンスに対するダイサイズと電力の効率が最も高いのは、In-Order実行の2wayスーパースカラパイプラインだと言われている。
例えば、Cell Broadband Engine(Cell B.E.)のPPU(Power Processor Unit)やSPU(Synergistic Processor Unit)も、In-Order実行の2wayスーパースカラパイプラインを採用している。その理由は、やはり、2wayが最も効率が高かったからだという。下が2005年4月に横浜で開催されたプロセッサカンファレンス「COOL Chips VIII」でのプレゼンテーションだ。これを見ると、1wayから2wayにするとガンと性能が上がるが、3way以上では性能向上がぐっと落ちることがわかる(汎用レジスタ128本、浮動小数点演算レイテンシ9サイクル、整数演算レイテンシ2サイクル、ロード8サイクルでシミュレーションをした場合)。
 |
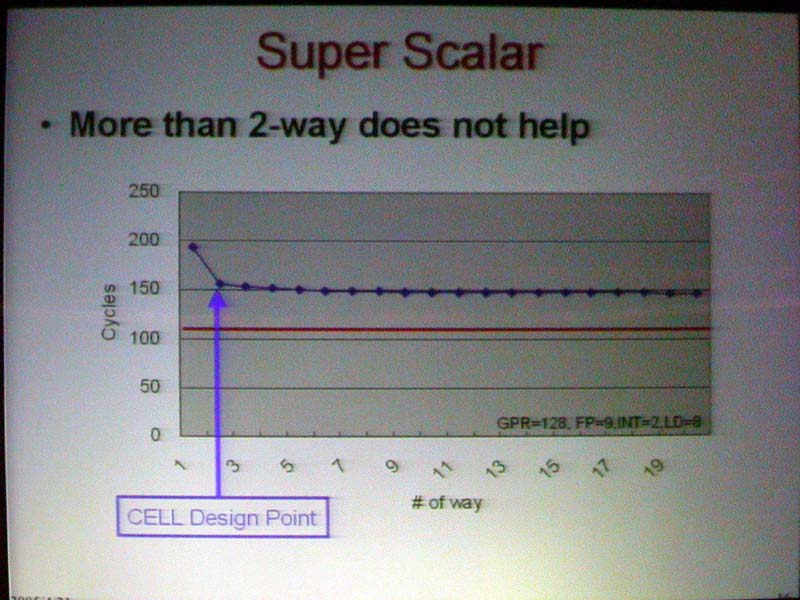 |
| COOL Chips VIIIで示されたIn-Order実行スーパースカラの効率 | |
Cell B.E.アーキテクトチームは、3way以上でベネフィットが得られるケースはワークロードに依存するとして、SPEでは2wayを採用した。Cell B.E.と同様に、ゲーム機としてパフォーマンス効率を最重視したXbox 360のCPUも、In-Order実行2wayスーパースカラを採用した。In-Order実行2wayスーパースカラは、パフォーマンス効率を重視するCPU設計では、現状では、最もリーズナブルな選択と判断されているようだ。
Out-of-Order実行で3way以上の性能を上げようとすると、CPUはより肥大化し、パフォーマンス効率はぐっと落ちてしまう。命令を並べ替えるためには、命令間の依存性をチェックし、大きな物理レジスタに論理レジスタをマップして真の依存性がないレジスタ競合を避け、深いバッファを設けと、命令の制御ロジックやバッファ、レジスタなどに膨大なトランジスタが必要になる。現在のPC向けCPUは、命令を実行する実行ユニット自体より、命令を制御する周辺部分の方が大きくなっている。BonnellのようにIn-Order実行にすれば、Out-of-Order実行に関係する余計な部分がなくなり、よりスリムでパフォーマンス効率の高いCPUになる。
効率性では、In-Order実行の1命令発行のスカラプロセッサ構成が最も高いという意見もある。NVIDIAのG80/90系GPUのストリームプロセッサ(SP)は、1wayのスカラ構造を取っている(クラスタ内に複数種類のプロセッサがあり、SPは1命令/サイクル)。しかし、CPUでの今の流れはIn-Orderの2wayスーパースカラパイプラインのようだ。
●LPIAにAVX以降を実装して浮動小数点SIMD演算を上げる
BonnellコアのIn-Order実行の2wayスーパースカラパイプラインは、効率性では優れるものの、シリアルな整数演算性能は上げにくい。Out-of-Order実行は、整数演算の絶対性能を引き上げる効果がある。しかし、整数演算と比較すると浮動小数点演算の方は、性能を上げやすい。浮動小数点演算中心のプログラムは、シリアルに演算を延々と行なう場合が多いため、複雑な命令の制御を行なわなくても比較的性能を上げやすい。だから、実行ユニットとデータパスを強化すれば、性能をある程度は向上できる。
現状では、Bonnellコアは浮動小数点演算の性能がぱっとしない。これはアーキテクチャの制約よりむしろ、実装上の問題だと考えられる。Bonnellコアは、コアを小さく保つため、演算ユニットの設計では、ユニットを共用するなど、さまざまな省コスト化を行なっている。LPIA系でも、浮動小数点演算ユニット自体を強化すれば、浮動小数点演算の性能を上げることができる可能性が高い。
特に、今のIntelは、浮動小数点演算の並列性を、SIMD(Single Instruction, Multiple Data)によるデータ並列性で上げる方向へと傾いているため、Bonnellの延長線で、今後も継続して浮動小数点演算性能を上げる余地が高い。データ並列での性能向上には、Out-of-Order実行による命令並列性を必要としないからだ。例えば、2010年の「Sandy Bridge(サンディブリッジ)」に実装する新命令拡張「Intel Advanced Vector Extensions (Intel AVX)」では、SIMDを今の128-bitから256-bitへと倍増させる。LPIA系コアにAVXを実装すれば、ピーク浮動小数点演算性能は2倍になる。ただし、256-bit SIMD自体が、256-bit分のスロットを埋めるのが大変なので効率が悪いという意見も多い。
LPIA系CPUコア自体の性能は向上させずに、マルチスレッド性能を高める方向の進化もありうる。AtomのCPUコアは、PC向けCPUコアの2分の1以下のサイズで、同じダイ(半導体本体)面積に、PC向けCPUより多くのCPUコアを搭載できる。さらに、SMT(Simultaneous Multithreading)を高めれば、より多くのスレッドを並列実行できる。例えば、8コアで32スレッド実行といったCPUに進化させることもできる。これは、SunのUltraSPARC T(Niagara:ナイアガラ)と同じ方向性だ。
●もう1つのCPUアーキテクチャの可能性
PC&サーバー向けx86 CPUは、数年前までシングルスレッド性能の向上を追求して来た。特に、PCではシングルスレッドの整数演算性能を継続的に上げることを重視していた。これは、過去に作られたプログラムも、新CPUの上で性能を向上させる必要があるという、PC向けCPUの呪縛によるものだった。だが、そのトレードオフで、CPUの電力効率が悪化してしまった。そして現在、命令レベルの並列性(ILP:Instruction-Level Parallelism)の限界「ILPウォール(ILP Wall)」、消費電力の壁「パワーウォール(Power Wall)」、メモリアクセスの壁「メモリウォール(Memory Wall)」の3つの壁に挟まれている。
そこで、CPUベンダーは現在、マルチコア化によるスレッド並列性と、ベクタ化によるデータ並列性を上げることで、性能を引き上げる方向に転じている。IntelのPC向けCPUも、整数演算性能の向上より、浮動小数点演算性能の向上にフォーカスした「Nehalem(ネハーレン)」を皮切りに、今後は、浮動小数点演算性能重視のCPU拡張が続く。ただし、出発点として、IntelもAMDも、現在の整数演算パフォーマンスを維持する方向にある。
そのため、代替解として、整数演算性能はより低いレベルで出発し、浮動小数点演算性能やマルチスレッド性能を高めるというCPUの方向性もありうる。従来アプリケーションの性能は低いが、電力消費はより低く、効率性の高いCPUだ。ゲーム機CPUなどを見る限り、こうした方向性は充分有効に見える。
しかし、IntelやAMDの場合、こうしたCPUを作ると、従来のPC&サーバー向けCPUとカニバライゼーションを起こしてしまう可能性が高い。ローエンドのバリューPCや、場合によっては下位のメインストリームPCが、ローパワーCPUに置き換わってしまう可能性もある。現状でも、Atomのカニバライゼーションを恐れて出荷を制約しているIntelが、PC向けCPUとのカニバライゼーションを恐れないわけはない。そのため、IntelがLPIAをこうした方向へと進化させる可能性は低いだろう。だが、マルチコアへの急転換が起きたように、よりローパワーCPUへと転換が起きる可能性も捨てきれない。
□関連記事
【6月4日】【COMPUTEX】Intel、“Diamondville”こと「Atom」を正式発表
http://pc.watch.impress.co.jp/docs/2008/0604/comp04.htm
【4月18日】【海外】ムーアの法則がIntelに逆襲する
http://pc.watch.impress.co.jp/docs/2008/0418/kaigai436.htm
【4月2日】【海外】Intel、IDFでAtomプロセッサを正式発表
http://pc.watch.impress.co.jp/docs/2008/0402/kaigai432.htm
(2008年6月16日)
[Reported by 後藤 弘茂(Hiroshige Goto)]
【PC Watchホームページ】
PC Watch編集部 [email protected] ご質問に対して、個別にご回答はいたしません
Copyright (c) 2008 Impress Watch Corporation, an Impress Group company. All rights reserved.