 |


■後藤弘茂のWeekly海外ニュース■AMDの次のサーバープラットフォーム「Maranello」 |
●DDR3メモリの成熟に合わせてプラットフォーム計画を変更
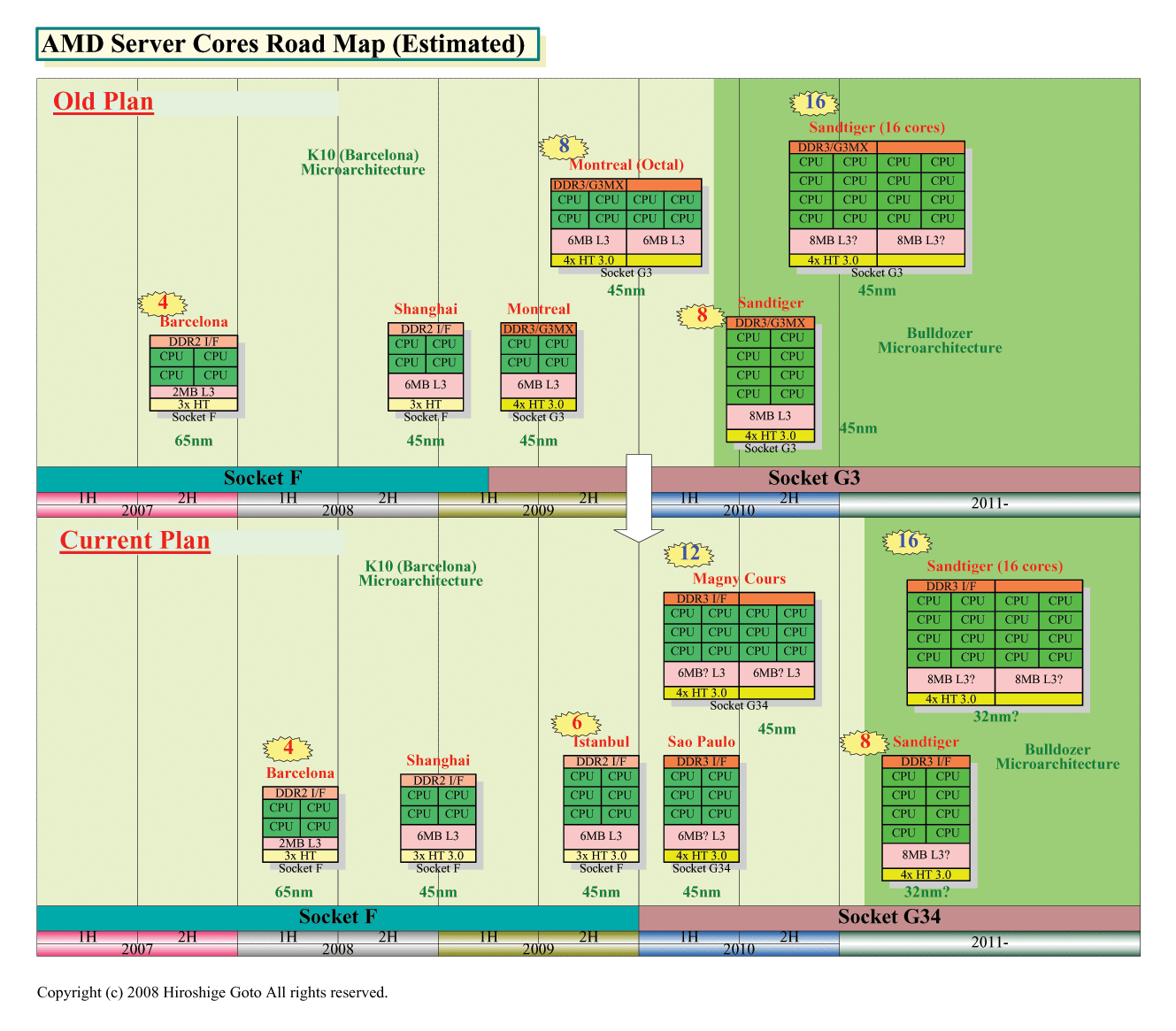
AMDは、2010年に12コアのハイエンドサーバー向けCPU「Magny-Cours(マニクール)」を投入する。Magny-Coursは、AMDが「Direct Connect Module」と呼ぶMCM(Multi-Chip Module)技術を使い、2個の6コアCPU「Sao Paulo(サンパウロ)」を1つのパッケージに封止する。Magny-Cours世代からは、CPUソケットも「Socket G34」になり、4リンクのHyperTransport 3.0とネイティブDDR3インターフェイスがサポートされる。
前回のニュースで伝えた通り、AMDはサーバーロードマップを大きく変更した。Magny-Coursの投入で、AMDが2010年に予定していた、ネイティブ8コアのサーバーCPU「Sandtiger(サンドタイガー)」は、後ろにずれ込んだ。Intelと同様に、4コアと8コアの間にネイティブ6コアCPUを持って来る計画となった。
 |
| サーバーロードマップ新旧プラン比較 PDF版はこちら |
Intelの6コアCPU「Dunnington(ダニングトン)」は今年(2008年)後半なので、来年(2009年)後半のAMDの6コアCPU「Istanbul(イスタンブール)」は1年遅れることになる。しかし、日本AMDは「Intelの6コアは当初はMP(Multi-Processor)向けだけで、競合しない部分も多い」と説明する。もっとも、Intelは2009年末から2010年にかけて、DP(Dual-Processor)以下の市場にも32nmプロセスの6コア「Westmere(ウエストミア)」を投入すると見られている。
日本AMDによると、ネイティブ8コアのSandtigerの計画はキャンセルになったわけではなく、3年のロードマップからは見えなくなっただけだという。Sandtigerからは、CPUコアのマイクロアーキテクチャが一新され「Bulldozer(ブルドーザ)」コアになる。オリジナルプランのSandtigerは45nm製品だったが、新プランでは32nmになると見られる。
そのため、マイクロアーキテクチャ自体はSao Paulo/Magny-Coursまで、現行のK10(Barcelona)コアが継承される。ただし、多少の拡張は行なわれるほか、Sao Paulo/Magny-Coursではキャッシュスヌープをフィルタする「Probe Filter」が実装される。Probe Filterでは、マルチプロセッサシステムで、各プロセッサのキャッシュのタグ内容をコピーして持つと思われる。従来のIntel CPUなどの構成では、フィルタはCPUのハブとなるチップセット側に実装した。しかし、プロセッサをダイレクトコネクトする場合には、タグを各プロセッサにコピーしなければならない。どういった実装になるのか、まだわからない。
今回のロードマップ変更で、Bulldozerから実装される新命令拡張「SSE5」も2011年以降にずれ込んだ。Intelは同時期のCPU「Sandy Bridge(サンディブリッジ)」に実装する新命令拡張「AVX」で256-bit長のSIMDをサポートする。AMDが、Bulldozerを遅らせたことで、同様の拡張を実装して来るかどうかが注目される。
ただし、日本AMDは、今回のロードマップ変更は、Bulldozerの開発が問題になったわけではなく、DDR3プラットフォームがどの時点で成熟するか、その移行時期を見極めたことによる変更だという。DDR3のサポートは、オリジナルプランでは2009年前半に導入する予定たった「Montreal(モントリオール)」からだったが、現在は2010年前半のSao PauloとMagny-Coursからとなっている。DDR3プラットフォームを1年ずらしたことになる。ただし、DRAMベンダーは2009年に焦点を合わせてDDR3メモリの準備を進めている。
 |
| Intelとのサーバーロードマップ比較 PDF版はこちら |
●キャンセルとなったG3MXメモリバッファチップ
サーバーでのDDR3は、メモリ搭載量をいかに確保するかが重要な課題となっている。DDR3では、RDIMMであっても4 Rank DIMMで1チャネル2DIMMまでに制限されるからだ。1チャネル当たりに接続できるDIMM枚数が制約されるため、メモリ搭載量が重要となる上位のサーバーではメモリチャネル数を増やす必要がある。また、1個のCPUに搭載されるCPUコア数が急ピッチに増えて行くため、CPUパフォーマンスの向上に見合った、メモリ帯域の拡張も要求されている。
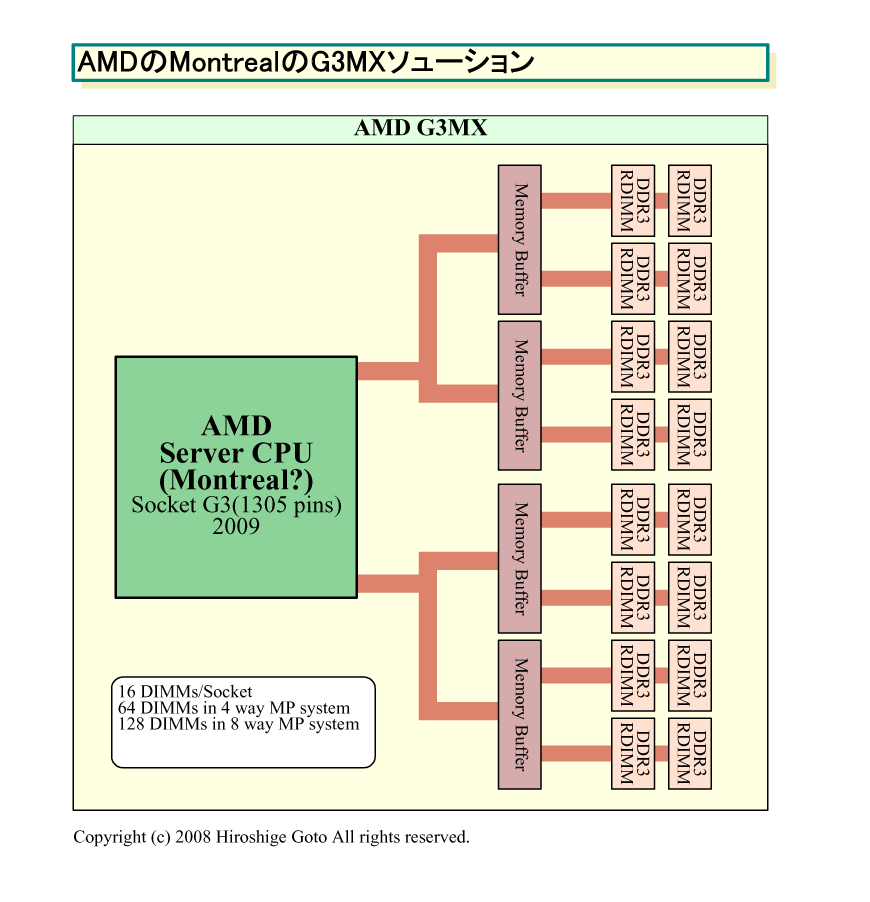
こうした問題に対するため、AMDは、Montrealで採用する「Socket G3」で、メモリシステムの大きな変更を予定していた。Socket G3では、ネイティブDDR3とともにメモリバッファ「G3MX(G3 Memory Extender)」をサポートする予定だった。
Socket G3 CPUでは、ネイティブDDR3時にはデュアルチャネルインターフェイスだが、G3MXによって4チャネルのメモリサポートが可能となるとされていた。また、昨秋に当時AMDのCTOだったPhil Hester(フィル・へスター)氏にインタビューした際には、各チャネルに2個のG3MXチップを接続することで、最大8チャネルの構成が可能だと説明された。
だが、AMDは新ロードマップのSocket G34ではG3MXサポートを取りやめ、DDR3のみのサポートに切り替えた。G3MXを取りやめた理由について、日本AMDの山野洋幸氏(マーケティング本部プロダクトマーケティング部長)は次のように説明する。
「G3MXソリューションは、いったんキャンセルした。DDR3になると(チャネル当たりのメモリ搭載量に)制約があるため、より多くのメモリを積みたいというニーズがあった。また、よりハイエンドのシステムを構成をしたいというOEMの要求もあった。そこで、(大容量構成と)フレキシブルにシステム対応できるソリューションとしてG3MXを提案した。
しかし、聞き取りしてみると実際のデマンドは多くなかった。今持っているアーキテクチャでカバーできる範囲でDDR3(世代)でも、だいたいのマーケットをカバーできると考えた。確かに、もっとたくさんのメモリを搭載したいという、顧客もあるが、そうしたニーズにはサードパーティのソリューションも出てくるかもしれない」
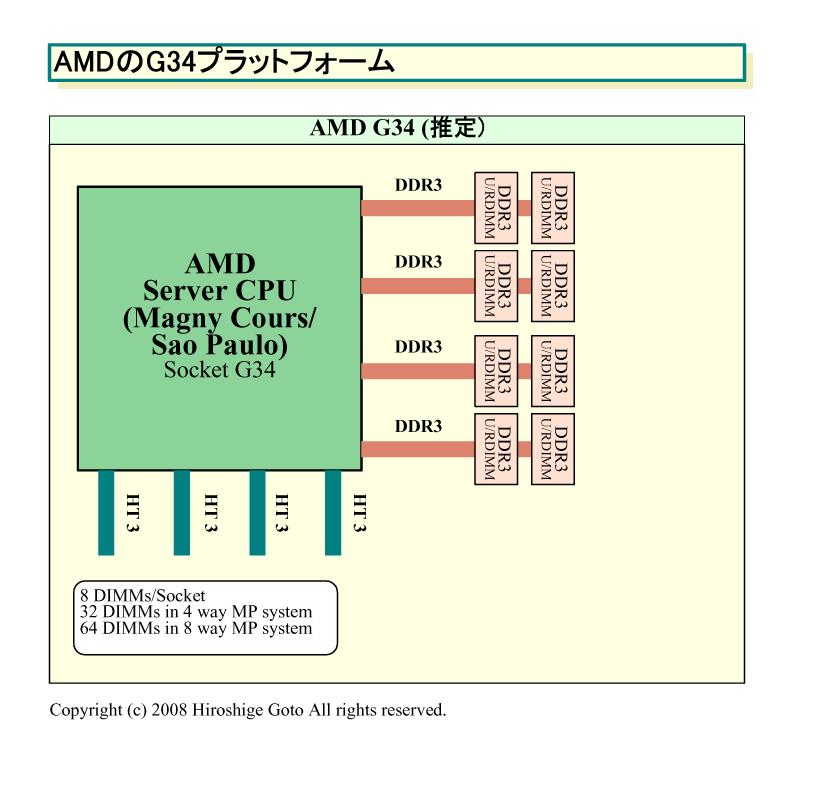
こうした背景から、AMDは、Socket G3とG3MXを取りやめ、Socket G34 CPUではネイティブDDR3インターフェイスにした模様だ。Socket G34では、Registered DIMM(RDIMM)とUnbuffered DIMM(UDIMM)の両方をサポートする。これは、IntelのNehalem(ネハーレン)と同様だ。
●4チャネルのDDR3インターフェイスを搭載するSocket G34 CPU
Socket G34 CPUでは、4チャネルのネイティブDDR3インターフェイスを実装すると言われている。Socket G3のデュアルチャネルネイティブDDR3時と較べると、メモリ帯域と最大メモリ搭載量は2倍になる。もともと、Socket G3では、G3MX時にはメモリインターフェイスをDDR3の2倍の帯域で稼働させる仕様となっていた。そのため、スペック上のピークメモリ帯域はネイティブ4チャネルDDR3と、G3MXベースのDDR3で変わらないことになる。4チャネルDDR3では、DDR3-800時に25.6GB/sec、予定の最高転送レートであるDDR3-1600時に51.2GB/secの広帯域となる。
 |
| AMDのMontrealのG3MXソューション PDF版はこちら |
 |
| AMDのSocket G34 PDF版はこちら |
Socket G34では、ネイティブ4チャネルDDR3になったことで、ボードベンダはコスト増となるバッファチップを使わなくても4チャネルのメモリ帯域とメモリ容量が得られるようになった。メモリレイテンシの面でも、バッファチップを使う場合より有利となる。
また、対Intelでは、ネイティブ3チャネルDDR3となるクアッドコアのNehalem(ネハーレン)に対して、メモリ帯域とメモリ容量で利点を持つ。Nehalemは、DRAMインターフェイスを統合し、3チャネルと広帯域のDDR3インターフェイスを備えることで、浮動小数点演算パフォーマンスを飛躍させる。それに対抗するためには、ネイティブ4チャネルDDR3が必要だと判断したとも考えられる。
ちなみに、Intelの8コアサーバーCPU「Nehalem EX(Beckton:ベックトン)」は4チャネルのFB-DIMM2インターフェイスを備え、メモリバッファチップでDDR3 RDIMMをサポートする。Nehalem EXに対しては、メモリバッファチップを使わないことで、コストとレイテンシで有利にできる可能性がある。
しかし、ネイティブDDR3化によって犠牲になるものもある。メモリソケットの配置のフレキシビリティと、最大構成時のメモリ容量だ。インターフェイス幅が64-bitと広いネイティブDDR3を4チャネル引き出すことは、配線上非常に難しく、ボードレイアウトも限定される。Hester氏が説明したような各チャネルに2個のG3MXの構成では1 CPU当たり最大16枚のDDR3 DIMMを接続できる。Socket G34のネイティブ4チャネルでは、そこまでは実現できない。ただし、従来と同様にサードパーティがメモリバッファを提供することはできる。
●サーバー向けチップセットRD890SをSocket G34に導入
Socket G34プラットフォームには「Maranello(マラネロ)」というコードネームがつけられている。これもF1シリーズで、フェラーリ本社があるイタリア都市だ。ちなみにSocket G3プラットフォームは「Piranha(ピラニア)」だった。こちらもF1に由来する。
AMDは、Socket G34プラットフォームをサポートするサーバー向けチップセットとして「RD890S」と「RD870S」を投入する。AMDは、Opteronではサーバー向けチップセットはNVIDIAとBroadcomに頼っていた。しかし、Socket G34では再び自社チップセットで支える態勢に戻す。
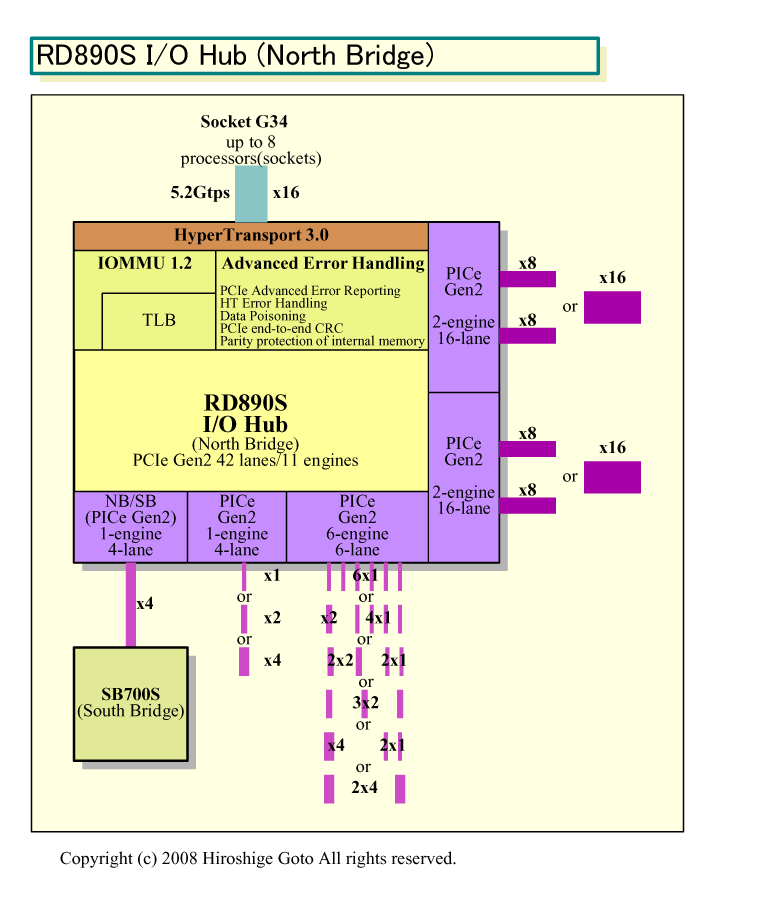
RD890Sの特徴は、PCI Express Gen 2.0を多数レーン備えることと、I/O仮想化支援ハードウェア「IOMMU(I/O Memory Mapped Unit)」を備えること。また、サーバー向けに高度なRASフィーチャも備える見込みだ。IOMMUではI/Oアドレスが物理アドレススペースではなく、仮想アドレススペースベースになる。メモリアドレスマッピングのオーバヘッドを減らすために、RD890Sはかなりの量のキャッシュメモリも内蔵すると言われている。
RD890SのPCI Express Gen2のレーン数は42。このほか、サウスブリッジチップとの接続もPCI Express x4を使っているため、厳密には46レーンのPCI Expressとなる。
 |
| RD890S I/O Hub (North Bridge) PDF版はこちら |
RD890Sの各PCI Expressレーンは、用途に最適化された5つのPCI Expressインターフェイスコアに分割されている。2つのコアは広帯域のチップ接続のために最適化されており、そのほかに中低帯域のチップ接続に最適化されたコアが2つ、サウスブリッジチップ接続のために最適化されたコアが1つある。
広帯域のチップ接続のための2つの「GPP0」コアは、それぞれ16レーンと2エンジンを備える。そのため、それぞれが1基のx16または2基のx8の構成が可能だ。つまり、RD890Sでは、2基のx16や4基のx8、あるいは1基のx16と2基のx8という、広帯域リンクの構成を取ることができる。
中低帯域のチップ接続向けのコア「GPP1」は6レーンと数は少ないが、6エンジンを備える。そのため、6基のx1から1基のx4と1基のx2の組み合わせまで、フレキシブルなインターフェイス構成を取ることができる。中低帯域のもう1つのコア「GPP2」は、4レーンでエンジンは1つだけ。基本的には1基のx4のためのコアとなっている。サウスブリッジチップ用の「NB/SB」コアも基本は同様で4レーンに1エンジン。x4リンクでサウスブリッジチップと接続する。
RD890SのPCI Expressの構成は、従来のノースブリッジチップのPCI Expressインターフェイスと、サウスブリッジチップのPCI Expressインターフェイスの両方を兼ね備えたものとなっている。AMDチップセットのソリューションでは、PCI Express接続はノースブリッジに集中させ、サウスブリッジチップ側は低速I/Oだけに限定するようだ。プロセス技術の進歩によって、それだけのPCI Expressをノースブリッジ側に集めることができるようになった。ちなみに、RD890SはTSMCの65nmプロセスで製造されるという。
Socket G34からは、CPU側のHyperTransportが4リンクとなる。そのため、4way以上のマルチプロセッサ構成時のメモリホップ数を減らすことが可能だ。また、チップセットを多数搭載した構成も容易になる。
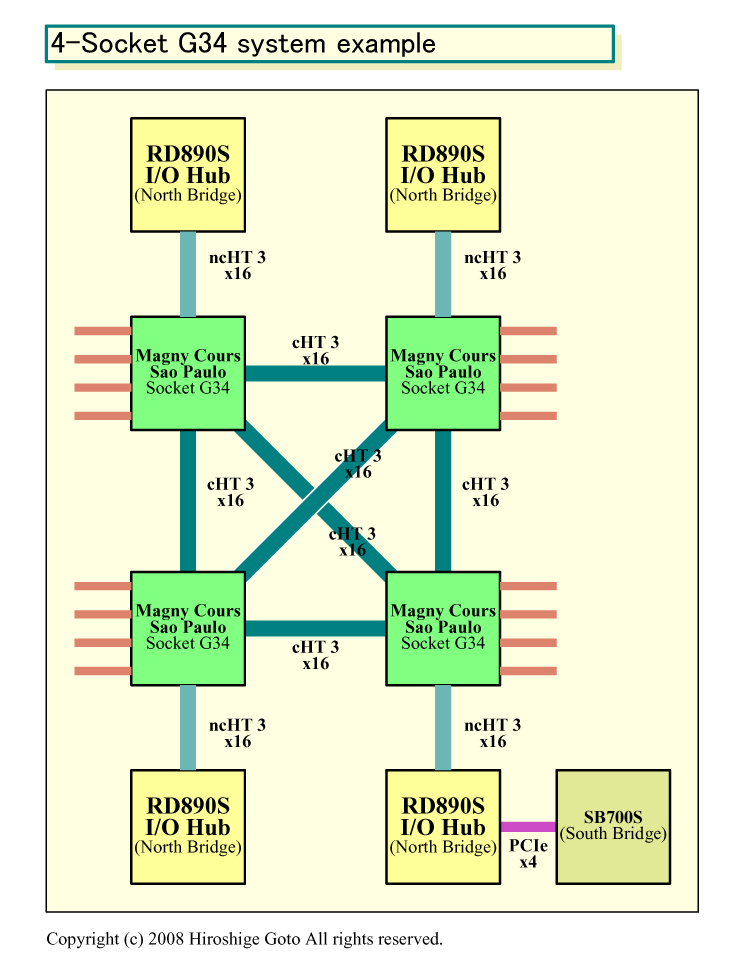 |
| RD890Sシステム構成例 PDF版はこちら |
□関連記事
【5月13日】【後藤】Intelへの対抗を迫られたAMDのサーバーCPUロードマップ
http://pc.watch.impress.co.jp/docs/2008/0513/kaigai439.htm
【5月8日】AMD、12コアOpteronなどサーバーロードマップを更新
http://pc.watch.impress.co.jp/docs/2008/0508/amd.htm
【2007年12月27日】【海外】Bulldozerが後退したAMDのロードマップの意味
http://pc.watch.impress.co.jp/docs/2007/1227/kaigai410.htm
(2008年5月20日)
[Reported by 後藤 弘茂(Hiroshige Goto)]
【PC Watchホームページ】
PC Watch編集部 pc-watch-info@impress.co.jp ご質問に対して、個別にご回答はいたしません
Copyright (c) 2008 Impress Watch Corporation, an Impress Group company. All rights reserved.