 |


■後藤弘茂のWeekly海外ニュース■Intelへの対抗を迫られたAMDのサーバーCPUロードマップ |
●よりリスクの少ない方向へと変わったAMDロードマップ
AMDがサーバーCPUロードマップを更新した。新しいロードマップの最大のポイントは、来年(2009年)のネイティブ6コアCPU「Istanbul(イスタンブール)」投入と、2010年の12コアCPU「Magny Cours(マニクール)」の投入。現在の4コアから2年後には3倍の12コアに持って行くプランだ。12コアは、2個のダイ(半導体本体)を1パッケージに封止する「MCM(Multi-Chip Module)」による製品と見られる。
一見華やかなAMDの新ロードマップだが、実際にはその影で後退した要素も多い。まず、CPUコアマイクロアーキテクチャの刷新となる「Bulldozer(ブルドーザ)」コアの投入は、2011年以降にずれたと見られる。ネイティブ8コアCPUの投入も後退し、CPUソケットの刷新とそれに伴うDDR3メモリサポートと4リンクHyperTransport 3.0の導入も約1年後退した。
つまり、1ソケット当たりのCPUコア数の増加は従来プランよりピッチが上がったが、CPUコアの中身とインターフェイス回りの計画は従来より後退している。意図は明瞭で、リスクの高い要素は後ろへずらして開発/検証期間をより長くとった。その一方で、リスクが少ないCPUコアの単純な追加は前へと倒した。リスク軽減を重視したプランに変わったと言える。
CPUダイそのもののプランも変わっている。従来のプランでは、2コア→4コア→8コアと、CPUコア数を倍々にする計画だった。しかし、現在のプランでは2コア→4コア→6コア→8コアと、2コアづつ増やすプランになった。
これにプロセス技術を重ねると、従来は45nmでネイティブ8コアだったのが、新プランでは45nmでは6コアになり、8コアはおそらく32nmプロセスになった。つまり、サーバーCPUのダイサイズ(半導体本体の面積)の増大を抑え、より生産性を高める方向へと舵を切っている。これも、ダイの肥大化による歩留まりの悪化のリスクを避けたものだ。ここでも、リスク軽減の意図が見て取れる。
こうしたロードマップ変化から見えるのは、AMDがサーバーではリスクを減らし、より着実な製品投入を重視していることだ。このところの「Barcelona(バルセロナ)」系コアのPhenom/Opteronのスムーズな立ち上げの失敗への反省から、こうした変更が行なわれた可能性は高い。
●CPUコアとインターフェイスの刷新は後退
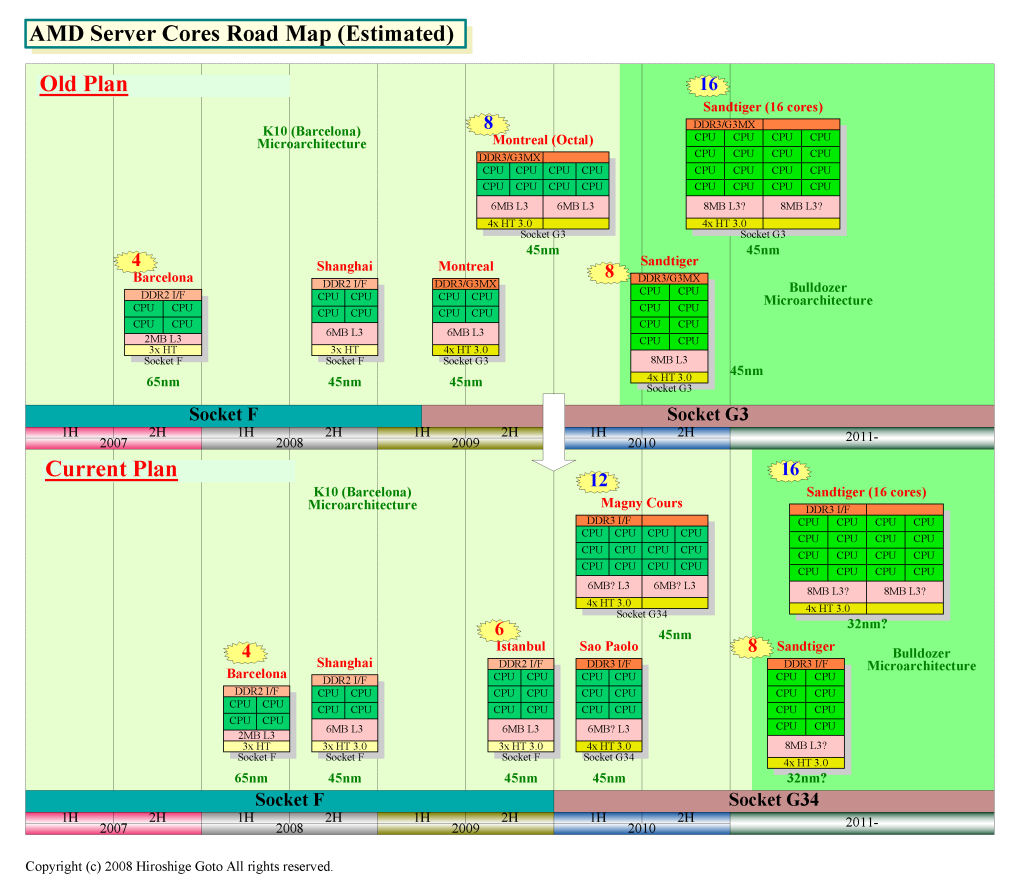
下の図は、AMDの従来のプランと、現在のプランを比較したサーバーCPUコア群のロードマップだ。
 |
| サーバーロードマップ新旧プラン比較 PDF版はこちら |
現在のプラン(図の下半分)では、AMDは、図のように、Barcelona→Shanghai(シャンハイ)→Istanbul→Sao Paolo(サンパウロ ※AMDによる表記)/Magny CoursとサーバーCPUを刷新して行く。プラットフォームの更新は2010年前半のSao Paoloから導入される「Socket G34」から、CPUマイクロアーキテクチャの更新は2011年以降にずれたと見られる。
それに対して、以前のプラン(図の上半分)ではBarcelona→Shanghai→Montreal(モントリオール)→Sandtigerとなっていた。つまり、新プランではMontrealが消え、Sandtigerが2010年までのロードマップに見えなくなった。プラットフォームの更新も、前のプランでは2009年前半のMontrealの「Socket G3」からだった。BulldozerコアはSandtigerからで2010年前半だった。比較すると、マイクロアーキテクチャとプラットフォームの刷新がずるずると後退していることが一目瞭然だ。
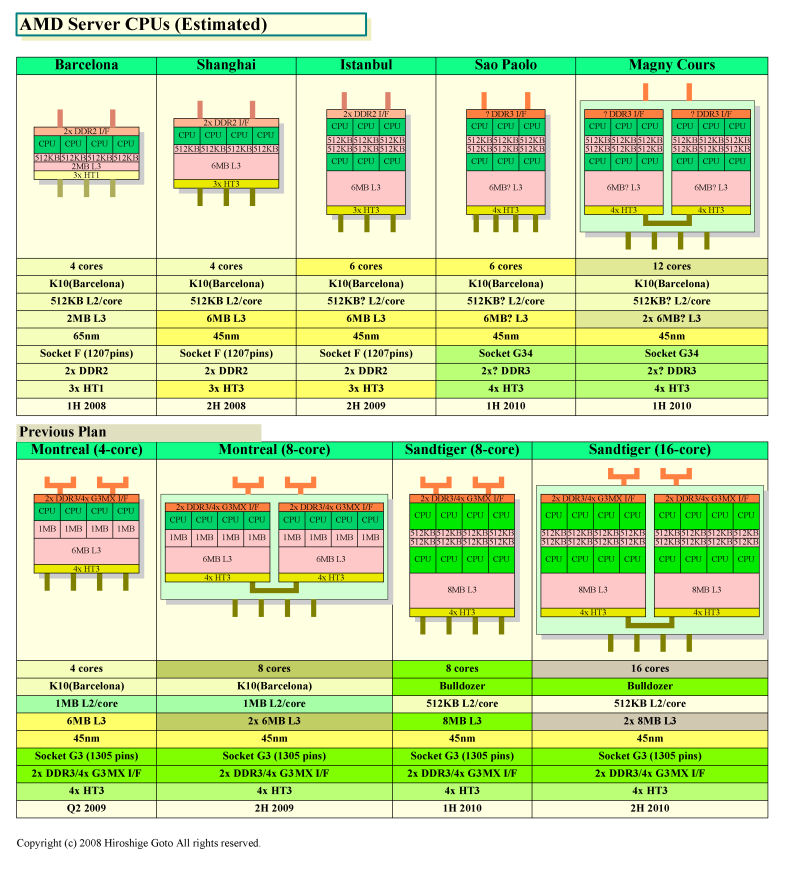
もう少し詳しく見て行こう。AMDは、今年後半に、4コアのBarcelonaを45nmプロセスへと移行させたShanghaiの量産を開始する。Shanghaiでは、CPUコアは4コアのまま、共有L3キャッシュを2MBから6MBに増強する。45nmプロセスによって、動作周波数の引き上げと、アイドルパワーの削減が可能になるという。また、まだ詳細は明かされていないが、クロック当たりの命令実行性能「Instruction-per-Clock(IPC)」も向上されるという。
ShanghaiはBarcelonaと同じSocket Fベースで、ドロップインでBarcelonaからShanghaiへと移行できる。機能的には、ハードウェア仮想マシン機能を向上させるほか、HyperTransport 3.0がサポートされる。AMDは2007年2月の半導体学会「2001 ISSCC (IEEE国際固体回路会議)」で、BarcelonaにHyperTransport 3.0を実装したことを明らかにしている。しかし、HyperTransport 3.0が有効にされるのは、Shanghaiからとなる。ちなみに、DRAMメモリインターフェイスは、BarcelonaですでにDDR2/DDR3両対応のPHYを実装しているが、ShanghaiでもDDR2しか有効にされない。ただし、サーバープラットフォームでサポートするメモリ速度はDDR2-667からDDR2-800へとShanghaiで引き上げられる。
AMDの顧客に対する説明でのShanghaiの位置は微妙に揺れて来た。昨年(2007年)中は2008年に出荷の見込みだったShanghaiは、今年に入り2009年に後退していた。今回のアナウンスでは、今年後半に量産と、やや微妙な表現がされている。
●CPUコアを6コアにし、次のステップでプラットフォームを刷新
新ロードマップでは、Shanghaiの後ろ、来年後半に6コアのIstanbulが登場した。AMDが顧客に対してIstanbulの説明を始めたのはわずか約1カ月前。顧客にとっても、かなり新しいプランだ。
Istanbulは一言で言えば、つなぎの6コアだ。ソケットはSocket Fのまま、ドロップインでのShanghai置き換えを狙う。プロセスはShanghaiと同じ45nmで、L3キャッシュも同じ6MB。詳細は明らかになっていないが、L2キャッシュも各コア512KBづつだと推定される。キャンセルになったMontrealは、L2が各コア1MBに倍増される予定だった。Istanbulは、おそらく、Shanghaiを6コアに拡張した製品だと推定される。
Istanbulをベースに、プラットフォーム側を刷新するのが、2010年前半のSao Paoloだ。Sao PaoloはIstanbulと同様に45nmプロセスで6コアだが、インターフェイス回りが異なる。Sao Paoloでは、新ソケットSocket G34になり、メモリサポートはDDR3に、HyperTransportは3リンクから4リンクへと増強される。実際には、Socket G34で、すでにBarcelonaから実装されているこれらの機能が有効にされる。
Magny CoursはSao Paoloと同じSocket G34ベースで、CPUコア数が倍の12コアの製品だ。AMDは、キャンセルされたMontrealでもMCMによるデュアルダイCPUを製品化する計画を進めてきた。Magny CoursもMCM技術によるデュアルダイCPUだと見られる。45nmプロセスで12コアをシングルダイで製造すると、歩留まりが非常に悪くなってしまうため、経済的にはMCM化が合理的となる。
 |
| AMDのサーバーCPUの概要 PDF版はこちら |
●じりじりと後退を続けるAMDの次世代CPUコアBulldozer
AMDの新ロードマップで重要なポイントは、従来のロードマップにあったネイティブ8コアでBulldozerコアベースのSandtigerが見えなくなったことだ。コードネームはどうなるかわからないが、AMDがネイティブ8コアCPU開発を止めたとは思えない。サーバーでは、汎用CPUコアを増やすことで、パフォーマンスアップを図ることができるため、今後もCPUコアの増大が続くと見られているからだ。
また、AMDがCPUマイクロアーキテクチャの刷新も諦めたとは考えられない。Intelが2年サイクルでCPUマイクロアーキテクチャを刷新し続けるため、AMDもマイクロアーキテクチャの刷新が急務となっているからだ。すでに概要を発表してある新命令セット拡張「SSE5」の実装のために、CPUマイクロアーキテクチャを大きく拡張する必要がある。
そのため、Sandtigerまたはそれに相当する、Bulldozerコアのネイティブ8コアCPUは、Sao Paolo/Magny Coursの後に位置づけられていると推定される。だとしたら、製造プロセス技術は32nmとなる可能性が極めて高い。逆を言えば、新コアアーキテクチャと8コア化を32nmプロセスへと先送りしたために、今回のロードマップ変更が発生したのかもしれない。
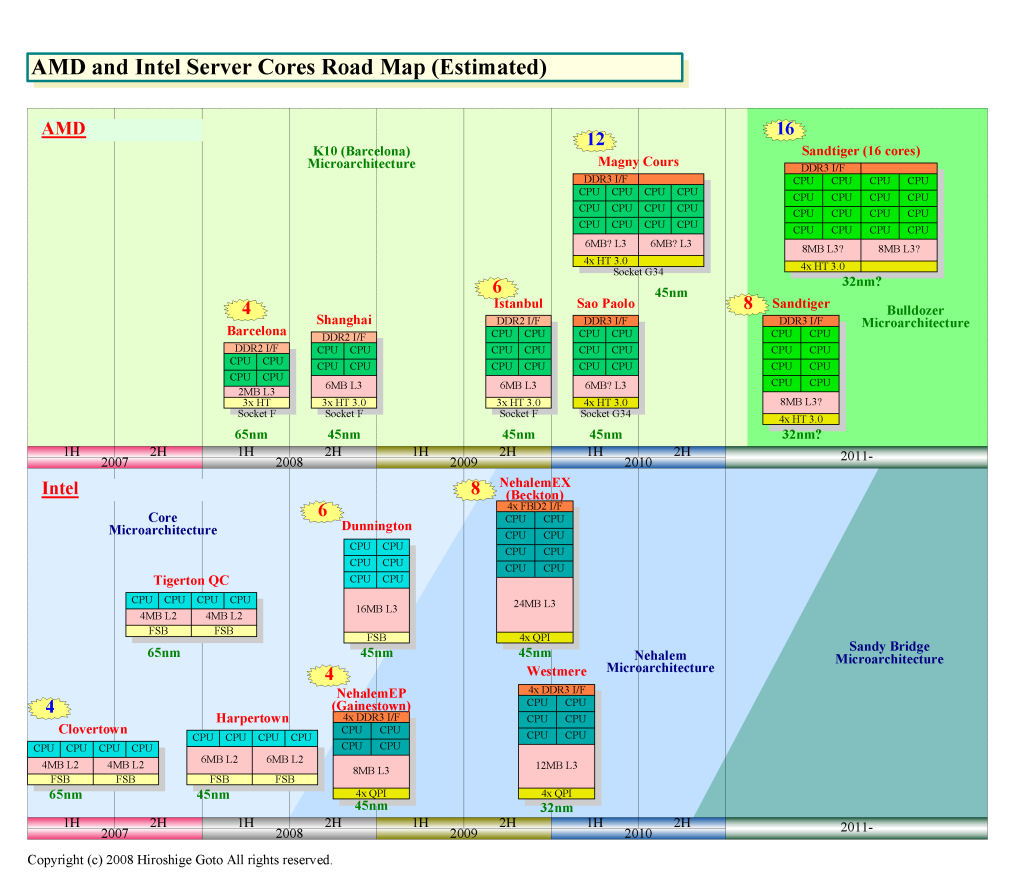
AMDが、Bulldozerコアのスケジュールを後退させたのは、今回が初めてではない。AMDは、昨年(2007年)8月の段階までは、2009年のFUSION CPUでBulldozerコアを採用するとしていた。しかし、昨年12月までに、第1世代のFUSION「Swift(スィフト)」に統合されるCPUコアは、現行のK10(K8L)世代へと巻き戻された。この段階で、2009年とみられていたBulldozerコアは、2010年に後退したと見られる。今回のロードマップ変更で、さらにBulldozerは2011年に後退することが示唆された。じりじりと、Bulldozerコアが後退している。これは、今年のNehalem(ネハーレン)でマイクロアーキテクチャを刷新し、2010年のSandy Bridge(サンディブリッジ)でさらに刷新するIntelに対しては不利な要素だ。下が、IntelとAMDのサーバーCPUロードマップを重ね合わせたチャートだ。
 |
| AMDとIntelのサーバーCPUロードマップの比較 PDF版はこちら |
●AMDはSandy Bridge対抗でBulldozerコアの設計を変更か?
しかし、Bulldozerのスケジュール後退には、ポジティブな側面もある。AMDは1世代進んだプロセスに合わせて、Sandtiger世代でより大胆なアーキテクチャ変更が可能となるからだ。そこで考えられるのは、AMDがIntelに対抗して、CPUマイクロアーキテクチャと命令セットをより飛躍させようとしている可能性だ。
そう考えると、符合する部分がある。Intelは、4月の技術カンファレンスIntel Developer Forum(IDF)で、Sandy Bridgeに256-bit長のSIMD(Single Instruction, Multiple Data)演算を導入することを発表した(従来のSSE系命令は128-bit長SIMD)。AMDがロードマップの変更を顧客に伝えたのはIDFの2週間後。もし、AMDがIDFでのIntelの発表を見て、バックアップで立案していたプランに切り替えたとしたら、時期的には符合する。
もしそうだとすれば、AMDは、Bulldozerコアのプランを、Sandy Bridgeに対抗できるように変更したことを意味する。従来プラン通りに2010年にSandtigerとBulldozerコアを投入すると、IntelのSandy Bridgeと競わなければならない。そこで、新命令拡張のフィーチャで大きく引き離されると、まずいとAMDが判断した可能性がある。特に、今回は、IntelとAMDのそれぞれの命令セット拡張に互換性がない。両社は、それぞれの命令セット拡張が、どれだけソフトウェアベンダーの支持を集めることができるか、競うことになる。そうした局面で、Intelが256-bit SIMDなら、AMDも同等の拡張を実装しようと動き始めた可能性はある。
ちなみに、AMDはBulldozerコアでは(Barcelonaコアに対して)1.3~2倍のパフォーマンス/ワットの向上を予定していた。Bulldozerは、ハイパフォーマンスコンピューティング(HPC)で特に性能が上がると示されており、元々、浮動小数点演算性能を重点的に向上させる予定だった。32nmプロセスへと1世代スライドさせ、開発期間も1年延ばすことで、浮動小数点演算をさらに引き上げようと図った可能性はある。
●不明瞭なAMDのメモリ戦略
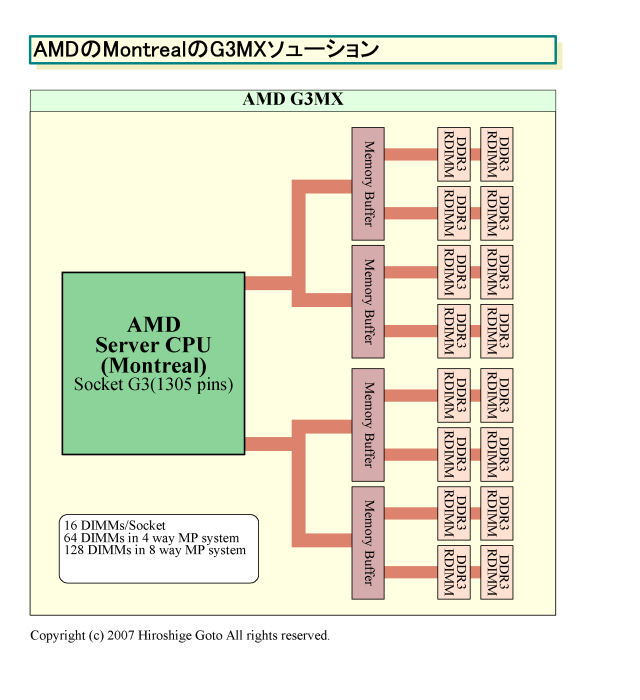
AMDの新ロードマップで不明瞭になった点のひとつは、メモリサポートだ。AMDは、MontrealのSocket G3では、Registered DIMM(RDIMM)のDDR3をサポートするほか、「Socket G3 Memory Extender (G3MX)」と呼ぶオンマザーボードのメモリバッファチップソリューションを導入する予定だった。
Socket G3世代のAMD CPUは2チャネルのDDR3インターフェイスを備える。インターフェイスはバッファチップインターフェイスと互換となっていて、各チャネルに2個のメモリバッファチップを接続できる。各メモリバッファは、2チャネルを備え、通常のDDR3 RDIMMを1チャネル2 DIMMで駆動できる。G3MXでは、合計で下の図のようなメモリ構成が可能となり、大容量のシステムメモリを搭載できるようになっていた。G3MX時には、メモリ帯域もDDR3 RDIMMを直接続した場合の2倍になる予定だった。
 |
| AMDのMontrealのG3MXソューション PDF版はこちら |
AMDは、今回、Sao Paoloから導入される新ソケットがSocket G34になるとアナウンスした。Socket G34と4がついたのは、Socket G3からの変更があったことを伺わせる。実際、AMDは今回のSocket G34についてDDR3サポートは明らかにしたが、G3MXバッファチップソリューションについては言及しなかった。AMDは、メモリ戦略も仕切り直ししている可能性がある。ただし、AMDが極めて広いメモリ帯域を必要としている点に変わりはない。CPUコア数が増える分だけ、より多くのメモリ転送が必要となるからだ。
AMDの今回のロードマップ刷新は、Intelとの厳しい競争で追いまくられる同社の状況を浮き彫りにした。6コアのIstanbulも、Intelが今年末までに投入する6コアの「Dunnington(ダニングトン)」に対抗する意味があると思われる。そして、来年後半のIntelのネイティブ8コアの「NehalemEX(Beckton:ベックトン)」に対抗するには、12コアしかないと考えたのかもしれない。
最後に、AMDが今回使った「Sao Paolo」の綴りは、英語圏での一般的な綴り「Sao Paulo」とは異なっている。現地ブラジルのポルトガル語の綴りは「Sao Paulo(※Saoのaの上にチルダ『~』がつく) 」となる。ただし、Sao Paoloという綴りも非常によく使われており、一般に受け容れられているため、そのままにしてある。
□関連記事
【5月8日】AMD、12コアOpteronなどサーバーロードマップを更新
http://pc.watch.impress.co.jp/docs/2008/0508/amd.htm
【2007年12月27日】【海外】Bulldozerが後退したAMDのロードマップの意味
http://pc.watch.impress.co.jp/docs/2007/1227/kaigai410.htm
(2008年5月13日)
[Reported by 後藤 弘茂(Hiroshige Goto)]
【PC Watchホームページ】
PC Watch編集部 pc-watch-info@impress.co.jp ご質問に対して、個別にご回答はいたしません
Copyright (c) 2008 Impress Watch Corporation, an Impress Group company. All rights reserved.