 |


■後藤弘茂のWeekly海外ニュース■Bulldozerが後退したAMDのロードマップの意味 |
●サイクルが伸びるAMDのCPUマイクロアーキテクチャ刷新
AMDのロードマップでの最大の変化は、次世代マイクロアーキテクチャである「Bulldozer(ブルドーザ)」コアの後退だ。少なくとも2010年まではBulldozer(BD)コアは登場しない。それまでは、K8マイクロアーキテクチャを拡張したK10(旧K8 Rev. HまたはK8L)が継続される。その結果、K8は7年もAMDの主軸となる長命なマイクロアーキテクチャとなる。
もっとも、多くのPC業界関係者にとっては、これは驚くべきニュースではない。すでに今年(2007年)の秋頃に、AMDはBulldozerは2010年頃で、それまではK8/K10マイクロアーキテクチャが継続されることを伝えていたからだ。8月まではBulldozerが「FUSION(フュージョン)」世代で使われると説明されていたので、その後、計画が修正されたことになる。それが12月の「2007 Financial Analyst Day」で公式に明らかにされたに過ぎない。ちなみに、AMDはBulldozerがなくなるといった説明もしていないという。
Bulldozerが2010年頃となる、これ自体は必ずしもネガティブな要素ではない。BulldozerとK8の間が空くことは、K8マイクロアーキテクチャの基礎がそれだけ優れていたことの証明でもあるからだ。Pentium 4で高周波数に最適化したIntelと異なり、AMDは、K8世代で高周波数設計に振らなかった。TDP(Thermal Design Power:熱設計消費電力)の増大を懸念したからで、その結果、IntelのNetBurst(Pentium 4)マイクロアーキテクチャのように、プロセス技術側の制約で90nmプロセス以降に電力消費が跳ね上がった時も、消費電力の問題でつまずくことがなかった。IntelほどCPUコアのマイクロアーキテクチャの革新で、差し迫った状況にはなかった。
しかし、AMDのマイクロアーキテクチャの刷新のペースが、これまでになく遅くなっていることも確かだ。AMDのDirk Meyer氏(President & COO)は、2002年6月には「一般的に、メジャーCPUは2年毎に投入する。うちもライバルもこれは同じで、このトレンドは続くだろう」と語っていた。しかし、K8以降、2年毎のCPUコアのマイクロアーキテクチャの刷新は途絶えてしまった。
 |
 |
| 新コア「Bulldozer」 | モジュラーデザインのアプローチ |
●IntelとAMDともにCPUコアの刷新に失敗
AMDのマイクロアーキテクチャの刷新が遅れた理由の1つはIntelと同じで、次期マイクロアーキテクチャについての軌道修正があったからだ。例えば、K8とBulldozerの間には、もともとは「K9」プロジェクトがあったがキャンセルとなった。「K9は犬だったから(canineと発音が同じ)」というのが、AMDがK9について必ず語るジョークだが、実際には電力効率の面で満足できるアーキテクチャに至らなかったためだと推測される。
Intelも、もしCore Microarchitecture(Core MA)がなければ、Pentium 4から「Nehalem(ネハーレン)」まで空いてしまったはずだ。IntelはNetBurstを拡張し、命令デコーダを2段にするなどの拡張を行なったTejas(テハス)をキャンセルしている。IntelもAMDも、マイクロアーキテクチャの刷新では、大きなつまずきがあった。
もっとも、CPUコア刷新のペースが開いたことは、決してCPUの進化が停滞していることを意味しない。CPU進化のトレンドが変化したからだ。現在は、相対的にCPUマイクロアーキテクチャの刷新が重要ではなくなっている。
かつては、プロセス技術が1世代進化すると、CPUコアの規模も2倍近くになった。倍々でのCPUコアの拡張には、CPUマイクロアーキテクチャの抜本的な刷新が必要となる。しかし、現在はプロセス技術が進むとCPUコア数を増やす方向へ向いている。CPUコア自体は、以前のようなペースでは肥大化させていない。そのため、CPUマイクロアーキテクチャの抜本的な刷新は必ずしも求められていない。
AMDのPhil Hester(フィル・へスター)氏(Senior Vice President & Chief Technology Officer(CTO))は、以前のインタビューで、CPUに含む非CPUコア(アンコア)部の革新の比重が高まっていると指摘、また、CPUコアを大きく拡張することで革新できると語っていた。汎用CPUコアは、大がかりな刷新は短サイクルでは行なわず、K8からK10への拡張のように、既存CPUコアに時代に合わせた拡張を加えることで性能カーブを維持。非コア部の革新やサブのプロセッサコアを加えることで性能を飛躍させるというのが、AMDの現在の方向性だ。
ちなみに、IntelのCPU設計センターのうち、Core MAを開発したイスラエルのハイファデザインセンターの開発手法も、CPUコアに関しては、AMDの方向と似ている。Pentium M(Banias:バニアス)→Core Duo(Yonah:ヨナ)→Core MA(Merom:メロン)と、連続的な継承性のある拡張を行なうことでCPUコアを発展させている。
●浮動小数点演算を2倍にブーストするNehalem
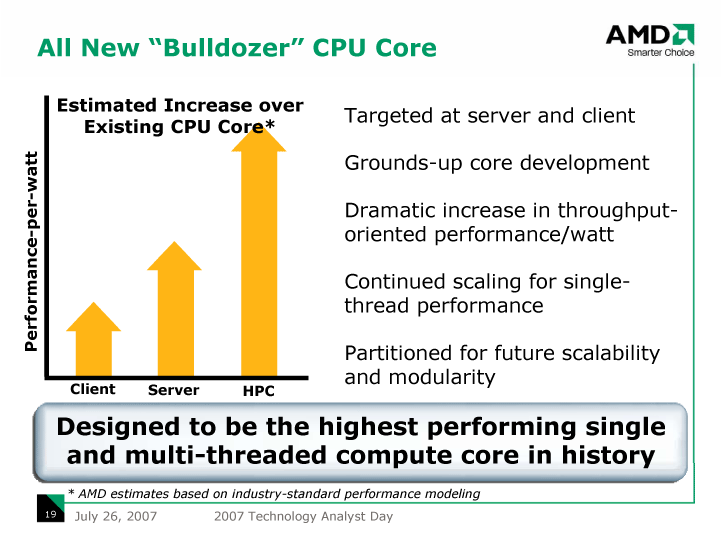
こうした状況で、より長いサイクルで行なう、CPUのマイクロアーキテクチャの刷新の方向性も以前とは変わってきている。マルチコア時代のCPUコアでは、CPUコアのパフォーマンス/電力の向上が必要とされるからだ。AMDが、BulldozerでCPUコアを抜本から切り替えようとするモチベーションもそこにある。
「ラフに言ってBulldozerコアは、(Barcelonaコアに対して)1.3~2倍のパフォーマンス/ワットの向上に設計される」とHester氏は語っていた。マイクロアーキテクチャレベルで、パフォーマンス/電力をどれだけ高められるかが競争となっている。
そして、NetBurstの失敗に懲りたIntelは、この点で非常にラディカルになっている。Intelは、Core MA以降は、CPUマイクロアーキテクチャを2年サイクルで刷新する態勢に切り替えた。マイクロアーキテクチャレベルで新しい技術をトライすることで、よりパフォーマンス/電力の優れたCPUへの進化を加速させようという戦略だ。
もっとも、Nehalemでは電力に対するパフォーマンスの向上だけでなく、絶対的なパフォーマンス値自体も高める。特に、浮動小数点演算性能の向上は顕著だ。Nehalemでは、Core MAに対して、SEPFfp(rate2006)ベンチマークで2倍近い性能にブーストされるとIntelは説明しているという。これだけ高い比率の性能向上は、かなり異例だ。
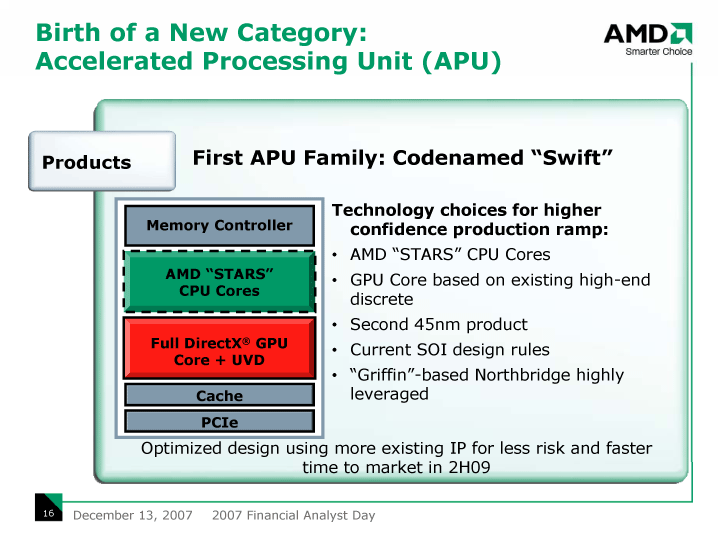
TDPを一定に保ちながら、性能をブーストするNehalemマイクロアーキテクチャの登場は、AMDにとって脅威となりうる。特に、Nehalemの浮動小数点演算性能は、Bulldozerに対しての挑戦状だ。そのため、Nehalemの性能予測を入手したAMDが、BulldozerコアとBulldozerベースのCPU製品の計画を修正している可能性はありうる。
また、BulldozerとFUSIONでは、AMDは慎重にならざるをえない理由もある。それは、命令セットレベルで、AMDとIntelがより広く分かれてゆく分岐点になる可能性が高いからだ。AMDは、Bulldozer以降のCPUコアではAMD版SSE5で3オペランドの命令拡張を行ない、将来はGPUコアをCPU側からのリソースとして命令レベルで利用できるようにしようとしている。BulldozerコアとBulldozerベースのFUSIONからそれがスタートすると推測される。
AMDはIBMとのプロセス技術開発連合もあって、プロセス技術でもIntelとの差異が大きくなりつつある。AMDは、Intelに対して、CPUのマイクロアーキテクチャだけでなく、命令セットアーキテクチャやプロセス技術でも、どんどん分かれつつある。技術的には、これから数年が、AMDにとって最もチャレンジの時期となる。
 |
| 現在のFUSIONのプラン |
●既存CPUコアのままアンコアとソケットを変更
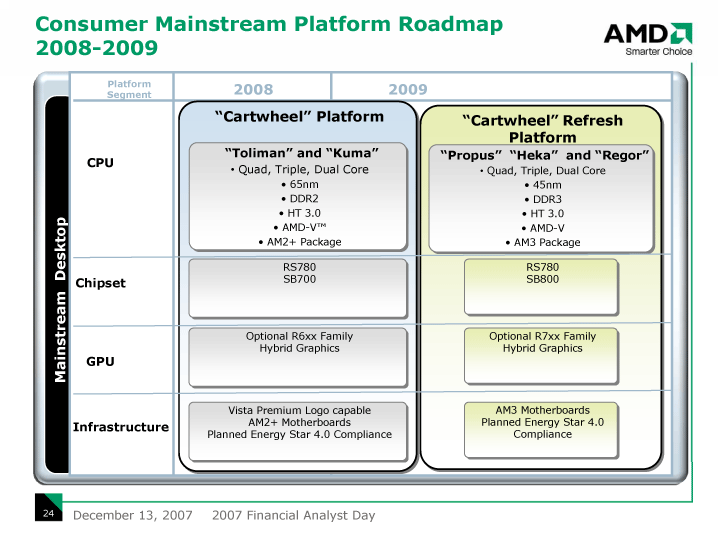
AMDの現在のCPUロードマップは、現在見通せる2009年までの範囲では、K8系またはK10系コアのままアンコア部とソケットを変えるものとなっている。もっと正確に言えば、デスクトップ&サーバーでは、すでにアンコアに実装している機能を、ソケット変更とともにイネーブル(有効化)にして行く。モバイルではアンコアをモバイル用に最適化する。
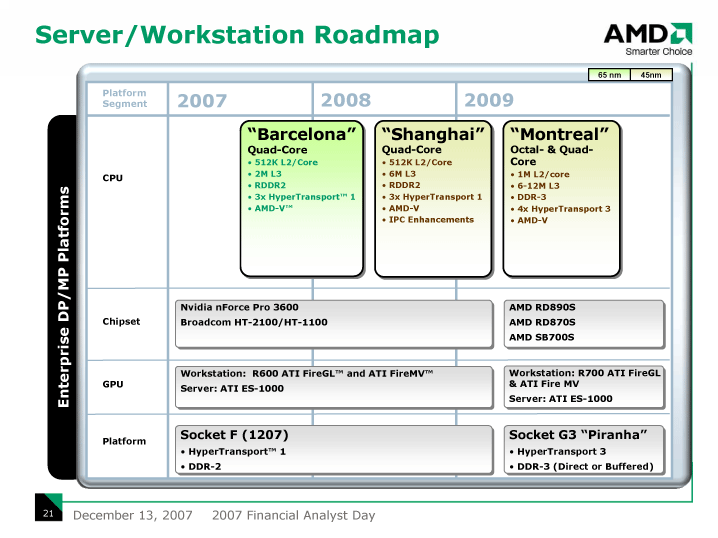
サーバー&ワークステーションでは、65nmプロセスのネイティブクアッドコアのBarcelonaから、来年(2008年)に45nmの「Shanghai(シャンハイ)」に、そして、2009年にクアッドコアとオクタルコア(Octal-core)の2種類がある「Montreal(モントリオール)」へと移行する。MontrealのオクタルコアはMCM(Multi-Chip Module)になると言われている。Montrealでは、各コア占有のL2キャッシュが1MBとなっており、512KB L2のShanghaiとは異なっている。Bulldozer(BD)コアのネイティブオクタルコア「Sandtiger(サンドタイガー)」は、2009年までのロードマップにはない。
 |
| サーバー&ワークステーションのロードマップ |
MontrealからAMDは、新しい「Socket G3」に移行する。Socket G3には、「Piranha(ペラーニャ、日本語読みはピラニア)」というコードネームが新たにつけられた。Socket G3は、HyperTransport3と、DDR3をサポートする。Montrealでは4リンクのx16または8リンクのx8の構成が可能だが、この機能は実はBarcelonaでも、すでに実装していると発表されている。
DDR3では、RDIMMをダイレクトに接続するほか、バッファチップ「Socket G3 Memory Extender (G3MX)」を介した大容量構成が可能となっている。以前レポートしたように、今年(2007年)9月にHester氏がインタビューで説明したG3MXの仕様は次のようになっている。
Socket G3世代のAMD CPUは2チャネルのDDR3インターフェイスを備える。G3のDDR3インターフェイスは、G3MXバッファチップ用インターフェイスと互換となっていて、各チャネルに2個のG3MXメモリバッファチップを接続できる。各G3MXメモリバッファは、2チャネルを備え、通常のDDR3 RDIMMを1チャネル2 DIMMで駆動できる。下がHester氏の示した図だ。
 |
| AMDのMontrealのG3MXソリューション |
ただし、AMDはDDR3 RDIMMを1チャネル4スロット接続するという説明も行なっているという。しかし、これは1チャネル2 DIMMまでとするDDR3のスペックとは異なっており、疑問がある。ちなみに、バッファチップを使うことで、DDR3 RDIMMの大容量構成をサポートする方向は、Intelのオクタルコア「Nehalem-EX(Beckton:ベックトン)」と同様だ。MontrealとBecktonは、どちらもメモリアドレッシングも拡張される。
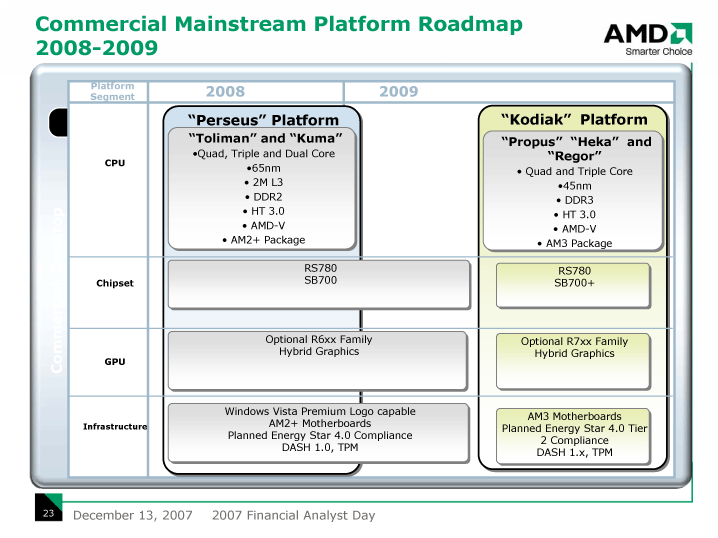
Montrealと同時期には、Socket AM3の「Suzuka(スズカ)」も投入される。これはShanghaiベースの45nmプロセスクアッドコアとなる。サーバー&ワークステーションではF1都市名シリーズのコードネームが継続される。
デスクトップロードマップもほぼ平行しており、来年には45nmプロセスへの移行が始まり、2009年にSocket AM3でDDR3をサポートする。AMDは、エンスージアスト向けプラットフォーム以外では、平均消費電力を規定するEnergy Star 4.0に準拠の予定であることを謳っている。モバイルについては、最初のFUSIONの「Swift(スウィフト)」のプラットフォーム名「Shrike」がつけられている。
 |
 |
| ノートPC向けプラットフォームのロードマップ | メインストリーム向けプラットフォーム「Perseus」と「Kodiak」 |
 |
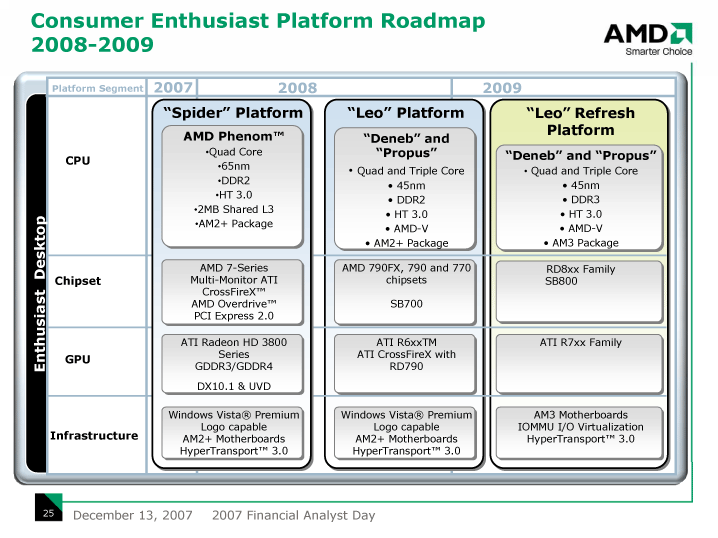 |
| メインストリーム向けプラットフォーム「Cartwheel」と「Cartwheel Refresh」 | エンスージアスト向けプラットフォーム「Spider」と「Leo」、「Leo Refresh」 |
□関連記事
【12月25日】【海外】現実路線へ修正されたAMDのFUSION
http://pc.watch.impress.co.jp/docs/2007/1225/kaigai409.htm
【10月11日】【海外】Intel NehalemとAMD FUSION両社のCPU+GPU統合の違い
http://pc.watch.impress.co.jp/docs/2007/1011/kaigai392.htm
【6月28日】【海外】AMDの製品戦略全体の再構築となるFUSION
http://pc.watch.impress.co.jp/docs/2007/0628/kaigai368.htm
(2007年12月27日)
[Reported by 後藤 弘茂(Hiroshige Goto)]
【PC Watchホームページ】
PC Watch編集部 [email protected] ご質問に対して、個別にご回答はいたしません
Copyright (c) 2007 Impress Watch Corporation, an Impress Group company. All rights reserved.