 |


■後藤弘茂のWeekly海外ニュース■GPUライクな構造が想定されるIntelの「Larrabee」 |
●TeraFLOPSクラスの性能を実現するLarrabee
「Larrabee(ララビー)」でIntelは、ハイスループットのデータ並列コンピューティングに特化したプロセッサを持つことになる。高パフォーマンスが要求されるこの市場のために、Larrabeeは1チップでTeraFLOPSレベルの性能をターゲットとしている。この数字は、倍精度ではなく単精度の浮動小数点演算のパフォーマンスだと推測される。
Larrabeeのターゲット性能は、現時点のGPUの2~3倍ということにある。ちなみに、NVIDIAの次期G9x系では、1チップで1 TeraFLOPSとほぼ同レンジの性能を達成する予定だ。NVIDIAは積和算(Multiply-Add)演算の性能だけをカウントしているわけではない。しかし、単純計算なら、AMDのR700/800も含めたGPUのパフォーマンスは、Larrabeeとちょうど拮抗すると推定される。
また、Cell Broadband Engine(Cell B.E.)の4 PEバージョンが登場すれば、演算性能的には匹敵する可能性がある。ちなみに、Cellの倍精度浮動小数点演算増強版である「HPC Cell」の最初の製品は、周波数当たりの単精度演算性能は、現在のCell B.E.と変わらない。Larrabeeも、x86互換性のために倍精度浮動小数点演算はサポートしているはずだが、その演算スループットは不明だ。
ダイサイズ(半導体本体の面積)当たりのパフォーマンスという点で見ると、違う側面が見えてくる。Intelは、昨年(2006年)のIntel Developer Forum(IDF)で、インオーダ型の小型CPUコアでは、伝統的なアウトオブオーダCPUコアよりもダイ面積当たりの演算パフォーマンスは4倍になるという試算結果を出した。それなら、65nmプロセスで4GHz時に、伝統的CPUコアと同面積で100GFLOPS以上を達成することができる。
Larrabeeの利点は、CPUと同様にフルカスタムで回路設計からチューンすることで、動作周波数をCPU並に上げることができる点だ。あるCPU業界関係者は、「GPUはASICであるため、どこまで行ってもCPUには周波数で離される」と語る。浮動小数点演算に特化したLarrabeeでは、Pentium 4レンジの動作周波数になると予想される。
しかし、それでもLarrabeeのターゲット性能には足りない。LarrabeeがIntelのPC向けCPUと同様に、経済的なダイサイズ(半導体本体の面積)だとすると、ダイ当たりの性能が4倍では、ワンチップで1 TeraFLOPSを超えることが難しい。逆を言えば、デスクトップCPU並のダイサイズで、TeraFLOPS性能を出すとしたら、パフォーマンス/ダイ面積は常識外れに高いことになる。
そのため、Larrabeeのコアは、さらに制御を簡素化した、GPUライクなベクタプロセッサ型構造を持っていると推定される。GPUのようなベクタプロセッサは、ダイ面積当たりの演算ユニット数は非常に多い。しかし、CPUと比べると動作周波数が低いために、ダイ面積当たりのパフォーマンスが削がれている。
つまり、GPUライクな構造のベクタプロセッサを、CPU並のクロックで動作させるなら、極めてダイ面積当たりのパフォーマンスの高いCPUが実現できることになる。原理的には、45nmプロセスで、現行のCore 2 Duoと同程度のダイサイズで、TeraFLOPSを超えるプロセッサを作ることが可能になる。おそらく、これがLarrabeeの基本コンセプトだ。
 |
| Small cores for high power efficiency (※別ウィンドウで開きます) PDF版はこちら |
●Larrabeeはベクタ型のプロセッサ構造を取る
Larrabeeのアーキテクチャについては、まだ概要が明らかにされていない。今見えているのは、Larrabeeが多数のCPUコアを搭載、CPUコアはそれぞれインオーダ型のシンプルなIA(Intel Architecture) CPUコアで、4wayのハードウェアマルチスレッディングをサポートすることだけだ。しかし、性能レンジから考えると、Larrabeeはベクタ型のプロセッサである可能性が高い。
だとすると、Larrabeeの中で多数のプロセッサエレメントを、連結したベクタとして制御していることになる。これは、個々のプロセッサコアがそれぞれ別なスレッドを独立して走らせる汎用のマルチコアCPUとはかなり異なる。
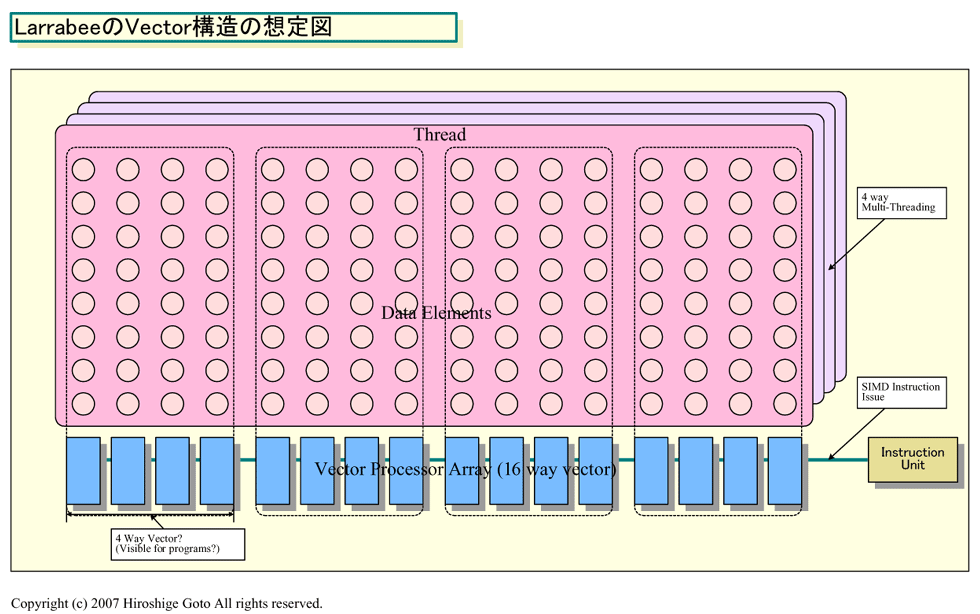 |
| Larrabeeのベクタ構造の想定図(※別ウィンドウで開きます) PDF版はこちら |
実際、多くのソースが、Larrabeeがベクタ型のプロセッサであるとしており、データ並列アプリケーションでの効率を上げるという点から考えて、間違いがないと推測される。データ並列アプリケーションで性能を上げるには、GPUのようにプロセッサの制御機構は可能な限り単純にして、小型化した演算コアを多数搭載するアーキテクチャが有利だからだ。
その場合、Larrabeeのベクタサイズとマルチスレッディングのバランスが重要なカギとなる。Larrabeeと同じようにデータ並列プロセッシングに特化したプロセッサであるGPUは、複数の演算プロセッサをバインドして制御する。1個の命令ユニットが、各プロセッサに同じ命令を発行するSIMD(Single Instruction, Multiple Data)/MIMD(Multiple Instruction, Multiple Data)型の制御を行なっている。クラスタ内のプロセッサ群はバインドされたまま、完全に同期して動作する。
例えば、Radeon HD 2900(R600)系では16個のシェーダプロセッサが、GeForce 8800(G80)系では8個のストリーミングプロセッサが1クラスタにまとめられている。各プロセッサは、もともと同期しているため、それぞれのプロセッサで走るスレッド間で明示的に同期させる必要がない。
それに対して、マルチスレッドを走らせるCPUの場合は、それぞれのスレッドは基本的には独立して制御されている。そのため、データの依存性の解決のために、スレッド間で同期を取る必要がある。マルチコアCPUで、各スレッドが異なるCPUコアで走っていたとしても、事情は変わらない。マルチスレッディングでは、より複雑な制御が必要となり、プロセッサ全体の機構が複雑となる。
●ベクタとマルチスレッドを組み合わせる
ベクタ型プロセッサには、こうした利点があるが、その一方で、ベクタ制御するサイズが大きくなると、条件分岐などの効率が悪くなるという難点がある。ベクタサイズが小さければ小さいほど効率はよくなる。過去のGPUでは、数百個のエレメントをバインドしていたが、現在のGPUでは、バインドするデータエレメントのサイズを32~64個程度にしている。
しかし、ベクタのサイズを小さくしたことで、現在のGPUではレイテンシの隠蔽のためにハードウェアによるマルチスレッド制御が必要となった。そのため、最新GPUの場合、スレッドバッチ(ベクタで処理するバンドル)をインタリーブすることで、演算ユニットの実行レイテンシを隠蔽。さらに、スレッドバッチをマルチスレッディングで切り替えることで、メモリアクセスのレイテンシを隠蔽している。
例えば、NVIDIAのG8x系の場合は、8個のストリーミングプロセッサがそれぞれ4サイクルに渡って、同じ命令を実行する。命令は同じだが、処理する対象は、1つのスレッドバッチ(NVIDIAではwarpと呼ぶ)に属する異なるデータエレメント(ピクセルなど)となる。8個のプロセッサが4サイクルに渡り処理するため、warpのデータエレメントのサイズは32個となっている。次に、G8xは別なスレッドバッチ(warp)に対して4サイクル同じ命令を実行する。複数のスレッドバッチをインタリーブして処理することで、演算実行のレイテンシを隠蔽してしまう。
さらに、よりレイテンシが長いメモリアクセスの場合には、GPUはマルチスレッディングを行なう。一般にGPUは、メモリアクセス命令を発行する段階になると、そこでスレッドバッチ自体を別なスレッドバッチにスワップしてしまう。データがロードされるまで、スワップされたスレッドバッチはスリープ状態に置かれ、別なスレッドバッチが実行される。
こうした基本的な仕組みは、NVIDIAのG8x系とAMDのR6xx系のどちらも共通している。2社が、同じ問題の解決のために、全く同じ解法にたどり着いた。LarrabeeとGPUが目指すアプリケーション領域が重なり合っていることを考えると、Larrabeeも同様に、ベクタとマルチスレッディングのバランスを取ると推測される。
●Larrabeeのベクタ構成は16way?
Larrabeeのベクタ長は、Larrabeeのコア数についてさまざまな数字が伝わっていることと無関係ではないかもしれない。例えば、Larrabeeが単精度浮動小数点演算で4wayのベクタユニットを4個バインドして16wayのベクタとして制御しているのなら、どちらを“コア”として数えるかによって、プロセッサコア数は4倍違ってくる。実際、以前露出したIntelのLarrabeeの基礎研究と思われる資料では、16way(512-bit)のベクタユニットとなっていた。
これは、プログラムにベクタをどこまで露出させるかという問題とも関わってくる。汎用CPUのスタイルでは、例えば、プログラムに対して16wayのベクタとして見えるようにする。一方、GPU的なスタイルでは、例えば、プログラムからはSSEユニット同様に4wayのベクタとして見えるが、実際にはLarrabee側で自動的に16wayベクタに構成して実行するようにする。この場合は、ソフトウェア側からは、Larrabeeは4wayのベクタプロセッサの塊に見えることになる。
GPUでは、汎用コンピューティングの場合でも、基本的にはこのスタイルを踏襲している。そのため、1つのプログラムが自動的にベクタのデータアレイに対して適用される、シンプルなプログラミングモデルとなる。NVIDIAは、将来的にもベクタの制御部分は完全に隠蔽するGPU型のモデルを継続するようだ。
しかし、IntelとAMDのCPUメーカー2社はどんな方向に向かうかわからない。GPU型のモデルには、ベクタアレイの構造を変えてもプログラムを変更しないですむという利点があるが、実行時のセットアップに時間がかかるといった難点があるからだ。アプリケーションによっては、セットアップのオーバーヘッドが大きすぎるケースが出るとAMDは説明する。
Larrabeeが、4wayのベクタユニットを4個バインドした構造を持っているとすると、スカラ性能はかなり削がれる可能性がある。Larrabeeでは、インオーダで命令をプログラム順に実行する。その場合、スカラ命令を4wayベクタコアで実行するため、4wayのユニットのうち3ユニットが遊んでしまうことになる。Intelは、こうしたケースについても、何らかの工夫を行なっているかもしれない。
●GPUと比べると少ないハードウェアマルチスレッド数
Larrabeeが16wayのベクタだとすると、LarrabeeはGPUのようにマルチサイクルに渡るベクタ処理を行なっていると見られる。GPUベンダーは、ベクタプロセッシングするデータエレメントの粒度は、32~64がスイートスポットだと説明している。例えば、16wayベクタプロセッサで4サイクルかけてプロセッシングすると、スレッドバッチの粒度は64エレメントとなる。そうすれば、4サイクルに渡って実行レイテンシを隠蔽することが可能になる。
ただし、4サイクルでは、Larrabeeの演算ユニットの実行レイテンシを完全に隠蔽することは難しい。1 TeraFLOPS以上という、Larrabeeの性能レンジから推測すると、LarrabeeはIntel CPU以上の高クロック動作を目指しているはずだ。その場合、浮動小数点演算ユニットの実行レイテンシは4サイクル以上になる。
そのため、LarrabeeもG8xやR6xxと同様に、複数のスレッドバッチをインタリーブ実行することで、実行レイテンシを隠蔽しているかもしれない。ただし、Larrabeeのハードウェアマルチスレッドは4スレッドで、そうした制御を行なうにはスレッド数が足りない。そのため、より深いサイクルでベクタプロセッシングを行なっている可能性が高い。
GPUと同様に、Larrabeeもマルチスレッディングで、メモリレイテンシを隠蔽する必要がある。しかし、4スレッドと言われるLarrabeeのハードウェアマルチスレッド数は、GPUのマルチスレッドと比べるとずっと少ない。現在のGPUでは、通常、数十スレッドをハードウェアで切り替え可能だからだ。ただし、GPUの深いマルチスレッディングには、グラフィックスの特殊な事情がある。
GPUの場合、グラフィックス処理については、メモリレイテンシが非常に長い。理由はいくつかある。グラフィックスでは、通常、キャッシュヒット率がCPUと比べて低く、ビデオメモリアクセスが多い。また、ビデオメモリのアクセス自体のレイテンシが長い。メモリ効率を高めるためにデータギャザリングを行なうことも、レイテンシを長くしている。さらに、テクスチャフェッチの場合にはメモリからロードだけでなくフィルタリングのレイテンシが加わる。また、従来のGPUのオンチップメモリはデータのバッファ的な役割で、処理したデータをオンチップメモリに保持して再利用する機構も持たなかった。こうした事情から、GPUでは長いメモリレイテンシを隠蔽するために、深いマルチスレッド機能を備えるようになった。
それに対して、汎用なデータ並列コンピューティングではデータの局在性が期待できるアプリケーションも多い。Larrabeeは、CPUコア間のキャッシュコヒーレンシを取るキャッシュメモリを備えているため、データを低レイテンシで再利用できる。また、グラフィックス処理でなければ、データのフェッチに、フィルタリングのような余計なレイテンシが加わらない。Larrabeeがフォーカスするアプリケーションが、グラフィックスより汎用的なエリアなら、切り替えるスレッド数が少なくても対応しやすいと推定される。
ただし、このことは逆に、Larrabeeではグラフィックス処理時にはフルパフォーマンスが期待できないことも予期させる。グラフィックスタスクで長いメモリレイテンシが多発する場合には、Larrabeeのアーキテクチャでは演算コアがアイドルになり、フルパフォーマンスを達成することが難しくなる可能性がある。
Larrabeeの詳細はまだわからない。しかし、Larrabeeの基本的な考え方は、ターゲットとするアプリケーションや性能、断片的な情報から見えてくる。Intelが作ろうとしているのは、GPUのように演算コア密度の極めて高いプロセッサでありながら、CPUのクロックで動作し、Intel CPUの命令セットがそのまま通るプロセッサだ。つまり、Intelの強みを活かしたベクタプロセッサとなる。
□関連記事
【6月18日】【海外】IntelのLarrabeeに対抗するAMDとNVIDIA
http://pc.watch.impress.co.jp/docs/2007/0618/kaigai365.htm
【6月11日】【海外】Intelが進める、32コアCPU「Larrabee」
http://pc.watch.impress.co.jp/docs/2007/0611/kaigai364.htm
【5月28日】【海外】「Griffin」から「FUSION」への道
http://pc.watch.impress.co.jp/docs/2007/0528/kaigai362.htm
(2007年6月20日)
[Reported by 後藤 弘茂(Hiroshige Goto)]
【PC Watchホームページ】
PC Watch編集部 pc-watch-info@impress.co.jp ご質問に対して、個別にご回答はいたしません
Copyright (c) 2007 Impress Watch Corporation, an Impress Group company. All rights reserved.