 |


■後藤弘茂のWeekly海外ニュース■IntelのLarrabeeに対抗するAMDとNVIDIA |
●データ並列に向けてIntelとAMDとNVIDIAが激突
Intelが2008~9年に投入する、メニイコアプロセッサ「Larrabee(ララビー)」。Intelは、Larrabeeによって、“ハイスループットコンピューティング”とIntelが呼ぶデータ並列アプリケーション向け市場に専用プロセッサで参入する。
しかし、この市場を狙うのはIntelだけではない。AMDとNVIDIA、この2社も同じ市場を目指している。むしろ、GPUコアを使った「GPGPU(汎用GPU)」または「GPUコンピューティング」で先行しているのは、AMDとNVIDIAだ。興味深いのは、3社が3社とも、データ並列型アプリケーションを新しいフロンティアと考え、そこに注力しようとしている点。新分野でのプロセッサウォーが、今まさに始まろうとしている。
もっともこれは、唐突に始まった流れではない。ATI(現AMD)とNVIDIAは5年ほど前から、GPUの汎用的な応用を強調していた。そして、IntelがLarrabeeプロジェクトを本格化させたのも4年ほど前と見られている。3社が3社とも、同じ頃に同じ市場とアプリケーションを狙った研究開発をスタートさせたことになる。
その背景には、既存の汎用CPUによる汎用的なコンピューティング性能のアップでは、目覚ましいアプリケーションの変革が望めなくなってきたという事情がある。そもそも、何が汎用コンピューティングなのか、その定義も変わろうとしていると、Intelのメニイコアプロジェクトを率いるJim Held氏(Intel Fellow & Director of Intel Tera-scale Computing Research, Intel)は指摘する。つまり、革新的なアプリケーションが求めるコンピューティング性能は、大量のデータを並列に処理するタイプに寄りつつある。それがプロセッサ業界のコンセンサスになりつつあるようだ。
そして、ここにLarrabeeを投入するIntelを、2社は強く警戒している。あるGPU関係者は「Larrabeeこそ最大の脅威」という。それは、GPUが切り開きつつある新市場を一気にさらわれる可能性があるからだ。
AMDにとって見れば、Intelがこの市場でスタンダードを打ち立て、Intelのプログラミングモデルを業界標準とされてしまうと、再びx86の二の舞になってしまう。プログラミングコミュニティ側からすれば、できれば一種類のモデルが望ましい。そのため、勝者総取りでIntelに独占されてしまう可能性がある。Intelがx86の拡張命令セットにLarrabeeを選択した最大の理由はそこにある。
GPUベンダーであるNVIDIAにとっても、Larrabeeは大きな脅威だ。それは、CPUにGPUコアが取り込まれる流れがあるからだ。そうなると、メインストリーム&バリュー市場の低価格GPUやグラフィックス統合チップセットのビジネスが成り立たなくなってしまう。グラフィックスだけに特化していると、NVIDIAは単体のGPUベンダーとしては生き残ることができなくなってしまう。
こうした事情から、GPUベンダーであるNVIDIAは、GPUの存在をより強く打ち出すため、GPUによる汎用コンピューティングを強く推進している。CPUにGPUコアが取り込まれても、ユーザーがディスクリートGPUを求める需要を産み出すためだ。NVIDIAの新しい道は、GPUコンピューティングに開けているため、Larrabeeが最大の脅威となる。
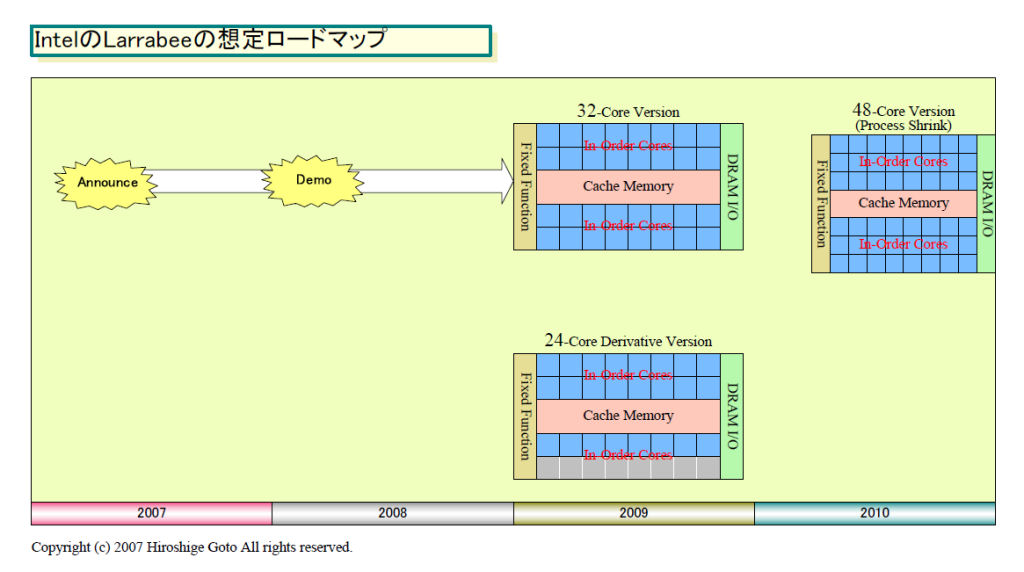 |
| IntelのLarrabeeの想定ロードマップ PDF版はこちら |
●グラフィックスパフォーマンスがカギ
では、IntelのLarrabeeをAMD幹部はどう見ているのだろうか。
AMDはCPUのFUSION化によって、CPUとGPUの機能を統合し、Larrabeeが目指すデータ並列コンピューティングもカバーしようとしている。また、旧ATIは、ディスクリートGPUをデータ並列プロセッサとして推進もして来た。より汎用的なデータ並列型のコンピューティングに向けたプロセッサ開発を目指す点では、IntelとAMDは一致している。
しかし、IntelとAMDの構想にはいくつかの違いがある。まず、目立つのは、AMDがGPUコアでデータ並列コンピューティングをカバーしようとしているのに対して、IntelがLarrabeeをGPUではなくデータ並列のためのプロセッサと位置づけた点だ。Intelは、Larrabeeの多数のCPUコアのそれぞれが、IA(Intel Architecture、この場合はx86)命令セットと互換性を持つことを明らかにしている。
 |
| Larrabeeコアの概要 PDF版はこちら |
あるAMD(旧ATI)関係者は「我々は長い間、LarrabeeはもっとGPU的なアーキテクチャだと聞いていた。IntelがストリームコンピューティングのプロセッサとしてLarrabeeをアナウンスしたことに非常に驚いている」と語る。
 |
| AMD Dave Orton氏 |
実際、Larrabeeについては、IntelのディスクリートGPUという憶測が広まっていた。AMDの旧ATI部門を率いるDave Orton氏(Executive Vice President of Visual and Media Businesses)は、次のように示唆する。
「我々はいずれも、IntelのLarrabeeについてさまざまな推測をしているし、私は、Intelがその推測を楽しんでるだろうと思っている(笑)。しかし、私は(世間の憶測とは違う)他の話も聞いているように思う。それは、(巷の)憶測をほとんど打ち消すものだ」
業界での推測以上の情報をAMDは掴んでいるようだ。では、AMDが見るLarrabeeはどのようなプロセッサなのか。Orton氏は個人的な推測とした上で次のように語る。
「私が最初に考えたのは、Intelはストリーミングコンピューティングの課題に取り組もうと考えたが、そのエレメント(プロセッサ)がグラフィックスを処理できることに気がついた、というものだった。もし、そう考えるなら、それ(Larrabee)は、“グラフィックスに最適化されたエンジンで、ストリーミングコンピューティングもできる”ものではなく、“ストリーム(コンピューティング)エンジンがグラフィックスもできる”ものということになる。そのシナリオの場合、(Larrabeeが)一般的なGPUになれるかというと、多分そうではない。そう(GPUに)なるとしても、最初の世代ではないだろう。もっとも、先のことはわからないが」
Orton氏は、Larrabeeが汎用的なストリーミングコンピューティング向けに設計されているとしたら、GPUとして十分に使えるデバイスにならない可能性がある、と指摘する。演算パフォーマンスの割には、グラフィックス性能が低い、といったケースは十分に考えられる。そして、GPUとしても高性能でなければ、グラフィックスという広い市場を獲得することでチップの出荷個数を増やして、コストを下げることが難しいかもしれない。
逆を言えば、これがGPUコアを使うAMDの利点だ。AMDのアプローチでは、ディスクリートGPU、そしてFUSION、これらにまたがって同じプログラミングモデルを利用できる。チップのコストを下げるだけでなく、普及しているGPUの上に立つことで、より広いインストールドベースをソフトウェア側に提供できるのが強みだ。
●x86との互換性が足かせになると指摘するAMD
 |
| AMD Phil Hester氏 |
一方、AMDのPhil Hester(フィル・へスター)氏(Senior Vice President & Chief Technology Officer(CTO))は、Larrabeeでのx86命令セットの実装という点に疑問があると指摘する。
「IntelがLarrabeeの設計でどんな選択をしたのかは、まだ明確にされていない。しかし、Intel対AMDという議論を離れて、データ並列型のアプリケーションに向けたプロセッサを、最も効果的に設計する方法という論点では話ができる。
PC業界全体に渡って概観すると、x86プロセッサベンダーは、グラフィックスやメディアといったジョブに向いた命令セットを継続して増やしてきた。その一方で、GPUベンダーは近年、GPUをモジュラー化して、ある種の汎用性を持たせる機能を加えてきた。より汎用プロセッサ的なマシンに近づけようとして来た、と言い換えてもいい。両者は、互いに反対の位置から、互いの位置に近づきつつある。
そのため、これをCPUとGPUの戦争だとする見方もある。しかし、率直に言うと、これは人為的な戦争だ。なぜならCPUとGPU、それぞれの開発者は、これまで異なる企業に属していて、彼らの技術を一緒にすることも、協力することもできなかったからだ。そのため、CPUとGPUそれぞれが、独自に動いていた。それが、我々(AMDとATI)が実際に合流するまでの状況だった。
こうした状況にあったため、CPU企業は、(データ並列プロセッサの開発でも)CPU的に考え、すべてをCPUに結びつけようとする。CPUとの互換性、CPUからの発展を考える。それが(Larrabeeについて)Intelの行なった選択かもしれない。そして私は、それは根本的に間違えた考え方だと思う。なぜなら、それでは走らせようとしている(データ並列型の)アプリケーションの構造に向いた設計にできないからだ。
それら(x86プロセッサとデータ並列プロセッサ)を統合した設計ができるか、と言えば、それはもちろんできる。しかし、実行効率を考えると、いい選択にはならない。x86命令セットのプロセッサは汎用向けにはいいが、並列データ実行に向いたマシンにはならないからだ。決してそのように設計はされていない。
しかし、我々の場合は、CPUとGPU、それぞれの企業が融合し、それぞれの設計者が一緒になった。そのため、それぞれのアプリケーションに最適な設計(のプロセッサコア)を統合することができる。我々は、それら(x86 CPUとデータ並列プロセッサ)をワンチップにするが、GPU自体にはCPUの命令セットは実装しない。GPUの命令セットを、CPUのユーザー命令として命令スペースに統合する。CPU命令セットを実装したデータ並列マシンを作るわけではない」
●AMDはx86 CPUとGPUそれぞれ最適化したコアを統合
IntelとAMD、CPUベンダー2社の長期的なビジョンには共通性がある。それは、x86命令セットとストリームプロセッサの命令セットの融合を目指す点だ。同じ命令ストリームの中で両者の命令を扱えるようにし、既存のx86のソフトウェア環境の資産を活かすと見られる。違うのはステップの踏み方とアプローチだ。
IntelのLarrabeeは、データ並列プロセッサ自体にx86命令セットを実装すると見られる。高スループットなデータ並列プロセッサでありながら、x86命令との後方互換性を持つアーキテクチャだ。それに対して、AMDのFUSIONは、x86 CPUコアとGPUコアを統合し、汎用向けのCPUコアとデータ並列向けのGPUコアがそれぞれのタスクに最適化すると見られる。簡単に言うと、IntelはGPUライクなx86 CPUを作ろうとしており、AMDはx86 CPUとGPUそれぞれの特徴を保持したまま統合しようとしている。
ちなみに、AMDは命令セットの統合化まにでステップを踏む。これまで、AMDはGPUのシェーダコアのネイティブ命令セットを「Close to the Metal(CTM)」イニシアチブで公開して来た(GPU全体の制御命令は抽象化している)。しかし、今回のRadeon HD 2000(R600)世代では、さらにランタイムレイヤ「AMD Compute Abstraction Layer(CAL)」を被せることでCPUとGPUのより上位での抽象化と融合を行なう。
そして最終ステップでCPUの命令セットスペースにGPU命令セットを統合し、x87コプロセッサのようにGPUコアを扱えるようにする。CPU命令セットにネイティブ統合するためには、永続的な命令のサポートが必要となり、そのためにはGPUの命令セットアーキテクチャを固める必要がある。現在は、まだその途上にある。また、将来に渡ってもランタイムでの抽象化は保持し、ランタイム経由でのアクセスも可能にする。
●x86ではないことの利点を持つNVIDIA
 |
| NVIDIA David B. Kirk氏 |
では、CPUベンダーではないNVIDIAはどうなのか。NVIDIAは、GPUアーキテクチャをより汎用的なデータ並列コンピューティングに向いた形へと進化させつつある。NVIDIAのDavid B. Kirk(デビッド・B・カーク)氏(Chief Scientist)は、GeForce FX(NV3x)アーキテクチャの時からGPUサーバーへの展開を語り続けてきた。その領域では、NVIDIA GPUとIntel Larrabee、AMD FUSIONとGPUが真っ向から対立する。NVIDIAは、もはや“グラフィックスチップ”のベンダーではない。そのため、Larrabeeが最大の敵となる。
そして、この3社の中でNVIDIAだけが、x86命令セットとは離れたスタンスにいる。将来的にもx86命令セットをGPUに持ち込むことはないだろうという。これが、NVIDIAとCPUベンダ2社との決定的な違いとなっている。
Kirk氏はLarrabeeとFUSIONについて次のように語る。
「彼らの現在の位置からすれば、x86命令セットの拡張は論理的なステップだと思う。彼らの強みであるCPU命令セットを活かすからだ。しかし、我々はx86コアを持っていないから(笑)、それは我々にとって論理的なステップにはならない。だが、これは決して我々の弱みとはならないだろう。どんな強みも、その裏は弱みにつながっているからだ。
x86互換は非常にパワフルで強みになるだろう。しかし、それは制約でもある。彼らの設計上の選択を制約してしまうからだ。レガシーを引きずると、どうしても並列ストリームに最適なプロセッサ設計にすることが難しくなる。
それに対して、我々は全くの白紙からスタートできる。そのため、望ましいと思われる選択を自由に行なうことができる。レガシーに引きずられることなく、純粋な並列ストリームコンピューティング環境を設計することが可能だ。
x86と互換にするという彼らの選択は、プロセッサに(ストリームコンピューティングには)不必要な複雑さを持ち込むことになるだろう。そうした互換設計が難しいことは(過去のプロセッサの)歴史が証明している。必ず何かが犠牲となる。ピュアな設計を目指す我々の選択が長期的にはいい結果をもたらすと信じている」
x86との互換性は有用ではあるが、プロセッサに複雑性をもたらすというのがNVIDIAの見方だ。この点でKirk氏の視点は、Hester氏と一致している。そして、NVIDIAは、ゼロからデータ並列コンピューティングに最適化した命令セットとマイクロアーキテクチャにすることで、最も効率のよいプロセッサを作ろうとしている。従来型の汎用的な処理はCPUにまかせ、GPUは最適な設計を追求するというのがNVIDIAの道だ。
NVIDIAはこのコースに沿って、GPUの機能の拡充を始めている。今後は、64-bit浮動小数点演算機能の付加や、1チップでの1TeraFLOPSの単精度浮動小数点演算パフォーマンスの達成が控えている。
●3社3様のアプローチで臨む新市場
現在推定されるIntel、AMD、NVIDIA、この3者の方向性の違いをまとめると次のようになる。
IntelのLarrabeeは、データ並列プロセッサ自体にx86命令セットを実装し、それをプログラムに対して露出させると見られる。将来はLarrabee型アーキテクチャをCPUへも統合するかもしれない。その場合、ランタイム層で制御を行なう可能性はある。その一方Intelは、既存GPUアーキテクチャを引きずるコアで、汎用的な並列コンピューティングを行なうことは、あまり考慮していない。そのため、グラフィックスのパフォーマンスは未知数だ。
AMDのFUSIONは、x86 CPUコアとGPUコアを統合し、汎用CPUコアは従来型のタスクに、GPUコアはデータ並列型のタスクに特化させる。GPUコアのネイティブ命令をx86命令スペースに統合し、命令セットを露出させつつランタイムでラップもする。また、より高パフォーマンスなディスクリートGPUも当面は平行して提供して行く。ソフトウェア側は、CPU、GPU、FUSIONに対して、ネイティブ命令セットまたはランタイム経由のどちらでもアクセスできる。
NVIDIA GPUは、x86とは全く異なる命令セットアーキテクチャで、データ並列コンピューティングに完全に最適化した設計を取る。NVIDIAは、汎用的な機能を強化しつつあるが、高いグラフィックス性能も維持する。プログラミングモデルは、GPUハードをランタイム層でラップする。将来もネイティブ命令セット自体は隠蔽すると見られる。ただし、AMDと同様にランタイムの中間コードを公開することで、コンパイラベンダーがコンパイラを開発できるようにする。
IntelがLarrabeeを公にしたことで、今後は、データ並列アプリケーションに向けた3社の競争が過熱すると予想される。
□関連記事
【6月11日】【海外】Intelが進める、32コアCPU「Larrabee」
http://pc.watch.impress.co.jp/docs/2007/0611/kaigai364.htm
【5月28日】【海外】「Griffin」から「FUSION」への道
http://pc.watch.impress.co.jp/docs/2007/0528/kaigai362.htm
【3月26日】【海外】CPUとGPUの大きな違い
http://pc.watch.impress.co.jp/docs/2007/0326/kaigai346.htm
【2月28日】【海外】GPU命令のx86体系への統合
http://pc.watch.impress.co.jp/docs/2007/0228/kaigai341.htm
【2月27日】【海外】CPUとGPUの統合プロセッサのチャレンジ
http://pc.watch.impress.co.jp/docs/2007/0227/kaigai340.htm
(2007年6月18日)
[Reported by 後藤 弘茂(Hiroshige Goto)]
【PC Watchホームページ】
PC Watch編集部 pc-watch-info@impress.co.jp ご質問に対して、個別にご回答はいたしません
Copyright (c) 2007 Impress Watch Corporation, an Impress Group company. All rights reserved.