 |


■後藤弘茂のWeekly海外ニュース■大幅に強化されたAMDのクアッドコア「Barcelona」 |
●メモリが最大の障壁となるマルチコア
AMDは、初のクアッドコアCPU「Barcelona(バルセロナ)」で、さまざまな問題に直面した。最大の壁はメモリで、そのためにメモリインターフェイスとキャッシュ回りでは、大幅な拡張が加えられている。AMDは、San Joseで10月9~11日に開催された「Fall Microprocessor Forum」で、Barcelonaのこうした拡張について説明を行なった。
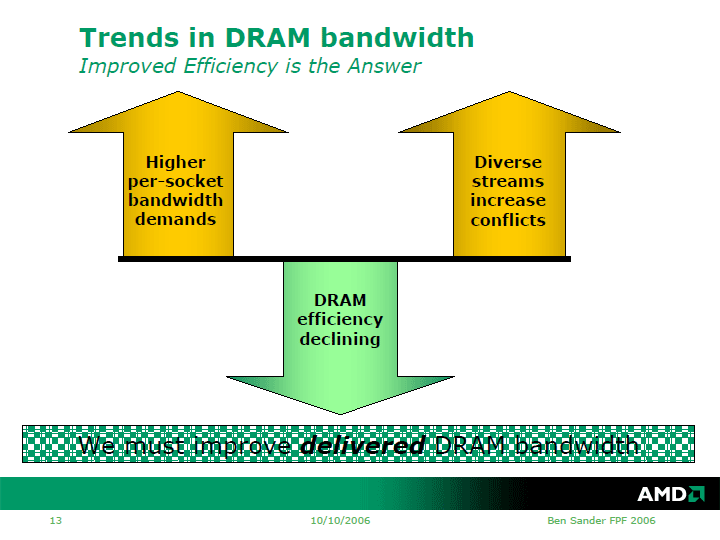
マルチコア化でメモリが問題になるのは、CPUコア数が増えるにつれて、より多くのCPUコアに命令とデータを供給する必要が生じるためだ。そのため、ソケット当たりのメモリ帯域をより広くすることが求められる。また、複数のCPUコアからの、異なるアクセスパターンのメモリアクセスが発生する。これは、ページコンフリクトも増やす傾向にあるという。
その一方で、DRAMの効率は悪化の一歩を辿っている。「DRAMはDDR2、DDR3とピーク帯域を広げてゆくが、レイテンシについては何もしていない。ほぼ一定だ。そのため効率は落ちつつある」とFall Microprocessor Forumで講演したBen Sander(ベン・サンダー)氏(AMD Principal Member of Technical Staff)は、説明する。
AMDはクアッドコア化に当たっては、4個のCPUコアをフルに回転させるために、メモリ帯域を引き上げ、メモリ効率を上げなければならない。しかし、DRAM技術の進歩はそれほど速くはない。Barcelonaでも、サポートするDRAMメモリはRev. Fと同じDDR2で、メモリのスペック上のピーク帯域は変わらない。
 |
| Trends in DRAN bandwidth (※別ウィンドウで開きます) PDF版はこちら |
●独立型DRAMコントローラでメモリアクセスを効率化
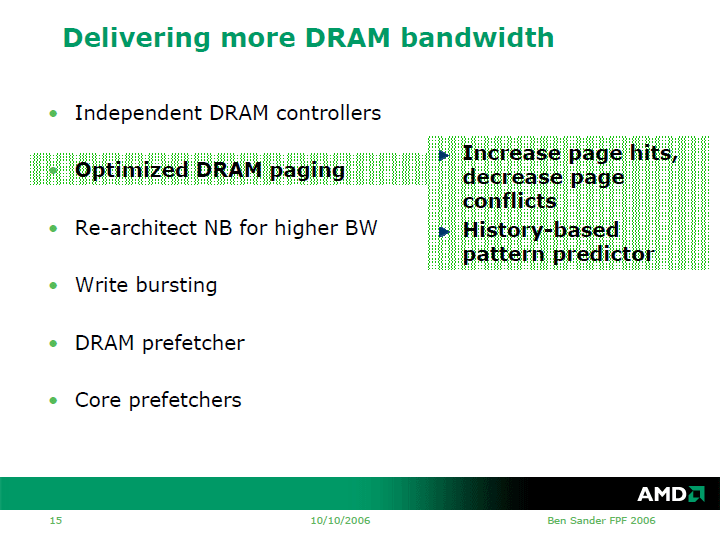
そこでAMDは、さまざまな技術を織り込むことで、メモリの実効帯域を引き上げるという。最大のポイントは独立型(independent)DRAMコントローラだ。
「今日のOpteronは2つの64bit DRAMコントローラを備える。しかし、この2つは一緒になっており、常に同じコマンドを同時にオペレートする。DRAMアクセスの1つのリクエストのうち半分を片方のDRAMコントローラに、別な半分をもう片方のDRAMコントローラに渡す。
それに対して独立型DRAMコントローラでは、それぞれのDRAMコントローラが独立してオペレートできるように分離した。ベネフィットは並列性だ。それぞれのDRAMコントローラが、それぞれ異なるアクセスを同時に処理できる。異なるCPUコアからのDRAMアクセスのリクエストを同時に処理できる。また、DRAMバンク数を増やすことで、ページコンフリクトを減らすこともできる」(Sander氏)
CPUはキャッシュラインフィルをベースにDRAMにアクセスする。Barcelonaでは、DRAMコントローラを独立して制御するため、バースト読み出しの長さも長くしたという。
 |
| Delivering more DRAM bandwidth(1) (※別ウィンドウで開きます) PDF版はこちら |
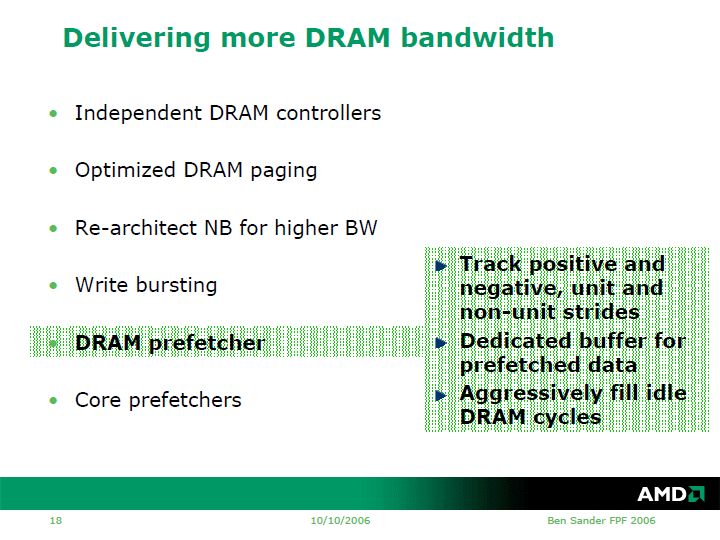
また、DRAMのアイドルサイクルを埋めることで、メモリ効率を上げられるようにDRAMプリフェッチャも強化された。より複雑なアクセスパターンに対応できるようにすることで、プリフェッチの精度を上げたという。また、DRAMのページヒットを上げ、ページコンフリクトを減らすために、アクセスヒストリをトレースすることでアクセスパターンを予測する機能を加えた。また、メモリへの書き込みをバッファリングしてバースト転送することで、DRAMリードとライトのターンナラウンドを最小にする。
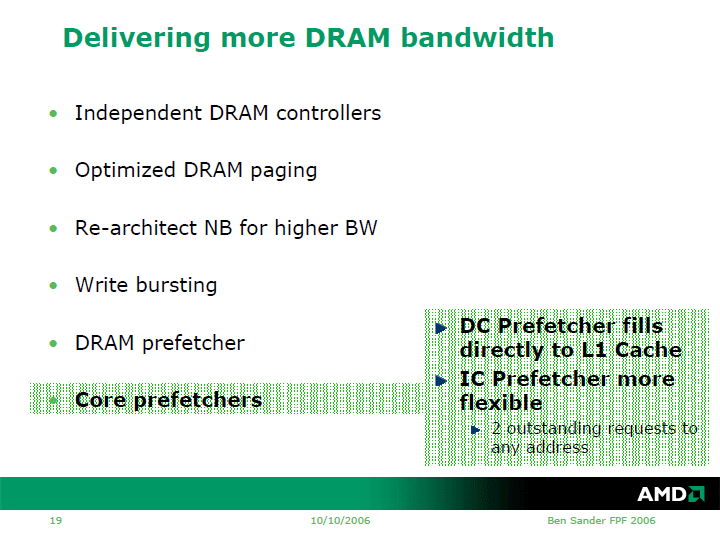
このほか、AMDはBarcelonaではノースブリッジ機能も再設計したという。バッファサイズを大型化するなど、DDR3など近い将来のDRAM技術に対応できるように拡張したと説明した。DDR3では最大1.6Gbpsまでのデータ転送が可能になる。DDR3をサポートするためには、ノースブリッジとメモリコントローラ間の帯域をDDR2の時の最大2倍に引き上げる必要があるはずだが、それについては、細かくは説明されなかった。
データキャッシュプリフェッチャ(DC Prefetcher)は、従来はL2へとロードしていたが、BarcelonaからはL1データキャッシュへ直接プリフェッチするようになった。効率上、この方がいいと判断したからだという。命令キャッシュプリフェッチャ(IC Prefetcher)も、より柔軟に改良された。
こうした改良の結果、同じDDR2メモリサポートでも、Rev. F/GとBarcelonaでは、メモリの実効帯域がかなり異なると見られる。メモリの実効帯域の拡張は、マルチコアCPUのカギであり、今後も拡張が必要になると推定される。
 |
| Delivering more DRAM bandwidth(2) (※別ウィンドウで開きます) PDF版はこちら |
 |
| Delivering more DRAM bandwidth(3) (※別ウィンドウで開きます) PDF版はこちら |
 |
| Delivering more DRAM bandwidth(4) (※別ウィンドウで開きます) PDF版はこちら |
 |
| Delivering more DRAM bandwidth(5) (※別ウィンドウで開きます) PDF版はこちら |
●キャッシュ制御をインテリジェント化したL3キャッシュ
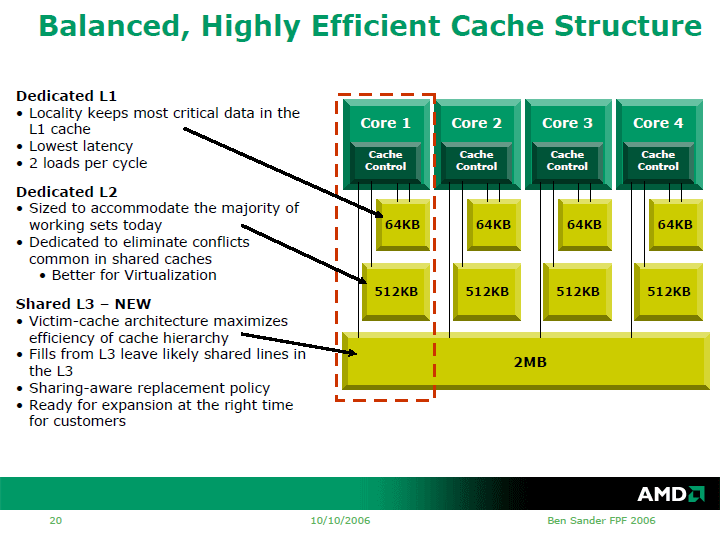
AMDは、BarcelonaからL3キャッシュを搭載、3階層のキャッシュ構成を取る。Barcelonaでは、L1データとL1命令キャッシュが各CPUコアにそれぞれ64KBずつ、占有型のL2キャッシュが各CPUコアに512KBずつあり、さらに共有の2MBのL3キャッシュを備える。また、キャッシュの階層を増やすだけでなく、キャッシュの制御方式も変えた。
AMDはキャッシュの制御に「ヴィクテムキャッシュ(Victim-Cache)」アーキテクチャ、つまり、キャッシュ階層間での排他的(Exclusive)な制御を行なうアーキテクチャを取ってきた。この方式では、L2とL1は排他的に制御されるので,L1に含まれるキャッシュブロックはL2には含まれない。L2に納められるのは,L1からあふれたキャッシュブロック(VictimまたはCopy-Back)だけとなる。この方式の場合、L2とL1には重複して含まれるデータがなくなるため、L2の量が比較的少なくても効率が上がるようになる。
しかし、この方式は複数CPUコア間で共有するL3の場合には非効率化を産みかねない。それは、共有L3から特定のCPUコアの占有L2へとキャッシュラインが移動してしまうと、他のコアがそのキャッシュラインを参照したい場合には、そのキャッシュラインを持つCPUコアのL2にアクセスしなければならないからだ。そこで、Barcelonaでは、異なる制御方式を組み合わせることでL3の効率化を図った。
BarcelonaのL3は、基本的にはヴィクテムキャッシュ制御方式を取る。しかし、共有ラインをL3に残すこともオプションとして可能となっている。特定のキャッシュラインに対して、効率のための排他制御か、共有向けの制御か、その選択はリクエストをベースにする。基本的にはコードフェッチャからの命令フェッチの場合はコピーをL3に残す。一方、データフェッチの場合はL3からL2へとデータを移動させてしまう。それ以外のケースでは、ヒストリをトラックして、同じダイ上の他のCPUコアからのアクセスがあったものはL3にコピーを残すという。
 |
| Balanced,Highly Efficient Cache Structure (※別ウィンドウで開きます) PDF版はこちら |
●仮想化ではネステッドページングをイネーブル
Barcelonaでは仮想化機能「AMD-V(Pacifica:パシフィカ)」もハードウェア的に拡張される。目玉は「ネステッドページング(Nested Paging:NP)」だ。AMDは、仮想化でのメモリアドレストランスレーションをハードウェアで行なうネステッドページング(NP)を、以前からサポートすると発表していたが、イネーブルにはされていない。Barcelonaからイネーブルにされることになったようだ。
OSはそれぞれメモリページテーブルを持つが、仮想化の場合は、複数のOSが立ち上がるため、メモリページテーブルが重複するという問題が出てしまう。そのため、仮想化では、ゲストOSのページテーブルを、ホストOSまたはHypervisorがアドレス変換して物理メモリアドレスにマップする必要がある。従来は、このメモリアドレストランスレーションは、ソフトウェアによる「シャドウページング(Shadow Paging)」で行なっていたため、低速で複雑だった。
しかし、AMDはBarcelonaからはハードウェアソリューションとしてネステッドページングを提供する。Barcelonaでは、ゲストOSとホストOS(またはHypervisor)の両方のページテーブルをハードウェア側が認識。仮想マシンのOSのテーブルから、ホストOS(Hypervisor)が管理する物理メモリテーブルへのトランスレーションをハードウェアで行なう。トランスレーションは、メモリアドレス変換のバッファであるTLB(Translation Lookaside Buffer)にキャッシュされるため、高速化される。
そのため、BarcelonaではTLB自体が大型化されている。
「TLBを大きくしたのは2つのワークロードに最適化するためだ。1つは仮想化だ。Barcelonaは仮想化でネストページング機能をサポートした。ネストページテーブルウォークでは、従来のテーブルウォークよりレイテンシがかなり長くなる。そのため、TLBは非常に効果がある。そのため、TLBを大きくする意味がある」とSander氏は説明する。
シャドウページングは、Hypervisorの場合は最大75%のサイクルタイムを占めていたため、パフォーマンスが大幅にアップする。また、Barcelonaでは、HypervisorとゲストOSの間を切り替える際のディレイであるワールドスイッチタイムも25%減るという。
 |
| Faster Virtualization Performance (※別ウィンドウで開きます) PDF版はこちら |
●Barcelonaはダイが大きい?
 |
| Barcelonaのダイ |
Barcelonaでは、CPUコアをパフォーマンス面で強化しただけでなく、AMDはメモリ回りや仮想化機能も強化した。マルチコア化とバランスを取って、増えるCPUコアへのメモリからのデータ供給を拡充。また、マルチコアをより有効に使うための仮想化のハードウェア支援も向上させるというアプローチだ。AMDは、DRAMインターフェイス統合による、アドバンテージとなる部分を活かしている。
Barcelonaで懸念材料はダイサイズ(半導体本体の面積)と、それによるコストだ。Barcelonaのダイは、予想よりもかなり大きくなると見られている。現在、AMDのデュアルコアCPUは90nmプロセスで199~220平方mm程度。65nmプロセスにシュリンクすれば、計算上はキャッシュを増量しても同程度か多少大きい程度に収まることになる。しかし、Barcelonaはそれよりもさらに大きく300平方mmクラスになると見られている。
もし、Barcelonaがこのサイズになるとすると、AMDのCPUとしては最大級となる。また、Intelのクアッドコアは、ダイサイズが143平方mmのConroe(コンロー)のダイを2個、ワンパッケージに納めたものであるため、サイズ的には同クラスとなる。Intelの方がダイが2つに分かれている分だけ、歩留まりは上がるが、パッケージングはより複雑となる。コスト面でも、Intelのクアッドコアと、よくて5分5分程度となる。
□関連記事
【10月13日】【海外】AMDがクアッドコアCPU「Barcelona」の詳細を発表
http://pc.watch.impress.co.jp/docs/2006/1013/kaigai311.htm
【5月22日】【海外】AMDがK8コアの浮動小数点演算ユニットを2倍に
http://pc.watch.impress.co.jp/docs/2006/0522/kaigai272.htm
【5月3日】【海外】クアッドコアCPUを2段階投入するAMDのロードマップ
http://pc.watch.impress.co.jp/docs/2006/0503/kaigai267.htm
(2006年10月16日)
[Reported by 後藤 弘茂(Hiroshige Goto)]
【PC Watchホームページ】
PC Watch編集部 [email protected] ご質問に対して、個別にご回答はいたしません
Copyright (c) 2006 Impress Watch Corporation, an Impress Group company. All rights reserved.