 |


■後藤弘茂のWeekly海外ニュース■AMDがクアッドコアCPU「Barcelona」の詳細を発表 |
●クアッドコアダイ写真も公開
AMDは、ネイティブクアッドコアCPU「Barcelona(バルセロナ)」の詳細を明らかにした。これは、「K8 Revision H(Rev. H)」または「K8L」と呼ばれていたCPUコアをベースにしたクアッドコアCPUで、「Deerhound(ディアハウンド)」と呼ばれいていたクアッドコアと同じものだ。AMDのコードネームやリビジョン名はしばしば変わる。
今回、AMDは、San Joseで10月9~11日に開催された「Fall Microprocessor Forum」で、Barcelonaについて、より突っ込んだ技術内容を説明した。AMDは、今年(2006年)5月の「Spring Processor Forum(SPF)」で同CPUの大まかな技術内容を発表しており、今回の発表はそのフォローアップとなっている。
また、AMDは、Barcelonaのダイ(半導体本体)写真も公開した。SPFでは大まかなダイレイアウトの写真だけだったのが、今回はダイ写真となり、製品化に一歩近づいたことを印象づけた。下が今回公開されたBarcelonaのダイの写真と、5月に公開されたレイアウト図だ。
 |
| Barcelonaのダイ写真 ※別ウィンドウで開きます |
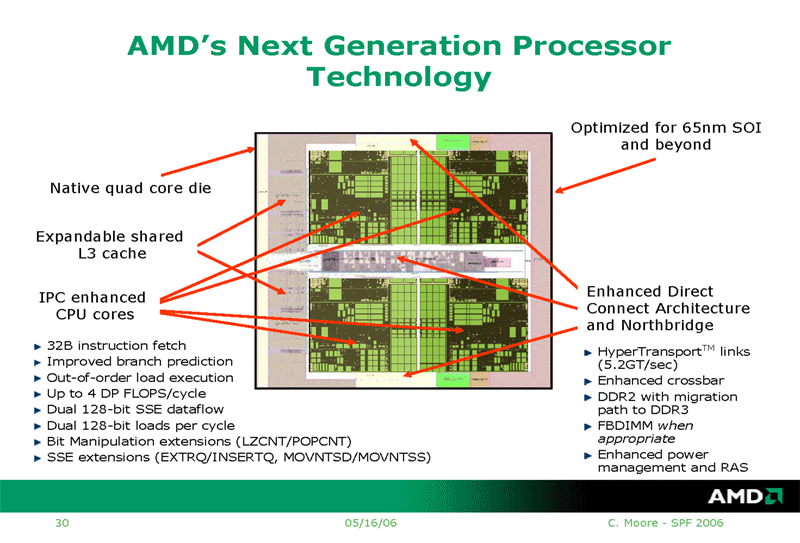 |
| AMD's Next Generation Processor ※別ウィンドウで開きます PDF版はこちら |
ダイ写真を見ると、CPUコアの内部のレイアウトは、前回公開されたものからほとんど変わっていないことがわかる。
ちなみに、AMDはその2週間前にBarcelonaのウェハも公開している。マイクロアーキテクチャを更新したCPUの場合、バリデーションに1年程度かけるのが一般的なので、来年(2007年)後半と言われるBarcelonaの開発状況は、スケジュール的に、ちょうど合うことになる。
Barcelonaは、65nm SOI(silicon-on-insulater)プロセスで製造されるクアッドコアで、2007年の投入が予定されている。K8 Rev. FのOpteronから採用された「Socket F(1207pin)」互換で、TDP(Thermal Design Power:熱設計消費電力)もSocket Fプロセッサと同レンジとなる。つまり、最大120WのTDP枠内で提供され、メインストリーム向け95W TDP版も提供されると見られる。デュアルコアから、同じソケット同じTDPで載せ替えが可能ということになる。また、AMDのデスクトップ向けクアッドコアは、Barcelonaと同コアをベースにすると見られる。
Barcelonaの技術上のポイントは6つ。
○SSE演算の強化
○CPUコアのIPC(instruction per cycle)の向上
○DRAMメモリの実効帯域の拡張
○L3キャッシュの搭載
○仮想化のパフォーマンスアップ
○電力管理の強化
これらの拡張の一部は、ダイ上でも見て取れる。下が推定されるBarcelonaの各ブロックをダイ写真に加えた図と、AMDの現行のK8 Rev. Fと、2007年に投入されるBarcelonaとMobileコアのそれぞれのCPUコア部分を比較した図だ。Barcelonaでは明瞭に、CPUコアのSSE/浮動小数点演算ユニット部分と、命令フェッチ回りのユニットが大型化している。
 |
| Barcelonaダイブロック ※別ウィンドウで開きます PDF版はこちら |
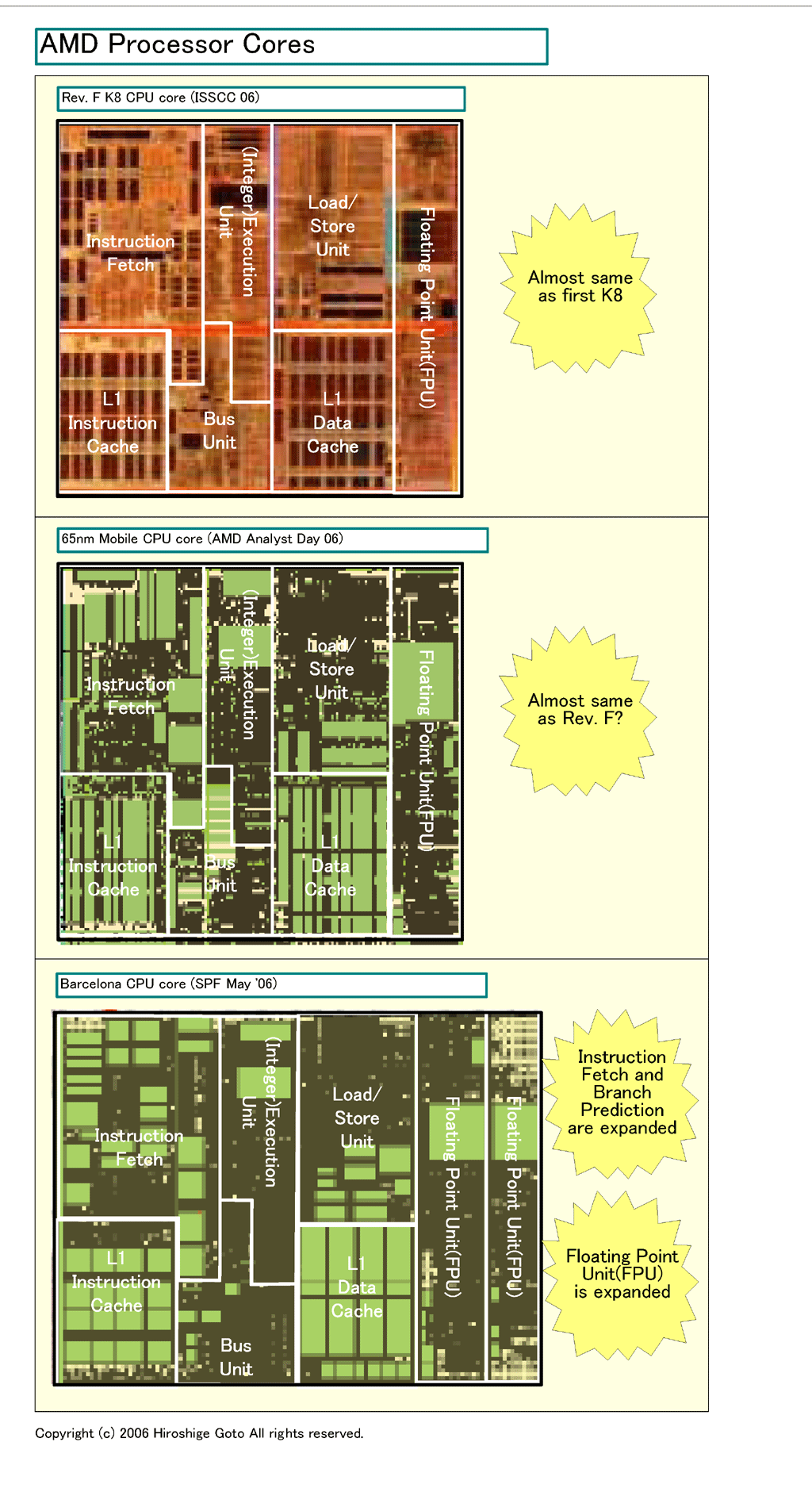 |
| AMD Processor Cores ※別ウィンドウで開きます PDF版はこちら |
●命令フェッチの拡張はSSE命令に最適化したため
以前レポートしたように、Barcelonaの世代からAMDはCPUコアのSIMD(Single Instruction, Multiple Data)演算性能を強化する。SSE/浮動小数点演算ユニットを2倍に強化、128bitのSIMD演算を1サイクルで行なえるようにする。これは、IntelがCore Microarchitecture(Core MA)で行なったものと基本的には同じ拡張だ。
現在は、SSE系の128bit SIMD演算は、64bitずつ下位と上位に分けて2パスで演算している。演算ユニットを倍増することで128bit分を1サイクルで実行できるようにする。浮動小数点と整数の両方のSIMD演算の性能を2倍にする。K8のパイプラインでは、SSE/浮動小数点演算パイプにはSIMD演算系ユニットが2つある。加算ユニットFADDと乗算ユニットFMULで、それぞれが128bit SIMD演算を平行して行なうことができる。その他にFMISCと呼ぶストアパイプがある。Barcelonaでは、新たにSSE MOV(ムーブ)命令がこのストアパイプで実行できるようになった。そのため、加算と乗算と平行してSSE MOVを実行できる。
ただし、演算パスの帯域を2倍に増やしただけでは、命令とデータのデリバリがボトルネックになってしまう。そこで、AMDは命令フェッチとデータロードを改良したという。
AMDの現行のCPUの、L1命令キャッシュからの命令フェッチ帯域は16byte/cycle。16byteの命令ウインドウから、命令を切り出して3並列のデコーダに送っている。Barcelonaでは、これが32byte/cycleへと拡張される。L1→フェッチユニットの帯域が32byte(256bit)幅になったわけだ。
 |
| Ben Sander氏 |
「命令フェッチ帯域をSSE命令をターゲットに最適化した。x86アーキテクチャに拡張された命令では、プリフィックスがついて命令長が長くなる。3命令/サイクルでSSE 128エンジンに命令を供給するために、16byteの命令フェッチでは十分ではないと判断した。そのため、実行エンジンを2倍にするのと同時に、命令フェッチ帯域も2倍にした」
この部分は、IntelのCore MAとの大きな違いだ。Core MAの現在の実装では、L1→フェッチユニットの帯域は16byte幅のままとなっている。
●2倍のエンジンにデータをフィードする仕組み
以前にもレポートしたが、BarcelonaではL1データキャッシュからのデータロード帯域も同じように強化した。従来のAMD CPUは、L1データキャッシュから64bitのロードを2並列で行なうことができた。つまり、64bit/cycleのロードが2倍で、128bit/cycleの帯域を持つ。Barcelonaでは、ここも2倍に拡張された。128bit/cycleのロードを2並列で行なうことができる。
2ロードを平行できるようにしているのは、データがアラインメントされていない場合、1アクセスが2つのデータアクセスオペレーションを生じる場合があるからだとAMDは説明する。アライメントされていないデータが連続する場合でも、SSEパイプをフルに回すために2ロードが必要になるとしている。
もっとも、BarcelonaではSSEロードに、アラインされていないデータにアクセスするSSE Unaligned Load-Executeモードも加えられている。このモードでは、アライメントされていないデータへのアクセス時に、2ロードを生成する必要を削減するという。これらの機能は、アライメントされていないデータが多いメディアアプリケーション向けの、PCを主なターゲットとした機能拡張だという。
L1キャッシュから実行コアへの帯域を2倍にしたことに合わせて、L2とノースブリッジブロックとの間の帯域も従来の2倍の128bit幅に拡張される。
また、SSE/浮動小数点スケジューラも拡張された。K8では、SSE/浮動小数点専用のスケジューラがあり、従来は64bitのオペレーション(OPs)を36個ハンドルすることができた。演算コアの拡張に合わせてスケジューラは128bit OPsを36個ハンドルできるようになった。つまり、スケジューラがハンドルできるOPsの数は変わらないが、OPsを64bitに分割しなくて済むようになったので、実質2倍の処理をハンドルできるようになるわけだ。下がSSE/浮動小数点演算系の拡張の一覧だ。
 |
| 現行品とBarcelonaとのSSE128機能比較 ※別ウィンドウで開きます PDF版はこちら |
●スタックポインタの操作を行なう専用ハードを搭載
Barcelonaでは、SSE/浮動小数点演算の強化に加えて、整数演算系のIPCを上げるための拡張も多く加えられる。SSE/浮動小数点以外の命令も、より多く並列に実行できるようになる。IPCの向上で、特に目立つ強化点は以下の5つだ。
○分岐予測(branch prediction)の強化
○32byteの命令フェッチ
○サイドバンドスタックオプティマイザ
○アウトオブオーダロード実行
○TLB(Translation Lookaside Buffer)最適化
 |
| CPU Core IPC Enhancements ※別ウィンドウで開きます PDF版はこちら |
分岐予測では、インダクレクトプレディクタ(間接分岐予測)が加わり、専用の512エントリが設けられる。リターンアドレススタックが24へと倍増され、分岐ヒストリビットも増やされる。命令フェッチはすでに触れたように32byteに増やされる。これはSSE128のためだが、整数演算コードでも利点があるという。
 |
| 命令フェッチの有効性 ※別ウィンドウで開きます PDF版はこちら |
サイドバンドスタックオプティマイザ(Sideband Stack Optimizer)は、今回明らかになった機能だ。x86の場合、データを一時スタックに入れるためのスタック操作が多く生じる。この場合、データを格納するだけでなく、スタックポインタを操作する必要がある。そのため、スタック操作のPUSH/POPオペレーションは、従来のCPUでは余計なオペレーションを発生させて、CPU内部での負荷が大きかった。
「(スタックに格納する)PUSH命令の場合、実際には2つのOPsを生成していた。ストアとスタックポインタ調整の2つのOPsだ。そこで、我々はスタックポインタの操作のための専用のハードウェアを加えた。それによって、スタックポインタの操作のOPsを通常の実行ユニットで実行する必要がなくなった。また、スタックポインタ操作を並列に実行できるようになった」とSander氏は語る。
 |
| スタックポイント操作の強化 ※別ウィンドウで開きます PDF版はこちら |
スタックポインタの操作については、専用ユニットで行なってしまうわけだ。この機能はIntelがPentium M(Banias:バニアス)で採用したDedicated Stack Managerと基本的には同じものだ。Intelは、これによって実行ユニットに送るOPsを5%減らすことができたと説明していた。同じことがBarcelonaでも期待できることになる。IntelのアイデアをAMDも採用した格好だが、これは、x86の弱点を克服しようとすると、同じようなアプローチを取らざるを得ないことも意味している。
●物理メモリは256TBまでアクセス可能に
アウトオブオーダ型のロード実行は、ロード命令を、他のロード命令やストア命令をバイパスして投機的に実行できるようにする機能。IntelがCore MAで実装した「Memory Disambiguation(メモリディスアンビギュエイション)」と類似の機能だ。L1データキャッシュをミスするとロードレイテンシが長いため、この機能でロード命令を従来より早い段階で実行できればレイテンシの短縮に効果がある。
 |
| アウトオブオーダ型のロード命令 ※別ウィンドウで開きます PDF版はこちら |
AMDはメモリのTLB(Translation Lookaside Buffer)も強化した。まず、物理メモリアドレスを従来の40bitから48bitへと拡張した。これによって、アクセスできるメモリ量が1TB(TeraByte)から256TBへと増えた。また、メモリページのサイズは従来の4KB、 2MBの他に、1GBが新たに加わった。これはデータベースアプリケーションからの要求によるものだという。
仮想アドレスから物理アドレスへのアドレス変換キャッシュであるTLB自体も、より大きくなった。これは、仮想化の機能拡張と、データベースやトランザクションなどのアプリケーションのためだという。
 |
| TBLの強化 ※別ウィンドウで開きます PDF版はこちら |
BarcelonaのSSE演算とIPC(instruction per cycle)の強化を概観すると目立つのは、まずIntelのCore MAとの共通性。かなりアプローチが似た点がある。x86 CPUの性能強化では道筋が似てくる。
もう1つ目につくのは、クライアント向けの機能拡張と、サーバーやハイパフォーマンスコンピューティング向けの機能拡張の両方が行なわれている点。特に、メモリ回りの拡張は、大型のデータセットを扱い、仮想化が重要となるサーバーを意識した部分が多い。K8アーキテクチャ自身、もともとDECのAlphaのアーキテクチャの流れを引くだけに、サーバーに適した要素が多かった。Barcelonaでも、そうした基本的な方向は変わっていない。
□関連記事
【10月10日】【海外】AMDがK8コアの浮動小数点演算ユニットを2倍に
http://pc.watch.impress.co.jp/docs/2006/0522/kaigai272.htm
【5月19日】【SPF】クアッドコアOpteronの詳細
http://pc.watch.impress.co.jp/docs/2006/0519/spf03.htm
(2006年10月13日)
[Reported by 後藤 弘茂(Hiroshige Goto)]
【PC Watchホームページ】
PC Watch編集部 pc-watch-info@impress.co.jp ご質問に対して、個別にご回答はいたしません
Copyright (c) 2006 Impress Watch Corporation, an Impress Group company. All rights reserved.