 |


■後藤弘茂のWeekly海外ニュース■AMDがK8コアの浮動小数点演算ユニットを2倍に
|
●明らかになったRev. G以降のAMD CPUコア
AMDは先週5月15~17日に開催されたプロセッサ関連カンファレンス「Spring Processor Forum」で、クアッドコアK8のコンセプトレイアウトと基本フィーチャを公表した。カンファレンス自体は大原雄介氏がレポートしている通りで、ここでは、資料上からわかるクアッドコアK8と新世代のK8コア群について分析してみたい。
今回の発表によって、ようやく、これまで不明瞭だった65nm世代の最初のK8「Rev. G(Revision G)」とK8のリフレッシュである「New Core」の関係が、ある程度見えてきた。クアッドコアK8の図にはめ込まれたCPUコアは、Rev. G世代のCPUコアとは明確に異なり、拡張されている。おそらく、AMDがNew Coreと呼ぶ次世代コアに搭載されるCPUコアの正体は、K8マイクロアーキテクチャ(内部実装アーキテクチャ)をRev. F/Gを経て段階的に拡張するものだ。最終的に現行のRev. EまでのK8とは、かなり別物へと進化すると見られる。言ってみれば“K8+α”で、「Rev. H」や「K8L」と呼ばれていたCPUコアと同一だと見られる。
これまでの情報では、AMDのクアッドコアサーバーCPUは2007年の「Deerhound(ディアハウンド)」と2008年の「Zamora(ザモラ)」の2ステップとされていた。今回発表されたクアッドコアは、Deerhoundになるはずだが、細部が異なっている。Deerhoundは、Rev. F世代のデュアルコアOpteronと同じインフラ(チップセット/マザーボード/ソケット)に載るはずだ。メモリはDDR2で、HyperTransport 1とされている。ところが、今回のクアッドはHyperTransport 3世代を実装することになっている。
ただし、HyperTransport 1との互換性も備えるとされているため、最初に登場するDeerhoundではHyperTransport 1のままで、その後HyperTransport 3がイネーブル(有効)される可能性もある。
●浮動小数点演算パフォーマンスが理論値2倍に
今回の発表では、クアッドコアK8ではCPUコアのマイクロアーキテクチャ自体が拡張されていることが明らかにされた。中でも目立つのは浮動小数点演算の理論値パフォーマンスが2倍(クロック当たり)になることだ。
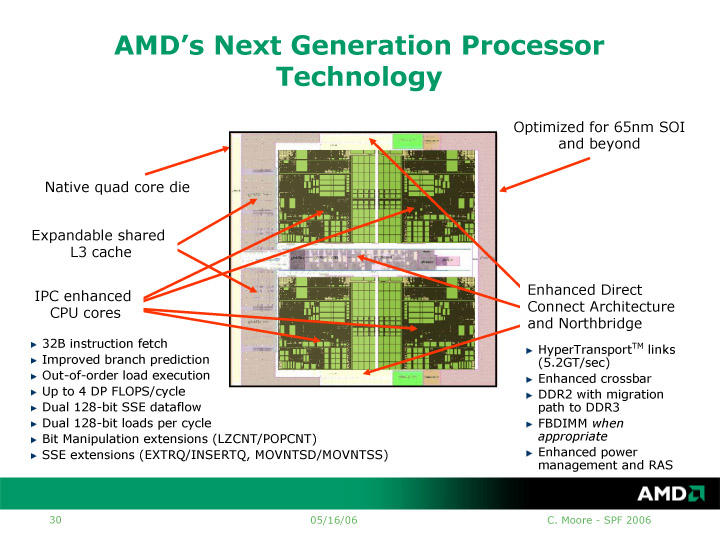 |
| クアッドコアOpteronの概要 (別ウィンドウで開きます) PDF版はこちら |
プレゼンテーションによると、1コアにつき最大4 FLOPS/Cycleのピークスループットで倍精度の浮動小数点演算が可能となっている。1サイクル当たりの演算スループットは、それまでのK8の2倍になる。これは、IntelのCore Microarchitectureと同じで、浮動小数点演算性能の強化はトレンドであることがわかる。ちなみに、クアッドコアK8では、128bitのデータロードも2 Load/Cycleと2倍になり、128bit SSEデータフローもデュアルになっている。これは演算性能の倍増に合わせたためと見られる。
命令フェッチも拡張される。K8では命令フェッチは、L1から16byte幅だった。それに対して、クアッドK8のコアでは32byte幅でフェッチする。つまり、単純計算で2倍の長さの命令フェッチを行なうことができるわけだ。もちろん、フェッチの次の命令デコードで変換できる以上の命令数は実行できないが、上位のフェッチ幅を広げることでデコーダによどみなく命令を送ることができるようになる。
汎用プロセッシングで、パフォーマンス向上の重要要素となる分岐予測も拡張される。ただし、拡張の詳細はわからない。このほか、out-of-order(アウトオブオーダ)のロード実行も可能になる。これが、メモリへデータを書き込むストア操作の前に、メモリからデータを読み出すロード操作をスケジュールできることを意味するなら、ストアとロードのデータ依存関係をチェックする仕組みも持つことになる。同じような仕組みは、Intelも、Core Microarchitecture(Merom)から採用する。この他、レポートされているように命令セットの若干の拡張も行なわれる。
こうして概観すると、この世代のAMD CPUコアの拡張は、フォーカスしているポイントがIntelとある程度似通っていることがわかる。CPUのプロセッシング効率をアップし、浮動小数点演算パフォーマンスを特に強化する。想定していたより大幅な拡張の気配が強く、Intelで言えばPentium M世代(Banias:バニアス/Yonah:ヨナ系)からCore Microarchitecture世代(Merom:メロン系)への拡張にある程度似ている。
●AMD CPUコアの今後3世代での変化
AMDによる、クアッドコアのCPUコアアーキテクチャのフィーチャ公開によって、ようやくAMDの2008年までのCPU拡張の穴が埋まってきた。
以前のコラムで、AMDが2007年にRev. GまでのCPUコア拡張を準備していることをレポートした。Rev. Gと見られる65nm K8とRev. Fでは、CPUコアのダイ(半導体本体)のレイアウトが明確に違っており、拡張は明白だった。
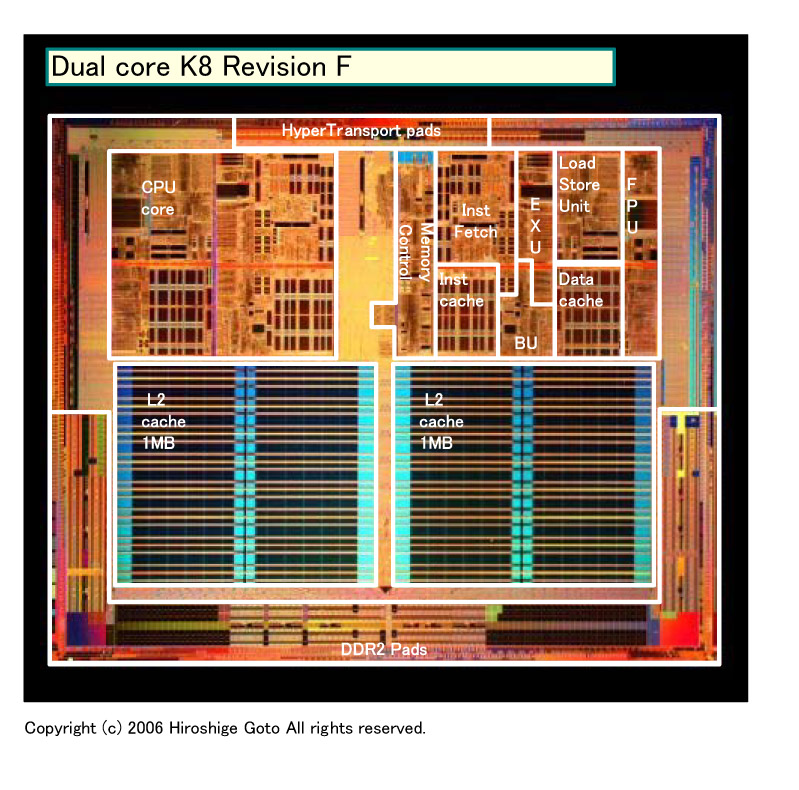 |
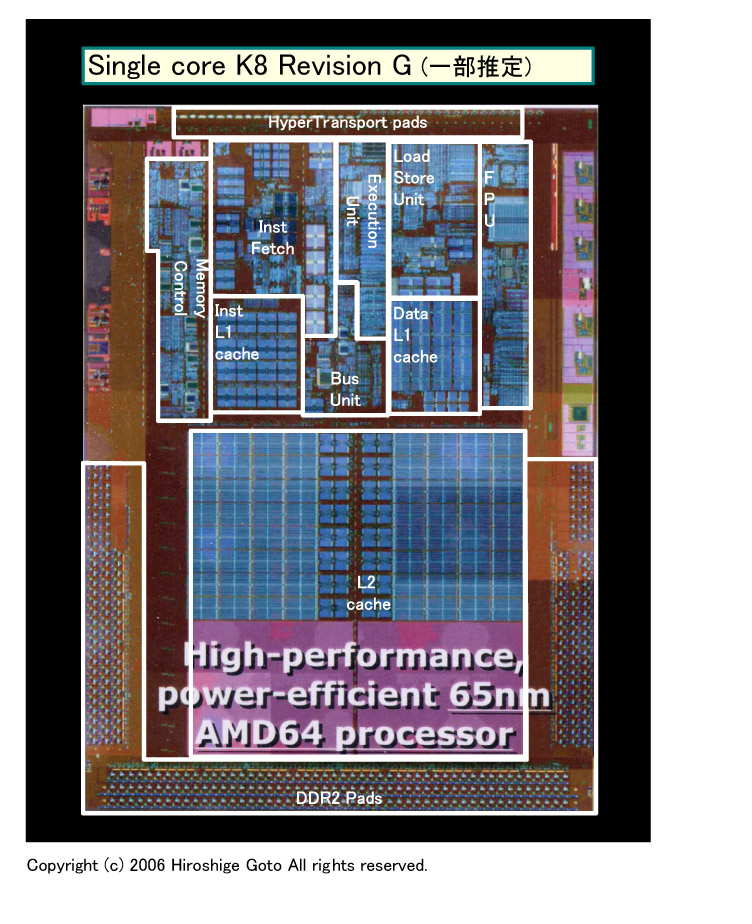 |
| Rev. Fのダイ (別ウィンドウで開きます) PDF版はこちら |
Rev. Gのダイ (別ウィンドウで開きます) PDF版はこちら |
しかし、その先の世代については情報が交錯していた。
まず、AMDがRev. Gの次のCPUコアRev. Hで、浮動小数点演算パフォーマンスが2倍になると説明していたことがわかった。その一方で、AMDが2007年末から2008年前半に投入するNew Core世代のモバイルCPUが、Rev. Gベースになるという情報もあった。Rev. Gは、浮動小数点演算ユニットが大きく拡張されているように見えないため、「Rev. H = New CoreのCPUコア」という部分も含めて謎が残っていた。もちろん、これらの情報が古い、あるいは間違えている可能性があるが、確証は掴めなかった。
ところが、今回のクアッドコアのCPUコアのダイレイアウトを見ると、この疑問がかなり解ける。このCPUコアは、Rev. Gと基本部分は共通だが、浮動小数点演算ユニット(FPU)部分だけが拡張されているように見えるからだ。これがRev. H世代CPUコアとすると、かなりの疑問が解ける。
これまでAMDが発表した今後3世代のK8 CPUコアを比較したのが下の図だ。一番上は、2月の半導体学会「ISSCC 06」での発表資料をベースに、ダイ写真に各ユニットブロックの区分を書き加えたRev. F CPUコア。真ん中は、4月のAMDの日本でのブリーフィングの資料に、推定されるユニットブロック区分を加えた65nm CPUコア。これはRev. Gと推定される。一番下は、先週のSPFのクアッドコアの資料に、推定されるユニットブロック区分を加えたもの。一応、便宜的にRev. Hとした。
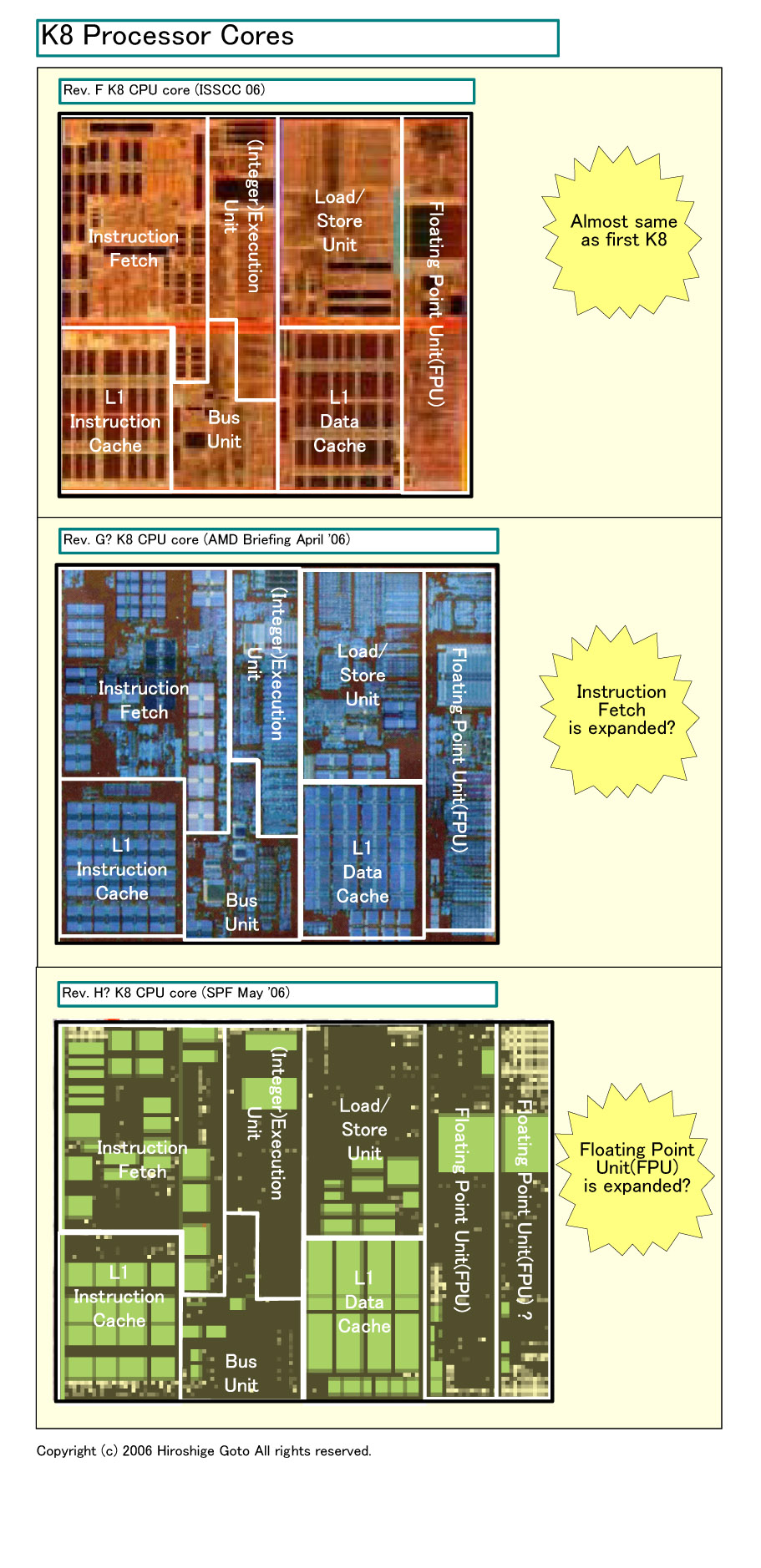 |
| Rev. F/G/Hの比較 (別ウィンドウで開きます) PDF版はこちら |
以前レポートした通り、Rev. FからRev. Gで、K8はダイレイアウトが初めて大きく変わった。ダイを見ると、命令フェッチ&デコーダが拡張されていることが明瞭にわかる。ロード/ストアユニットも、内部の配置が変わったように見えた。しかし、浮動小数点演算ユニットについては、Rev. GとRev. Fを比較しても、相対的に同程度のサイズにしか見えなかった。ユニット面積(=トランジスタ)を増やさないなら、性能を飛躍させることは難しい。
●浮動小数点演算パイプを1本追加した?
ところがクアッドのCPUコア(Rev. H? )を見ると、浮動小数点演算ユニット(FPU)の隣に、1個ユニットが加わっている。これが追加の浮動小数点演算ユニットだとすれば、同ユニットのサイズは2倍とは行かないまでも、かなり面積が拡張されることになる。
現在のx86系CPUは、64bit幅の浮動小数点演算ユニットで128bit SIMD演算を実行している。つまり、従来の浮動小数点演算パイプは64bitということだ。もし、AMDがそこに64bitの浮動小数点演算パイプをもう1本加えて、128bit SIMD演算を1サイクルスループットでできるようにしたとすれば、浮動小数点演算パフォーマンスが2倍になるというのも納得できる。
これは、ちょうどIntelのPrescott以降のNetBurstアーキテクチャが、32bit整数演算ユニットを2パイプにして64bit演算を可能にしたのと似た実装だ。ちなみに、IntelのCore Microarchitectureも、128bit SIMD演算ユニット実装となっている(NetBurstとPentium Mは64bit SIMD実装)
面白いのは、Rev. Hと見られるコアは、浮動小数点演算ユニット部分以外の部分の大まかなレイアウトが、Rev. Gに似ているように見えることだ。これだけラフな図では確信を持って言うことはできないが、ブロックが大きく変わっているようには見えない。ここから推定できるのは、浮動小数点演算パイプ以外の拡張は、Rev. Gですでに実装している可能性だ。その上で浮動小数点演算ユニットも拡張できるように設計したのがRev. Gなのかもしれない。クアッドコアのスライドで説明された、命令フェッチや分岐予測といった拡張は、いずれもRev. Gで大型化している命令フェッチ&デコードユニット部分に含まれる。
だとすれば、Rev. GからRev. Hへは比較的容易に拡張できることになる。つまり、Rev. Hは、Rev. G+追加浮動小数点演算ユニットという構成かもしれない。SPFのプレゼンテーションを見ると、サーバー&ワークステーションは、Rev. GをスキップしてRev. Hコアへと移ると考えられる。これは、AMDが、過去数年のプレゼンテーションで、CPUのコアブロックのモジュラー化を強調していることとも符合する。
もし、Rev. GからRev. Hへと比較的簡単に拡張できるとすれば、New Core世代でCPUコアにバリエーションが存在したとしても不思議ではない。例えば、モバイル向けには浮動小数点演算は拡張しないRev. Gコアで、サーバーやデスクトップはRev. Hコアといった組み合わせもできそうだ。そう考えれば、先ほど説明した矛盾した情報の説明もつく。
ここまでの流れを整理すると、AMDのCPUコアアーキテクチャは3段階の発展を遂げると推測される。Rev. Fで仮想化などダイへのインパクトが小さい拡張。Rev. Gで命令フェッチやロード/ストアなどの拡張。Rev. Hで浮動小数点演算パフォーマンスにフォーカスした拡張といったステップという推理だ。もちろん、これはダイから推測される拡張で、実際に拡張された機能がイネーブルされるかどうかは別のストーリーだ。
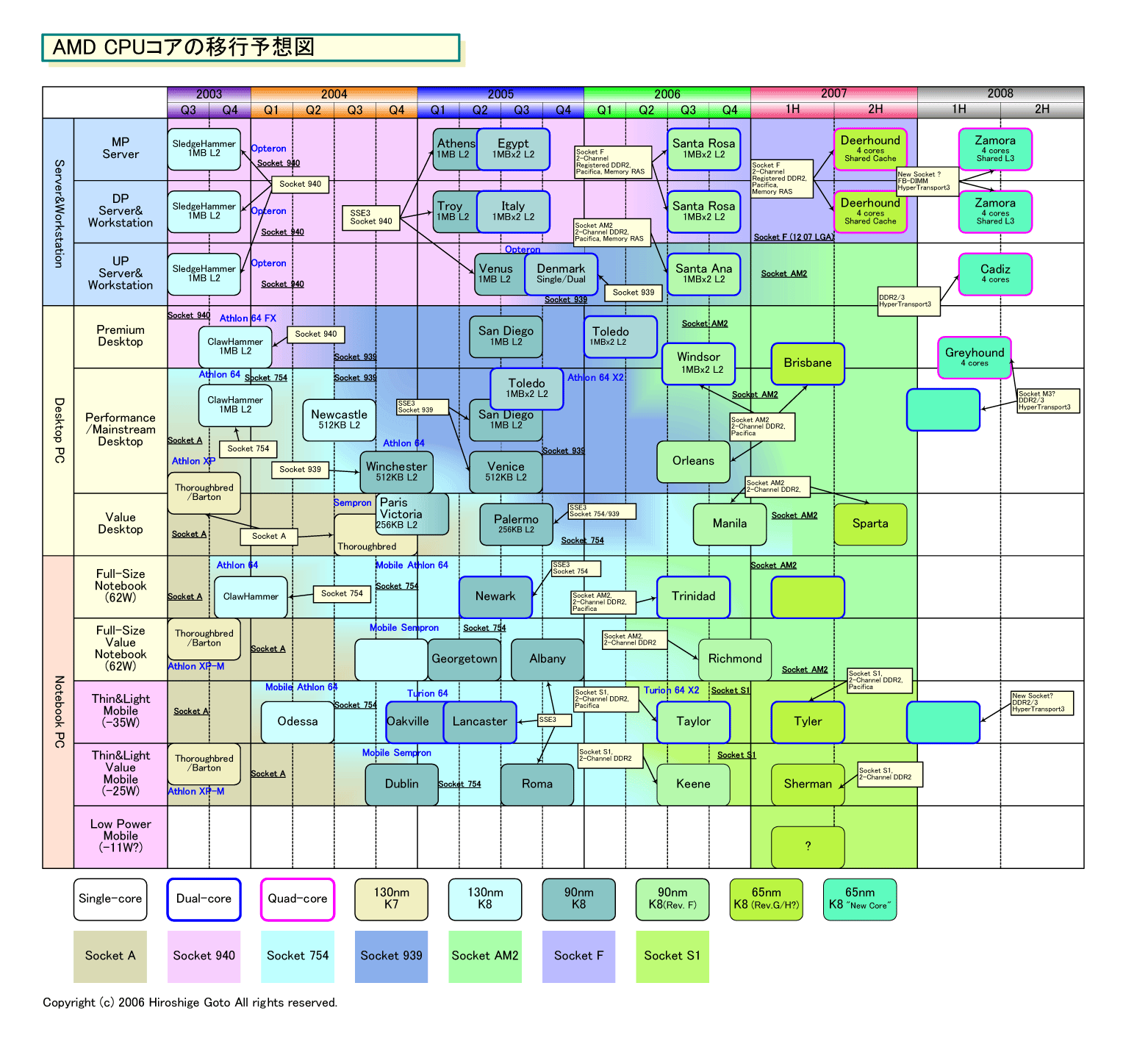 |
| AMD CPUコアの移行予想図 (別ウィンドウで開きます) PDF版はこちら |
●クアッドコアは512KBのL2キャッシュと2MBの共有L3の構成か
この他、クアッドのレイアウトからは、いくつかの事実がわかる。
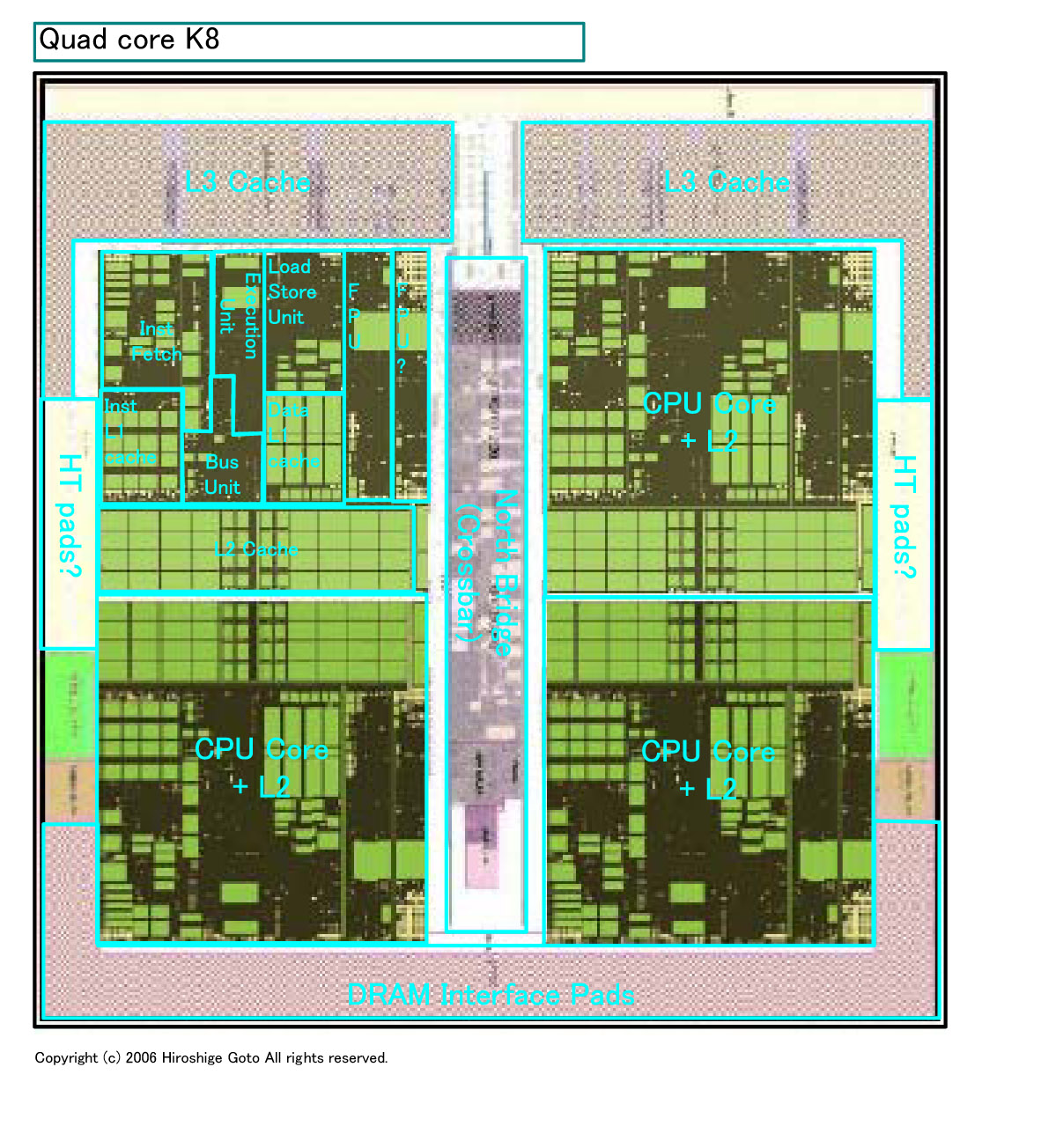 |
| クアッドコアOpteronのレイアウト (別ウィンドウで開きます) PDF版はこちら |
クアッドコアの図にあるCPUコアのL2キャッシュは、各コア512KBずつに見える。左右が鏡像の配置、つまりCPUコアのレイアウトは上下のコアで裏返しとなっている。4コアとL3キャッシュ、各I/Oを接続すると見られるノースブリッジブロックは、CPUコアに匹敵するようなサイズに巨大化している。この世代も引き続きクロスバーを取る。
DRAMインターフェイスは現在と同様にCPUに統合で、DDR3へのマイグレーションを考慮したDDR2となっている。次のZamoraではFB-DIMMサポートだと言われている。パッドはCPUダイの1.x辺を占めている。共有L3キャッシュはDRAMインターフェイスと逆サイドに配置されている。これがDeerhoundだとするとL3は2MBのはずなので、面積とほぼ合致する。
SPFでのAMDのChuck Moore氏(AMD Senior Fellow)のプレゼンテーションは、同氏が昨年(2005年)11月のプロセッサアーキテクチャカンファレンス「Micro-38」で行なったプレゼンテーション「Chip Multi-Processors: Now and into the Future」の続きとなっている。プレゼンテーション自体の差分は、クアッドコアの図以外はそれほど多くはない。同氏は、ダイジェストを昨年6月のAMD Analyst Dayにも行なっている。
そして、今回の発表で、下のスライドの4世代に分けたマルチコア実装ビジョンのうちAMDはGen-1からGen-2へと移ろうとしていることが見えてきた(Gen-0はIntelのPentium Dを示している)。次のステップGen-3では、ランタイムアダプティブフレキシビリティという意味深な項目もあり、AMDのCPUアーキテクチャ拡張がまだまだ続くことを示している。
 |
| SPFで発表されたキーノート (別ウィンドウで開きます) PDF版はこちら |
□関連記事
【5月19日】【SPF】クアッドコアOpteronの詳細
http://pc.watch.impress.co.jp/docs/2006/0519/spf03.htm
(2006年5月22日)
[Reported by 後藤 弘茂(Hiroshige Goto)]
【PC Watchホームページ】
PC Watch編集部 pc-watch-info@impress.co.jp ご質問に対して、個別にご回答はいたしません
Copyright (c) 2006 Impress Watch Corporation, an Impress Group company. All rights reserved.