
|
Spring Processor Forum 2006レポート
クアッドコアOpteronの詳細
 |
会期:5月15日~17日(現地時間)
会場:米カリフォルニア州サンノゼ
DoubleTree Hotel
SPF2006初日の基調講演では、AMDのChuck Moore氏による“Redefining Performance Through System Balance”というプレゼンテーションが行なわれた。
 |
 |
| AMD Senior FellowのChuck Moore氏 | 【写真02】こちらと比較すると、微妙に違いが見られるプレゼンテーション。ちなみにこちらの最後にある空母のプレゼンテーションは今回も登場した |
{kind=link}
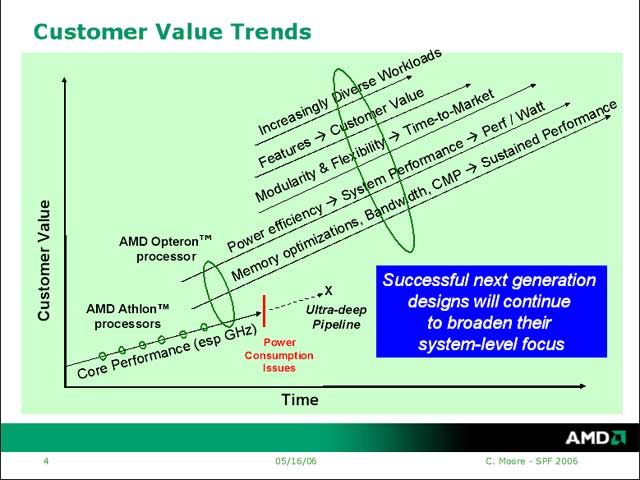
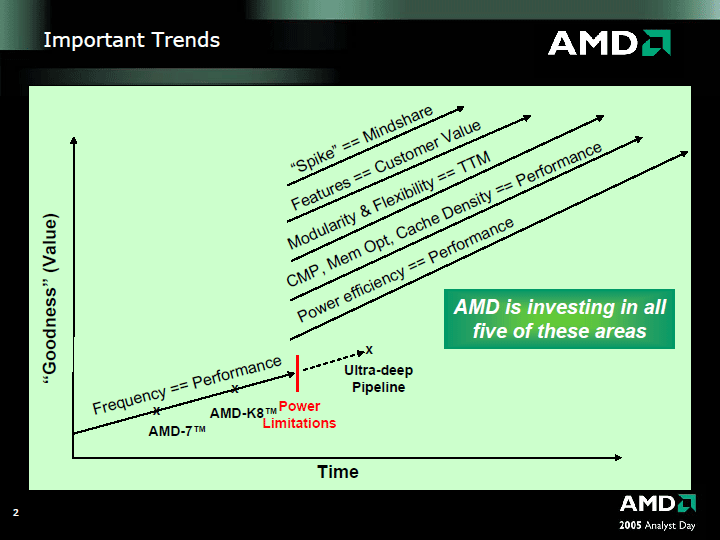
プレゼンテーションの内容はというと、同氏が2005年6月のAnalyst Dayで発表した内容を下敷きに、もう少し詳細を付け加えた話になっている(写真02)。つまり単に周波数を上げるのではなく、CMPを始めとするさまざまな方法論をとることで、Customer Valueを付加してゆくという話だ。Sustained Performance(持続可能な性能)を上げる、つまりピーク性能は必ずしも追う必要はない、という方向性が打ち出されたのはちょっと目新しい。もっともこのSustained Performanceの詳細に関してはまだ議論の余地があるのか、明確なポイントは示されなかった。
さて、目新しい点をいくつか紹介すると、
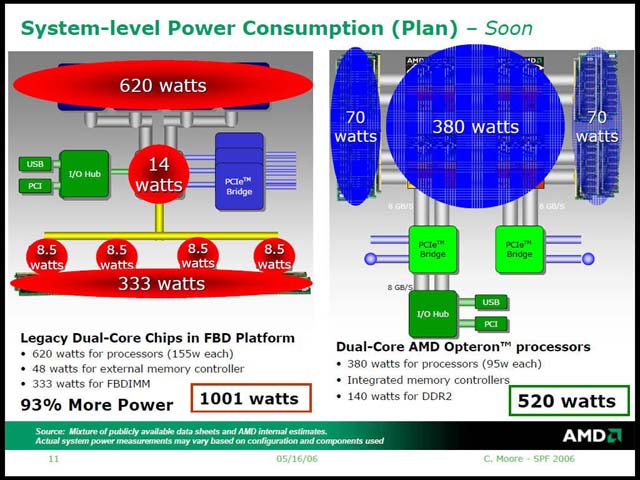
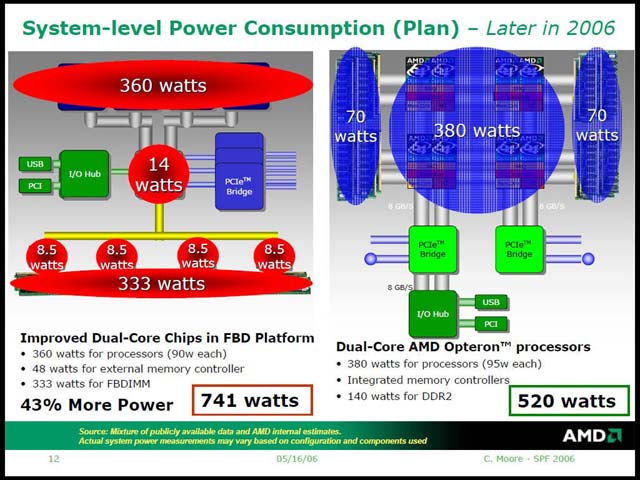
・Dempsey+Blackford vs Opteron(写真03)およびWoodcrest+Blackford vs Opteron(写真04)の消費電力比較が掲載された。
・次世代コアの特徴がいくつか示された(写真05、06)
 |
 |
| 【写真03】FB-DIMMの333Wとは、FB-DIMM 1枚あたり10.4W(AHBが6W、メモリが4.4W)で、これが32枚で333Wという計算である。一方Opteronは4Pシステムで、1Pあたり8枚でやはり32枚という計算になっている | 【写真04】Woodcrestには2Pと4Pの両方の構成があるが、今回の試算の前提になっているのは2Pのもの |
 |
 |
| 【写真05】ちなみに従来のOpteron(というかAMD64)は、仮想アドレスは48bitだったが物理アドレスは40bitだった | 【写真06】L3の詳細は今回一切なし。ただダイレイアウトから見て、CPUコアから直接という形ではなく、Interconnectの下にぶら下がる形になるのは明白。個人的にはこのL3、Z-RAMではないかと思うのだが |
あたりだろうか。以下、もう少し詳細を説明したい。
まず、既に一部で展示なども始まったDempsey+Blackfordと、Dual Core Opteronの消費電力比較においては、CPUもさることながらFB-DIMMの消費電力が非常に大きいため、システム全体ではほぼ倍近くまで差が広がることが示された。
ほかに、FB-DIMM用のメモリコントローラが8.5Wずつ消費すると見込んでおり、この結果メモリシステムだけで367W vs 140Wと大きな差が出るとしている。これがWoodcrest世代になると、CPUに関しては大幅な省電力化が可能としつつも、チップセットやメモリサブシステムには違いが無いので、システムトータルではやはりOpteronの構成の方が省電力、というメッセージである。
このメッセージはちょっと面白い。AMDは最近「ワット性能」という言葉を盛んに使っており、問題は絶対的な性能ではなく性能/消費電力比であるというメッセージを発している。既に知られているとおり、Woodcrest世代では従来のNetburstベースのものから大幅に性能を上げてくる事がIDFなどでも予告されており、プロセッサ単体の性能/消費電力比では圧勝しているOpteronも、Woodcrest世代では逆転されてもおかしくないほどだ。
しかしながら、システム全体での消費電力と考えた場合、この数字に従えば741÷520=1.425で42.5%ほどOpteron側にマージンがあることになる。つまり、性能面が40%程度の差に治まるなら、当面はそれで良しとするつもりなのかもしれない。まぁこの時期にはRev. FのOpteronが投入済みのはずだから、性能に関しては現時点ではなんともいえないのだが。
ついで次世代、つまりRev. Gのコアの詳細と思しきものも示された。HypertTransport Linkに関しては既に3.0のSpecificationが公開済みで、これをそのまま搭載するほか、On-ChipのL3キャッシュの搭載、およびコアのIPC向上も示された。FPUが2倍の性能になる、とされているのも興味深いところだ。またサーバー向けの話では、仮想アドレスと物理アドレスがどちらも48bitに揃えられ、しかも1GBのページサイズがサポートされたのは非常に判りやすい。またメモリコントローラとして、DDR2/3とFB-DIMM1/FB-DIMM2が全てサポートされる形になるという。
ただこれに関しては、「同時にサポートされる」(つまり1つのCPUに全てのインターフェースが含まれており、ピンへの信号などでConfigurationで切り替えられる)のか、それともRevisionが分かれるのかは明確にされなかった。思うに、OpteronがFB-DIMM1/2、Athlon系がDDR2/3といった形になるのかもしれない。
それと細かい話であるが、Memory MirroringやData poisoning、HyperTransport LinkのRetry Protocolなど、明らかに1レベル上のRAS機能を搭載することを明確にしたのは興味深い。Intelではこうした機能を持つのは今のところItanium系に限られており、対抗上Xeonにこれらの機能を搭載したら、いよいよItaniumとXeonの差別化が難しくなってしまう。このあたりをIntelがどう考えるかは興味あるところだ。
65nm世代のQuad Opteronに関しては、これがRev. Gのものなのか、その次に来る世代のものなのか、いまいちはっきりしない(話の流れからすればRev. Gのものだと思うのだが)が、命令フェッチ単位を倍増し、Branch predictionを強化するそうで、これは後藤氏の記事にあった「命令フェッチとデコーダ回りが強化されると推定される」に一致する。
またFPU/SSEユニットをおそらく倍増させているようで、今までよりも浮動小数点演算性能を上げる方向性を見せているが、そもそも今のOpteronでもXeon系とはかなり良い勝負をしている(動作周波数の違いもあって、圧勝には至っていないが)。従って理由の1つはSSE系命令でXeonを圧倒することだろうが、それよりもこの強化の目線はItaniumを向いているように思われる。HPCの分野などではまだまだItaniumの高い浮動小数点演算能力が重用されており、この分野で肩を並べるには、FPU/SSEユニットの強化が必要ということだろう。
最後のSSE Extentionに関して、前者の2つは名前からすると(それを何でSSEでやらなければいけないのかは不明だが)Queue操作命令っぽく、後者の2つはそれぞれNon-temporal store of Doubleword/Scalar single-precision floating-point valueと想像されるが、正直なところこれらの目的は良くわからない(プレゼンテーションでも軽く流されてしまった)。
ちょっと気になるのはIntelがMeromアーキテクチャで導入するといわれるMNI(Merom New Instruction:既にSSE4の方が通りが良いが)で、ひょっとするとこれはその先取りなのかもしれない。
□Spring Processor Forum2006のホームページ(英文)
http://www.instat.com/spf/06/
□関連記事
【5月3日】【海外】クアッドコアCPUを2段階投入するAMDのロードマップ
http://pc.watch.impress.co.jp/docs/2006/0503/kaigai267.htm
【4月24日】【海外】CPUコアの設計が一新される65nm版K8
http://pc.watch.impress.co.jp/docs/2006/0424/kaigai263.htm
(2006年5月19日)
[Reported by 大原雄介]
【PC Watchホームページ】
PC Watch編集部 pc-watch-info@impress.co.jp お問い合わせに対して、個別にご回答はいたしません。
Copyright (c)2006 Impress Watch Corporation, an Impress Group company. All rights reserved.