 |


■後藤弘茂のWeekly海外ニュース■SSE4命令とアクセラレータから見えるIntel CPUの方向性 |
●プロセス世代毎に命令セットを拡張
 |
| 新命令拡張について発表するPatrick P. Gelsinger氏 |
Intelは、45nmプロセス世代のCPU「Penryn(ペンリン)」から、新しい命令セット拡張「SSE4」とアクセラレータ「Application Targeted Accelerators」の実装をスタートする。
前回の記事で命令セット拡張の時期について不鮮明と書いたのは間違いで、多くの命令は、まずPenrynに実装される。残りはPenrynの後のCPUに実装されるとされており、「Nehalem(ネハーレン)」が該当すると見られる。Penrynは、Core MAを45nmプロセスに微細化するだけでなく、命令セットの拡張と、モノリシックなクアッドコア版を含むことになる。
命令セットの拡張は、大なり小なりマイクロアーキテクチャの拡張を伴う。そのため、Intelはプロセステクノロジが刷新され、より多くのトランジスタをCPUコアに割くことができるようになった時点で、命令セットを拡張している。プロセス世代と命令セット拡張は、連携して発展してきた。意外なことに、マイクロアーキテクチャの刷新とは、必ずしも連動していない。
具体的には、Intelの命令セット拡張の歴史は下の図のようになる。古くはx87浮動小数点命令の追加があるが、ここではIA-32以降のSIMD(Single Instruction, Multiple Data)命令の追加を中心とした拡張をリストにした。
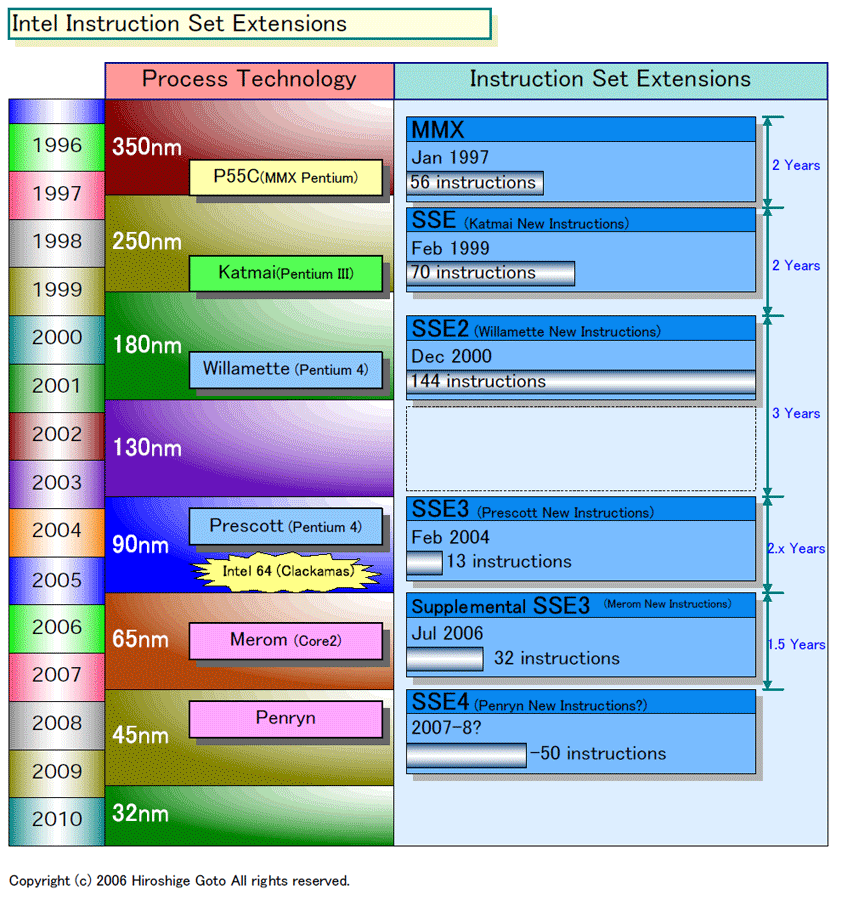 |
| Intel Instruction Set Extensions(※別ウィンドウで開きます) PDF版はこちら |
最初の拡張は、'97年の「MMX」で、350nmプロセスのMMX Pentium(P55C)から実装された。その後、「SSE (Katmai New Instructions)」「SSE2 (Willamette New Instructions)」とIntelはプロセスが1世代微細化する毎に、1グループずつ拡張命令を加えてきた。追加した命令数は、MMXが56命令、SSEが70命令、SSE2が144命令。
命令拡張のペースが鈍化したのは130nm以降で、90nm版Pentium 4(Prescott:プレスコット)では「SSE3(Prescott New Instructions)」の13命令、Core 2(Merom:メロン)では「Supplemental SSE3(Merom New Instructions)」の32命令が加わった。Intelは、この2世代の命令拡張がワンセットでSSE3と定義している。PrescottとMeromの命令拡張は、比較的小規模ということになる。
だが、実際にはPrescottは「Intel 64(旧名EM64T)」が実装されており、ISA自体は大きく拡張されている。ちなみに、オリジナルの計画では、Prescottの次の「Tejas(テハス)」で8個の新命令(Tejas New Instructions)が加わることになっていた。MNI(Merom New Instructions)はこのTNI(Tejas New Instructions)のスーパーセットだと推定される。
整理すると、350nmがMMX、250nmがSSE、180nmがSSE2、130nmが抜けて、90nmと65nmでSSE3(+Intel 64)と拡張された。プロセス技術の発展とともに、命令セットが複雑化してきたことになる。そして、45nmプロセスのSSE4はその次に来る拡張となる。
●ベクタライゼーションを支援するSSE4命令
SSE4の特徴はコンパイラによる自動ベクタライゼーション(ベクタ化)を支援する命令を中心としていることだ。ベクタライゼーションでは、コンパイラがスカラのソースコードからベクタ化(SIMD化)できそうなコードの局所性を見つける。例えば、32bitの値に対して32bitの値を足す演算が繰り返される場合、それを4個の32bit値を格納した128bit SIMDデータに、同様の32bit×4のSIMDを加える演算にすれば、演算は4回が1回に減ることになる。
一般的に、ベクタライゼーションが容易なのはループで、同じ処理を繰り返し一連のデータに対して行なうようなケースが多い。次にコンパイラは、スカラ命令をベクタ命令にコンバート、また、データをSIMDにパック/アンパックする命令を加える。SSE4では、データフォーマットのコンバージョンなど、こうした一連の処理を容易にする命令を含んでいる。
ベクタライゼーションの意図は、SIMDによるデータレベルの並列性「DLP(Data-Level Parallelism)」を使うことで、実質的に、命令レベルの並列性「ILP(Instruction-Level Parallelism)」を上げることにある。CPUのシングルスレッドアプリケーション性能は、動作周波数×IPC(instruction per cycle)×命令ステップ数に比例する。ベクタライゼーションによって命令ステップ数を減らすことで、スレッド内の並列性を上げる。IntelはSIMDユニットのパフォーマンスを引き上げる方向へと向かっており、それを利用しようという意図だ。
また、IntelはSSE4に加えて、CPUに統合するアクセラレータコア向けの命令についても言及している。
 |
| ラトナー氏基調講演で紹介されたテラスケールプロセッサの詳細 |
Intelが明らかにしたのは、「アプリケーションターゲテッドアクセラレータ(Application Targeted Accelerator)」と呼ぶ、一種のコプロセッサ的な固定機能ユニットをCPUに統合して行くことだ。特定のアプリケーションや特定処理に特化したアクセラレータを、汎用CPUに統合する。こうしたアクセラレータは、ターゲットとするアプリケーションを非常に高速化しながらも、消費電力を抑えることができる。CPUやシステムの効率化を図るにはうってつけのソリューションだ。
Intelはテラスケールコンピューティング(メニイコア)でも、固定機能の追加を強調している。45nmプロセス世代からは、それが実際のCPU製品に実装され始めるようだ。このことからは、テラスケール構想は、IntelのCPUアーキテクチャの方向性の集大成であることがわかる。
●アプリケーションに特化したアクセラレータ命令
これまでの汎用(General Purpose)CPUは、できる限り汎用的に使える命令を中心にしてきた(実際にはそうでもない命令もある)。だが、アクセラレータ命令は、それとは趣が異なる。非常にアプリケーションに特化した特殊な命令になるという。
その中で、Intelが最初に実装しようとしているのは「Cyclic Redundancy Check (CRC:巡回冗長検査)」のアクセラレーション。CRCアクセラレータのために、CRCバリューのチェックを行なう命令「CRC32」を実装するという。CRCは、データの完全性、つまり、データが破損しているかどうかをチェックする仕組み。対象とするデータから生成されるCRCバリューを比較することで、チェックを行なう。
CRCは通信やストレージでよく使われており、Intelもネットワークストレージをターゲットとすると説明している。Intelによると、「iSCSI(Internet Small Computer System Interface)」や「RDMA(Remote Direct Memory Access)」といったストレージのデータトランスファプロトコルのアクセラレートが主目的だという。現在は、こうしたプロトコル処理をCPUオフロードする専用チップも使われているが、Intelの構想はそれをCPUベースで取り込むことにある。CPUの汎用コアをオフロードするか、外付けのアクセラレータカードの必要性をなくすことで、システム全体の消費電力を下げることになる。
さらにIntelは、2つ目のアクセラレータ命令としてラージデータセットのサーチ向け命令「POPCNT」を挙げている。Population Count命令で、オペランド中のビットセットの数を数える。Intelは応用例としてゲノムマイニング、手書き認識、ハミングアルゴリズムなどを挙げている。
Intelの45nmプロセス世代のCPUは、汎用の演算ユニットに加えて、CRCアクセラレータとサーチアクセラレータの2種類の固定機能ユニットを持つことになるようだ。Intelは、この2つが統合してもコストに見合うアクセラレータだと判断したことになる。
●ILPウォールがCPU業界の共通認識
SSE4とアクセラレータ命令が示唆するのは、今後のIntelのCPUパフォーマンス向上の方向性だ。コンパイラによるベクタライゼーションで並列性を上げる、アクセラレータによって特定処理の効率を著しく改善する。これらのアプローチからは、CPUの性能をコンパイラやアクセラレータハードで上げようという意図が感じられる。
しかし、それは当然の方向だ。というのは、シングルスレッド性能の向上には、もはや伝統的なILP向上のテクニックがあまり有効ではなくなりつつあるからだ。それは、ILPの向上の余地が小さくなって来たからだ。
現在、CPUアーキテクチャではILPの向上が壁に直面しつつあると言われている。例えば、コンピュータ科学の研究者として有名なDavid A. Patterson(デヴィッド・A・パターソン)教授(University of California at Berkeley)は、2006年8月のチップカンファレンス「HotChips 18」で、ILPの壁「ILPウォール(ILP Wall)」について触れている。同氏によると、ILPを上げるためにハードウェアリソースを追加しても、そこから得られるILP向上の度合いが減りつつあるという。つまり、ILPを少し上げるために、今までより多くのトランジスタを必要とするようになり、性能向上が非効率化していることになる。
Patterson氏は、このほか、消費電力の壁「パワーウォール(Power Wall)」と、メモリアクセスの壁「メモリウォール(Memory Wall)」が、CPUのパフォーマンス向上の障壁になっていると指摘。その結果、シングルプロセッサの性能向上は、従来の1.5年で2倍程度から、5年で2倍程度に落ちるかもしれないと示唆した。つまり、シングルコアの性能は、もはや従来のようなペースでは上がって行かない。
 |
| コンピュータアーキテクチャにおける常識の変遷 |
多くのCPUベンダーが、マルチコア化によるTLP向上へと走っているのはそのためだ。シングルコアで性能が上がらないのなら、コアの数を増やして性能を上げようという流れだ。
ところが、Intelは新マイクロアーキテクチャCore MAではNetBurstに対して、シングルコアのILPも大きく引き上げた。その最大の理由は、NetBurstのILPがもともと低かったためだが、他のCPUベンダーがILPからTLPへとフォーカスを移しつつあるのとは、かなり趣が異なっている。Core MAだけを見ると、IntelはILPを伸ばし続けているように見える。
●ILPに限界が見えたからSSE4とアクセラレータへ向かう
では、Intelは今後も、今回のCore MAのようなペースでILPを引き上げることができると考えているのだろうか。
どうも、そうではなさそうだ。例えば、IntelのJoel S. Emer氏(Intel Fellow, Director, Microarchitecture Research, Enterprise Group)は今回のIDFのQ&Aセッション「Shop Talk」時に次のように説明している。
「シングルコアのILPは今後も継続して向上する。しかし、それほど目覚ましいレートにはならない。ILPを上げるための実装コストが高くなったからだ。我々は、継続してコアも拡張して行くが、シリコンをより有効に使うためにCPUコアの数も増やして行く。LIPとTLPの組み合わせのバランスを取る」
Emer氏は元DECでAlpha EV8などのアーキテクトを務めた。Emer氏の意見も、ほぼPatterson氏と共通している。ちなみに、HotChips 18のキーノートで登場した、IntelのJustin R. Rattner(ジャスティン・R・ラトナー)氏(Intel Senior Fellow, Director, Corporate Technology Group)も、今後はシングルコアの性能はそれほど上がって行かないと語っていた。
 |
| David Perlmutter氏 |
IntelのMobility Groupを統括するDavid(Dadi) Perlmutter氏(Senior Vice President, General Manager, Mobility Group)も次のように語る。
「シングルスレッドとマルチスレッドの両方を上げる。我々は、シングルスレッドの性能を(Core MAで)上げたが、マルチコアの方により重点を置いた。とはいえ、シングルスレッドアプリケーションの性能も継続して向上させようとしている。そのために、あらゆる種類のテクニックを用いる。
ILPの向上はその1つだが、他の手法としては、浮動小数点演算での(コンパイラによる)ベクタライゼーションによって、シングルスレッドのデジタルメディア性能を上げる。また、マイクロアーキテクチャだけでなく、システムレベルでの性能向上も図る。例えば、メモリ階層の改善などだ」
Perlmutter氏も、シングルスレッド性能の向上は、ダイナミックなILP向上の技術だけでなく、ベクタライゼーションやシステムレベルの改良によるメモリウォールの軽減など、複合したアプローチで達成するというニュアンスだ。
こうして見ると、Intelも、ILP向上は壁に当たっていることを前提にアーキテクチャを考えていることがよくわかる。おそらく、今後のIntelのマイクロアーキテクチャでは、今回のCore MAほど、ハードウェアによる動的なILPの大幅な向上は望めない。つまり、CPUコア自体のダイナミックILPはそれほどは上がって行かない。
CPUリソースは、CPUコア内部では浮動小数点演算SIMD系の拡張に費やし、また、CPUコアを増やすことにも投入する。シングルスレッドの性能向上は、コンパイラによるベクタライゼーションや、特定アプリケーション向けアクセラレータ搭載で上げて行く。そして、オーバーオールの性能は、マルチコアを活かすことで引き上げる。基本的には、今後のIntel CPUの発展はこうしたラインにあることがわかる。
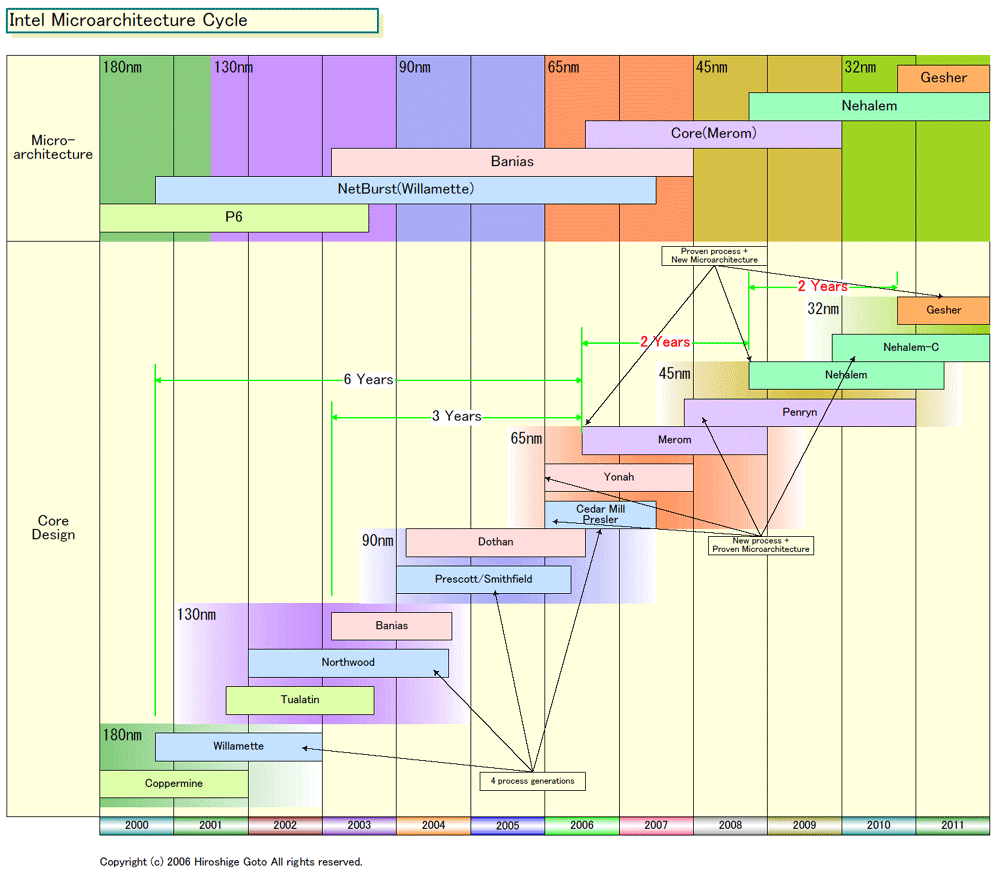 |
| Intel Microarchitecture Cycle(※別ウィンドウで開きます) PDF版はこちら |
□関連記事
【10月2日】【海外】次世代CPUのヒントが出されたIDF
http://pc.watch.impress.co.jp/docs/2006/1002/kaigai306.htm
【9月29日】【海外】年内に投入され、45nmで普及を目指すIntelのクアッドコア
http://pc.watch.impress.co.jp/docs/2006/0929/kaigai305.htm
【9月28日】【IDF】ラトナーCTO基調講演レポート
http://pc.watch.impress.co.jp/docs/2006/0928/idf02.htm
(2006年10月4日)
[Reported by 後藤 弘茂(Hiroshige Goto)]
【PC Watchホームページ】
PC Watch編集部 pc-watch-info@impress.co.jp ご質問に対して、個別にご回答はいたしません
Copyright (c) 2006 Impress Watch Corporation, an Impress Group company. All rights reserved.