 |


■後藤弘茂のWeekly海外ニュース■決定的となったヘテロジニアスマルチコアへの潮流 |
●モノリシックコアからヘテロジニアスマルチコアへ
コンピュータ向けCPUは「ヘテロジニアス(Heterogeneous:異種混合)マルチコア」へと向かっている。PLAYSTATION 3(PS3)に載る「Cell」がその方向を定め、AMD CPUとATI GPUの統合が決定付けた。おそらく、今後10年のCPUアーキテクチャの方向は、ヘテロジニアスマルチコアになる。
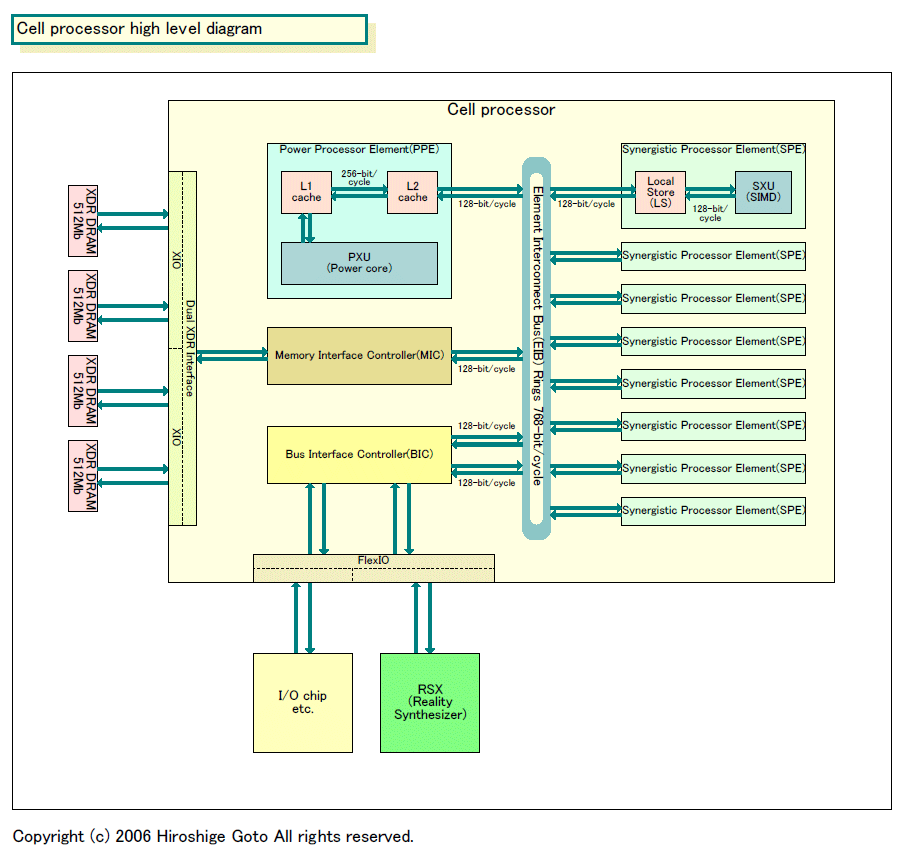 |
| Cell processor high level diagram(※別ウィンドウで開きます) PDF版はこちら |
AMDがCellと似たような方向へ進むことは、ATI買収の発表の前に、すでに示唆されていた。AMDのPhil Hester(フィル・へスター)氏(Senior Vice President & Chief Technology Officer(CTO))は5月に次のように語っている。
「我々のワークロードは汎用コンピューティングが主流で、ゲームプラットフォームとは異なるストーリとなる。Cellはゲームプラットフォームのためのプロセッサで、汎用コンピューティングへ(の適用)は難しいだろう。ただし、潜在的には、(強力な)汎用プロセッサにCell(のSPE)をアタッチすることもできると考えている。特定のワークロードはCell(のSPE)で走らせ、汎用ワークロードは強力なままのプロセッサで走らせるといった形だ」。
AMDの汎用(General Purpose)CPUコアに、ATI GPUの演算プロセッサ「Programmable Shader」を組み合わせた姿は、まさにこれに当たる。Cellの演算プロセッサ「SPE(Synergistic Processor Element)」は、GPUのShaderにある程度似た性格を持つからだ。AMDが、GPUコアからShaderを抜き出して、CPUと密接に統合させる方向を選べば、その構造はますますCellと似ることになる。
| AMD Processor transition?(※別ウィンドウで開きます) PDF版はこちら |
●スーパースカラ以来のCPUアーキテクチャの大きな節目
もっとも、ヘテロジニアス型のCPUコアの構成自体は、珍しいものではない。むしろ、組み込み系CPUでは制御用コアと演算用コアという構成はごく普通で、コンピュータ向けCPUが例外的だったとも言える。あくまでも、コンピュータ向けCPUのトレンドの変化だ。
これまでのPC&サーバー向けCPUは、モノリシックなシングルコアをひたすら拡張する方向で進んできた。それが、過去1~2年で、単一アーキテクチャのCPUコアをマルチ化した、「ホモジニアス(Homogeneous:均質)マルチコア」へと急転換し、さらに、次の2~4年のステップではヘテロジニアスマルチコアへと進もうとしている。
AMDは2008年以降には、少なくともPC向けCPUをヘテロジニアスマルチコアへと進化させる。ヘテロジニアス形のハイパフォーマンスCPUの先駆Cellを載せたPS3は、もうすぐ市場に登場する。Intelは、リサーチプロジェクトの「Many-core(メニイコア)」でヘテロジニアスマルチコア化を打ち出しており、おそらく、製品レベルでも今後4年程度でこれに似たアプローチへと進むと予想される。
この変化は、数十年に一度のCPUアーキテクチャの大きな節目になる可能性が高い。それは、ヘテロジニアスマルチコア化が、CPUにとってさまざまな根源的な変化を含んでいるからだ。それは次のような変化だ。
○ベクタプロセッサの統合による10倍の演算パフォーマンスアップ
○命令並列性からスレッド並列性とデータ並列性への変化
○シンプルコア化によるパフォーマンス効率のアップ
○モジュラー化によるCPU開発効率の改善
○「フリーランチの終焉」ソフトウェア開発の労力が激増
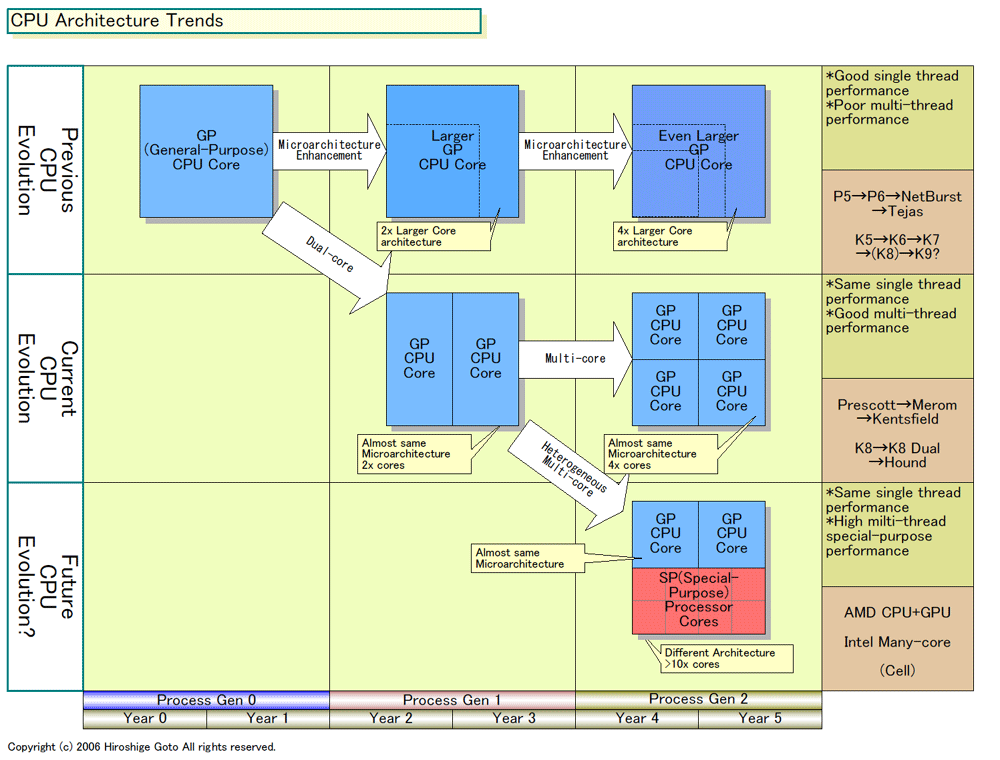 |
| CPU Architecture Trends(※別ウィンドウで開きます) PDF版はこちら |
●ベクタプロセッサで10倍の演算パフォーマンスへ
ヘテロジニアスマルチコアと一口に言ってもさまざまなアーキテクチャが考えられるが、AMDやソニー/IBM/東芝はある程度方向が似ている。どちらも、汎用(General Purpose)CPUコアとSIMD(Single Instruction, Multiple Data)型演算にフォーカスしたプロセッサコアを組み合わせる構成を取った。PCやゲームコンソールなどでは、「ベクタプロセッサ」の一種であるSIMD型プロセッサが、統合するコアとして妥当と判断されたことになる。
CellもAMD CPUも、ヘテロジニアス構成を取る目的は、大まかには同じと考えられる。それは、演算パフォーマンスを飛躍的にアップさせること。Cellは3.2GHz時に理論値で200GFLOPS以上(8個のSPEなら205GFLOPS)の浮動小数点演算パフォーマンス(単精度の場合)を誇る。AMDのGPU統合CPUも、おそらく数百GFLOPSクラスの単精度浮動小数点性能に達すると見られる。IntelもゴールにTFLOPS(テラフロップス)を掲げている。
単精度で数十GFLOPS止まりの従来のPC向けCPUから、演算パフォーマンスを飛躍させようというのが狙いだ。同プロセス世代同ダイサイズ(半導体本体の面積)で比べるなら、10~20倍のパフォーマンスアップとなるだろう。あるCell関係者は「10倍のパフォーマンスアップなら、アーキテクチャの変化を受け入れてもらえると考えた」と語っていた。
簡単に言うと、「ヘテロジニアスマルチコア=数百GFLOPS=10倍パフォーマンス」へと舵を切ったことになる。
●ILP偏重からTLPとDLP重視へと変わる
また、これはCPUアーキテクチャの方向性の根源的な変化ととらえることもできる。これまでの汎用CPUは、命令レベルでの並列性「ILP(Instruction-Level Parallelism)」を追求してきた。そのために、スーパースカラ構造でアウトオブオーダ(out-of-order)実行型のアーキテクチャを開発した。
しかし、これからは、マルチコア化によるスレッドレベルの並列性「TLP(Thread-Level Parallelism)」を高め、搭載するコアにベクタプロセッサを選ぶことにより「DLP(Data-Level Parallelism)」を高める。つまり、ILPによる性能向上から、TLP&DLPによる性能向上へと舵を切る。
IntelもAMDも、汎用CPUコアのパフォーマンス拡張を諦めるわけではない。IntelはCore Microarchitectureで汎用CPUコアのILPとDLPを引き上げ、AMDも次のHound世代の汎用CPUコアでILPとDLPを上げる。しかし、もはや以前のようなペースでは汎用CPUコアを拡張しない。汎用CPUコアの拡張は鈍化させ、ダイサイズ(半導体本体の面積)の多くは、TLPとサブプロセッサコアによるDLPの向上に費やすようになると推定される。
ただし、TLP&DLPによってどうやってパフォーマンスを向上させるかについては、まだ各社の方向性が定かではない。例えば、Intelはシングルスレッドプログラムを、リアルタイムにスレッドに分解することで、マルチスレッドCPU上でシングルスレッドのパフォーマンスを引き上げる「投機マルチスレッディング(Speculative multithreading)」を真剣に検討している。他社は、投機マルチスレッディングについては静観している。
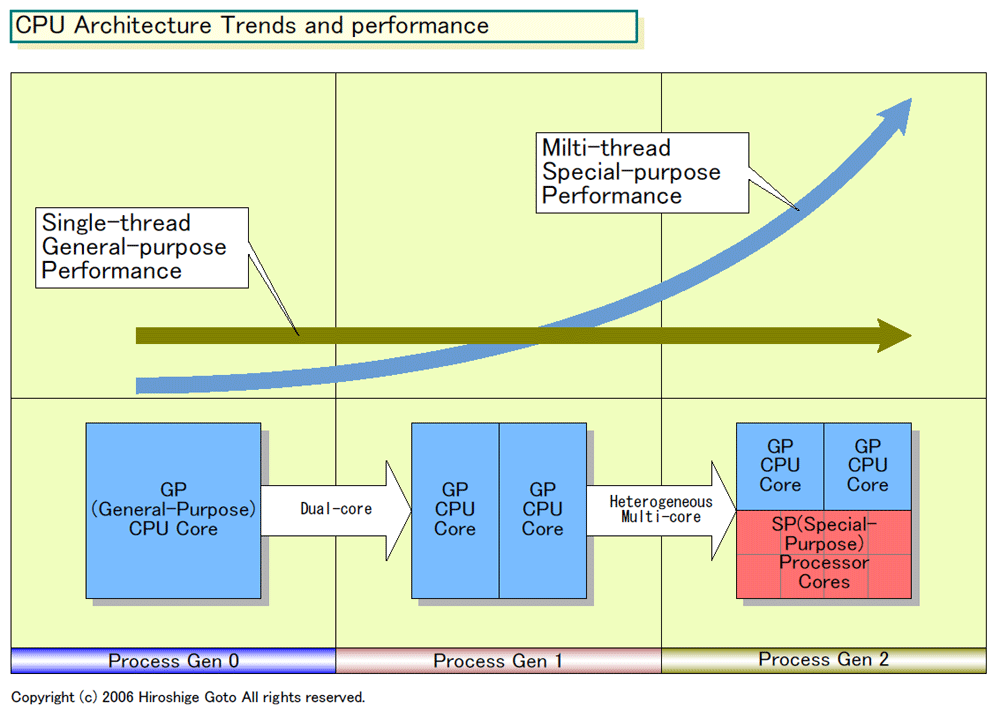 |
| CPU Architecture Trends and performance(※別ウィンドウで開きます) PDF版はこちら |
●シンプルコア化でポラックの法則を破る
「シンプルコア化」もキーワードの1つだ。ヘテロジニアス型では、サブの演算プロセッサコアをより簡素なシンプルコアにすることで、多数のCPUコアの搭載を可能とする。Cellの場合は汎用CPUコアである「PPE(Power Processor Element)」もシンプルコアとすることで合計9個のCPUコアを搭載する。それに対して、Cellと同サイズのPC向けCPUはデュアルコアに留まる。大まかに言って、CellのコアはIntelの汎用コアの1/4のシンプルさということになる。AMDのCPU+GPUでも、汎用CPUコア1個分のスペースに少なくとも4個、多ければ10個以上のベクタプロセッサ(Shader)を載せることができると推測される。こちらもシンプルコアだ。
シンプルコア化によって、ムーアの法則に沿った性能向上を達成することができる。Cell関係者は「これまでのCPUはムーアの法則に沿った性能向上を達成できていなかった」と指摘する。つまり、プロセス世代毎に2倍の性能アップはして来なかった。これは、CPUコアを拡張しても、それに見合ったパフォーマンス向上は得られないからだ。
このCPU開発の経験則は以前から知られていたが、Intelは『ポラックの法則』と名付けている。Intel Microprocessor Research Labs(MRL)のディレクタ兼Intel FellowだったFred Pollack(フレッド・ポラック)氏の発見にちなんだものだ。それによると、CPUのダイサイズ(=トランジスタ数)を2倍に増やしても、パフォーマンスはその平方根(約1.4倍)程度にしか伸びないという。
つまり、CPUコアはパフォーマンスを増すにつれてどんどん非効率になってきた。そのため、CPUコアの複雑化を止める、あるいは逆にシンプルコア化すると、CPU全体のパフォーマンス効率はアップする。CPUコアをシンプルに留めたまま、コア数を増やして行くと、理論上のパフォーマンスはプロセス世代毎に倍々に伸びて行くことになる。つまり、ムーアの法則に沿った向上が得られ、ポラックの法則を破ることができる。
●モジュラー化でCPU開発地獄を抜け出す
CPUを、比較的シンプルなCPUコアの集合体に組み替えることは、CPUの開発効率をアップさせる。CPUコアは、プロセス技術の発達とともに利用できるトランジスタ数も指数関数的に増えてきた。そのため、CPUコアは非常に複雑化しており、それに伴いバグも開発コストも増え、パフォーマンスチューニングも難しくなっているという。また、開発規模が巨大化するにつれて、設計の全体像を把握することも難しくなり、プロジェクト管理自体が難しくなっているという。
この問題はIntelの元アーキテクト(P6, Willamette)だったRobert P. Colwell(ボブ・コールウエル)氏が自著『The Pentium Chronicles: The People, Passion, and Politics Behind Intel's Landmark Chips』(2005/12, Wiley-IEEE Computer Society Press)で指摘している。
また、レガシーを引きずるIA-32命令セットの場合は、命令セットの複雑さのためにパフォーマンスチューニングも難しいという。Colwell氏は、2004年2月に米スタンフォード大学で行なった講演「Things CPU Architects Need To Think About」でこの点も指摘している。同氏は、IA-32のパフォーマンス向上を、「ゾウを急坂に押し上げるようなもの(Pushing Elephants up Steep Hills)」と形容。無理な高速化により、アーキテクチャ上の脆弱性が増していると説明していた。
こうした問題も、マルチコア化で抑えることができる。汎用CPUコアの拡張を抑えると同時に、設計が容易なシンプルコアを演算プロセッサとして加えるなら、全体の設計はずっと容易になる。演算プロセッサが汎用CPUコアの1/4の規模なら、複雑度も1/4となる。あとは、各コアエレメントを複製して並べるだけだ。CPU全体のうち、半分以上を複製した回路が占めるなら、実際に設計しなければならないエリアは半分になる。その分、開発期間も短縮できる。
●メモリ帯域が最大の障壁になる
ヘテロジニアスマルチコア化は、システムのコンフィギュレーションに変化をもたらし、メモリの重要性も高める。CPUにとってメモリ帯域が非常にクリティカルになるからだ。
演算性能、特に、ベクタコアによるストリーミングタイプのプロセッシングのパフォーマンスが増えると、それに見合うメモリ帯域がCPUに必要となる。200GFLOPSレベルのCellが25.6GB/secのメモリ帯域を使う。単純に考えれば、PC向けのヘテロジニアスマルチコアが500GFLOPSレベルに達した時は、50GB/secのメモリ帯域が必要となる。これは、デュアルチャネルDDR3-1600の2倍のメモリ帯域だ。
メモリ技術的にはDDRの2倍高速なGDDRがあるが、コンピュータではモジュールによるメモリ増設は欠かせない。現状では、こうした条件を満たすのはRambusのXDR DRAM系メモリ技術だけだ。CPU側の変化は、メモリアーキテクチャにも大きな影響を与えると予想される。異なるコアが、異なるメモリアクセスビヘイビアを取ることも、問題になるだろう。
ソフトウェア側がヘテロジニアスマルチコアに適応して来ると、ソフトウェアのスケーラビリティが高まる。マルチスレッドで性能が出しやすくなるため、マルチコアだけでなく、マルチプロッサでも性能が上がりやすくなる。マルチプロセッサの構成もホモジニアスではなく、ヘテロジニアスが可能になる。例えば、AMDのCPU+GPUに、ビデオカードを加えて、外側のGPUチップにも処理を分散するといったことが可能になる。そのため、さまざまなシステムコンフィギュレーションが可能になる。Cellのように、ネットワーク経由の分散化もアーキテクチャ段階から織り込んでいれば、よりスケーラブルな展開も見えてくる。
●ソフトウェアのフリーランチが終わった
ただし、ヘテロジニアスマルチコアへの変化には痛みが伴う。それはソフトウェア面だ。ヘテロジニアスマルチコア化によって、ソフトウェア開発の労力が激増する可能性があるからだ。ヘテロジニアスマルチコアは、ハードウェア側の痛みを、ソフトウェア側に持って来るアプローチと考えることもできる。
 |
| The First Slide Last(※別ウィンドウで開きます) PDF版はこちら |
これは「the free lunch is over(フリーランチは終わった)」という、昨年(2005年)米国で有名になった言葉に集約されている。これは、MicrosoftのSoftware ArchitectであるHerb Sutter氏がコラムなどで言い始めた言葉だ。フリーランチはタダ飯のことで、タダ飯食いは、もうできないという意味だ。
これまで、CPUはシングルコアの性能を高める方向で来た。そのことは、ソフトウェアにとってはタダ飯食いと同じことだったという。つまり、ソフトウェア側は何もしなくても、CPUが進化するにつれて同じコードがより速く走るようになったからだ。ソフトウェアは、増えるパフォーマンスをどんどん食べればよいだけだった。
ところが、CPUベンダーがマルチコアにターンしたため、状況が変わってしまった。汎用CPUコアのシングルスレッド性能は、現状ではもはや急激には伸びてゆかない。その代わり、マルチコア化によりマルチスレッド性能が急激に上がって行く。そのため、ソフトウェア開発者はCPUのパフォーマンスを活かそうとすると、ソフトウェア側を根底から切り替えて行かなければならない。
特に、ヘテロジニアスマルチコアになると、対応が非常に重要となる。CellやAMD CPU+GPUの場合は、演算コアであるSPEやShaderで走るコードを書けば非常に高いパフォーマンスが得られるが、そうしない限り大きな性能アップは得られない。これまでと違って、パフォーマンスアップはタダではなく、代価を払わなければならない。フリーランチは終わってしまったというわけだ。
そのため、CPUベンダーはソフトウェア側の労力を軽減するための手段に、ますます注力する必要がある。それは、開発環境だったり、ライブラリやローレベルのプリミティブだったりする。AMDはGPUコアを選んだことで、DirectXとOpenGLという広いソフトウェアベースを使うことができるが、GPUコアをもっと汎用に使うためにはそれでは足りない。Cellも、ゲーム開発という比較的閉じた世界から広げるためには、まだまだ開発環境を整える必要がある。
ヘテロジニアスマルチコア化によってソフトウェアの負担が増える分、CPUベンダーはそこに力を入れなければならない。CPUベンダーの役割は、ハード設計だけでなく、ソフトウェアベースの方に、さらに寄らなければならない。しかし、Sutter氏は昨年(2005年)のFall Processor Forumのキーノートスピーチで、ハードウェア側にはソフトウェア側の困難に対する理解は、まだ薄いのではないかと指摘した。
課題はここにある。
□関連記事
【8月10日】【海外】AMD+ATIの統合プロセッサの姿
http://pc.watch.impress.co.jp/docs/2006/0810/kaigai294.htm
【8月2日】【海外】AMDがATIのGPUを選んだ理由
http://pc.watch.impress.co.jp/docs/2006/0802/kaigai293.htm
【7月25日】【海外】AMDとATIのプロセッサは1つに融合する
http://pc.watch.impress.co.jp/docs/2006/0725/kaigai290.htm
(2006年8月18日)
[Reported by 後藤 弘茂(Hiroshige Goto)]
【PC Watchホームページ】
PC Watch編集部 [email protected] ご質問に対して、個別にご回答はいたしません
Copyright (c) 2006 Impress Watch Corporation, an Impress Group company. All rights reserved.