 |


■後藤弘茂のWeekly海外ニュース■AMDとATIのプロセッサは1つに融合する |
●Torrenzaの最後のパーツがATIの買収
 |
| AMDのPhil Hester(フィル・へスター)CTO |
AMD+ATI結合体は、CPUとグラフィックス“コプロセッサ”を統合した次世代プロセッサを実現するために走り始めたと見られる。
AMDは、すでに、コプロセッサをAMDプラットフォームに統合するイニシアチブ「Torrenza(トレンザ)」を発表している。Torrenzaのゴールでは、AMDは汎用プロセッサコアと、特定用途向けのコプロセッサコアをワンダイ(半導体本体)に統合する。AMDは、汎用プロセッサコアについては、当面はベースアーキテクチャを刷新しないと見られる。汎用プロセッサコアを肥大化させるよりも、アプリケーションに最適化したコプロセッサコアでパフォーマンスを得た方が得策と判断した。Torrenzaは、こうしたAMDのCPUアーキテクチャの方向性を示す重要な戦略だ。
しかし、Torrenzaの発表では、AMD自身のコプロセッサ開発や、メディアプロッセッシングパートナーの話は抜け落ちていた。しかし、今回のATIの買収により、このパーツが埋まる。Torrenzaを前提とすれば、当然AMDはATIのプロセッサを同じダイへと統合する。そして、PC向けCPUでは、統合されるコプロセッサコアはGPUコアになることが明瞭になった。Torrenzaで当然出てきてしかるべきGPUが、Torrenza発表時点で抜け落ちていた謎もこれで解けた。
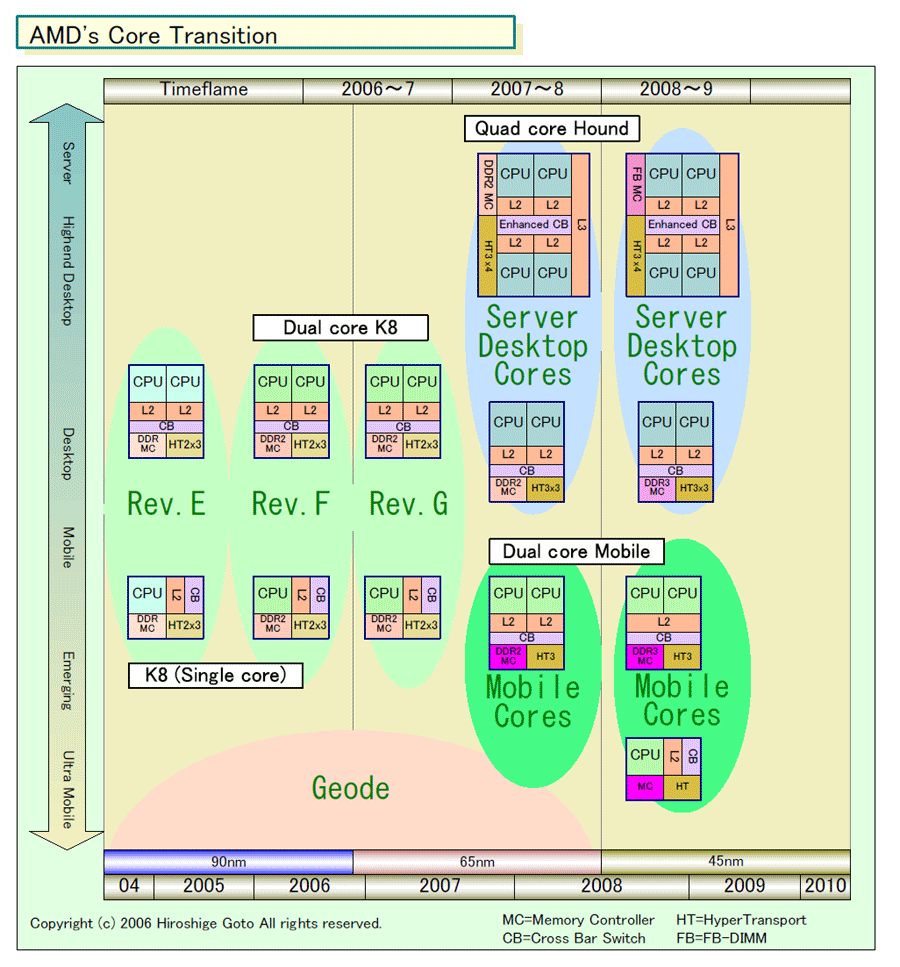 |
| AMD CPUアーキテクチャ移行図 最新版 (※別ウィンドウで開きます) PDF版はこちら |
●ベクタプロセッサコアをCPUへ統合へ
 |
| ATI TechnologiesのDavid E. Orton(デビッド・E・オートン)社長兼CEO |
もっとも、CPUに統合される時点のATI GPUは、汎用性の高い「Programmable Shader(GPUのプログラマブル演算ユニット)」の塊であり、そのベクタ演算ユニットはグラフィックス用途だけでなく広範囲に応用される。つまり、将来のAMD CPUの実態は、汎用スカラプロセッサコア群+ベクタプロセッサコア群の「ヘテロジニアスマルチコア(異種混合マルチコア:Heterogeneous Multicore)」プロセッサとなる。言い換えれば、「Cell」プロセッサに似たコンセプトを持つCPUに進化する。
AMD+ATIのヘテロジニアスマルチコアが実現すると、1個のCPUの中に複数のAMD汎用プロセッシングコアと、多数のProgrammable Shader(GPUの演算コア)を持つATIのベクタプロセッサコアが内蔵されるようになる。レガシーの汎用コンピューティングアプリケーションはAMDの汎用コアで走り、グラフィックスやデータセントリックなコンピューティングはATIのベクタコアで走るようになると推定される。
 |
| ATI Processor in Torrenza (※別ウィンドウで開きます) PDF版はこちら |
技術的な指向性で見れば、ATIはAMDの目的には最適のパートナーだ。現状で、ATIは、GPUメーカーの中では最もプロセッサ指向が強い。ATIの次世代GPU「R600」ファミリは、より柔軟で汎用性の高い「Unified-Shader」アーキテクチャを取る。すでに、ATIは他社に先駆けて、Xbox 360に搭載したGPU「Xeos」でUnified-Shaderアーキテクチャを採用している。Unified-Shader化したGPUは、真にベクタプロセッサと呼ぶにふさわしい汎用性を持ち、CPUに統合して汎用コンピューティングに応用しやすい。
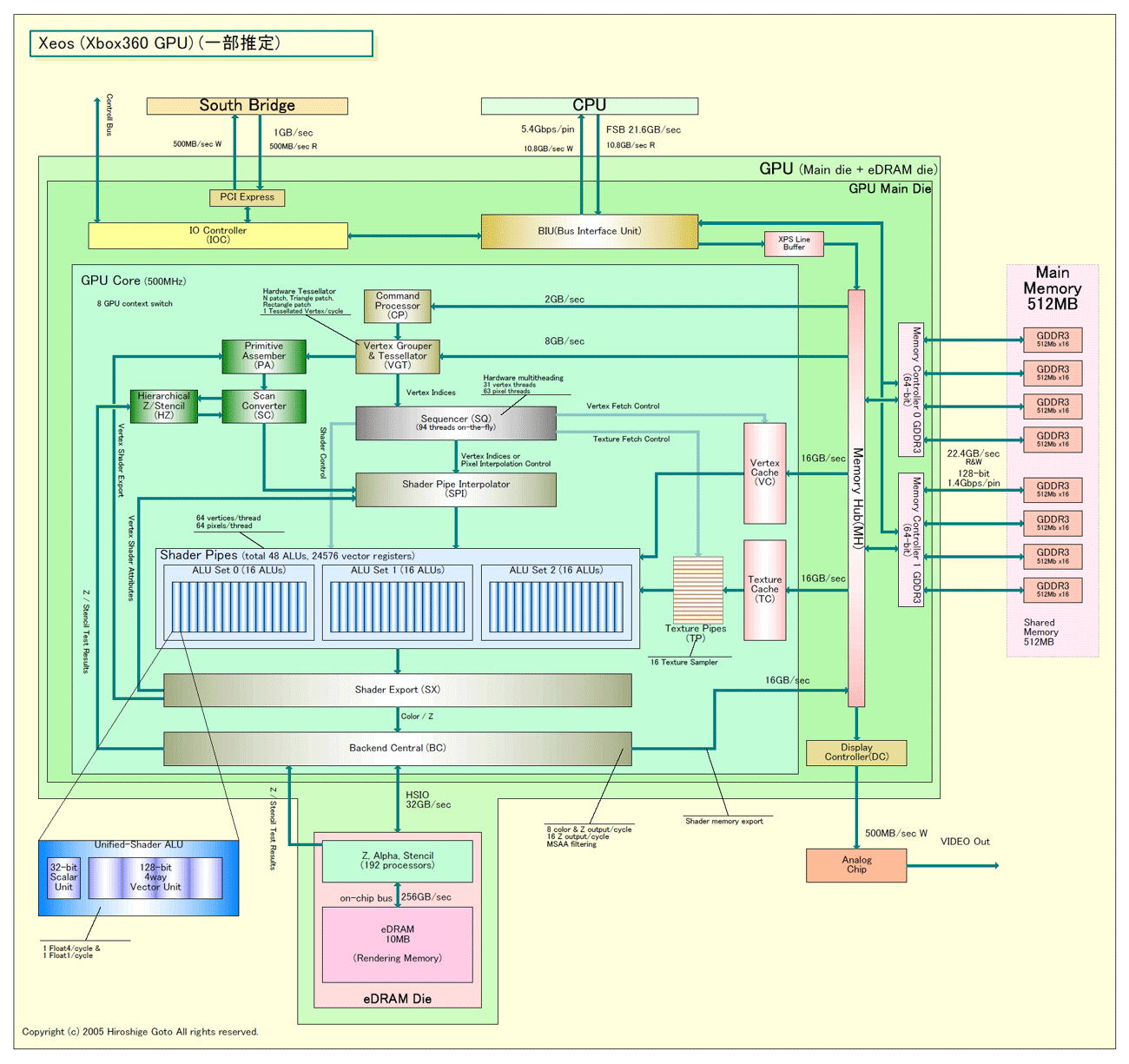 |
| Xeos(Xbox360 GPU)(一部推定) (※別ウィンドウで開きます) PDF版はこちら |
「グラフィックスプロセッサはどんどん、汎用的なベクタプロセッサになってゆく」とATIのRich Heye(リッチ・ハイ)氏(Vice President & General Manager, Desktop Business Unit)は語る。Heye氏は、元AMDの副社長からATI副社長へ転身した人物で、移籍した理由について上のベクタプロセッサ化を挙げていた。すでに、AMDがATIと交わる前から、ATIはAMDの人材を取り入れていた。
●AMD+ATIプロセッサの想定される姿
では、AMD+ATIの次世代プロセッサはどんな姿になるのだろう。
ATI製品のAMDへの最適化&統合化はいくつかのステップを経ると推定される。最初のステップとして確実なのは、HyperTransportネイティブのGPU設計だ。
ATIのベクタプロセッサは、おそらくAMD CPUにHyperTransportまたはCoherent HyperTransportで直接接続できるようになる。形態から見るとグラフィックス統合チップセットを強化するのと同じだが、HTX(HyperTransportの拡張スロット仕様)カードやAMD CPUソケットでの拡張も視野に入るだろう。
次のステップとして想定されるのはCPUパッケージへの統合だ。Torrenzaでは、AMDのCPUパッケージに、マルチチップモジュール技術を使ってコプロセッサを統合することを計画している。この場合、ATIのベクタプロセッサのダイは、Coherent HyperTransportでCPUのダイとオンモジュールで接続される。
そして、最終的なステージではオンダイへのコプロセッサの統合となる。このフェイズでは、ATIのベクタプロセッサコアは、インターナルのCoherent HyperTransportでAMDのプロセッサコア群と結ばれることになる。AMDは、CPU設計にビルディングブロックアプローチを取り入れ、各ブロック間のインターフェイスをよりクリーンにすることで、コプロセッサなどの統合を容易にしている。
こうしたAMD+ATIの密接な統合が実現すると、ワンチップで汎用コンピューティングとグラフィックスとデータセントリックコンピューティングが実現できるようになる。バリューレンジなら、AMD+ATIワンチップ+サウスブリッジチップでPCが実現できるようになる。よりハイパフォーマンスなレンジでは、GPUを外付けして、CPU内のベクタコアはフィジックスのようなデータ演算だけに使うこともできるだろう。
●増えたトランジスタをベクタエンジンにつぎ込む
プロセス技術の進歩も、統合化をドライブする。プロセスが微細化するにつれ、AMDはCPUに多数のコアを載せられるようになる。
下のダイサイズのチャートを見ればわかる通り、AMD CPUのダイサイズ(半導体本体の面積)は、デュアルコアですら65nmプロセス世代に100平方mmを切り始める。45nm世代ではデュアルコアでは、確実にダイエリアが余ってしまう。
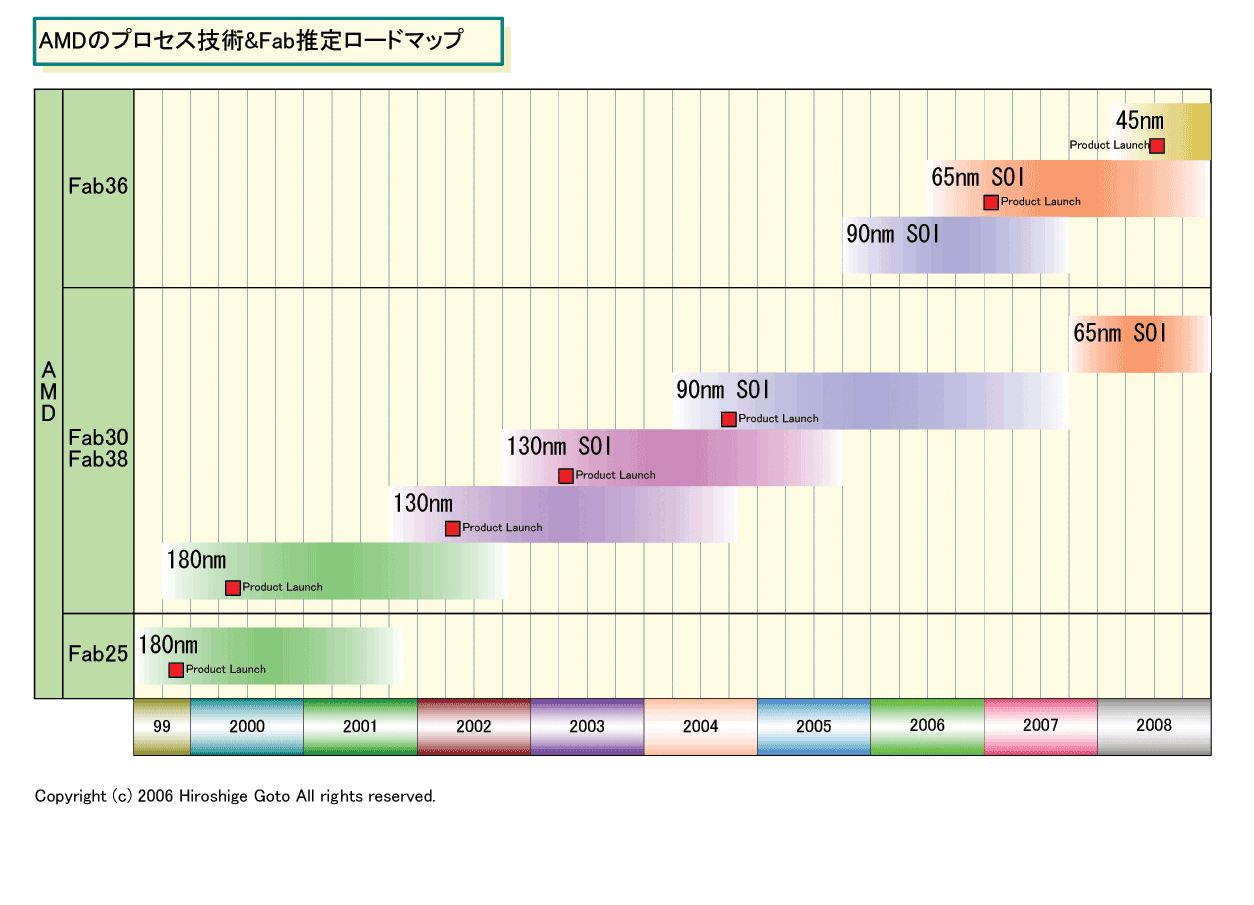 |
| AMDのプロセス技術&Fab推定ロードマップ (※別ウィンドウで開きます) PDF版はこちら |
 |
| AMD CPU Die Size(一部推定) (※別ウィンドウで開きます) PDF版はこちら |
AMD CPUはDRAMインターフェイスを統合しているため、CPUの周囲にある程度パッドの面積が必要だ。そのため、一定以下のダイサイズにはできない。そのため、AMDは何かでダイを埋めなければならない。しかも、AMDはIBMとのプロセス技術開発の提携で、プロセスの移行をスピードアップしつつあり、65nmから45nmへは約1年半で移行するつもりだ。つまり、AMDは急速に多くのコアを載せることが可能になりつつある。
しかし、汎用プロセッサコアを2個から4個に増やしても、パフォーマンス上の利点はそれほど大きくはない。PCのソフトウェア環境では、汎用コンピューティングのアプリケーションがマルチスレッドで同時に多数走らないからだ。
PCでは、それよりもマルチメディア系や、いわゆるRMS-「Recognition(認識)」「Mining(分析&抽出)」「Synthesis(合成)」-系のアプリケーションのパフォーマンスが求められるようになると言われている。こうしたアプリケーションはデータセントリックで、膨大なデータ処理能力が求められる。つまり、コンピューティングの重要性が、汎用コンピューティングから、もっとデータ演算中心へと傾きつつある。それに対するよりよい解は、汎用コンピューティングコアの増強ではなく、データ処理に特化したコプロセッサの搭載とAMDは考えたと見られる。
これをトランジスタバジェット、つまり、使えるトランジスタ数という観点から見ると、次のようになる。
ムーアの法則で1プロセス世代毎に、同程度のダイサイズのCPUに載せられるトランジスタ数は倍々になっていく。しかし、そのバジェット(資産)を汎用コアにつぎ込んでも性能アップが得にくい。
汎用コアを肥大化させてもシングルスレッド性能はそれほど劇的に上がらないし、汎用コアを増やしても、マルチスレッド化が劇的に進まないと性能のベネフィットが小さい。となれば、増えたバジェットを、データプロセッシングに特化したベクタプロセッサにつぎ込んだ方が効率的となる。データセントリックなアプリケーションは、マルチスレッド化もしやすいので、ぴったりフィットする。
この考え方は、基本的にはCellとよく似ている。Cellは、汎用プロセッサコア「PPE(Power Processor Element)」とベクタ演算プロセッサコア「SPE(Synergistic Processor Element)」のヘテロジニアス統合だ。ゲームではデータセントリックなプロセッシングが必要と見て、8個のSPEをワンチップに載せている。ちなみに、PLAYSTATION 3も、初期プランでは、Cellをベースにしたアーキテクチャでグラフィックスも処理するという案になっていた。
●サーバー向けの64bitベクタプロセッサは
 |
| GPUで物理演算を行なうCOMPUTEXでのデモ |
例えば、ATIが絡むベクタプロセッサの分野では、サーバー向けとPC向けでは、要求される仕様が異なる。そのため、AMDはサーバーCPUとクライアントCPUで、それぞれ異なる仕様のベクタプロセッサを統合を統合すると推測される。ポイントの1つは演算精度だ。
グラフィックスやメディアプロセッシング、ゲームフィジックスでは32bit単精度浮動小数点演算(FP32)までしか要求されない。そのため、GPUもShader Model 3.0/4.0世代では、FP32で4wayのベクタ演算能力(128bit)しか実装しない。しかし、科学技術系などでは64bit倍精度浮動小数点演算(FP64)か、それ以上が要求される。ATI TechnologiesのDavid E. Orton(デビッド・E・オートン)社長兼CEOは、6月のCOMPUTEXのラウンドテーブルで、FP64について、次のように答えている。
「FP64を実装するかどうかについて、いくつかの疑問がある。まず、汎用コンピューティング分野では、FP32で解決できない問題が出る。いい例が、物理演算だ。ゲームアプリケーション向けの物理ではFP64は全く必要ない。この種のビジュアルエクスペリエンスに影響のあるアプリケーションでは、FP32で十分だと考えている。しかし、(同じ物理演算でも)オイルやガスの採掘や科学技術プログラミングでは、倍精度のサポートと、エクセプションハンドリングのサポートが必要となる。
そのため、我々は、倍精度とエクセプションハンドリングの方向も継続して(研究して)いる。グラフィックスエンジンの全てのリソースの中で、4(Way)のパイプラインを捨てることなく、倍精度のサポートを実現する方向が適切だと、私は考えている。そのためには、アーキテクトがクリエイティブでないとならない。しかし、我々は、倍精度とエクセプションハンドリングについて研究している」
すでにAMDとの対話がかなり進展していたと見られるこの時点で、Orton氏はFP64の実装の方向について否定していない。グラフィックスやゲームフィジックスではFP64は必要ないとしながら、汎用コンピューティングのためにFP64を検討していると言う。AMD傘下になったATIが、FP64の汎用ベクタプロセッサへと向かうのは自然な流れに見える。
●CPUとGPUの統合化は今後の大きなトレンド
CPUとGPUの統合、言い換えるとスカラプロセッサとベクタプロセッサの統合は、おそらく、今後5~10年のプロセッサ業界の大きなトレンドとなる。AMDとATIだけでなく、他のCPUベンダも最終的にはこの流れに乗ってくると推定される。実際、AMDとATIの件が発表される前から、CPU業界関係者は口々にCPUとGPUの統合について語っていた。
例えば、あるCPUメーカー関係者は「CPUはブラックホールのように何でも飲み込んでゆく。チップセット…、将来はGPUも飲み込むだろう」と言っていた。Intel関係者ですら「CPUとGPUが統合されるのは、当然の流れだろう」と語る。Intelが考えているヘテロジニアス型マルチコアの将来像にも、Shaderとして使うことができるベクタ演算プロセッサの統合が含まれていると推定される。
そもそも、GPUがShader時代に入ってから、CPUメーカーはGPUに高い関心を示し始めていた。どんどん汎用化するShaderのアーキテクチャは、CPUメーカーにとってなじみ深いものだからだ。実際、IntelはGPUコア開発に本気で取り組み始めており、Intel 965 Express(Broadwater-GC:ブロードウォータ-GC)ではUnified-Shaderタイプの実装を行なったと見られる。その先も、Intelは複数のグラフィックスコアのプロジェクトを平行して進めていると言われる。
他のCPUベンダーも、公式に表明することはないが、オフラインではGPUへの進出がしばしば話題に上る。あるCPUメーカーの関係者は数年前に「CPUメーカーの回路設計技術があれば、現在の数倍のクロックで動作するGPUを作ることができる」と語っていた。また、あるCPU開発ベンダーでは、社長自身がグループ企業のGPUのネットリスト(設計データ)を取り寄せてチェックしているという。
こうした水面下の動きを見ると、CPUとGPUの統合化は今後大きな潮流になると推定される。GPUまたはGPUが取ろうとしているベクタプロセッシングのエリアを取り込まないと、CPUはその意味を失ってしまうからだ。
□関連記事
【7月25日】AMD、ATI買収記者会見を開催
http://pc.watch.impress.co.jp/docs/2006/0725/amdati.htm
【7月24日】AMD、ATIの買収を発表
http://pc.watch.impress.co.jp/docs/2006/0724/amdati.htm
【7月21日】コプロセッサへの分散が進むAMDの次世代CPU
http://pc.watch.impress.co.jp/docs/2006/0721/kaigai289.htm
(2006年7月25日)
[Reported by 後藤 弘茂(Hiroshige Goto)]
【PC Watchホームページ】
PC Watch編集部 pc-watch-info@impress.co.jp ご質問に対して、個別にご回答はいたしません
Copyright (c) 2006 Impress Watch Corporation, an Impress Group company. All rights reserved.