 |


■後藤弘茂のWeekly海外ニュース■“シンプルコア”に向かう次世代CPUアーキテクチャ |
●CPUコアの複雑化にストップがかかった
Intelの「Tejas(テハス)」と「Nehalem(ネハーレン)」、AMDの「K9」と「K10」。x86系の両CPUメーカーは、過去数年で相次いで次世代CPUマイクロアーキテクチャのプランをキャンセルまたは見直し/延期した。両CPUメーカーの、CPUアーキテクチャの方向性の転換を、これほど如実に物語るものはない。
新しい方向性は『シンプルコア』だ。CPUコアをどこまでも複雑にしていくのではなく、コアはシンプルに留める。
CPU誕生以来これまで、コンピュータ向けCPUメーカーは、数年置きに、より複雑な新設計のCPUコアを投入して性能をアップさせてきた。しかし、現在、IntelとAMDとも、CPUコアをより複雑にするよりも、CPUコアの複雑度の増加は抑えて、コアを複数搭載する方向へと向かっている。IntelとAMDの場合は、すでに複雑なCPUコアを、シンプル化することはないだろう。しかし、今後のパフォーマンスは、CPUコアを複雑にすることよりも、マルチコア化で得ようとしている。つまり、“相対的”シンプルコアへと向かっている。
例えば、AMDは「K8(Athlon 64/Opteron系)」マイクロアーキテクチャの後継として、「K9」を開発していたが、これをキャンセルした。K9はおそらくアーキテクチャを拡張したリッチなCPUコアだったと推定されるが、それよりK8系コアを小幅に拡張することを選んだ。実際、AMDは2007年のK8「Revision Hound(ハウンド)」でCPUコアを拡張するが、CPUコアの複雑度はかなり抑えている。CPUコアの拡張は最小に留め、それによってクアッドコア化を可能にしたのが、Houndファミリの特徴だ。
AMDでは次の「K10」の開発も明らかに後退している。つまり、AMDもCPUコア自体をどんどん拡張していくという方向にはない。そして、その代わりにAMDが打ち出してきたのが、CPUにGPUコアを搭載するヘテロジニアス(Heterogeneous:異種混合)マルチコア化だった。
GPUコアの実態は、シンプルコアである「Programmable Shader」の集合体だ。AMDの汎用(General Purpose)CPUコアよりもずっとシンプルなShaderコアを融合させることで、より多くのコアをCPUに載せる。つまり、ヘテロジニアス化でシンプルコアのマルチコア化を加速させる。
 |
| CPU Architecture Trends(※別ウィンドウで開きます) PDF版はこちら |
●2倍の複雑度のCPUコアから2倍の数のCPUコアに
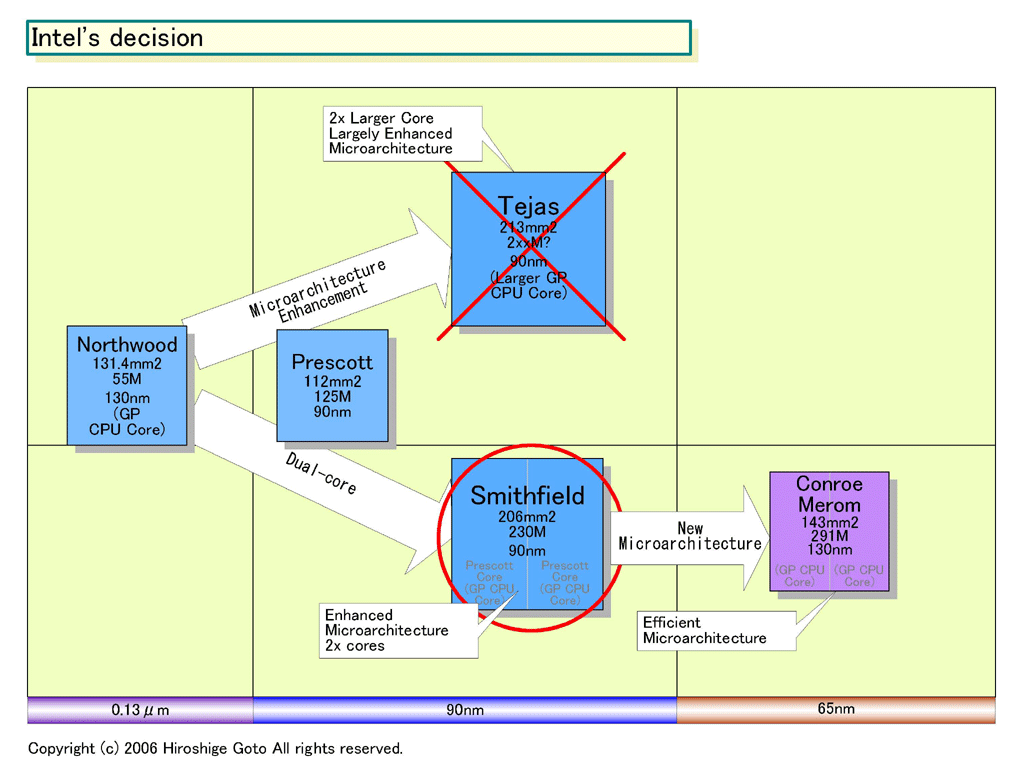
Intelのシンプルコアの方向性はAMDほどクリアではないが、それでも端々に見え隠れする。IntelもK9キャンセルと同じ頃に、NetBurst(Pentium 4)アーキテクチャを発展させたTejasをキャンセルした。Tejasは、NetBurstを抜本的に拡張したCPUで、トレースキャッシュの増量や、x86命令デコーダの階層化、Hyper-Threadingの拡張、実行ユニットの拡張といった革新を盛り込んでいたと言われる。そのため、TejasのダイはPrescott(112平方mm)の2倍近いサイズの213平方mmになる予定だった。
ところが、IntelがTejasの代わりに投入したのは、90nm版Pentium 4(Prescott:プレスコット)コアを2個、同ダイ(半導体本体)に乗せたPentium D(Smithfield:スミスフィールド)だった。Smithfieldのダイは206平方mmとほぼTejasと同程度。つまり、Tejas→Smithfieldの変更は、同じダイサイズで、2倍複雑なCPUコアのシングルコアから、2倍の数のCPUコアを載せたデュアルコアへの切り替えだった。
今回のCore Microarchitectureでは、アーキテクチャ刷新でかなりの拡張が行なわれている。しかし、AMDと同様に、CPUコアを倍々にリッチにするというペースではない。CPUのダイは143平方mmと、Intelの新マイクロアーキテクチャCPUとしては最小で、トランジスタ数は2億9,100万(291M)。複雑化はかなり注意深く抑えている。
それどころか、概算ではCPUの実行コアは、NetBurstより小さい。IntelによるとCPUの実行コアのサイズは1コアにつき36平方mmで、トランジスタ数はわずか1,900万(19M)。つまり、トランジスタの大半はキャッシュSRAMで、CPUコア自体は極めてシンプルであることがわかる。Core Microarchitectureは、コアのダイエリアが小さいことはクアッド化に向いている。ただし、オンダイでクアッドコア化する「Whitefield(ホワイトフィールド)」は別な理由からキャンセルになってしまったが。
 |
| Intelの進路決定(※別ウィンドウで開きます) PDF版はこちら |
次のNehalemも、一度アーキテクチャが根底から見直されており、同様の変更が行なわれた可能性が高い。次の次の「Gesher(ゲッシャ)」では、ラディカルにマルチコア化が促進され、またダイスタッキングなどの技術も検討されていると伝えられる。
IntelとAMDのこうした変化は、CPUコアの拡張と複雑化は、もう以前のようには続かないことを意味している。
●理論上のパフォーマンス効率ではマルチコア
「贅沢はしないで、節約しよう」
急激にマルチコアへ向かうCPUベンダーの、現在のフィロソフィを一言で説明するとこうなる。それは、Tejasのような大型のCPUコアは、非常に贅沢なシロモノだったからだ。贅沢というのは、パフォーマンス効率の面での話だ。
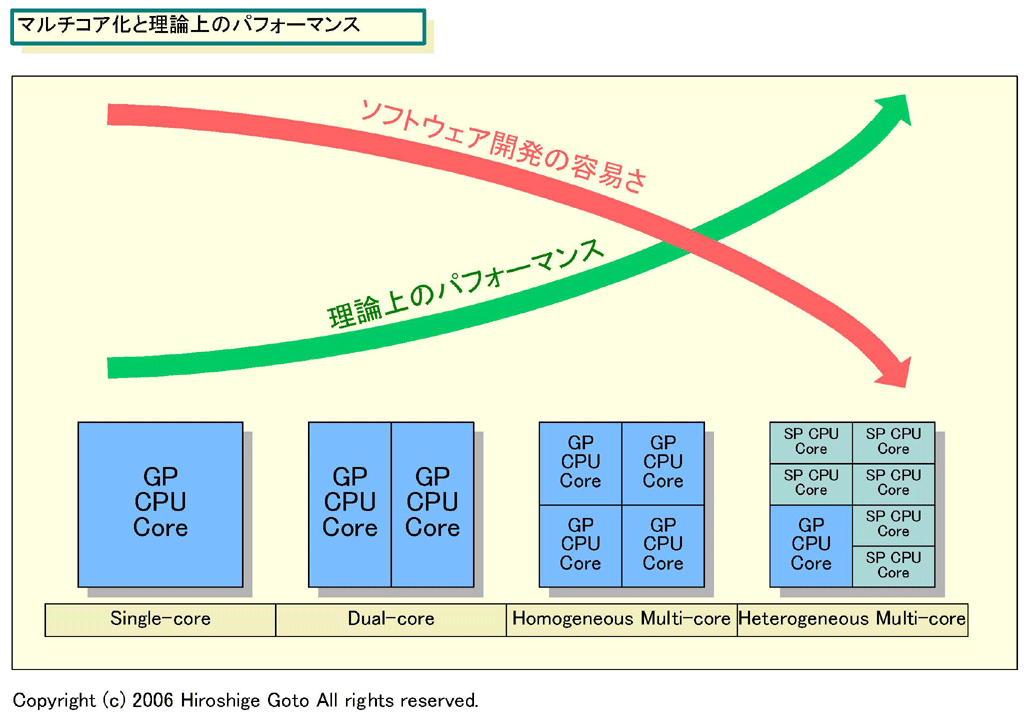
CPUの理論上のパフォーマンスは、シングルCPUコアを拡張するより、マルチコア化した方が上がる。理論値では、CPUコアを2個にすれば(パーフェクトメモリ時の)パフォーマンスは2倍になるが、シングルコアを2倍に拡張しても1.4~1.5倍程度にしかパフォーマンスはアップしない。性能効率という点では、大型で複雑なシングルコアCPUより、シンプルコアのマルチコアCPUの方がいい。
さらに、同じシンプルコアでも、アプリケーションや特定の演算に特化したコアを混載したヘテロジニアス構成の方が、よりパフォーマンス効率が高いCPUコアになる。そのため、理論上のパフォーマンス効率を考えたら、CPUはヘテロジニアスマルチコアに向かうのが自然となる。AMDのCPU+GPUや、Cellは、論理的には正しい方向にある。
 |
| マルチコア化と理論上のパフォーマンス(※別ウィンドウで開きます) PDF版はこちら |
ところが、つい最近までコンピュータ向けCPUのベンダーは、効率が悪い方法でパフォーマンスをアップしてきた。それには2つのもっともな理由があった。
(1)非効率な方法でのパフォーマンスアップが許される、半導体のスケーリングがあった。プロセスが1世代微細化すると、同サイズのチップに2倍のトランジスタの搭載、1.4倍以上の周波数アップが可能になり、それでいて消費電力は同レベルに保つことができた。だから、贅沢な方法でパフォーマンスをアップしても、それほど非効率性が目立たなかった。
(2)シングルコアを拡張した方が、同じソフトウェアがより速く走るという利点も大きかった。特に、レガシーのソフト資産が決定的に重要となるPCでは、旧来のソフトが高速化する手法の方がいい。つまり、PCに向いた、ソフト開発に優しいCPUにするには、CPUコアの拡張が一番よかった。
●非常事態でソフトウェアに負担をかける方向に
つまり、ソフト開発にインパクトを与えてまで、CPUアーキテクチャの方向を変える必要があるほど、パフォーマンス向上に困っていなかったわけだ。多少効率が悪くても、ソフト側の支持が得られるCPUアーキテクチャの方がいいと判断していたわけだ。
なのに、それがここへ来て流れが突然変わった。最大の理由は、従来型のCPU拡張ではCPUのパフォーマンスがアップしなくなったため。その原因は、半導体のスケーリングが部分的に効かなくなり、これまでと同じ調子でCPUコアを拡張すると、消費電力が跳ね上がってしまうことにあった。
CPUコアの拡張が難しくなったことで、CPUメーカーはCPUの進化の方向性を考え直さなければならなくなった。緊急の課題は、CPUコアのパフォーマンス効率のアップにある。非常事態になって、CPUベンダーは、ソフトウェアにある程度犠牲を強いてもしょうがないと判断した。
マルチコアへ向かうCPUの潮流を、非常に簡単に言うとこういうストーリーとなる。つまり、メッセージは次のようなものだ。
「会社が傾いて(=半導体スケーリングが効かなくなって)みんな(CPUメーカーは)貧乏に(=CPUのパフォーマンスを簡単に上げられなく)なっちゃった。もう贅沢(=シングルコアのパフォーマンスアップ)はやめて、倹約して(=マルチコア化で)生きよう。だから、みんな(=ソフトウェアデベロッパ)にもタダでご飯は(苦労なしのパフォーマンスアップは)上げられないよ」
ソフトウェア側にとってはいい迷惑だが、今のところ、この流れは避けられそうにない。
ちなみに、PC向けCPUよりも先に、ゲームコンソール向けCPUの方が、よりラディカルなシンプルコアへ向かったのは、ソフトウェア資産の事情からだ。ゲームコンソールでは、レガシーのソフト資産をより高速に走らせなければならないという呪縛はない。その一方で、パフォーマンス要求は高い。そのため、さっさとシンプルコア&マルチコアへと向かったわけだ。
ゲームコンソールでは、今世代のXbox 360、PLAYSTATION 3(PS3)、Wiiのいずれもシンプルコアを取る(Wiiは推定)。Xbox 360とPS3を見ていると、過去15年続いてきたアウトオブオーダ(out-of-order)型実行はもう古い、というメッセージが浮かんでくる。
●実は効率が悪いCPUのアウトオブオーダ実行化
では、実際にどれだけ従来のCPUコアの拡張は非効率だったのか。
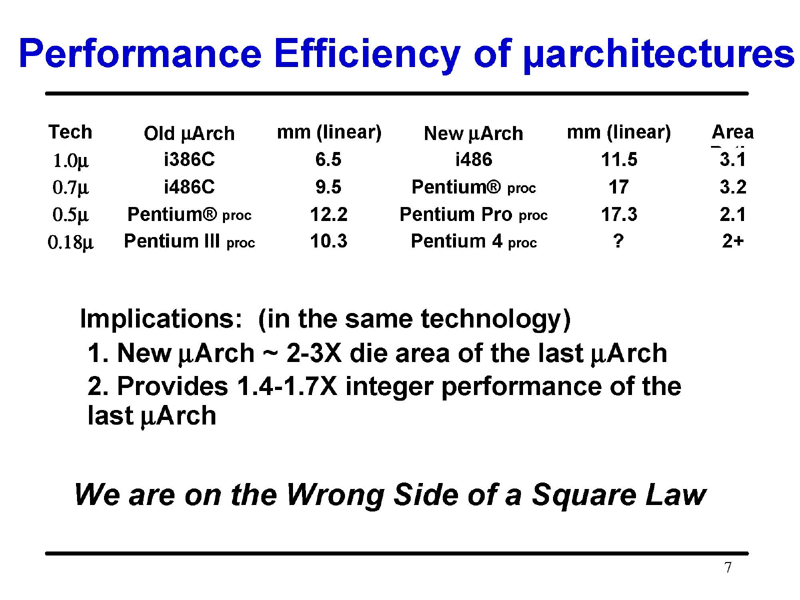
まず原則は「ポラックの法則(Pollack's Rule)」とIntelが呼ぶ経験則で示されている。前回の記事でも触れたが、同じプロセス技術では、CPUのダイサイズ(=トランジスタ数)を2~3倍に増やしても、整数演算パフォーマンスはその平方根(約1.4~1.7倍)程度にしか伸びない、という法則だ。
Intel Microprocessor Research Labs(MRL)のディレクタ兼Intel Fellowだったフレッド・ポラック(Fred Pollack)氏が、2000年頃にプロセッサ関係のカンファレンスでのプレゼンテーションで発表したものだ。i386C→i486、i486C→P5(Pentium)、Pentium→Pentium Pro、Pentium III→Pentium 4で、こうした現象が繰り返されてきたという。
 |
| ポラックの法則オリジナルプレゼンテーション(※別ウィンドウで開きます) PDF版はこちら |
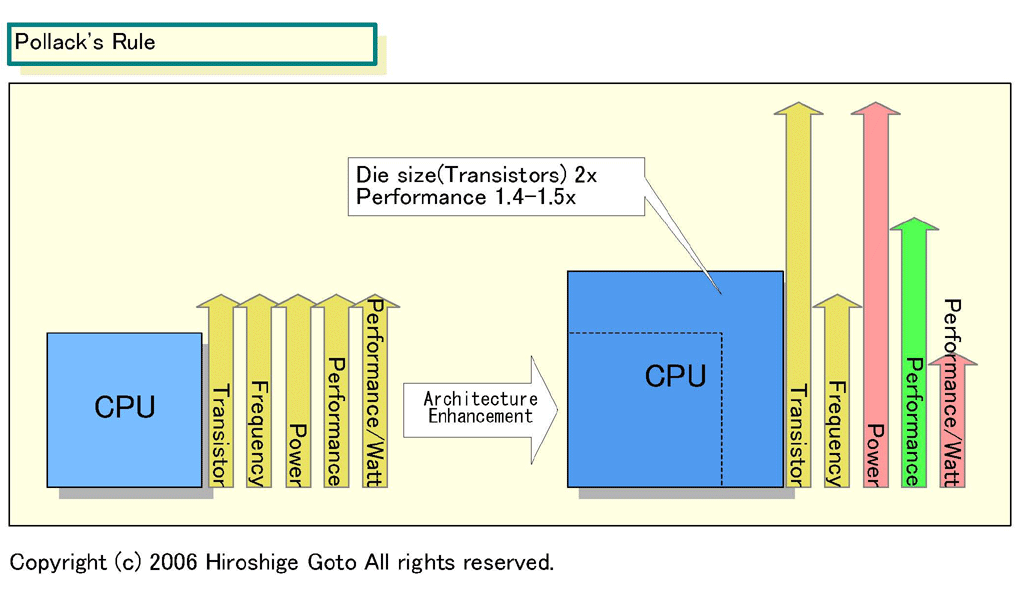
この法則を図式化すると下のようになる。2倍のダイサイズ(半導体本体の面積)に拡張したマイクロアーキテクチャのCPUは、消費電力も単純計算では2倍になる。そのため、平方根分しか性能が伸びないと、パフォーマンス/ワットとパフォーマンス/ダイは70%に悪化してしまうことになる。
 |
| ポラックの法則図解(※別ウィンドウで開きます) PDF版はこちら |
CPUコアの進化に伴うパフォーマンス効率の悪化を、CPUアーキテクチャ毎に分析した資料もある。下の図は、ISSCC(IEEE International Solid-State Circuits Conference) 2001のキーノートスピーチで、当時Intelの副社長兼CTO(Intel Architecture Group)だったPatrick P. Gelsinger(パット・P・ゲルシンガー)氏(現Senior Vice President and General Manager, Digital Enterprise Group)が示したスライドを元にしたものだ。元のスライドが見にくいのでチャートに起こしたが、基本的にはGelsinger氏のスライドと変わっていない。
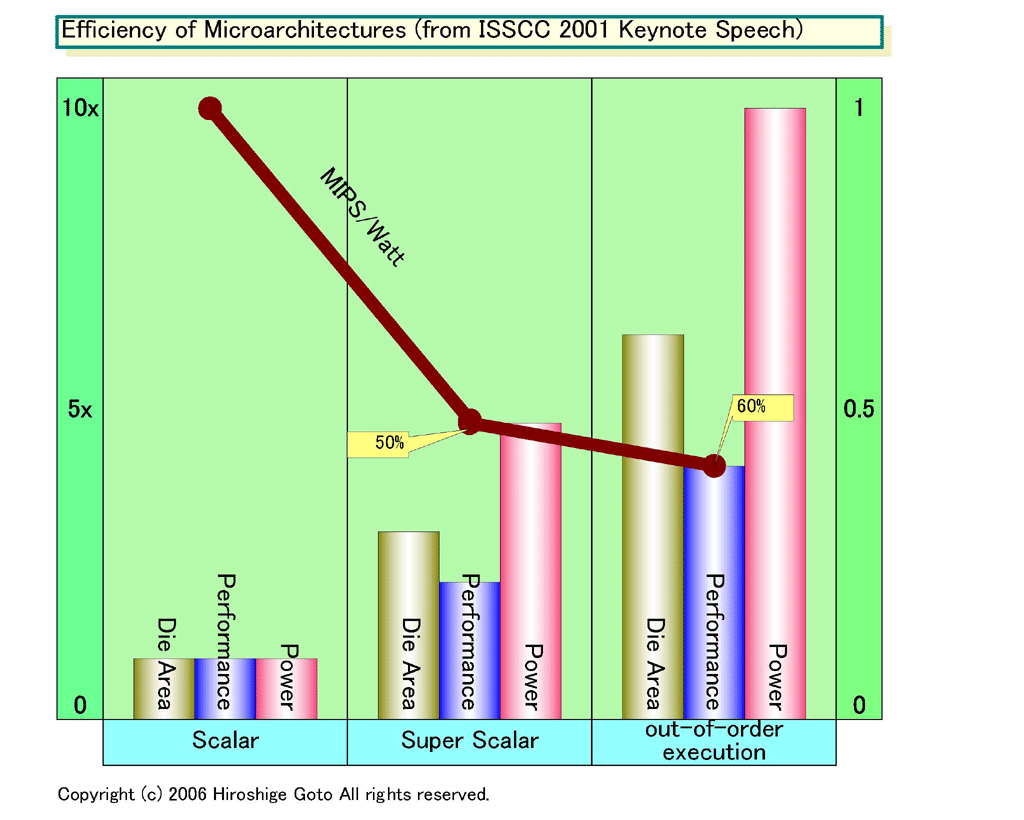 |
| アーキテクチャーによるパフォーマンス効率の変遷(※別ウィンドウで開きます) PDF版はこちら |
この図では、486までのスカラ型CPUから、Pentiumのスーパースカラ、そしてPentium Pro以降のアウトオブオーダ投機実行マシンまでを比較している。一目でわかるのは、じつは、CPUはシンプルなスカラCPUだった時が、一番効率がよかったということ。スーパースカラ化すると、絶対パフォーマンスは上がるものの効率はがくっと悪化し、アウトオブオーダ化ではさらに悪化する。Xbox 360とPS3が、いずれもアウトオブオーダを捨てた理由がよくわかる。
このチャートでは、パフォーマンスはポラックの法則よりは効率がいいが、それでも、世代毎にパフォーマンス効率が悪化することは変わりがない。重要なのはシンプルコアは効率がよく、コンプレックスコアになるほど効率が悪くなるという点だ。それだけ贅沢なパフォーマンスアップの方法を取ってきたことになる。
では、半導体のスケーリングが鈍化すると、これまでの贅沢なパフォーマンスアップはどうなるのだろう。次の回で、それをレポートしたい。
□関連記事
【8月18日】【海外】決定的となったヘテロジニアスマルチコアへの潮流
http://pc.watch.impress.co.jp/docs/2006/0818/kaigai295.htm
【8月10日】【海外】AMD+ATIの統合プロセッサの姿
http://pc.watch.impress.co.jp/docs/2006/0810/kaigai294.htm
(2006年8月21日)
[Reported by 後藤 弘茂(Hiroshige Goto)]
【PC Watchホームページ】
PC Watch編集部 pc-watch-info@impress.co.jp ご質問に対して、個別にご回答はいたしません
Copyright (c) 2006 Impress Watch Corporation, an Impress Group company. All rights reserved.