 |


■後藤弘茂のWeekly海外ニュース■AMD+ATIの統合プロセッサの姿 |
●GPUの独立か融合かが分かれ目
AMDがATI TechnologiesのGPUをCPUに統合する。その目的は、もちろんグラフィックスだけではない。GPUコアを使って、より広汎なプロセッシングを行なうところにポイントがあると考えられる。
こうした動きは、GPU業界全体の潮流で「GPGPU(General Purpose GPU)」と呼ばれている。ただし、“GP(General-Purpose:汎用)”と言っても、本当にCPUのような汎用的なコンピューティングをGPUにやらせるというわけではない。物理シミュレーションのような、GPUアーキテクチャに比較的向いた特定用途のコンピューティングをやらせる方向だ。
つまり、GPGPUというのは、GPUにグラフィックスだけでなく、“より汎用的”な処理をやらせようという動きで、いわゆる汎用CPUの領域までカバーするという話ではない。その意味では、“非グラフィックスコンピューティング”と呼ぶのが正しいだろう。だからこそ、AMDの汎用CPUコアと補完関係になるというわけだ。
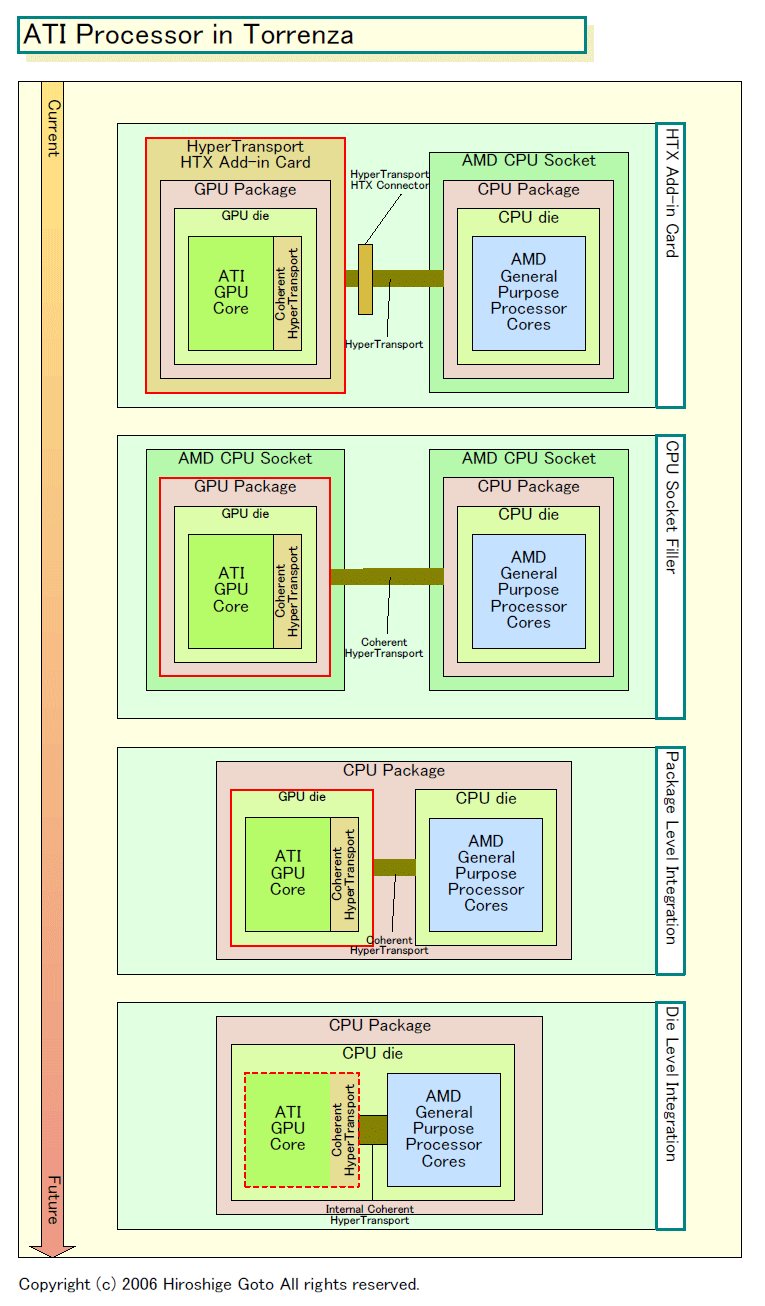 |
| ATI Processor in Torrenza(※別ウィンドウで開きます) PDF版はこちら |
では、GPGPUを主眼に考えたAMDは、ATIのGPUをどうやって統合するつもりなのだろう。
GPUコア統合の方法にはさまざまなパターンが考えられるが、大きく分けると2つの方向に分けられる。(1)GPUを現行のままのマイクロアーキテクチャで統合する方法と、(2)GPUのパーツを分解してCPUに融合させる方法だ。言ってみれば、前者は『GPUそのまま方式』、後者は『Cellプロセッサライク方式』となる。もちろん、この2つの中間解もありうるが、方向性としては大きくこの2つだろう。
前者のGPUそのまま方式の場合、話は簡単で、Unified-Shader型GPUをそのままCPUに取り込んでしまう。CPUコアやI/Oとの間は、クロスバースイッチで結び、メモリはCPUとメモリコントローラを共有する。CPUからコマンドストリームをGPUコアに送ると、GPU側でそれを演算ユニットである個々のShaderに割り振って処理する。
GPUコアの中のShaderユニット群の制御は、シェーダスケジューラが担当する。個々のShaderユニットは、CPUから直接制御されることはない。CPUから見れば一種のブラックボックスだ。この方式なら、CPU側からは、外付けのGPUとほぼ同じように見えるはずだ。
しかし、後者のCellライク方式を取る場合は、話が異なってくる。GPUは分解され、各Shaderユニットがクロスバーあるいはリングバスなど内部バスに直結される。各Shaderユニットは、半ば独立したCPUコアのような扱いになる。
そのため、各Shaderの制御は、汎用CPUコア上で走るシェーダスケジューラソフトウェアが行なう。CPUが直接Shaderコアを制御する形で、GPU内部がある程度隠蔽されている前者とは制御が大きく変わる。
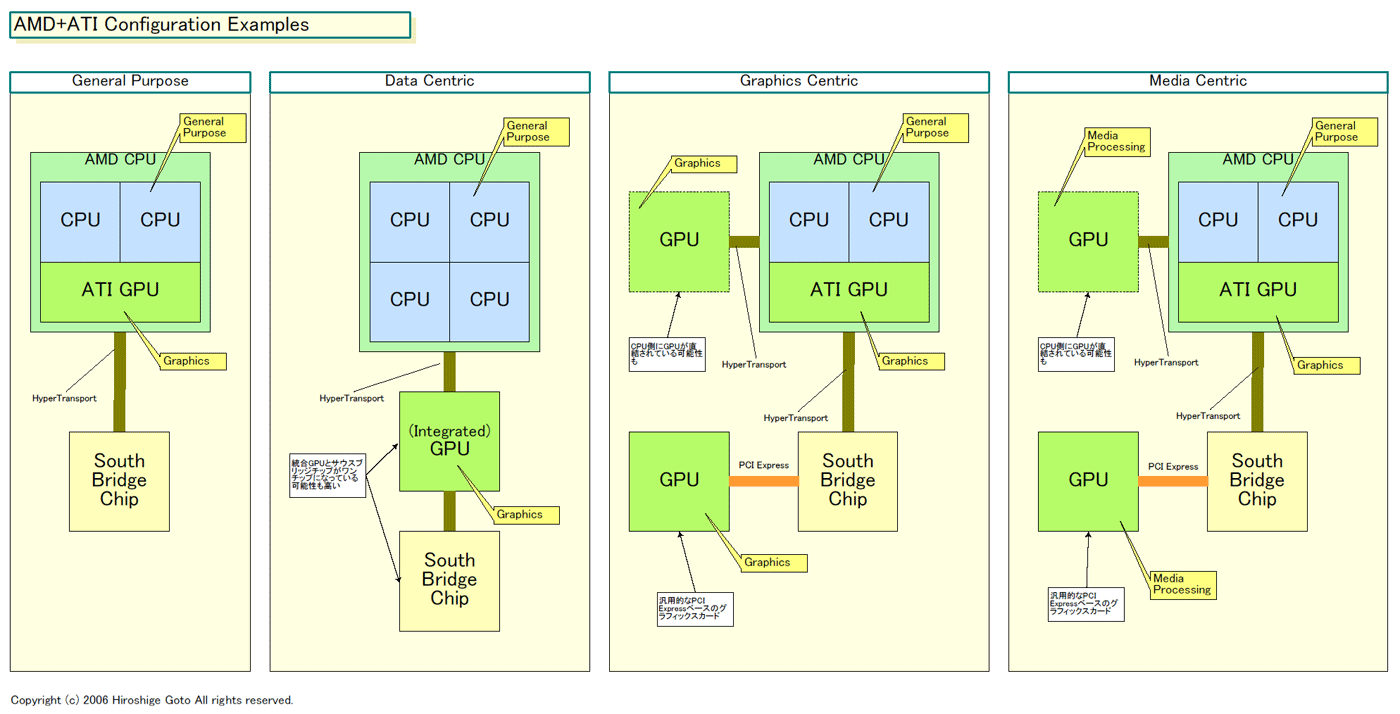 |
| AMD+ATI Configuration Examples(※別ウィンドウで開きます) PDF版はこちら |
●GPUの経験をそのまま持ち込める“そのまま”方式
両方式にはそれぞれ利点と難点がある。まず、前者のGPUそのまま方式の場合、現在のGPUマイクロアーキテクチャからの変更が最小で済むため、コアの開発に時間がかからない。ソフトウェアモデルも、現在のGPUのモデルをほぼそのまま踏襲できるので、手間がかからず、リスクも小さい。個々のShaderユニット自体のアーキテクチャも変更が小さくて済む。単体GPUと同じアーキテクチャなので、グラフィックスの性能も予想がしやすい。
その一方で、この形ではGPU型のShader制御に縛られるため、いわゆるGPGPU的な処理ではロスが大きくなることが想定される。少なくとも、現状のShaderのスケジューリングは、グラフィックスに特化しており、そのためGPGPUアプリケーションの種類によっては、Shaderの演算性能を活かし切ることができない。
例えば、GPUではピクセルまたは頂点をある程度の粒度のバッチ「スレッド」にまとめて、それをShader群に割り当て、各ピクセルまたは頂点を順番に処理させている。GPUでは、この粒度が高いため、例えば条件分岐などが多いと効率的に処理することが難しいケースがある。ATI系は粒度が小さい方だが、本格的にGPGPUを行なうには、Shaderをもっと柔軟に制御できるようにする方が望ましい。
ラフに言ってしまうと、GPUそのまま方式は、比較的グラフィックス向きの統合方式で、GPGPUに最適とは行かない可能性がある。
●GPGPUで効果が大きいCellライク方式
後者のCellライク方式は、それとは全く逆のトレードオフとなる。Cellライク方式と名付けたのは、構造的にCellに似ているからだ。Cellでは、汎用プロセッサコア「PPE(Power Processor Element)」が、多数のデータ演算向けプロセッサ「SPE(Synergistic Processor Element)」を管理する。後者のケースでは、汎用CPUコアがPPEの役割を、ShaderコアがSPEの役割を果たすことになる。
利点は、Shaderを個々に制御することで、よりGPGPUに最適化しやすい点だ。Shaderの制御は、フルにソフトウェアで行なうため、アプリケーションに合わせて柔軟に変更しやすい。完全にShaderを個別制御できれば、Shaderのプロセッシング性能を最大に発揮させることができる。特に、ShaderユニットのネイティブISA(命令セットアーキテクチャ)を公開して、CellのSPEのようにプログラミングできるようにすれば、ぎりぎりまで性能を活かすことができる。
その反面、ハードルは高い。まず、高スループットが要求されるグラフィックス処理で性能を発揮させることが難しくなる。これは、GPUの歴史で何度も繰り返されてきた。スループットが重要なGPUでは、ある程度固定的なパイプラインの方が性能を上げやすい。それを大きく崩すと、制御が複雑になり、思わぬ性能低下をもたらすことになる。NVIDIAはGeForce FX 5800(NV30)の際に、この問題で苦しみ、その結果、Unified-Shader化に慎重になっている。ShaderをCPUに溶け込ませるとなると、さらにハードルは高くなる。
また、Shaderユニット自体の内部アーキテクチャも大きく変更しなくてはならないため、開発にかなり時間もかかる。ソフトウェア構造も変わってしまうため、既存のGPUとのドライバレベルの互換性を取ることが難しい。GPUのネイティブISAを公開するなら、ISAを今後互換に保つ必要も出てくる。
ラフに言ってしまうと、Cellライク方式はGPGPUに向いているが、GPUとしては難しいアプローチだ。
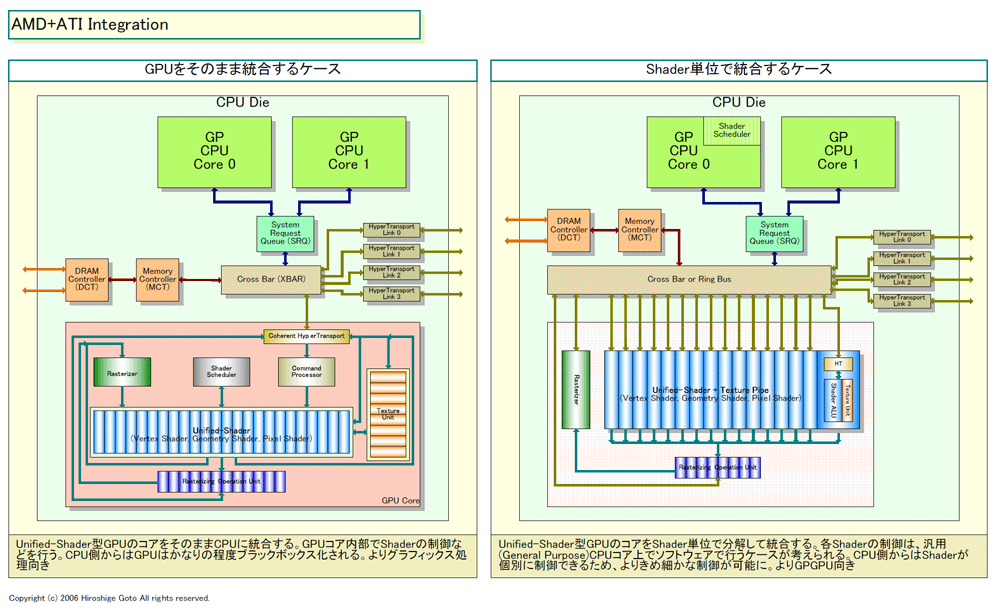 |
| AMD+ATI Integration(※別ウィンドウで開きます) PDF版はこちら |
●最初のステップはおそらくGPUアーキテクチャを踏襲
AMDのこれまでのコプロセッサについての説明を聞いている限りでは、AMDはできるだけ余計な開発リソースをかけずに統合しようとしているように聞こえる。だとすれば、最初は、GPUそのままに近い形で統合する可能性が高い。AMDの開発リソースや、厳しい開発期間を考えると、それが現実的でリスクも小さい。
また、GPUをそのまま統合するなら、まず別ダイ(半導体本体)で作って、オンパッケージで統合し、その次にオンダイ(半導体上)で統合するというステップも踏みやすい。当初は、GPGPU的な使い方は限られていてグラフィックス中心と考えるなら、これが穏当だろう。
しかし、その先、2010年以降となると、違ったストーリーになる。AMD+ATIは、より密接なCellライクなCPUとGPUの統合へと向かっていく可能性もある。GPGPU的な使い方が進むと、よりフレキシブルな構造がGPUコアにも求められるようになる。また、より多くのシリコンリソースが使えるようになるため、プログラム性の高いアーキテクチャを取っても十分なパフォーマンスを得ることもできるようになる。
AMDがどういった手法を採るにせよ、長期的には統合GPUコアの姿は変わって行くだろう。Cellライクに完全に統合されないとしても、GPUコア内部は、よりGPGPUにも適用しやすい姿になると推定される。実際に、APIでGPUの進化をけん引するMicrosoftも、そのあたりに思惑があるようで、よりGPGPUに向いた方向へと押している。
●Shaderが数GHzで動く時代が来る
この先、CPUとGPUの統合の結果が顕著に現れてくるのは、おそらくGPUコアの高クロック化だ。CPUベンダーの、より進んだプロセス技術や回路設計技術を使えるようになることは、高速化への影響が大きい。さらに、統合化が進めばアーキテクチャ的にも高クロック化を図りやすくなる。Shaderが数GHzで動作する日もそう遠くはないかもしれない。実際、CellのSPEは3.2GHzで動作している。
最初のステップで、GPUコアをそのまま統合する場合には、CPUコアとGPUコアのクロックドメインは分離することになるだろう。汎用CPUコアは高クロック動作にパイプラインが最適化されているが、GPUコア全体を高クロック動作に最適化設計するのは当面は難しいからだ。そのため、当面は、CPUコアの数分の1のクロックでGPUコアを走らせることになると推定される。CPUコアが2.xGHz時に、GPUコアが700MHzといった具合だ。
しかし、将来的にはShader部分をより高速に走らせることも可能になる。GPUがCPUほど速く走らせることができない理由はさまざまだが、アーキテクチャ的には固定機能部分が高クロック化の障害になると言われる。しかし、Unified-Shader化が進むと、Shaderコア部分は他の固定機能ユニットとは分離される。あるGPU業界関係者は、Shaderアレイのクロックドメインを分離して、他のユニットの倍速などのクロックで動作させることが可能になると語っていた。
もし、Shaderが完全にCPUに溶け込んで、CPUの演算コアと同速で動くようになれば、性能上の利点は大きい。現在のGPUは、ベクタ演算の並列度は高くても動作クロックが低いために、ダイサイズ(半導体本体の面積)の割に演算パフォーマンスは低い。だが、最高2.xGHzや3.2GHzでShaderが動作するようになれば、より少ないShader数でも高パフォーマンスが得られるようになる。
●Shaderが成熟すれば高クロックへのチューンも可能に
もっとも、Shaderを完全にCPUコアと同速で走らせるためには、Shaderの設計をかなりチューンする必要がある。あるCPU関係者は、GPUはスタンダードなASICプロセスで作られているため高速化が難しいと指摘する。NVIDIAのDavid B. Kirk(デビッド・B・カーク)氏(Chief Scientist)は、数年前、その理由について「カスタム設計でチューンすれば、(GPUが)もっと高速になるのは確かだ。問題は設計に時間がかかることだ。例えば、IntelなどのCPUでは、アーキテクチャデザイナが仕事を終えてから、約1~2年もトランジスタチューニングに時間をかけている。同じことをGPUでしたら、2002年に、2GHzのTNT2を出すことになる」と語っていた。従来のGPUの短い開発サイクルでは、そうしたチューンは難しかったわけだ。
しかし、GPUがプログラマブルなプロセッサとしてある程度成熟して来ると、Shader設計にもっと長期サイクルで臨むことが可能になって来るかもしれない。以前のGPUは、フィーチャーはハードウェアで加えていたため、短サイクルの開発が重要だった。しかし、これからのGPUは、新フィーチャはShader上のソフトウェアで実現する。そのために、Shaderをできるだけフレキシブルで汎用に作り替えようとしている。そして、GPU性能は、Shaderの高速化にかかるようになりつつある。
現在は、まだGPUは内部アーキテクチャを大きく変える移行期にあり、設計がなかなか成熟しない。しかし、GPUがより汎用的なアーキテクチャに変わって行くと、設計に時間をかけ、高クロックにチューンしても見合うようになる。逆を言えば、そういったサイクルにならないと、CPUにShaderを完全に溶け込ませることは難しいだろう。開発サイクルが異なるコアは、完全に分離しておいた方が都合がいい。
GPGPUを視野にCPUとGPUの統合を目指すAMD。この2つのプロセッサの統合には、利点が多い。とはいえ、CPUとGPUの統合には、多くのハードルも待っている。例えば、メモリ帯域とShaderマイクロアーキテクチャ、そしてプログラミングモデルなどの問題を、AMDとATIは片付ける必要がある。
□関連記事
【8月2日】【海外】AMDがATIのGPUを選んだ理由
http://pc.watch.impress.co.jp/docs/2006/0802/kaigai293.htm
【7月27日】【海外】正反対の方法論で対決するATIとNVIDIA
http://pc.watch.impress.co.jp/docs/2006/0727/kaigai291.htm
【7月25日】【海外】AMDとATIのプロセッサは1つに融合する
http://pc.watch.impress.co.jp/docs/2006/0725/kaigai290.htm
(2006年8月10日)
[Reported by 後藤 弘茂(Hiroshige Goto)]
【PC Watchホームページ】
PC Watch編集部 pc-watch-info@impress.co.jp ご質問に対して、個別にご回答はいたしません
Copyright (c) 2006 Impress Watch Corporation, an Impress Group company. All rights reserved.