 |


■元麻布春男の週刊PCホットライン■AMDが2008年以降のロードマップを公開 |
2006年6月1日(日本時間6月2日午前0時30分)、AMDは金融関係者向けのイベントであるアナリストデイを開催した。多くの企業同様、年に2回、春と秋に開催されるが、AMD本社のあるSanta Claraで開催される春のアナリストデイは、テクノロジーアナリスト向けであるため、Technology Analyst Dayと称されている(New Yorkの秋は一般アナリスト向け)。
登壇した主なエグゼクティブは、Hector Ruiz CEOを筆頭に、Dirk Meyer社長兼COO、Daryl Ostrander副社長(製造部門担当)、Phil Hester副社長兼CTO、Joe Menard副社長(コンシューマー担当)、Marty Seyer副社長(コマーシャル担当)の6人。Ruiz CEOとMeyer COOの2人を除いた4人が、それぞれの担当事業についてプレゼンテーションをまじえたスピーチを行なった。ここではQ&Aを含めて4時間近い内容の概要を紹介することにする。
●Fab 38立ち上げで生産能力を強化
 |
| ドレスデンのFab 30/38とFab 36。Fab 36が隣接して設けられたことで、従来のような旧式化した工場をフラッシュ用に転用する計画ではないことがうかがい知れた |
まず最初の話題は、製造技術に関するものだ。先日AMDは20億ドルを投じて、ドレスデンのFab 30を、同社2番目の300mmウェハ工場となるFab 38に転換する計画を発表した。現在AMDは、Fab 30で200mmウェハを用いた90nmプロセスによる量産を、隣接するFab 36で300mmウェハを用いた90nmプロセスによる量産を、それぞれ行なっている。2006年の第4四半期から65nmプロセスによる量産がFab 36でスタートし、2007年7月には全量65nmプロセスへ移行する予定だ。
このFab 36の立ち上げと平行してFab 30の転換作業を行ない、2008年第1四半期にはFab 38における最初のウェハの生産がスタートできるとしている。2つの工場を隣接させたことで、立ち上げ時間を短縮することが可能になった。
加えて、Fab 36の生産能力を現在の2万枚/月から2万5千万枚/月(いずれも300mmウェハ換算)に拡張する。これにより、ドレスデンにおける製造能力は、Fab 38が完全に立ち上がる2009年には現在の4倍になる見込みだという。これに生産委託先であるシンガポールのChartered Secmiconductorの生産分を含めると、AMDは2008年時点で市場の3分の1を供給可能なキャパシティを手にする。
65nm以降の製造プロセスについては、現在IBMとの共同開発が順調に進んでおり、2008年半ばには45nmプロセスの導入が可能だとしている。65nmプロセスについては、工場の立ち上げと重なったこともあり、Intelからほぼ1年遅れの導入となったが、計画通り45nmプロセスの導入ができれば、その差が約半分に短縮されることになる。
●モジュラー化が進む次世代アーキテクチャ
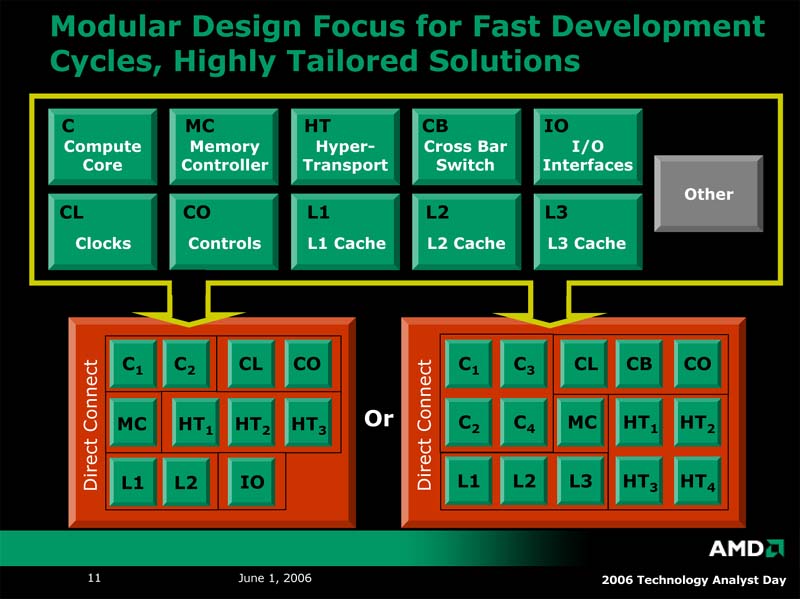
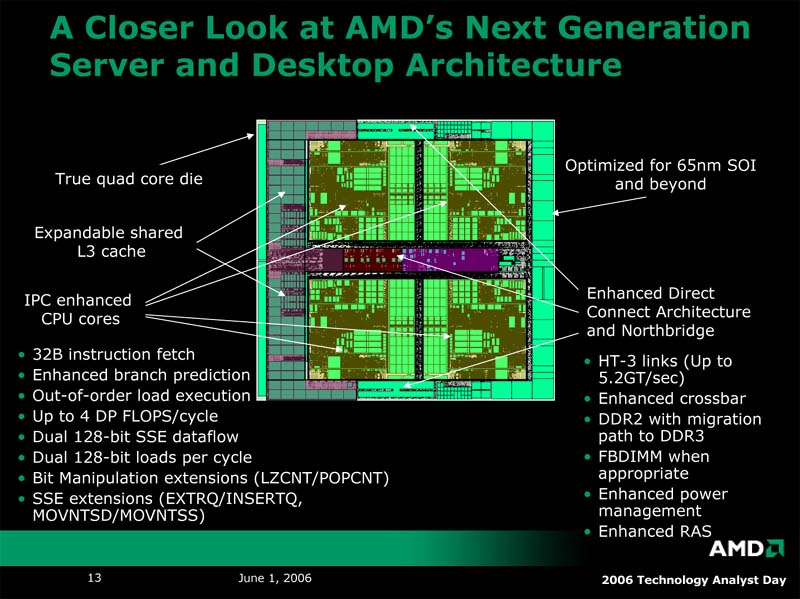
マイクロアーキテクチャに関しては、まず内部構造のモジュラー化について紹介された。プロセッサを構成する各パート、演算コア、メモリコントローラ、キャッシュメモリ、各種インターコネクトをモジュラー化し、それぞれのセグメントにふさわしい構成を採用可能にする。同様の構想はIntelもUncoreアーキテクチャということで明らかにしており、マルチコア時代の標準的な構成ということなのだろう。今回公開された次世代のクワッドコアプロセッサ(デスクトップおよびサーバー向け)の写真でも、きれいにブロックが並んでいる様子がうかがえる。
 |
 |
 |
| モジュラー化するプロセッサの構成。必要に応じて最適なコア数やメモリコントローラ、HyperTransportリンク数などを選択する | デスクトップとサーバに用いられる次世代クワッドコアプロセッサ。共有されるL3キャッシュは拡張が容易なよう左側に寄せられている | 共有されるL3キャッシュは2MB以上。ただしこの図からはキャッシュがExclusiveかどうかを判断することはできない |
一方、モバイル向けのプロセッサでは、
・プロセッサコアと内蔵ノースブリッジの電源プレーン分離
・モバイル用途に最適化されたNorthbridgeの採用
・リンクパワーマネージメント機能を備えたHyperTransport 3
など省電力が優先されているようだ。また、Q&AではULV版提供の予定があることも明らかにされている。
もちろん省電力は、今やモバイルだけの問題ではない。Intelは、Coreマイクロアーキテクチャのプロセッサをリリースすることで、AMDとの間にあった1Wあたりの性能で追いつく、あるいは逆転することを狙っている。これに対してAMDは、サーバーについてはFB-DIMMの消費電力が大きいことにより、プラットフォーム全体を見れば、AMDの方がまだ有利だとしている。ただ、この比較はいずれも正式にリリースされていない製品間のものであり、この通りに行くのか、比較条件がどうなっているのか、必ずしも明らかではない。
 |
 |
| 2007年に登場すると見られる次世代のモバイル向けデュアルコアプロセッサ | AMDによるDPサーバーの消費電力比較。FB-DIMMの消費電力の高さがやり玉に挙げられているが、AMDも将来の採用を明らかにしている |
 |
 |
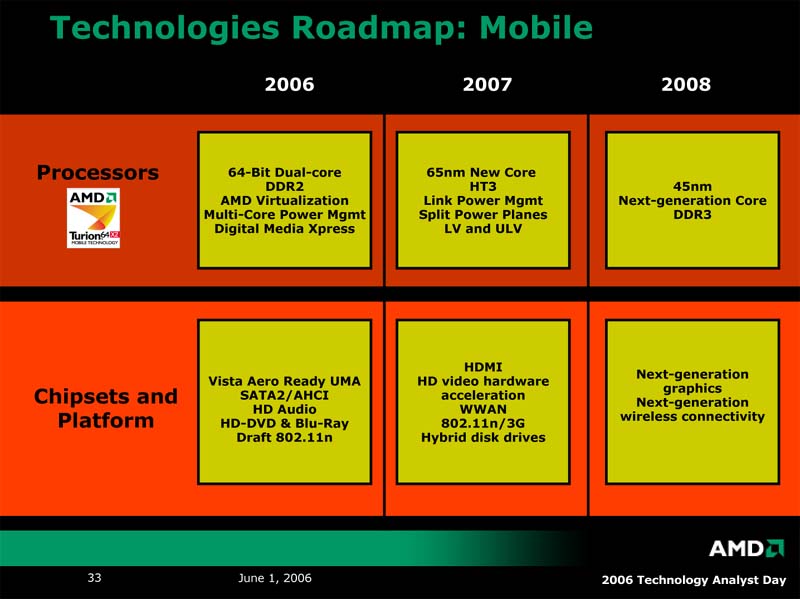 |
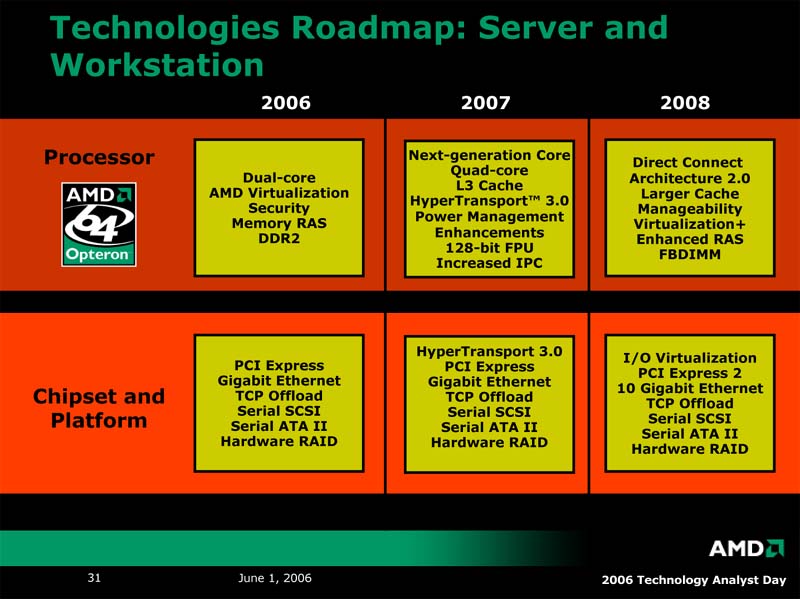
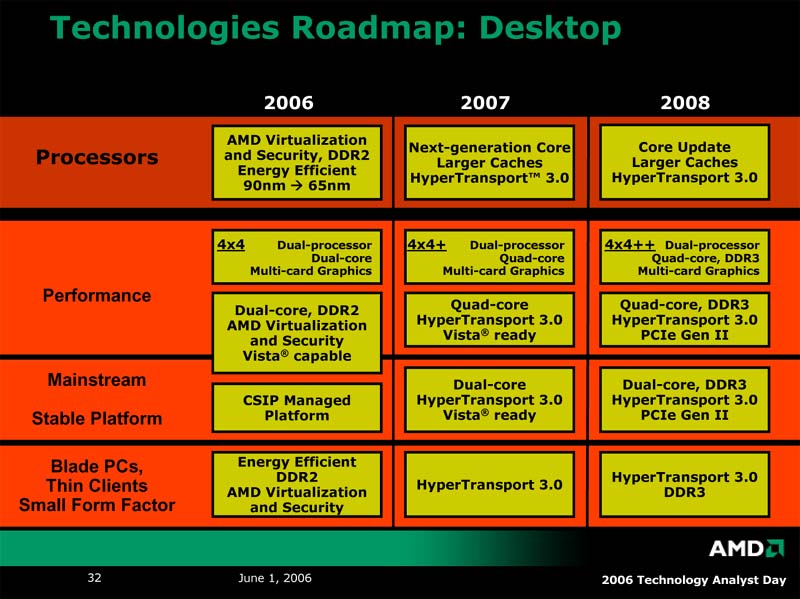
| サーバー/ワークステーションロードマップ | デスクトップロードマップ | モバイルロードマップ。2008~2009年のタイムフレームでは、さらにモバイルに特価したプロセッサを投入するという |
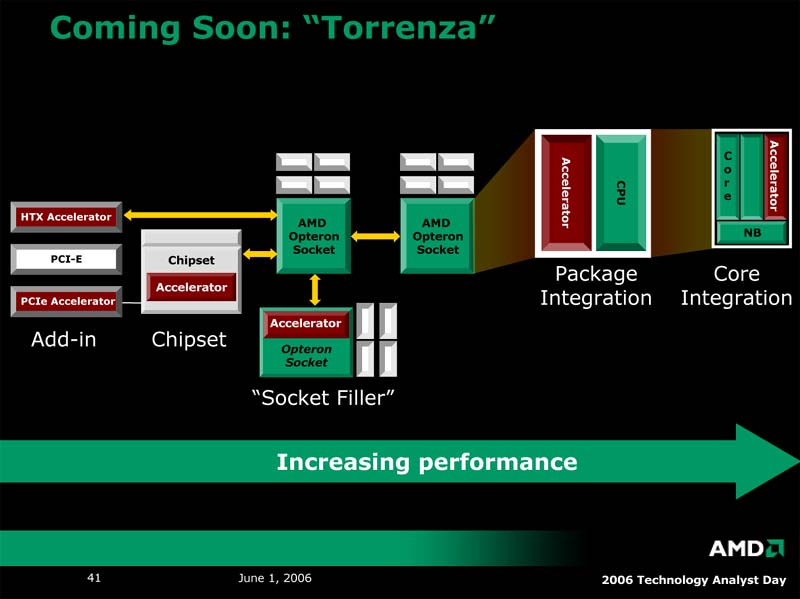
●専用コプロセッサをシステムに付与する「Torrenza」
今回のアナリストミーティングで、AMDはいくつかのプラットフォーム技術を発表した。従来、「Pacifica」という名前で知られていた仮想化技術の次世代版となる「Trinity」、HPのブレードPC(データセンターのブレードサーバーに単純な端末を接続することでTCOの改善やセキュリティの強化を図る)に仮想化技術を組み合わせた一種のシンクライアント技術である「Raiden」、そして専用コプロセッサをシステムに付与する「Torrenza」である。中でも最も興味深いTorrenzaについて、若干紹介しておこう。
Torrenzaは、特定の目的を持ったコプロセッサを、AMD64アーキテクチャのプロセッサに付与するものである。付与する形態は、コア内での統合、マルチチップによるパッケージ内での統合、HyperTransportやPCI Expressスロットを介した外部接続、の3つが考えられている。
中でも注目されるのが、専用の拡張スロットを用いる外部接続だ。HyperTransportに準拠したHTXスロットに、専用コプロセッサ搭載の拡張カードを実装する形式は、最も実現時期が早いものとして紹介された。用いるコプロセッサとしては、JavaやXMLのアクセラレータ、あるいはメディアプロセッサ、さらにはゲーム業界で注目されているPhysXのような物理演算アクセラレータなどが挙げられている。
 |
 |
 |
| AMDの技術ロードマップ | システムに専用コプロセッサを付与するTorrenza。実装する場所はさまざまなところが提案されているが、CPUに近づけば近づくほど性能向上が期待できる | HyperTransportの外部スロットHTX |
会場でのQ&Aセッションでは、過去のWeitekなどを引き合いに出して、このようなコプロセッサは、一時的には成功しても、歴史的には成功していない、との質問が出された。もちろんこれは、成功するほどのコプロセッサなら、ムーアの法則によりその機能がプロセッサ内部に取り込まれてしまうことを意味している。AMDは、Weitekやかつのて数値演算コプロセッサのように汎用性の高いものは、その通りかもしれないが、目的が絞られた専用プロセッサはアドオンとなる可能性があるのではないかと答えた。
実はIntelも、省電力の観点から専用プロセッサをダイ上に統合するアイデアを数年前のIDFで公開している。が、ダイ上の統合やパッケージ内の統合では、専用プロセッサの供給元はプロセッサメーカーに限られてしまう。HTXスロットのユニークな点は、Hyper-Transportに対応したものであれば、サードパーティ製のコプロセッサを利用することが可能な点にある。
●HTXスロットは受け入れられるか
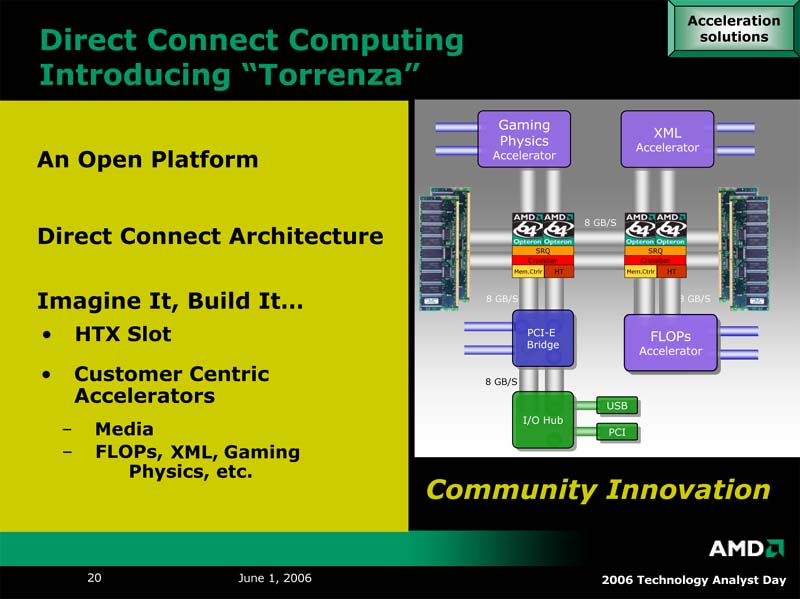 |
| 実装場所はさまざまだが、本命は明らかにHyperTransportによる外部接続(と拡張スロットの提供)だろう。いきなり汎用の拡張スロットというと「波風」も考えられるため、コプロセッサスロットという形で提案したのかもしれない |
しかし、こう考えると、HTXスロットと汎用の拡張スロット、特に高性能スロットであるPCI Express x16やx8のスロットとHTXスロットが競合する可能性を秘めていることに気づく。もしAMDのいうようにHTXスロットが高性能なのであれば、グラフィックスカードをPCI Express x16よりHTXスロットに使った方が良いのではないか、という意見が当然出てくるハズだ。
AMDは、HyperTransportを最初にリリースした時点から、拡張スロットを用意する構想を持っていたと言われている。それができなかったのは、当時のAMDの市場シェアや政治力の問題からだったと思われる。2005年、AMDはシェアを高めたことにより、自社仕様の拡張スロットを提唱できるだけの力を備えた、ということなのだろう。PCI ExpressがもともとIntelが開発したものであることを考えれば、AMDが自社仕様のスロットが欲しいと考えてもそれほど不思議はない。
x86アーキテクチャの64bit拡張ではかろうじて1つの舟に乗ったAMDとIntelだが、すでに仮想化技術ではそれぞれが独自の道を歩んでいる。果たして拡張スロットやそのほかの技術でも、両社が袂を分かつことになるのか、HTXの受け入れられ方が気になるところだ。
□2006 Technology Analyst Day(英文)
http://www.amd.com/us-en/Corporate/InvestorRelations/0,,51_306_14047,00.html
□関連記事
【6月1日】【海外】拡大が進むAMDのコプロセッサ構想
http://pc.watch.impress.co.jp/docs/2006/0601/kaigai275.htm
【5月31日】【海外】Rev. Fの次の次に来るAMDの次世代コア「Hound」
http://pc.watch.impress.co.jp/docs/2006/0531/kaigai273.htm
【5月30日】AMD、Fab 30を300mmウェハに拡張し「Fab 38」に名称変更
http://pc.watch.impress.co.jp/docs/2006/0530/amd.htm
(2006年6月2日)
[Reported by 元麻布春男]
【PC Watchホームページ】
PC Watch編集部 pc-watch-info@impress.co.jp ご質問に対して、個別にご回答はいたしません
Copyright (c) 2006 Impress Watch Corporation, an Impress Group company. All rights reserved.