 |


■槻ノ木隆のPC実験室■新しくなったScanSnap! fi-5110EOX |
●fi-4110EOX3での格闘
以前、このコラムで、2002年9月にPFUから発売された「ScanSnap! fi-4110EOX2」のレビューをお届けした。
その後ドライバがマイナーバージョンアップされると共に、同梱されるソフトウェアがAdobe Acrobat 5.0からAdobe Acrobat 6.0 Standardにアップグレードされた「fi-4110EOX3」が発売された。この製品については、スタパ斎藤氏がレビューを書いていて、それをまとめると、
・Acrobatが6.0になって、物凄く使いやすくなった
・PDF Thumbnail Viewが搭載され、縮小表示ができるようになった
・用紙選択にリーガル/レター/自由サイズが追加された
 |
| 【写真1】よくもココまでスキャンしたというべきか…… |
というあたりが主な改善点である。このうちAcrobat 6.0に関しては、ScanSnap!のバージョンアップというわけではないのだが、筆者的にはページの移動や指定などに、ページビューを使って直接操作できるようになったことを高く評価しておきたい。
一方Thumbnail Viewに関しては、Windows 2000をメインで使っている筆者にはあまり関係なしというか、後述するがとにかく筆者の環境では割と非現実的だったので割愛。用紙選択については、これはもう素直に嬉しかった。なにせ(海外取材の際に持ってくる)レターサイズのドキュメントが結構あるからで、これをちゃんと認識してくれるだけでかなり嬉しいといったところである。
で、筆者もこれを結構使った。昨年10月頃に届いてから、最初の1カ月ほどでスキャン枚数は10,000枚を(写真1)、スキャンし終わった紙の束は1mを超え(写真2、3)、本棚はガラッと空いた(写真4)。その分、資料ディレクトリは8GBものサイズに膨れ上がるといった具合だが、お陰で雑誌類を除いた紙の資料はほぼ完全に電子化が完了した。
 |
 |
 |
| 【写真2】スキャン後の書類。NDAとかのヤバイものを除き、基本的には資源ごみとして捨てたが、捨てに行くのも一苦労だった | 【写真3】どちらの山もこの通り50cmを超えており、積み重ねると1m超えとなる | 【写真4】すっきりと空いた(?)本棚。もっとも今ではまた埋まっているのだが…… |
さて、こうなるとむしろ面倒なのは情報の検索である。先に「PDF Thumbnail Viewが非現実的」なんて話をしたのは、この7,000を超えるPDFファイルを、先頭ページのサムネイルだけで管理するのが土台無茶、というあたりに起因する。これだけの分量だと、目で見るとかそういうレベルではない。結果として、
・ディレクトリ名で会社名、ファイル名で内容をそれぞれ判るように記載する
・それで不足する場合、Adobe Acrobatの検索を利用する
という方法を使うことにした。Adobe Acrobatの検索は、6.0になって「保護されたPDF文章の中」まで検索できるようになり、随分使い勝手が上がっている。が、実際にやってみると、これまた時間がかかる。試しに検索をかけてみると、40分かけてもまだ半分位しか検索できていない有様で、恐ろしく効率が悪い。
 |
 |
| 【写真5】F:はファイルサーバーのドライブ。とはいえGigabit Ethernetで接続しているので、ローカルHDD並みに高速だが | 【写真6】40分を過ぎた辺りでいい加減待っていられなくなり、検索を中断。放っておけば2時間くらい検索をやっていそうだ |
そこで考えたのは、Namazuを使った全文検索エンジンの導入だ。幸い手頃なマシンもあるし、環境的には揃っている。問題は、メーカーなどからダウンロードしたPDFファイルはテキスト情報が含まれているが、ScanSnap!で取り込んだPDFファイルは画像イメージとして認識されることだ。
このままではNamazuでの検索が不可能なので、どこかでテキスト情報に変換してやる必要がある。ScanSnap!にも「名刺ファイリングOCR」なるOCRが付属しているが、こちらは名刺を読み込んでテキストにするツールだから、ちょっと今回の目的には使い勝手が悪い。
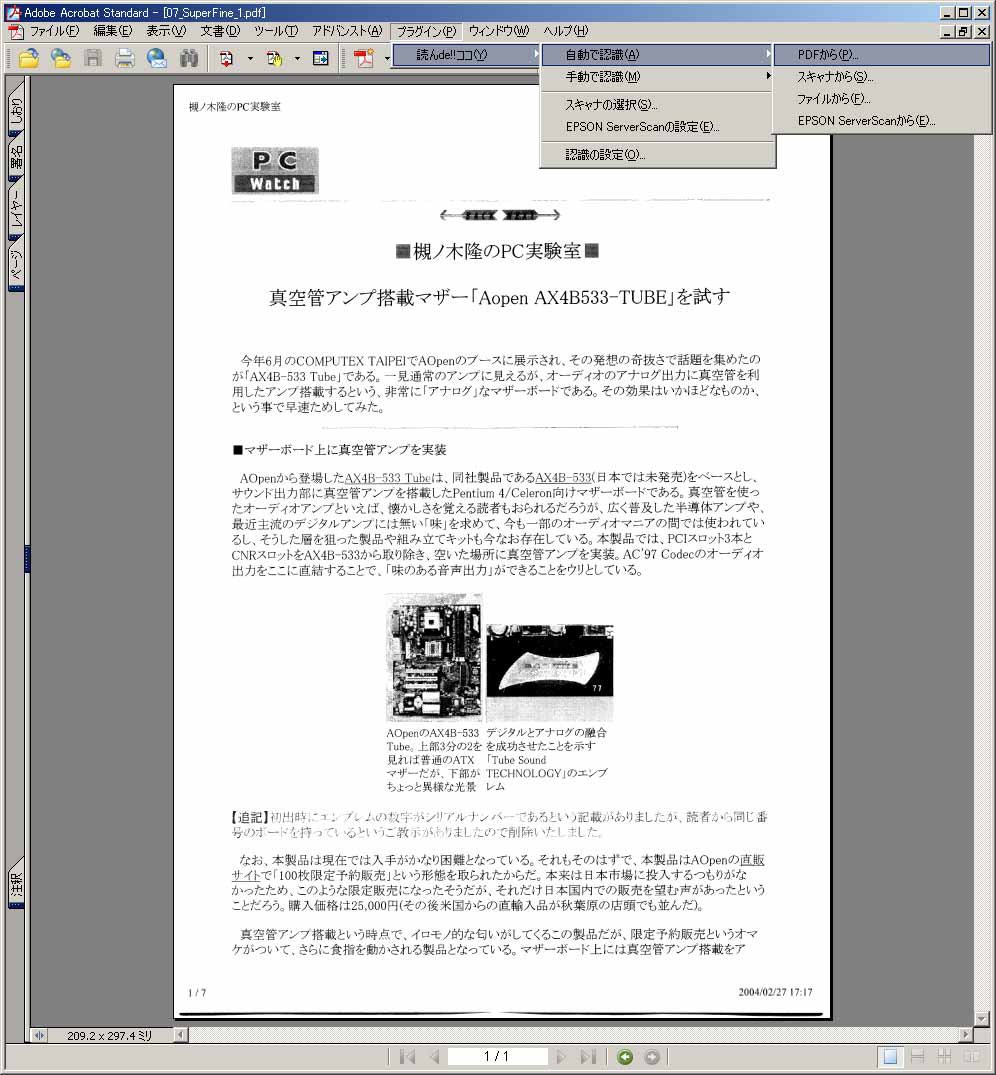
ということで、導入したのがエー・アイ・ソフトの「読んde!!ココ」(写真7)である。これを使って画像イメージのPDFをテキスト情報付きにしてやろう、という目論見だ。読んde!!ココをAdobe Acrobatのプラグインとして登録すると(写真8)、Acrobatの中からそのままOCRを実行できる。
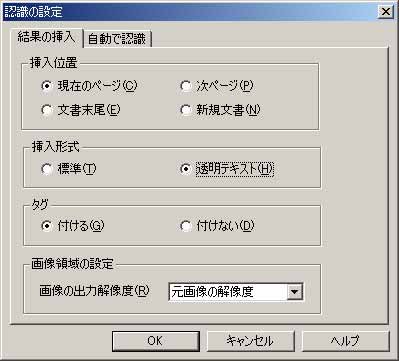
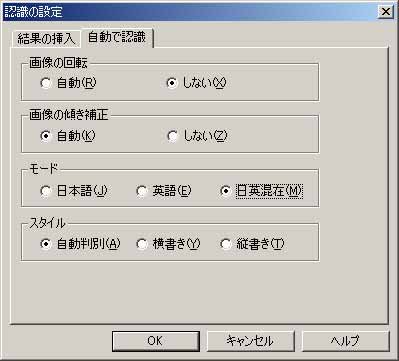
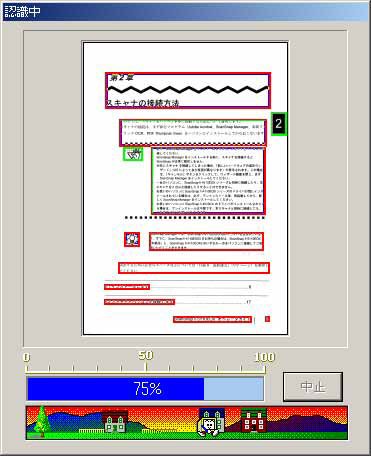
認識した結果をどうするか、は“詳細設定”で設定できる。元のイメージを崩さないでテキスト化できる「透明テキスト」がかなり便利である(写真9)。また、そもそも筆者の手元にある資料は英語のものがかなり多く、日本語のものでも英語が頻繁に混じる事が多いため、モードは日英混在をデフォルトとした(写真10)。ここで読み取りをかけると、PDF化した各ページ毎に読み取り処理を行ってくれる(写真11)。これを利用して「透明テキスト」を挿入しておけば、Namazuからの検索も可能になるだろう、という読みだ。
 |
 |
| 【写真7】今ではVersion 10が最新だが、買った当時はVersion 9だった。このあたりを見ると、多少認識精度が上がっているようだが…… | 【写真8】読んde!!ココのマニュアルにはAdobe Acrobat 5.0対応となっているが、6.0でも問題なく利用できた |
 |
 |
 |
| 【写真9】ただし、正しく文字を認識できたかどうか、一目で判らないという欠点もある。透明テキストを別に表示できると便利なのだが | 【写真10】縦書きはほとんど無いので、スタイルは横書きにしても構わないのだが、自動判別でもほぼ誤解することがなかったのでこのままとしている。画像の回転は、基本的にScanSnapで読み込んだときに補正をかけているので、ここではなしとした | 【写真11】写真のページで、平均30秒前後。結構時間がかかる。もっとも、使ったのがAthlon XP 2200+という今では遅めに分類されるマシンだからで、もう少し高速なマシンだともう少し短縮されるかもしれない |
が、結論から先に言うと、実はあまりうまく行かなかった。要するに、認識率がすこぶる悪いのだ。具体的に例を示してみよう。筆者の以前の記事をInternet ExplorerからPDFに出力した上で、それを手持ちのレーザープリンタ(OKI Microline 18N)でプリントアウト。これをもう一度ScanSnap!で読み込ませて、その後にOCRをかけて認識率を確認してみた。
まずPDFファイルの方であるが、結果を表1に示す。ちなみに、00_Original.pdf (53KB)がIEから出力したオリジナルである。
| 圧縮率(→) 読み取りモード(↓) |
1(最大) | 3(標準) | 5(最小) |
|---|---|---|---|
| ノーマル | 01_Normal_1.pdf (91KB) | 02_Normal_3.pdf (91KB) | 03_Normal_5.pdf (91KB) |
| ファイン | 04_Fine_1.pdf (138KB) | 05_Fine_3.pdf (137KB) | 06_Fine_5.pdf (138KB) |
| スーパーファイン | 07_SuperFine_1.pdf (226KB) | 08_SuperFine_3.pdf (227KB) | 09_SuperFine_5.pdf (226KB) |
仕様上、一番荒いのは03_Normal_5.pdfだが、確かに読みにくいとは言え、人間が見る分には十分であるかのように見える。さて、これにOCRをかけた結果はどうか? 透明テキストにすると判りにくいので、通常のテキストとして出力してみた。この結果を表2に示す。
| 圧縮率(→) 読み取りモード(↓) |
1(最大) | 3(標準) | 5(最小) |
|---|---|---|---|
| ノーマル | 01_Normal_1_OCR.pdf (37KB) | 02_Normal_3_OCR.pdf (36KB) | 03_Normal_5_OCR.pdf (37KB) |
| ファイン | 04_Fine_1_OCR.pdf (61KB) | 05_Fine_3_OCR.pdf (61KB) | 06_Fine_5_OCR.pdf (62KB) |
| スーパーファイン | 07_SuperFine_1_OCR.pdf (108KB) | 08_SuperFine_3_OCR.pdf (107KB) | 09_SuperFine_5_OCR.pdf (107KB) |
サイズだけ見ると半分~3分の1程度になっており、この点では非常に有意義なのだが、問題は認識率である。一番認識率の良い筈の07_SuperFine_1_OCR.pdfですら、
| 原文 | 認識結果 |
|---|---|
| AX4B-533 Tube | 鍵垣 |
| AX4B-533 | 壁 |
| 【追記】初出時にエンブレムの数字がシリアルナンバーであるという記載がありましたが、読者から同じ番号のボードを持っているというご教示がありましたので削除いたしました。 | 藍追記ヨネ椎僻に、1tこイLムぴ)数キニがンりプルナンバー…であうといプ記赦があり蓋したが、読者か三)同じ番号のボーイヾ、を持っているふいうご教溝′′′根こ)りました〔りで削除いたしました(・ |
| 直販サイト | 塵塵生赴 |
とまぁ、非常に楽しい事になっている。一番圧縮のキツイ03_Normal_5_OCR.pdfに至っては、「COMPUTEX TAIPEI」→「COMPUTEXTAJPEI」から始まり、かなり激しく誤認識されており、全般的に使い物にならない。
「この程度なら良いのでは……? 」という声も聞かれそうだが、このテストではスキャン元がかなり程度が良い状態である。一般にメーカーのプレゼンテーションの場合、カラーのものをモノクロコピーしたものが多く、この時点でかなり情報が欠落している。その上、2ページをまとめて1ページに収めるなんて事も珍しくない。何せ人間が見ても「これ何だっけ? 」とか思う事がしばしばあるほどだから、OCRなんぞひとたまりも無い。
実際、スキャンしたデータにOCRをかけてみたところ、認識率が数%とか0%(1文字も認識出来なかった! )なんてページがざらざら出てきてしまうほどで、到底使い物にはならない事が確認できた。というわけで、Namazuを使った管理は挫折と相成った。
というのは、読み取ったイメージは大半が読み取りモード:ファイン、圧縮率:3になっていて、これだとOCRでの認識率が極端に低すぎるからだ。せめてスーパーファインにしておけばもう少しマシだったかもしれないが、ファイルサイズの肥大化に繋がるわけで、今ですら馬鹿にならないサイズの資料ディレクトリが更に増えるのも考え物である。
 |
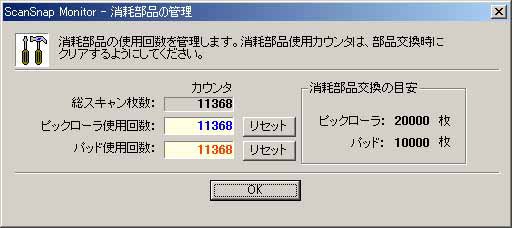
| 【写真12】上側がピックローラーで1年または2万枚ごとに交換、下側がパッドユニットで1年または1万枚ごとに交換 |
「それでもメーカーからPDFの形で配布される資料はNamazuで扱えるのでは? 」という向きもあろうが、こちらはPDFにロックがかかっているのが一般的なので、PDFをテキストに変換するXpdfで変換できない(*1)という問題があり、これまた難しかったりする。まぁ、もう少しこのあたりうまい方法が見つかるまで、暫くはディレクトリ名+ファイル名で手動検索という方法に頼らざるを得ないだろう。
さて、スキャン枚数が1万枚を超えたあたりで、そろそろ消耗品の交換を考えねばならなくなる。消耗品はピックローラーとパッドユニット(写真12)で、PFUの直販サイト「PFUダイレクト」で購入できる。ピックローラーが5,900円、パッドユニットが1,900円となっている。PFUダイレクトでは購入代金が1万円を超えると送料無料になるので、今回はピックローラー1つとパッドユニット3つをまとめて購入した。これで4万枚まではいける計算になる。
ちなみに8,000枚を超えたあたりから、かなり紙詰まりとか紙送りのずれが気になるようになってきており、そろそろ交換時期が近いという感じだった。まぁ紙の供給に気をつけさえすれば、「1万枚を超えたら使えなくなる」というわけではないのだが、1万枚を超えるとオートフィーダーにも関わらず、限りなく手差しに近い取り扱いが必要になってくるので、素直に交換したほうが無難だ。
(*1) 最新のXpdf 3.00で試したわけではないが、Changesを見る限り望み薄のようである。
●見かけから一新されたfi-5110EOX
 |
| 【写真13】fi-5110EOX。格納状態状態だと、ボディの大きさがむしろ目立つ感じ |
そのScanSnap!シリーズだが、今年2月19日に全く新しいスタイルになって「fi-5110EOX」として再登場した(写真13)。サイズはfi-4110EOX3が308.5×154×130mm(幅×奥行き×高さ)だったのが、284×146×150mmとなり、若干ながら設置面積は減った計算になる。ただ、fi-4110EOX3がスリムな形状だったのに対して、若干ボディが膨らんだためか、ややグラマラスな印象を受ける(写真14)。
ところが設置してみると、案外にサイズを取らない(写真15)。蓋の部分がそのまま紙送りガイドになっており、また紙送りの角度もfi-4110EOX3よりやや立ち上がっている印象で、この結果、奥行きはむしろfi-4110EOX3よりも小さくて済む(写真16)。
余談になるが、fi-4110EOX3ではスキャナ部を開くためのラッチが本体裏側にあったが、fi-5110EOXはラッチが手前に移動しており、片手で簡単に開けるようになった(写真17)。
紙詰まりを起こした場合には、しばしばスキャナを開ける必要があるのだが、従来は両手であけないとうまくいかない(ロックは外れてもスキャナ部が手前に展開しないので、結局紙詰まりを取り除けない)事があったが、今度はラッチを手前に引っ張ればそのまま開く事ができるので、割と合理的である。なお、この状態から更にカバーを外すと、ピックローラー部が出現する(写真18)。まぁ、これはピックローラーの交換時以外には関係ない話ではあるが。
外見の違いをもう1つ挙げておくと、スキャン後の紙を受けるシューターの構造が大きく変わった(写真19)。従来は本体の下にシューターをはめ込むだけの構造で、
・底面がフラットでないと、うまくシューターが引っ張り出せない事があった
・ちょっとシューターを引っ張りすぎると簡単に外れてしまう
といった欠点があった。これに対しfi-5110EOXでは、
・シューターのカバー部のゴム足の数が増え、多少底面が凸凹していてもシューターをスムーズに引っ張り出せる
・シューターの端にロックが付き、簡単に引き抜けないようになった
という具合に変更されており、割と細かい部分ではあるが使いやすい改良がなされている。
 |
 |
 |
| 【写真14】本体自体は明らかにfi-4110EOX3の方が小さい | 【写真15】蓋を開けると電源スイッチとスキャンスイッチが出現する | 【写真16】fi-4110EOX3の方は紙送りガイドが寝ているため、実はこの位置だと後ろのラックに引っかかってしまう。もうちょい、スキャナ本体を手前に引っ張り出す必要あり |
 |
 |
 |
| 【写真17】蓋を開いた状態。詰まった紙を取り除くのが容易になった | 【写真18】通常はここまで開く必要はない | 【写真19】上端に2箇所、引っかかりが設けられた。この上にfi-5110EOXを置くと、そう簡単には引き抜けなくなる |
スペックに関してもかなり改良された。表3に主な違いをまとめてみたが、白黒原稿だと解像度が倍増したほか、エクセレントモードと呼ばれる超高解像度モードが追加されたのはかなり嬉しい。
また、USB 2.0に対応したのも「ひょっとして多少動作が速くなるかも」という期待をさせてくれる。また表3には入れてないが、sRGB対応となり、カラー原稿の色再現性が上がったとしている。
| fi-5110EOX | fi-4110EOX3 | ||
|---|---|---|---|
| 解像度/読み取り速度 | ノーマルモード | カラー150dpi/白黒300dpi 15枚/分 | 150dpi 15枚/分 |
| ファインモード | カラー200dpi/白黒400dpi 10枚/分 | 200dpi 6枚/分 | |
| スーパーファインモード | カラー300dpi/白黒600dpi 5枚/分 | 300dpi 3枚/分 | |
| エクセレントモード | カラー600dpi/白黒1,200dpi 0.5枚/分 | N/A | |
| 補正機能 | 傾き補正(±5度)/回転補正(90度単位) | なし | |
| インターフェイス | USB 2.0/USB 1.1 | USB 1.1 | |
| 消費電力 | 動作時:28W以下/省電力時:8W以下 | 稼動時:35W以下/休止時:6W以下 | |
| 原稿サイズ | A4/A5/A6/B5/B6/はがき/名刺/レター/ リーガル/カスタム(5種類)/ サイズ自動選択 |
A4/A5/A6/B5/B6/はがき/名刺/レター/ リーガル/カスタム/サイズ自動選択 |
|
| 用紙種類 | 45~110kg/連量 | 45~90kg/連量 | |
| 添付アプリケーション | Acrobat 6.0 Standard 日本語版 名刺ファイリングOCR V1.1 |
Acrobat 6.0 Standard 日本語版 名刺ファイリングOCR V1.0 |
|
使い方としては、従来と大きく異なる部分はない。カバー兼用となっている用紙ガイドを開けるとそのまま電源が入る。その状態で用紙をセットして“SCAN”ボタンを押せば、後は自動的に1枚づつ読み込まれ、Adobe Acrobatに読み込んだ原稿がPDFとして表示されるという仕組みだ。
従来と異なるのは、fi-4110EOX3だとSimplex(片面)/Duplex(両面)という2つのスキャンボタンがあり、必要に応じて選ぶ事ができたのが、今度はScanボタンが1つにまとめられており、片面/両面の設定はScanSnap Manager(写真20)で設定するようになったことだ。
一見ちょっと不便に見えるが、そもそも白紙ページの自動削除機能があるので、普段からDuplexで利用する事が多い事を考えるとそれほど不自由ではない。ではなぜSimplexがあったほうが便利かというと、両面読み取り→白紙削除をかけるとちょっと遅くなっていたためである。
ただこれはスキャン速度がそもそも高速ならあまり気にならないわけで、その意味でも速度の確認は重要だろう。
その他の違いといえば、読み取りモードに「エクセレント」が追加された(写真21)とか、カスタム原稿サイズの登録モードが追加された(写真22)とかといったあたりだ。
また、ファイルサイズの設定に「高圧縮を有効にする」というオプションが加わった事も挙げられよう。この「高圧縮」とは文章などに絞った圧縮技法で、文字部分と背景部分を分離した上で、背景部分を高い圧縮率とする仕組みである。この結果、写真などは思いっきり潰れる可能性があるが、文字だけならば有効に読み取り出来る仕組みだ。このあたりの効果も試してみる事にしたい。
 |
 |
| 【写真20】まぁ普段片面読み取りボタンを使うケースは少ないから、これで十分かもしれないが | 【写真21】各項目の説明が何となくおかしい |
 |
 |
| 【写真22】ここで「追加」ボタンを押して、適当な名前と一緒にサイズを登録するわけだ。複数の変わったサイズの原稿をよく扱う場合には便利だろう | 【写真23】高圧縮のチェックボックスが左下に追加された |
●fi-5110EOX vs fi-4110EOX3
さて、紹介が終ったところで早速実力確認である。まずは読み取り速度だ。A4のコピー用紙に両面印刷された某社のプレゼンテーション資料(18枚/35ページ)を圧縮率3、読み取りモードファインの状態で「Scanボタンを押してから、Adobe Acrobat 6に読み取った原稿が表示されるまで」の時間を手動計測した。ちなみにAdobe Acrobat 6はあらかじめ起動しておく事にする。結果はというと
fi-5110EOX:1分19秒
fi-4110EOX3:2分26秒
といった具合に、圧倒的にfi-5110EOXの方が早い。実のところ、原稿をスキャンする時間もさることながら、fi-4110EOX3の場合でスキャンをかけると「原稿を読み込む→スキャナが休憩している間、画面上で2ページ目の読み取り処理→次の原稿に移る」といった感じになっているのに対し、fi-5110EOXでは切れ目無く原稿を読み込んで処理している。この待ち時間の違いも合計のスキャン時間の差に大きく影響していそうだ。
ついでクオリティのテストである。表1同様、1ページのモノクロ原稿を読み込んだ結果を表4にまとめる。白黒ページの場合、解像度が倍になるためか全般的にサイズはやや大きめに推移していることが判る。
気になる高圧縮だが、ファイルを見ていただければ判る通り、本当にこれが見やすいのかはちょっと微妙なところ。筆者的にはあまり見やすいとは思えない。しかも読み取りモードがノーマルやファインでは、むしろファイルサイズが大きくなってしまう。
もっとも、これはモノクロ原稿の場合で、カラー原稿の場合は実用的で、パンフレット類などの原稿を、メール添付で送信する場合などには、ファイルサイズも小さくなり有効なオプションだ。ドキュメントの保存には向かないので、使い分けが必要ということだろう。
またエクセレントにすると、確かに画像は綺麗なのだが、公称毎分0.5枚の読み取り速度と、データ量の増加によるスローモーションぶりで、1枚かそこらならばともかく、これで大量のドキュメントを読み込むのはちょっと耐えられない感じだ。やはりファインあたりが、大量ドキュメントを読み込める限界だろう。
| 圧縮率(→) 読み取りモード(↓) |
1(最大) | 3(標準) | 5(最小) | 高圧縮 |
|---|---|---|---|---|
| ノーマル | 10_Normal_1.pdf (63KB) | 11_Normal_3.pdf (64KB) | 12_Normal_5.pdf (64KB) | 13_Normal_High.pdf (146KB) |
| ファイン | 14_Fine_1.pdf (99KB) | 15_Fine_3.pdf (100KB) | 16_Fine_5.pdf (97KB) | 17_Fine_High.pdf (110B) |
| スーパーファイン | 18_SuperFine_1.pdf (175KB) | 19_SuperFine_3.pdf (174KB) | 20_SuperFine_5.pdf (177KB) | 21_SuperFine_High.pdf (121KB) |
| スーパーファイン | 22_Excellent_1.pdf (356KB) | 23_Excellent_3.pdf (355KB) | 24_Excellent_5.pdf (354KB) | 25_Excellent_High.pdf (318KB) |
| 圧縮率(→) 読み取りモード(↓) |
1(最大) | 3(標準) | 5(最小) | 高圧縮 |
|---|---|---|---|---|
| ノーマル | 10_Normal_1_OCR.pdf (15KB) | 11_Normal_3_OCR.pdf (16KB) | 12_Normal_5_OCR.pdf (15KB) | N/A |
| ファイン | 14_Fine_1_OCR.pdf (30KB) | 15_Fine_3_OCR.pdf (32KB) | 16_Fine_5_OCR.pdf (18KB) | N/A |
| スーパーファイン | 18_SuperFine_1_OCR.pdf (63KB) | 19_SuperFine_3_OCR.pdf (64KB) | 20_SuperFine_5_OCR.pdf (67KB) | N/A |
| スーパーファイン | 22_Excellent_1_OCR.pdf (115KB) | 23_Excellent_3_OCR.pdf (114KB) | 24_Excellent_5_OCR.pdf (120KB) | N/A |
●雑感
ということで使ってみた感じで言うと、大きく認識率が上がるとかいうわけでは無いが、利用上のストレスは大幅に減った。蓋があるお陰で、ふだん、ホコリが入り込む心配はなくなったし、蓋を上げれば電源が入る。細かいところでは原稿ガイドのサイズ調節のつまみがだいぶ堅くなったため、連続読み取りをしていると、次第に原稿が斜めにずれるといった問題も解決した。おまけに自動傾き補正も入ったために、スキャンが斜めにずれる事はほんとどどなくなっている。スキャンスピードも速く、もう買うなら今更旧型を選ぶ理由はどこにも無い。
しいて難点を挙げるとすれば、やはり49,800円という値段の高さだろう。筆者のようにとにかく常時大量の書類を電子化する必要がある人には「安い」とすら感じられるが、一般のユーザーにとって汎用性にやや乏しい(なにしろTWAINにすら対応しない)この製品が喜ばれるか、というとやや微妙なところ。
あれこれ注文をつけなければフラットベッドスキャナが1万そこそこで手に入ってしまうだけに、割高感は残るかもしれない。ここで5,000円程度でも安くなれば、グンと割高感が薄れたのだが。
あと個人的な雑感としては、折角手に入れたfi-4110EOX3用の消耗品が、fi-5110EOXではまるっきり使えない(形状からして変わってしまった)のはちょっと悔しくもある。まぁ、スキャン性能が大幅に上がったので、この程度はやむなしというところだ。
□関連記事【2月19日】PFU、ドキュメントスキャナ「ScanSnap」をモデルチェンジ
http://pc.watch.impress.co.jp/docs/2004/0219/pfu.htm
【2003年9月9日】PFU、Acrobat 6.0を同梱したPDF作成スキャナ
http://pc.watch.impress.co.jp/docs/2003/0909/pfu.htm
【2003年1月6日】【槻ノ木】PDF作成スキャナがフラットベッドに「ScanSnap! fi-4010CU」
http://pc.watch.impress.co.jp/docs/2003/0106/pclabo14.htm
【2002年11月12日】PFU、PDF作成スキャナのフラットベッドモデル
http://pc.watch.impress.co.jp/docs/2002/1112/pfu.htm
【2002年10月22日】【槻ノ木】かゆいところに「かなり」手が届いているPDF作成スキャナ「ScanSnap!」
http://pc.watch.impress.co.jp/docs/2002/1022/pfu.htm
【2002年9月9日】PFU、ワンタッチでPDF化できる高速シートフィードスキャナ
http://pc.watch.impress.co.jp/docs/2002/0911/pfu.htm
(2004年3月3日)
[Reported by 槻ノ木隆]
【PC Watchホームページ】
PC Watch編集部 [email protected] 個別にご回答することはいたしかねます。
Copyright (c) 2004 Impress Corporation All rights reserved.