 |


■後藤弘茂のWeekly海外ニュース■製造コストが非常に高い? GeForce FXの勝算 |
●GeForce FXのダイサイズはPentium 4(Willamette)並み?
NVIDIAの「GeForce FX(NV30)」のスペックは、業界を震撼させた。500MHzの動作周波数に、1GHzのDDR IIメモリ。数字だけを見ると、圧倒的だ。おそらく、登場時点でGeForce FXファミリの最初のコアである「NV30」は、パフォーマンスでトップに立つだろう。無事に出荷できれば、NVIDIAは再び業界トップの座を取り戻すことは間違いない。
しかし、NV30はいいことずくめのGPUというわけでもない。死角がある。それはコストだ。NV30自体の製造コストは、おそらく非常に高く、さらに現在の仕様だとボードコストも高い。そのため、NVIDIAはハイエンド向けのGeForce FXを、RADEON 9700 Pro(R300)よりもさらに高価格に設定する可能性もある。
まず、NV30自体のコスト。GPUのコストはCPU同様にダイサイズ(半導体本体の面積)に大きく左右される。高コストだったGeForce4 Ti(NV25)でも、12.数mm角、つまり、ダイサイズは150平方mm前後以下だった。だが、NV30のダイはそれよりずっと大きいと推定される。その証拠はいくつかある。
まず、NVIDIAがGeForce FX発表に際して公開したNV30のチップとウェハの写真。写真を見る限り、ウェハの中心から縁まででで、直線上にNV30のダイは7個分しか配置できないように見える。これが200mmウェハだとすると、計算上チップは14mm角程度ということになる。すると、ダイサイズはその二乗で200平方mmとなる。200平方mmというのは、CPUで言うと0.18μm版Pentium 4(Willamette:ウイラメット)クラスで、GPUとしては超巨大だ。もちろん、目算なので誤差はあるが、NV30がかなりの巨大チップであることに間違いはない。
 |
 |
| NV30のウェハとチップ | NV30のダイ |
過去のNVIDIAのチップサイズからも、ほぼ同じサイズが算出できる。これは簡単な算数だ。NV25(GeForce4 Ti)は0.15μmで製造され、NV30は0.13μmで製造される。製造プロセスは0.15μmから0.13μmへ、約80%に縮小することになる。面積の縮小率は、プロセスの縮小率の2乗で得られるので、70%程度となる。つまり、同じトランジスタ数のチップを0.15μmから0.13μmに移行させた場合には、理論値として70%のダイサイズになるというわけだ。
それに対して、NV30のトランジスタ数は、NV25(GeForce4 Ti)より約2倍に増えた。そうすると、200%×70%で、計算上、NV30のダイはNV25の約140%ということになる。NV25が初期に140平方mm台だった(リビジョンが上がるに従って縮小している)とすると、計算上でNV30は200平方mm弱となる。
そして、NVIDIAも、NV30のダイが大きいことを認める。例えば、Kirk氏は「あなたのように(ダイサイズを)計算すれば、かなり近い数字を得ることはできるだろう。RADEON 9700(R300)よりずっとパワフルだから、ダイもそれなりに大きいことは間違いない」と言う。0.13μmだからRADEON 9700よりダイ(半導体本体)が小さく、コスト上利点があるとは決して言わないところに注目して欲しい。
●同じダイサイズなら新プロセス技術の方が不利
NV30のダイが200平方mm程度(またはそれよりやや小さい程度)だとすると、ダイサイズはATIのRADEON 9700(約200平方mm)と同程度ということになる。そうすると、コスト的にはNV30が圧倒的に不利になる。それは、NV30が0.13μmプロセスで製造されているのに対して、R300は0.15μmプロセスで製造されているからだ。
半導体チップの歩留まりは、ウェハ上の欠陥の密度(Defect Density)×単位面積当たりのダイ(半導体本体)数に左右される。そして、成熟したプロセス技術より、立ち上がって間もない新プロセス技術の方が、Defect Densityが高くなる。そのため、同程度のダイサイズであっても、古い0.15μmで製造するより、新しい0.13μmで製造する方が、ずっと歩留まりが悪くなる。
 |
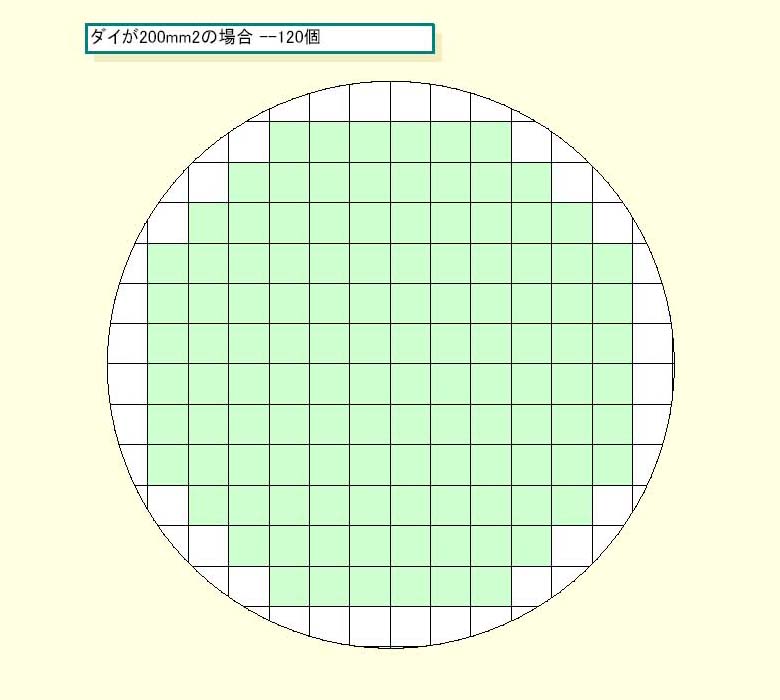 |
| ダイが140平方mmの場合のウェハ | ダイが200平方mmの場合のウェハ |
さらに、NV30は新メモリ技術であるDDR IIを使う。これは、DRAMベンダーの価格設定次第だが、原則的には高コストになる。また、現状ではNV30ボードは10層基板となっているが、これもコストを押し上げる。加えて、特殊な排熱機構のコストが加わる。
もちろん、今後もずっとNV30が高コストというわけではない。NVIDIAの通例で行くと、リビジョンが上がる度にダイは小さくなる。また、TSMCの0.13μmプロセスのDefect Density自体が下がって行く。そのため、将来的にはNV30の製造コストはぐんぐん下がるだろう。メモリも同様だ。また、「ボードも将来的には全て8層へと移行する」とあるOEMメーカーは言う。そうすると、最高性能のNV30でも、コストは下がる
だが、それはあくまでも先の話。少なくともデビュー時には、NV30ボードはかなり高コストにつくのは間違いない。そうした事情を考えると、NVIDIAはNV30の価格をかなり高めに設定してくると考えられる。実際、すでにGeForce FXボードは高価格になるというウワサが飛び交っているが、R300よりも高いと見られるコストを考えると、NVIDIAが高価格戦略を採るのは、むしろ自然だろう。
●肥大化し続けるNVIDIAのGPU
こうして見ると、NVIDIAのNV30は高パフォーマンス&高コスト&高価格へと向かっているように見える。性能を求めるためにダイ(半導体本体)が大きくなり、そのためにコストが高くなり、価格が高くなるという連鎖だ。
じつは、これは今回だけの特殊な事情ではない。まず、NVIDIAのこれまでの歴史を振り返ると、これは過去から継続した流れということがわかる。というのは、NVIDIAのGPUは、TNT2以来、継続してGPUが大型化し続けて来たからだ。「TNT2の世代だと9.8mm角、GeForceは11mm角、GeForce3は12mm角、GeForce4も同じくらい。どんどんダイサイズは大きくなっている」とATI TechnologiesのDavid E. Orton(デビッド・E・オートン)社長兼COOは指摘する。つまり、これまでもムーアの法則以上に性能を上げようとして来たためにダイが大きくなり続けて来たのだ。チップサイズが2倍になれば、それだけでチップコストは3~4倍になる。
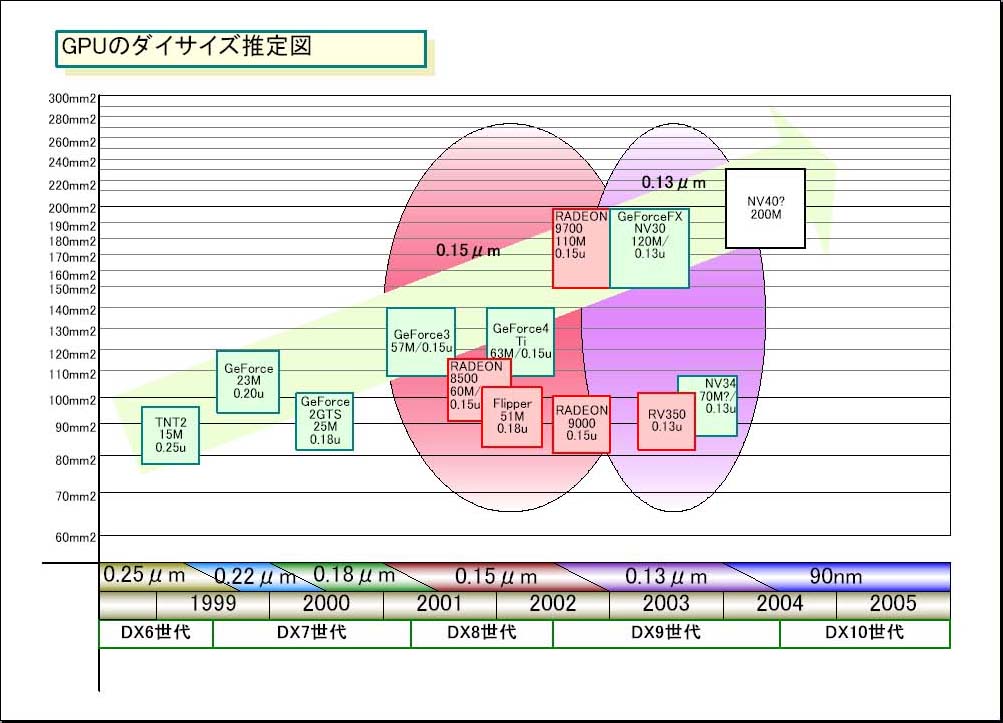 |
| GPUのダイサイズ推定図 |
そして、今後もNVIDIAのフラッグシップGPUは、ダイの大型化が続くだろう。実際、NVIDIA自身も「(ダイサイズが肥大化する)傾向は続くと思う」(Kirk氏)、「コンシューマ価格に抑えることやプロセス技術の制約はあるが、我々は限界をもっと引き上げたいと考えている」(Ballew氏)という。
そう考えると、NV30はたまたま高コストになったのではないことがわかる。高コストはムーアの法則以上にGPUを高性能化させる戦略の結果であり、NVIDIAは確信犯ということになる。どんどんダイが大きくなれば、どんどんGPUを高く売らなくてはならなくなる。明白なことだ。
そうすると、当然の疑問は、なぜNVIDIAがハイエンドGPUをひたすら高性能&高コスト=高価格へと押しているのか、それで経済的に成り立つのかという点になる。それに対して、Kirk氏は次のように答える。「ハイエンドGPUに関しては(経済的に)成り立つ。製造面でもどんどん効率が良くなっているから、チップサイズが大きくなったとしても、効率的に製造できるだろう。だから、それなりの価格(reasonable price)で売れるなら問題はない」
確かに、ファウンダリを見ると、製造面では効率は上がっている。しかし、それで追いつける以上にダイは大きく(高コストに)なっているように見える。そうすると、NVIDIAとしては“それなりの価格”、つまり、価格競争に巻き込まれない、高利潤を維持できる価格に維持しなければならない。裏を返せば、ハイエンドGPUは高価格でも需要はあるとNVIDIAが見ているからこの戦略がとれることになる。
おそらく、それは、コンシューマ以上の市場を見ているからだと推定される。つまり、上にプロフェッショナルユース市場があるから、ハイエンドGPUをさらに上へ伸ばしてもOKというわけだ。つまり、現在「Quadro」系のミッドレンジが占めている部分の一部も、GeForce FXが占めることになるだろう。プロユース向けにはNV30の他にQuadro系と見られる「NV30GL」もあるが、基本的に同じダイと考えられている。
●NVIDIAはGPUの世界のサーバー市場も視野に入れる
こうした背景を考えると、NVIDIAの野望は、上はCG制作の世界、下はコンシューマ製品と、同社の製品の幅を広げて、あらゆるCG市場を支配することにあると思われる。それも、CG制作の世界で、NVIDIAがNV30以降の世代で目指すのは、従来のモデリングやプレビューといった部分だけでなく、レンダリングファーム(CGレンダリングに使われるサーバー群)の領域までも手中にすることだと思う。
そう考えるのは、同じようにエグゼクティブにインタビューしても、ATIはレンダリングファームをGPUがすぐに置き換えられるとは言わないが、NVIDIAは置き換えられると言うからだ。もちろん、両社とも最終的なゴールが、レンダリングファームをプログラマブルGPUで置き換えることにあるのは間違いない。しかし、NVIDIAの方がよりアグレッシブにその方向へと向かっているように見える。NVIDIAの思惑通りに行けば、近い将来、「NV35(2003年中盤のNV30後継ハイエンドGPU)」か「NV40(2004年前半と推定される次世代GPU)」が2~4個載ったボードが何枚もささったレンダリングボックスが、従来のレンダリングサーバーに置き換わることになるのだろう。
 |
| ソニーのレンダリングボックス「GScube」 |
この話は、どこかで聞いたことがある? そう、SCEIがかつてPlayStation 2アーキテクチャの「GScube(PlayStation 2のチップの拡張版を搭載したボードを何枚も挿したレンダリングボックス)」でやろうとしたことと同じだ。
もし、ハイエンドGPUがレンダリングファームにあるラックマウントサーバー群を置き換えるなら、GPUはかなり高価格につけることができる。サーバーのコストを考えれば、GPUボードが高価格でも損はないからだ。また、この分野では、価格よりも機能と性能の方がずっと重要だから、GPUをどんどん機能リッチにして行くという方向性とも合っている。
CPUの世界に照らし合わせると、このストーリーはもっとよくわかる。例えば、IntelやAMDといったCPUメーカーは、PC向けのCPUから、サーバー&ワークステーション向けCPUへと拡大しつつある。よりダイサイズが大きく高コストのCPUを作って。それなら、同じようにGPUメーカーも彼らの世界のサーバー&ワークステーションを狙ってもおかしくはないだろう。
□関連記事【12月11日】【海外】NVIDIAインタビュー(上)
~GeForce FXの高クロックと高パフォーマンスの秘密
http://pc.watch.impress.co.jp/docs/2002/1211/kaigai01.htm
【12月11日】【海外】NVIDIAインタビュー(下)
~プログラム性と性能の両立を重視するGeForce FX
http://pc.watch.impress.co.jp/docs/2002/1211/kaigai02.htm
【11月21日】【海外】ATIの勝算とNVIDIAの勝算
~GPU戦争の次のフェイズ
http://pc.watch.impress.co.jp/docs/2002/1121/kaigai01.htm
【11月20日】【海外】ついにベールを脱いだNVIDIAの次世代GPU「GeForce FX(NV30)」
http://pc.watch.impress.co.jp/docs/2002/1120/kaigai01.htm
【11月19日】NVIDIAが次世代GPUのNV30をGeForce FXとして正式発表
http://pc.watch.impress.co.jp/docs/2002/1119/comdex04.htm
【2000年9月12日】SCEI、日本でもリアルタイム映像制作システム「GScube」を公開
http://pc.watch.impress.co.jp/docs/article/20000912/scei.htm
(2002年12月18日)
[Reported by 後藤 弘茂]
【PC Watchホームページ】
PC Watch編集部 pc-watch-info@impress.co.jp 個別にご回答することはいたしかねます。
Copyright (c) 2002 Impress Corporation All rights reserved.