 |


■後藤弘茂のWeekly海外ニュース■ATIの勝算とNVIDIAの勝算
|
●激戦がまだまだ続くATI対NVIDIA
いよいよGeForce FXすなわちNV30を“発表”したNVIDIA。これで、NVIDIAは再び王者の座を取り戻すことができるのか? 少なくとも、コアクロックとパフォーマンスでは、GeForce FXが優れているように見える。そうすると、また、NVIDIAが性能で引き離しにかかるのか。
 |
| NVIDIAはGeForce FXを2003年1月に出荷するとしているが…… |
じつは、これがそう簡単には行かない状況にある。NVIDIAの遅れがまだ響いているからだ。まず、両社の製品スケジュールを点検してみよう。
NVIDIAのJen-Hsun Huang社長兼CEOは「1月のタイムフレームで出荷できるだろう」とLas Vegasで開催した発表会で語った。年内クリスマス商戦前という目標は外れたが、それでも年明けにはなんとか出せるという説明だ。
しかし、ATI TechnologiesのKwok Yuen Ho(K. Y. ホー)会長兼CEOは、それは難しいと指摘する。「彼らが(NV30の)サンプルを入手してからの期間を考えると、十分に検証ができているとは思えない。通常は、サンプルから製品出荷までに6カ月かかるのだから、1月は難しいはずだ。CeBitの時期(3月)が合理的なタイミングだろう」
確かに、1月にNVIDIAが出荷しようとすると、そろそろ製品出荷版のウエーハの投入をファウンダリでスタートさせていなければならない計算になる。テープアウトが夏の終わりだとすると、確かに厳しい状況だ。実際、NVIDIAが発表会のプレゼンテーションでみせたシリコンも、A1ステッピングだった。もっとも、1月は決して不可能な数字ではない。
また、NVIDIAが実際に製品を投入しても、ATIには対抗できる手段があるという。「彼らが早く出せたとして1月2月だろう。それなら、我々も次の製品をすぐに投入できる。十分対抗できる性能の製品だ」とATIのRichard A. Bergman氏(Senior Vice President of Marketing & General Manager, Desktop Business)は言う。
実際、ATIにはRADEON 9700(R300)とほぼ併行して進めていた「R350」がある。Bergman氏の口ぶりだと、おそらく3~4月にはR350をGeForce FX対抗で持ってこれるメドが立っていると見られる。現在のR300は0.15μmプロセスの製品であるため、動作周波数などでGeForce FXに見劣りするが、0.13μmへ移行すれば、ATIはNVIDIAに対抗できることになる。
●製品投入のペースをあげる両社
 |
| NVIDIA Chief Scientist David B. Kirk氏 |
ここで、NVIDIAとATIのロードマップを整理しておこう。
NVIDIAは、GeForce FXを初めとするNV3xファミリを、今後、メインストリーム、モバイル、バリューへとどんどんファミリ展開をすると説明する。以前のコラム「NVIDIA、DirectX 9世代のGPU「NV30」を今秋発表」でレポートした通り、NVIDIAはこれらのファミリGPUを、徐々にではなく、かなり速いペースで連続して投入して行く。「これまでのなかでもっとも速いペースでファミリ製品を提供する」とNVIDIAのDavid B. Kirk(デビッド・B・カーク)氏(Chief Scientist)は説明する。
実際、あるグラフィックス関連ソフトの関係者は「デスクトップでは、メインストリーム向けのNV31とバリューセグメント向けのNV34があとに続く。バリュー向け製品まで併行して開発しているというのが驚きだ」と語る。NV31はもともと年末発表の予定だったが、NV30同様に遅れており、来年前半と言われている。NV34に関しては、あるGPUベンダー関係者は「NV34は来年中盤の予定で、予定は動いていないはずだ」と言う。
このほか、ノートPC向けでは、モバイル版の「NV31M」と「NV34M」があると言われている。また、「NV34」ベースと推定される、グラフィックス統合チップセットもある。「統合チップセットでも新しいアーキテクチャが必要だと考えている」とKirk氏は言う。現在推定されるNVIDIAのロードマップは下の図のようになっている。
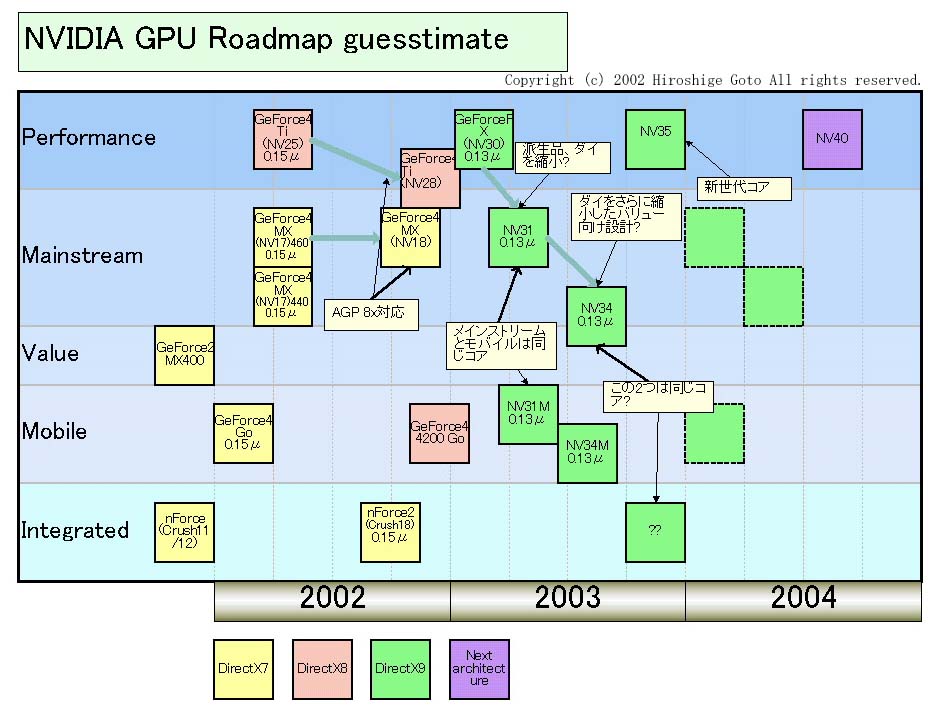 |
| NVIDIA GPU 推定ロードマップ (別ウィンドウで開きます) |
そして、NVIDIAはコアリフレッシュの「NV35」も2003年中に準備する。業界関係者の間では、じつはNV35というコードネームはもともと現在のNV30(GeForce FX)のものだったと広く信じられている。複数の業界関係者が、NVIDIAがオリジナルのNV30の設計をいったん破棄、もともと第2世代のNV35用に開発されていたアーキテクチャの多くを現在のNV30(GeForce FX)に取り込んだと証言する。
最初のNV30が中止になったのは、ファウンダリであるTSMCから、0.13μmラインでの製造が難しいと断られたからだと言われる。つまり、チップが複雑であるため、初期の0.13μmの歩留まりでは、現実的な歩留まりを達成できないとファウンダリから断られ、スケジュールが大きく後ろへずれたために、アーキテクチャも変えたと言う。そのため、現在、NV35の内容はまったく見当がつかなくなっている。
一方、ATIのロードマップはどうなっているか。ATIもR300の後続にあたるR350以外を用意する。これは、来春と予想される。さらに、来年中盤を目標にメインストリーム向けの0.13μm製品「RV350」と、第2世代のハイエンドGPU「R400」を用意している。R400の内容は、NV35同様に謎に包まれているが、まったく新しい設計になることだけは確かだ。
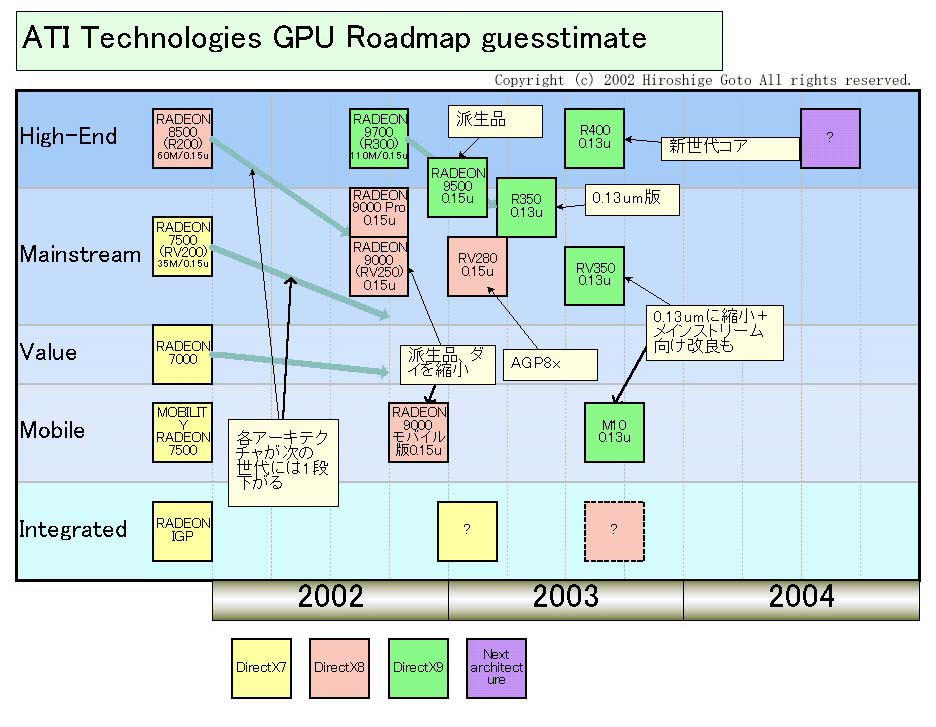 |
| ATI VPU 推定ロードマップ (別ウィンドウで開きます) |
こうしてみると、ATIもここから先、ほぼ3カ月に1~2製品のペースで、新しいGPUコアを投入する。この2社のロードマップを重ねると、NVIDIAがATIを抜き去ることができる態勢にはないことがわかる。むしろATIとNVIDIAが交互に新製品を投入、レースを繰り広げることになる可能性が高い。
●激突が予想されるNV30対R350
もっとも、ATIの次世代コアとNVIDIAの性能レースは、まだ不明瞭だ。両社とも、次世代製品が対抗製品に匹敵または凌駕すると主張している。
例えば、R350は0.13μmプロセスで製造されると思われていたが、あるNVIDIA関係者は「R350が本当の0.13μmプロセスだとは考えていない。そのため、実際のシェーダ性能ではNV30の方がはるかに上回るはずだ」と言う。NVIDIAの試算では、NV30のシェーダ性能はR350の1.5倍になるという。確かに、もし、R350がトランジスタと配線層の両方が0.13μm化された真の0.13μm製品でなかった場合、周波数ではNV30に引き離される可能性はある。このあたりは、フタを開けてみないと真実はわからない。
メモリ帯域についても論争がある。NVIDIAはDDR IIで128bitメモリインターフェイス、ATIはDDRで256bitインターフェイスを最初のDirectX 9世代で採用した。ピーク帯域は、NV30が17.1GB/secで、RADEON 9700(R300)が20.8GB/secだ。
ATIのDavid E. Orton(デビッド・E・オートン)社長兼COOは「NV30は128bitのメモリインターフェイスであるため、メモリ帯域は絶対に不足する。メモリ帯域は、性能に大きく影響するため、我々が明らかに有利だ」と指摘する。それに対して、NVIDIAのKirk氏は「実効帯域では我々の方が上だ。通常のDDR Iの2チャネルだと、2パーティションでアクセスするため、128bit幅のうち一部しか使われないとあとの帯域はムダになる。しかし、我々のDDR IIインターフェイスは4パーティションになっているため、はるかにメモリ効率がいい。アーキテクチャ上の利点がある。GeForce FXの場合、様々なデータ圧縮を考慮した実効帯域は32GB/secになり、ライバルのアーキテクチャの実効帯域を上回る」と言う。
もっとも、ATIもメモリ帯域をさらに引き上げられると言う。Orton氏は次のように語る。「当社も、じつは現在の製品でDDR IIメモリに対応している。しかし、発表時点では、DDR IIの供給は十分ではなかったので発表しなかっただけだ。DRAM側の準備が整えば、我々も(DDR II製品を)発表する。DDR IIでは我々も(NVIDIAと)同じDRAMベンダーとコンタクトを取っている。Samsung、Infineon、Hynix、現在のところSamsungだけが高速のDDR IIグラフィックス用を供給できる。DDR IIを使えるようになる時期は同じだ」
ちなみに、DDR IIはインターフェイス効率を上げる仕組みを持っているため、DDR Iより実効帯域が上がる場合がある。具体的には「Posted CAS」と呼ばれる仕組みで、RAS(Row Address Strobe)のすぐあとに続けてCAS(Column Address Strobe)コマンドも受け付けられる。CASコマンドは、実際にはDRAM側で留め置かれ(Posted)ているが、そのために、複数のリード/ライトが連続しても、コマンドの競合が抑えられ、アドレスバスの効率が落ちない。そのため、ある程度の帯域の差はカバーできる。
●動作周波数での優位はそれほど保てない?
動作周波数では、500MHzのGeForce FXが大きくRADEON 9700 Pro(325MHz)を上回っている。しかし、ATIがNVIDIAと同様に、TSMCの0.13μmプロセスに完全に移行したら、この有利は消えるか薄らぐと思われる。というのは、NVIDIAは500MHzの高クロックをGPUのアーキテクチャ改良ではなく「純粋にプロセス移行だけで達成した。銅配線で配線遅延が大幅に減少するために、単に0.13μmへ移行するよりも周波数向上の幅ははるかに大きかった」(Kirk氏)と説明しているからだ。つまり、ATIも同じプロセスを使えば、同様の周波数向上を得られる原理になり、500MHzに迫る可能性は高い。ただ、NVIDIAは同じ周波数であっても、シェーダプログラム実行の効率は、NV30の方が高いと主張する。
アーキテクチャでは、明らかにNVIDIAがATIを凌駕する。NV30はDirectX 9の暫定仕様を大きく拡張しているからだ。Kirk氏によると、現在MicrosoftはDirectX 9の定義を修正、ベースのDirectX 9に拡張仕様を加えた多層構造にしつつあるという。つまり、他社はベースDirectX 9しかサポートしていないが、NVIDIAはNV30で拡張仕様をサポートするというわけだ。
だが、このアーキテクチャ拡張は、ソフトウェア側に使われてこそ意味がある。NVIDIAが市場を支配して、例えばゲームプレイの標準プラットフォームになれば、開発者もNVIDIAのCineFXアーキテクチャを使ってくるだろう。しかし、そうしたトレンドにならず、開発者がDirectX 9のベース機能しか使わないのなら、アーキテクチャ上の利点は、少なくともPCサイドではほとんど活きないことになる(コンテンツ制作では活きる)。
そしてコスト。チップコストは、常にATIが有利だ。というのは、同じプロセスで同程度の規模のGPUを設計した場合、常にATIの方がダイサイズ(半導体本体の面積)が小さくなるからだ。ATIのOrton氏はその理由を「当社はチップの物理設計を効率よくする努力をしてきた。我々は非常にいい物理設計のチームを持っており、NVIDIAよりダイサイズを小さくできる」と説明する。一方、NVIDIAのKirk氏は「最初の世代ではパフォーマンス追求を優先するため、ダイサイズは大きい。2世代目で小さくする」と説明する。ATIはコストにも配慮した物理設計をし、NVIDIAはコストよりも性能を追求した物理設計をする傾向がある。
(2002年11月21日)
[Reported by 後藤 弘茂]
【PC Watchホームページ】
PC Watch編集部 pc-watch-info@impress.co.jp 個別にご回答することはいたしかねます。
Copyright (c) 2002 Impress Corporation All rights reserved.