 |


■後藤弘茂のWeekly海外ニュース■Nehalemに見えるIntel CPUマイクロアーキテクチャの今後 |
●CPUの中で電力を食う命令デコーダ
Nehalemマイクロアーキテクチャには、Intelの今後のCPUの発展の方向性が見て取れる。それは、プログラムの中のホットコード、つまり、頻繁に実行される部分だけを、ボトルネックを避けて、CPUのより深くにキャッシュして、実行を高速化する方向だ。実際、Nehalemマイクロアーキテクチャを見ると、実質的なキャッシュであるループストリームのバッファなどが、CPUの実行エンジンにより近いところに配置され、非常に階層化されたキャッシュ構造になっていることがわかる。そして、これはx86 CPUの場合、自然な進化の流れでもある。
x86 CPUにとって最大の重荷は命令デコーダ(Instruction Decoder)だ。可変長で命令フォーマットが複雑なx86命令のフェッチからデコードにかけては、処理が難しくロジックが複雑になる。そのため、命令デコーダのコスト(トランジスタ数)が高い。
CPUの場合、コストは、イコール電力消費だ。トランジスタ数が多く複雑な命令プリデコーダ&デコーダが多くの電力を消費する。特に、デコーダでは比較的小さな面積が集中して熱源となるため、それがCPUのパフォーマンスを規定してしまう。IntelのJustin R. Rattner(ジャスティン・R・ラトナー)氏(Senior Fellow, Corporate Technology Group兼CTO, Intel)は次のように語っていた。
「(CISCであるx86命令セットの)可変長命令のデコーダは、固定長命令のRISCのデコーダより電力を消費する。IntelやAMDのプロセッサのサーマルマップ(温度分布図)を見れば、チップ上の最も熱いエリアがデコーダ部分であることがわかる。デコーダの電力効率に関しては、固定長命令セットアーキテクチャの方がどうしても有利になる。
ここで重要なのは、プロセッサのパフォーマンスは平均消費電力で制約されるのではなく、ピーク温度で制約されることだ。そのため、ホットスポットであるデコーダが、CPUの動作周波数の事実上の制約となる。なぜなら、その部分のジャンクション温度が既定値を超えないように、抑えねばなければならないからだ」
現在のCPUは、複数のサーマルセンサでダイ(半導体本体)上の温度を計測している。ダイ上の、どこかの温度が規定値に達すると、周波数と電圧を制御して温度を抑える。そのため、CPUの動作周波数は、ダイ上で電力消費が集中しており熱が高い「ホットスポット」に制約されてしまう。そして、x86 CPUでは、命令デコーダ回りが最大のホットスポットだ。
●今後2世代引き継がれる命令最適化
Intelは、Nehalemでも、最大の熱源となっている命令プリデコーダ&デコーダをこれ以上に複雑化することを避けた。電力効率にフォーカスするために、効果があってもコストが高い改良は諦めた。1%のトランジスタを加えるのは1%以上のパフォーマンス向上を見込める場合に限るのが、Nehalemの設計思想だからだ。
Core MAでは、命令プリデコード部分でもさまざまな制約のために、コード最適化にいくつかの制約がついている。LCPを避ける、不必要に命令長を長くしない、といった制約だ。そして、その多くはNehalemにも引き継がれる。
この件は、以前から示唆はされていた。Intelは、日本で2006年6月に行なった「HPC Developer Conference」では、コード最適化について、次のように説明していた。
「Core MAに合わせてコードを最適化するなら、その最適化の全てではないが、その多くは、あと2世代のCPUに渡って有効となる。最適化への投資は、今後6年間に渡って活きるだろう」
この世代という単語が、マイクロアーキテクチャの刷新を示すなら、IntelはNehalemの次の「Sandy Bridge(サンディブリッジ)」まで、同じ最適化が必要な構造を維持することになる。つまり、フロントエンドの構造は2010年世代のCPUでも引き継がれることになる。中間世代の改良版マイクロアーキテクチャもカウントするなら、最適化はNehalemまでの継承となる。
6年間という表現を見ると、前者である可能性は高い。2010年に登場するSandy Bridgeが引き継がれるのは2年後の2012年で、カンファレンスが開かれた2006年の6年後となるからだ。だとすれば、Core MAの土台は、NehalemだけでなくSandy Bridgeにも継承されることになる。ボトルネック自体はその時点まで残ると予想される。
 |
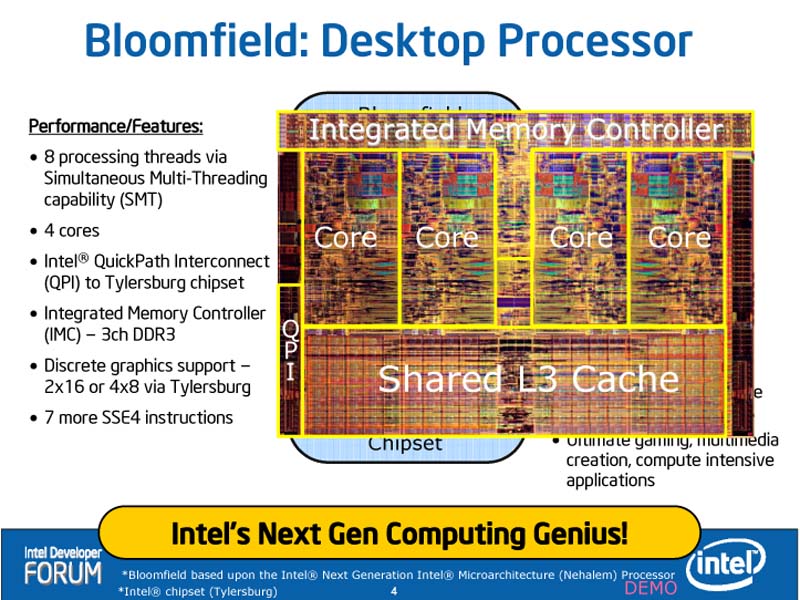 |
| Nehalemの概要 | デスクトップ向けNehalem「Bloomfield」のブロック図 |
●ボトルネックを回避するループストリームディテクタ
では、Nehalemでは、ボトルネックが残る命令プリデコードやデコードをどう回避するのか。Intelは解決にコストがかかるフェッチ/プリデコード/デコードに絡む問題に対する最良の解決法のひとつは、命令フェッチからデコードまでを実行しないで済むようにすることだと考えているように見える。
それが見えるのは、Nehalemで実装された、uOPsベースの「ループストリームディテクタ(Loop Stream Detector)」だ。Core MAから組み込まれたループストリームディテクタは、ループを探知すると、ループ内の命令を最大18命令までキャッシュする。実際には、ループの場合、プリデコーダの下の命令キューに格納した命令をフラッシュしないで保持して、繰り返し実行する。そのため、Core MAでは、ループ内の命令は再びフェッチ&プリデコードする必要がない。
それに対して、Nehalemのループストリームディテクタは、命令デコーダの後にループストリームディテクタがあり、ループ内のuOPsを最大28 uOPsまでキャッシュする。そのため、命令デコーダまでをバイパスすることができる。Nehalemのリードアーキクトの一人であるRonak Singhal氏(Principal Engineer, Oregon CPU Architecture, Intel)は、命令プリデコード&デコードをコストをかけて改良するより、むしろループストリームディテクタなど、別な解決策を講じた方がいいと判断したと語っている。
 |
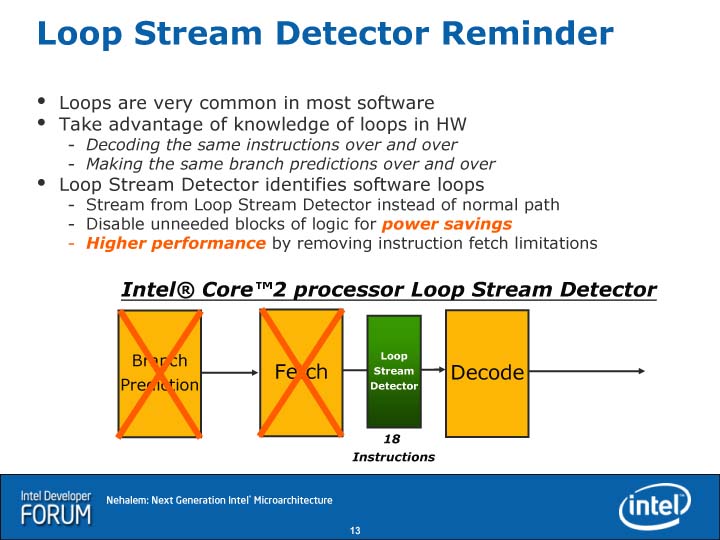 |
| Nehalemのループストリームディテクタ | Core MAのループストリームディテクタ |
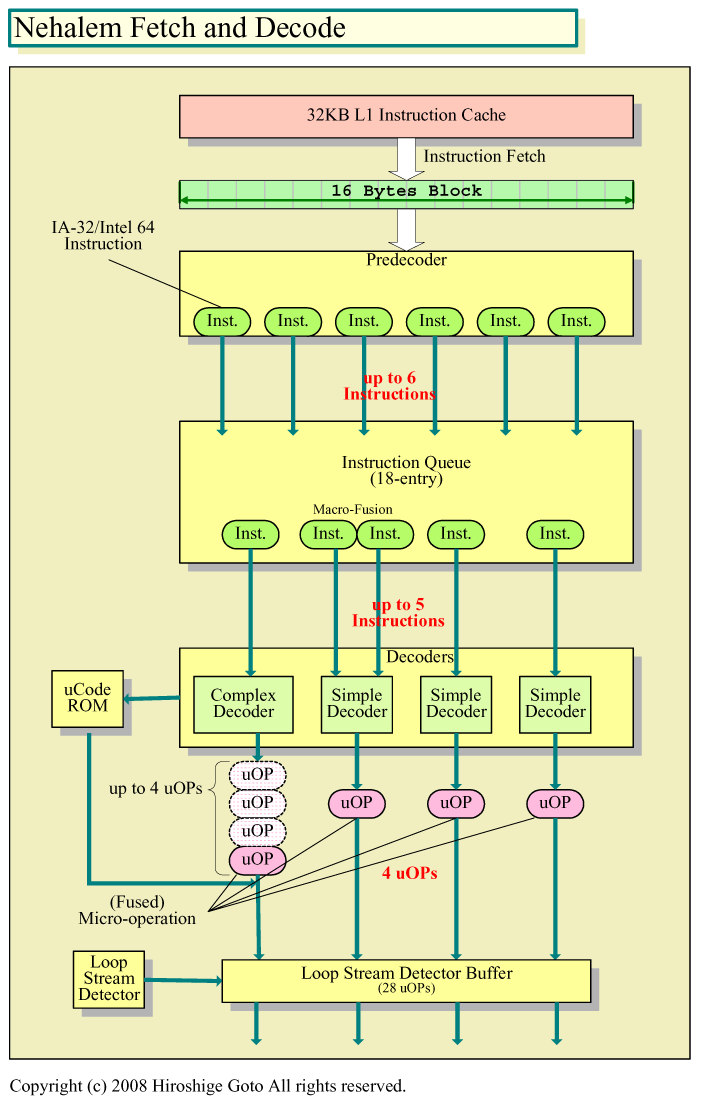 |
| Nehalemのフェッチ&デコード PDF版はこちら |
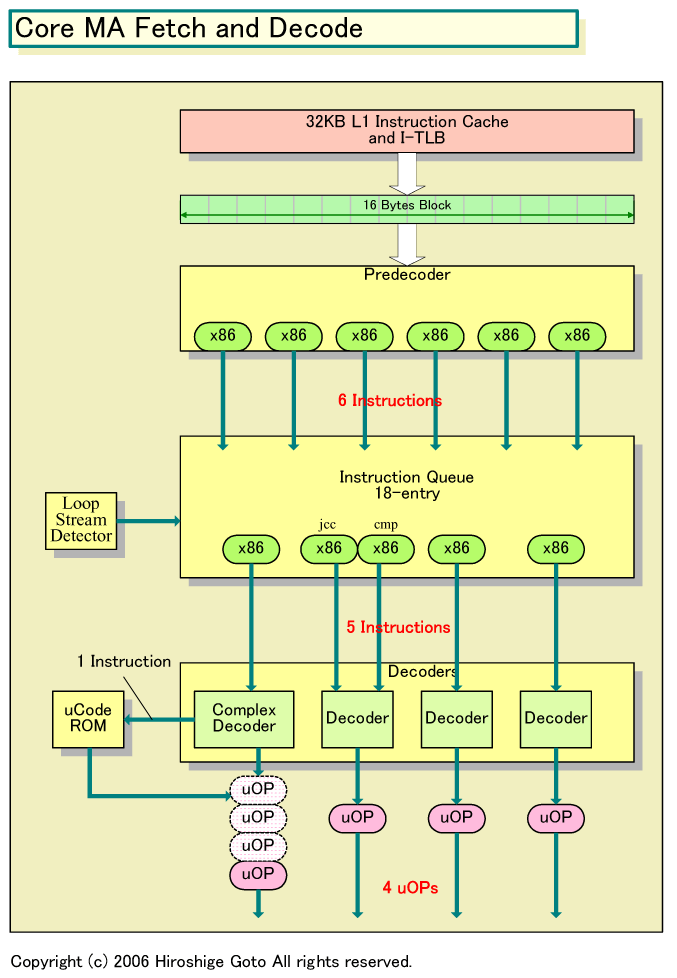 |
| Core MAのフェッチ&デコード PDF版はこちら |
この発想は、NetBurst(Pentium 4)のトレースキャッシュの考え方と、(規模とケースは限られるものの)基本的には似ている。トレースキャッシュも、命令デコーダのボトルネックを回避するための仕組みだったからだ。
しかし、Nehalemのリードアーキクトの一人であるRonak Singhal氏(Principal Engineer, Oregon CPU Architecture, Intel)は、次のように慎重に説明する。
「Nehalemのループディテクタは、トレースキャッシュをベースにしたわけではない。ループディテクタはCore MAにすでにあり、パイプライン中でのその位置を上により効率的な位置に動かすことは自然な拡張だからだ。結果としては似ているが、基本の土台は異なる」
●非効率だったNetBurstのトレースキャッシュ
NetBurstでは、デコーダの後にL1命令キャッシュに相当するトレースキャッシュを配置した。そのため、トレースキャッシュにヒットする限り、命令デコードの必要がなかった。命令デコーダのボトルネックを、L1命令キャッシュをデコーダの後に持ってきて、命令デコードをパイプラインから外すことで実現した。
しかし、NetBurstのトレースキャッシュは非常に高コストで非効率だった。まず、x86命令をuOPsに分解すると命令数が多くなり、命令長も長くなり、キャッシュが肥大化してしまう。Prescottでは、12KBのuOPsを格納するために128KBのトレースキャッシュを実装していた。x86 CPUの通常のL1命令キャッシュよりずっと大きく、NetBurst CPUを見ると、トレースキャッシュが、ダイ上で大きな面積を取っていることがわかる。
また、NetBurstのトレースキャッシュは、分岐予測に基づく予測トレースをキャッシュしていた。NetBurstでは、予測ミスなどで、キャッシュミスが発生すると、命令デコードから実行する。ところが、命令デコーダは1wayなので、キャッシュミス時には1命令/サイクルのマシンになってしまう。
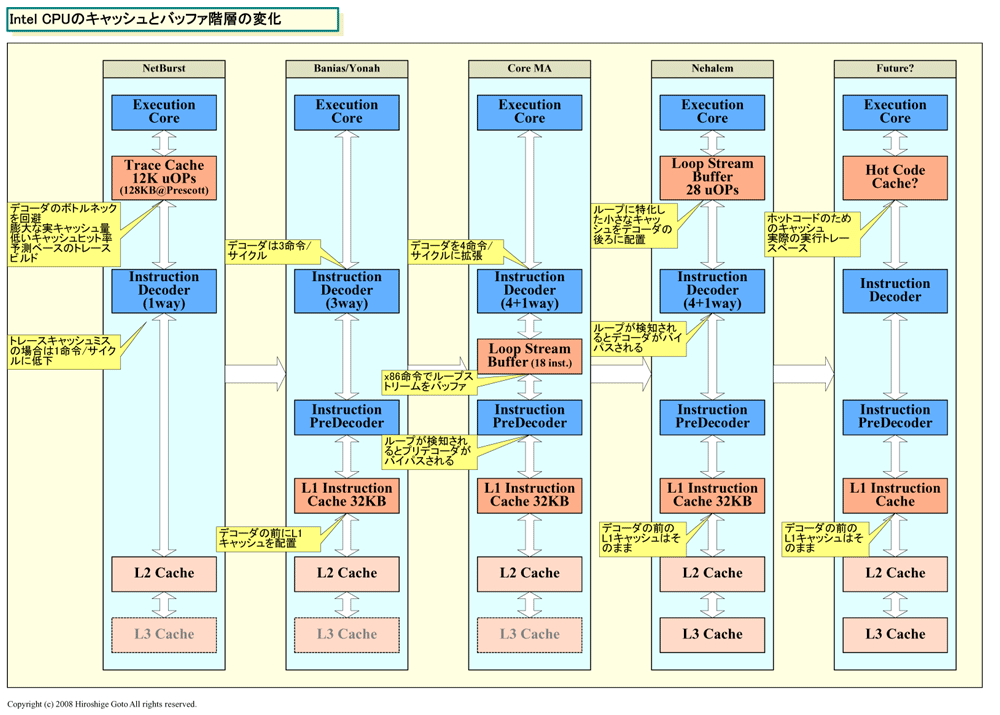 |
| NetBurstからのキャッシュとバッファ階層の変化 PDF版はこちら |
NetBurstの改良アーキテクチャだった「Tejas(テハス)」は、この部分の改良に力を注いだと言われている。Intel関係者は、Tejasは、パイプライン中にデコーダが2カ所にあり、キャッシュミス時のデコード効率を劇的に上げたアーキテクチャだったと語っていた。しかし、Tejasは、CPUコアがあまりに複雑になったため、マルチコア化の流れの中でキャンセルされてしまった。ここでも、デコーダ部分を拡張するとx86 CPUが非効率になることが暗示されている。
●ホットコードだけを格納するuOPsキャッシュ
コストが高く、効率が悪く、キャッシュミス時のペナルティが大きい、NetBurstのトレースキャッシュは、同マイクロアーキテクチャの弱点だった。そのため、Pentium IIIから拡張されたPentium M(Banias:バニアス)では、命令デコーダの前にL1命令キャッシュが配置された。トレースキャッシュの試みはご破算にして、もう一度、通常のx86 CPUのスタイルに戻した。電力効率を考えた場合に、トレースキャッシュは効果的ではないと認めた格好だ。
そして、Pentium Mから発展したCore MAでは、命令プリデコーダと命令デコーダの間に、ループストリームディテクタのバッファ(物理的には命令キュー)を挟むアーキテクチャとなった。つまり、命令プリデコードのボトルネックを回避できる部分に、ループに特化したキャッシュを配した。頻繁に使うコード部分(ホットコード)については、よりCPUの実行エンジンに近いところでキャッシュするという試みだと言える。
そして、Nehalemでは、ループストリームのためのバッファが、命令デコーダの後に設けられた。x86命令キューをループストリームバッファとして使う代わりに、uOPsキューをバッファとして使うようになった。ホットなコード部分のキャッシュが、段々と、CPUの内側に移動して行くのがよくわかる。しかし、NetBurstとは異なり、デコーダの外のL1命令キャッシュはそのままで、デコーダの内側のuOPsキャッシュは非常に小さいままだ。
NetBurstのトレースキャッシュでは、1度しか実行しないコード部分(コールドコード)も、uOPsのキャッシュに格納されていた。それに対して、Nehalemのアプローチでは、コールドコードはデコーダの外のL1キャッシュにあり、ループ部分のホットコードだけがuOPsでキャッシュされる。そのため、トレースキャッシュと較べると小さくても、非常に効率的だ。
そのため、この流れから論理的に予想される、Intel CPUの進化の方向性は次のようになる。命令デコーダの下に配置するキャッシュを、さらに大きくする。より長いループや、実行中のループ以外のホットコードも検知して格納するようにする。実際の命令実行をベースにした実行トレースをキャッシュする。そうすれば、より多くのコードに対して、CPUのフロントエンドのボトルネックを回避させることができる。
実際に、Intelがそうした実装をするかどうかはわからない。しかし、x86命令のプリデコードとデコードがボトルネックであり、その改良が電力効率的に見合わないものである以上、電力効率を維持しながらパフォーマンスを上げる方法は、理論的には、より多くの命令実行でボトルネックを回避することになる。ホットコードだけをキャッシュすれば、かつてTransmetaがやったように、ホットコードだけをバックグラウンドで最適化するような手法を採ることもできる。
Nehalemに見えるのは、IntelがCore MAの基本に自信を持ち、Core MAをベースに明瞭な方向でCPUマイクロアーキテクチャの開発を進めていることだ。それだけ、NetBurstで電力効率を悪化させた失敗に懲りたと推測される。
□関連記事
【4月28日】【海外】x86 CPUの弱点が浮き彫りになったNehalemマイクロアーキテクチャ
http://pc.watch.impress.co.jp/docs/2008/0428/kaigai438.htm
【4月7日】【海外】x86からの脱却を図るIntelの新ロードマップ
http://pc.watch.impress.co.jp/docs/2008/0407/kaigai434.htm
【4月3日】【海外】IDFで公開された「Nehalem」の内部アーキテクチャ
http://pc.watch.impress.co.jp/docs/2008/0403/kaigai433.htm
(2008年5月23日)
[Reported by 後藤 弘茂(Hiroshige Goto)]
【PC Watchホームページ】
PC Watch編集部 pc-watch-info@impress.co.jp ご質問に対して、個別にご回答はいたしません
Copyright (c) 2008 Impress Watch Corporation, an Impress Group company. All rights reserved.