 |


■後藤弘茂のWeekly海外ニュース■x86 CPUの弱点が浮き彫りになったNehalemマイクロアーキテクチャ |
●Nehalemで拡張されなかった要素がx86 CPUの重荷部分
Intelの次期CPU「Nehalem(ネハーレン)」は、極めて強力なマイクロアーキテクチャだが、同時にx86 CPUの抱える弱点も浮き彫りにしている。複雑なx86命令の実行にともなう問題の多くは、解決されないまま残されたからだ。現在のCPUにとって最も重要な電力効率の向上を目指すと、x86命令の複雑性を解決することが難しいからだという。Nehalemは、それ以外の、より効率的にパフォーマンスをアップできる部分にフォーカスしているように見える。
Nehalemではパフォーマンスが上がっても、それ以上にコスト(トランジスタ&電力)が上がるフィーチャは実装しなかったとIntelは説明している。「Nehalemでは、1%電力消費がアップするなら、少なくとも1%のパフォーマンスアップが得られることが原則だ。パフォーマンスが増すものの、ハードウェアコストがそれ以上に増すアイデアは一切採用しなかった」(Nehalemの開発ディレクタJim Brayton氏(Director, Enterprise Microprocessor Group and Design Manager, Nehalem Family CPU Development, Intel))。
NehalemとCore Microarchitecture(Core MA)を較べると、Intelが拡張した部分と、拡張を見送った部分とが顕著に分かれている。そのため、何が拡張されなかったのかをチェックすると、どこがx86 CPUの障壁なのかが浮き彫りになる。明瞭なのが、Nehalemのパイプラインの中で、命令の取り込みからデコードまでを担当するフロントエンド部だ。
Nehalemのフロントエンドパイプラインの先頭に位置するのは、「インストラクション(命令)フェッチ(Instruction Fetch)」で、32KBのL1命令キャッシュからx86(IA-32/Intel 64)命令を取り込む。Nehalemでは、Core MAと較べてL1キャッシュレイテンシが3サイクルから4サイクルに伸びているため、命令フェッチにかかるレイテンシも1サイクル増えていると考えられる。ちなみに、Nehalemのパイプラインは16ステージで、Core MAの14ステージより2ステージ増えた。うち1ステージ分が命令フェッチだと推測される。
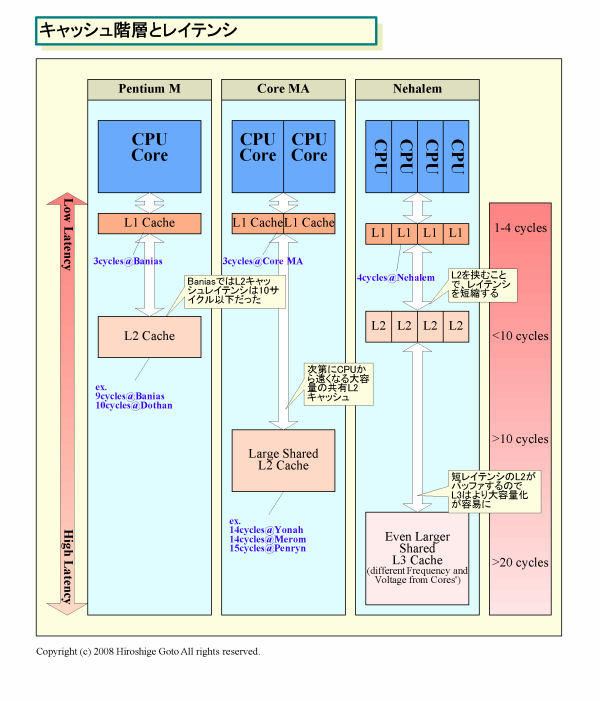 |
| キャッシュ階層とレイテンシ PDF版はこちら |
●ジョウロのような構造になったフロントエンドブロック
命令キャッシュからフェッチしたブロックからは、「プリデコーダ(PreDecoder)」が、x86命令を切り出す。プリデコードでは最大6命令を切り出すことができる。切り出されたx86命令は「インストラクションキュー(Instruction Queue)」で待機、最大5命令ずつ「命令デコーダ(Decoder)」に送られる。命令デコーダは4個で、3個のシンプルデコーダと、1個のコンプレックスデコーダで構成されている。命令デコーダからは、CPUの内部命令uOPs(Micro-Operation)が4命令/サイクルで、下のステージに送られる。全体で見ると、6命令プリデコード、5命令デコード、4uOPs発行と上から下へ狭まっていることがわかる。この構造はCore MAと同一だ。
「ジョウロのように、入り口をより広くとって、パイプラインに注ぎ込むイメージだ。上にヘッドルームを持たせないと、4個のデコーダに十分に命令を供給できない」とCore MAのアーキテクトの一人Bob Valentine(ボブ・バレンタイン)氏(CPU Architect, Mobility Group)は説明していた。
パイプラインの流れだけでなく、デコーダユニットもコンプレックス1にシンプル3の構成で、フェッチとプリデコードのステージの流れも基本的に共通だ。目立つ違いは、ループを探知してループ内の命令をキャッシュする「ループストリームディタクタ(Loop Stream Detector)」がデコーダの下に来たこと。Core MAでは、これはデコーダの前に位置していた。
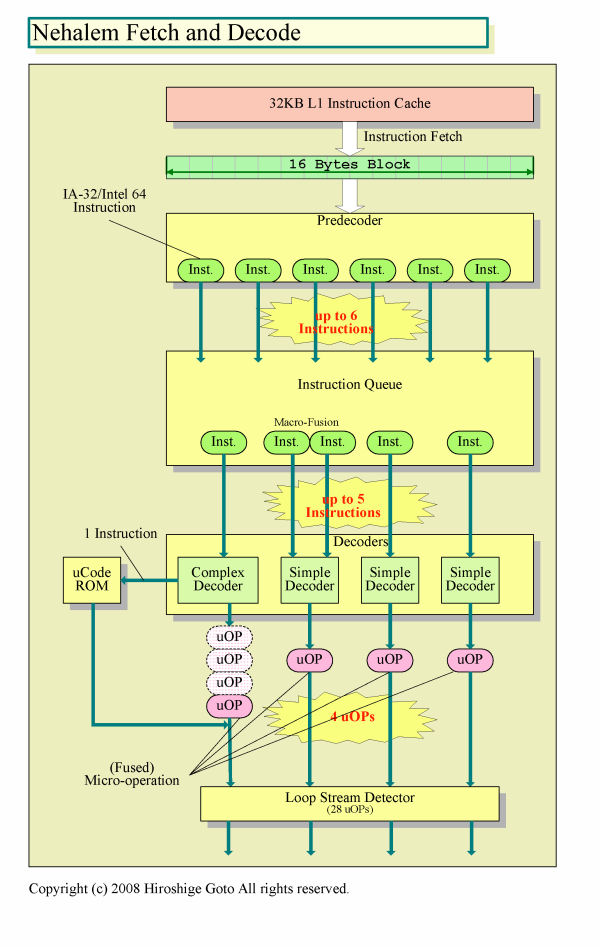 |
| Nehalemのフェッチとデコードの流れ PDF版はこちら |
●16bytes命令フェッチは電力効率から拡張を見送り
Core MAでは、L1命令キャッシュからの命令フェッチが16bytesブロック単位だった。16bytesは、4命令をフェッチするには狭すぎて、ブロックに含まれる命令によっては、後段のパイプラインに充分な数の命令を供給できるだけの命令フェッチができない場合があると指摘されていた。命令フェッチがボトルネックとなって、下の広帯域の実行エンジンへの命令供給が足りなくなり、パフォーマンスが落ちる可能性があるという。
 |
| インストラクションフェッチとプリデコードの最適化 |
実際、AMDは、そう主張して、フェッチ部分を2倍の32bytesに拡張している。だが、Nehalemでは命令フェッチ部分は拡張しなかった。Nehalemのリードアーキクトの一人であるRonak Singhal氏(Principal Engineer, Oregon CPU Architecture, Intel)は、次のように説明する。
「我々が、命令フェッチを拡張しなかった主な理由は、今日、そこがボトルネックになっているとは考えていないからだ。より正確に言えば、拡張しても見合うだけのボトルネックではなかった。ハードウェアを増やすとそれだけコストが増し、電力も増えるからだ。
我々はもちろん拡張も検討はした。しかし、拡張によって得られるパフォーマンス比率が非常に顕著でなければ採用はしたくなかった。この場合は、拡張によって得られるパフォーマンス面の利点が、求めるパフォーマンスと電力の比率に合致しなかった」
命令フェッチ部分の拡張は、パフォーマンスと電力効率のトレードオフにあり、電力効率を落とす拡張は採用しないNehalemでは見送られたという説明だ。32bytesフェッチは、分岐での無駄が多くなり、電力効率を悪化させる可能性が高いとIntelは説明する。整数演算では分岐命令の頻度が非常に多いため、この件はクリティカルだ。
命令フェッチ幅の制約は、Core MA/Nehalemでのソフトウェア最適化に影響している。長い命令が多くなると、プリデコードの効率を落としてしまうからだ。Intelはそのため、日本で2006年6月に行なった「HPC Developer Conference」では、Intel 64で加わった8本ずつのレジスタセットを使うための「REX」プリフィックスも、命令長を長くしてしまうため、Core MAではできれば使わない方がいいと説明していた。Nehalemでも、原則として同じ理論が当てはまることになる。新しく加わった拡張命令やフィーチャは、プリフィックスを使うため命令が長くなる傾向がある。
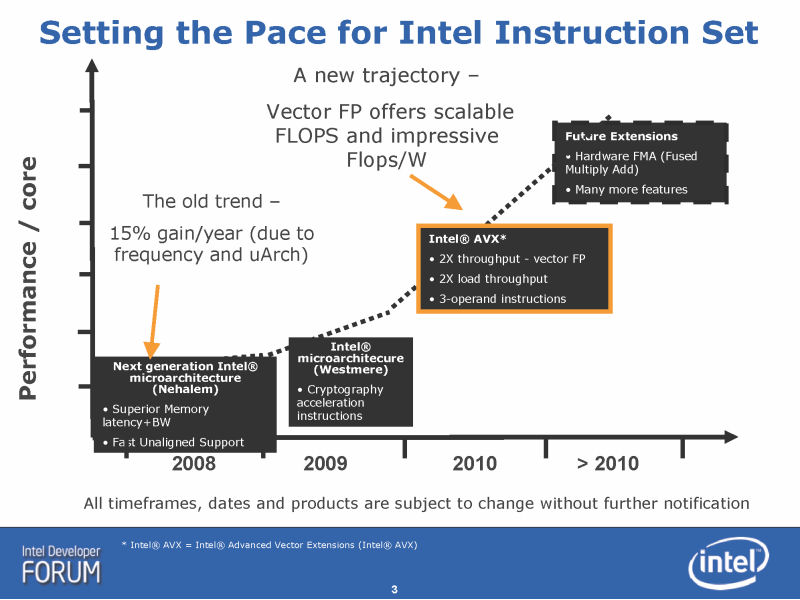
しかし、Intelは、将来的には命令フォーマット自体を変えることで、この問題を軽減しようとしている。Nehalemの次の新マイクロアーキテクチャである「Sandy Bridge(サンディブリッジ)」に実装する新命令拡張「Intel Advanced Vector Extensions (Intel AVX)」からは、「VEX(Vector Extension)」と呼ぶ新プリフィックスを使う命令エンコーディングシステムで、命令長の圧縮とフォーマットの整理を図るからだ。SSE命令もAVX命令へとコンバートしてしまえば、問題は軽減される。ハードウェア側ではなく、命令フォーマット自体を改良することの方が良策とIntelは判断したようだ。
 |
| 16byteブロックに6命令を送ると性能が下がる場合がある |
●複雑なx86命令を切り出す命令プリデコードユニット
フェッチした16bytesブロックは、命令プリデコードで処理される。プリデコードステージでは、可変長のx86命令の区切りをマーキングし、命令タイプを判別する。2個のx86命令を1個に融合させるMacro-Fusionが可能かどうかも、このステージで検出する。Core MAの時は次のように説明されていた。
「プリデコードは、命令ストリームの中のどこに命令があるのか見つけ出してマーキングする。x86 ISAの命令プリフィックスを見分け、命令を分類してデコーダでの『Macro-Fusion』に備える。このマシンでは最大6命令を1サイクルでマーキング可能と非常に効率が高い」
可変長で複雑なx86系命令の場合、CPUハードウェアにとっては、命令ストリームの中で、各命令の頭がどこにあるのかが判別しにくい。そこで、x86系CPUでは、命令デコードの前に、各命令の頭に境界を判別する「命令長マーキング(Instruction Length Marking)」を行なう。Core MA/Nehalemでは、これはプリデコードステージで行なっている。
6命令プリデコードは効率が高いが、Core MAでは、この効率を常に維持できるわけではない。まず、16bytesフェッチ幅の制約で、フェッチしたブロックに5命令以下しか含まれていない場合は、プリデコード帯域が落ちる。そのほかにも条件によって、プリデコードの効率が維持できないケースが出る。
例えば、オペランドやアドレスのサイズを変化させる命令プリフィックス「LCP(Length-Changing Prefixes)」があると、プリデコードが極めて遅くなる弱点。Core MAは、通常なら最大6命令を1サイクルでマーキングできるが、LCPがつくと効率が落ちてしまう。HPC Developer Conferenceで、IntelのJeffrey D. Gilbert(ジェフリー・D・ギルバート)氏(Xeon Processor Architect, Architecture & Planning, Digital Enterprise Group, Intel)は次のように説明していた。
「LCPプリフィックスがあると、プリデコードの際に命令マーキングを行なうアルゴリズム(Length Decoding Algorithm)を変えなくてはならない。これは非常にコストが大きい。LCPプリフィックスを使って、命令がイミディエイトを持つ場合、(最大で)6クロックのペナルティとなる。そのため、LCPプリフィックスを使わないことを推奨する」
つまり、Core MAのプリデコーダは、一定のモードでの命令マーキングでは1サイクルに6命令を切り出せるが、アルゴリズムが変わると最悪1サイクルに1命令までプリデコード効率が落ちてしまう。これでは、1サイクル4命令をデコード&発行できるパイプラインに充分な命令を供給できず、ボトルネックとなりかねない。Core MAの弱点のひとつだった。
 |
| LCPプリフィックスを使わないことを推奨 |
●実装コスト(トランジスタ数)的に見合わないプリデコーダの改良
しかし、IntelはNehalemでも、この問題を解決しなかった。Nehalemのアーキテクチャを担当したSinghal氏は、その理由を次のように説明する。
「Nehalemでも、Core MAと同様にLCP(Length Changing Prefixes)について、依然としていくつかの懸念事項がある。(Core MAの)『Software Optimization Guide』にある通りで、我々は、LCPを使わないように説明している。また、コンパイラはほとんどのケースではLCPを避けてコードを生成する。コンパイラが最適化するため、幅広いアプリケーションに渡っての全体的なパフォーマンスで見ると、LCPストールのインパクトはそれほど大きくはない。
LCPの問題も、(Nehalem設計の)いちばん最初の頃の改善リストにあった。我々は『ヘイ、このLCPストールはどうなんだ? 解決するべきなのか』と議論した。確かに、LCPの件もパフォーマンスを阻害している。しかし、この件を解決するために必要なコストに見合うほどの阻害要因ではなかった。なぜなら、LCPストールの件を解決するためのコストは非常に大きいからだ。
我々は、コストをかけてLCPのプリデコードを改善するよりも、別な解決法を考えた方がいいと判断した。一例を挙げると、ループストリームディテクタが走っているなら、LCPのストールは関係がなくなる。なぜなら、ループストリームのバッファでは、命令はすでにデコードされてしまっているからだ」
Nehalemの場合、ループが検知されると、ループ内の命令をuOPsレベルでバッファして繰り返し実行する。実行するのはuOPsであるため、ループ内の命令については、やっかいな命令プリデコードもその後のデコードも不要となる。当然、LCPストールも関係がなくなる。
命令フェッチに較べるとLCPの問題はマイナーだが、x86 CPUにとって命令マーキングが極めてやっかいな問題であることを浮き彫りにしている。命令プリデコード段階で、よりメジャーな問題を解決するために、Intelは膨大なトランジスタを割いているはずだ。それだけ多くの電力を、プリデコーダ段階で消費することになる。
ちなみに、プリデコード全般について見ると、Intelの次の命令拡張「Intel Advanced Vector Extensions (Intel AVX)」の「VEX(Vector Extension)」エンコードフォーマットが、有利になるかもしれない。VEXでは最初の1byteで、命令オペコードの位置がわかるため、命令マーキングがより容易になる可能性があるからだ。
もしかすると、将来のIntelのプリデコーダは、内部的にVEXモードと従来モードの2つのアルゴリズムに分かれていて、VEXフォーマットだと迅速にプリデコードできるが、従来のプリフィックスフォーマットだとプリデコードが遅いケースが出るといった違いが発生するかもしれない。Intelは、AVXをSSE系命令をほぼ内包できるように定義しており、SSEからAVXへと移行させたいとしている。それは、ハードウェア設計を容易にするための意味もあるかもしれない。
 |
| 将来を見据えた命令書式 |
 |
| CPUアーキテクチャの方向と命令セット PDF版はこちら |
●3~4命令の同時デコードは条件つきが合意事項?
Nehalemのフロントエンドパイプラインの、プリデコードまでの前半部分を見る限り、Intelは、一番やっかいな問題はそのままにしていることがわかる。いずれも、可変長&可変フォーマットのx86命令セット自体から来る制約だ。
もともと複雑だったx86命令セットアーキテクチャに、さらに増築を重ねた現在のx86命令は、複雑になりすぎており、命令プリデコード&デコードの負担は大きい。そして、Intelは、その部分の改良が、Nehalemの1対1電力効率の原則に合致しないことを明らかにした。つまり、x86命令の複雑性から来る問題は、改良しようとすると、トランジスタと電力を非常に食ってしまうので、電力効率の維持の観点から合理的ではないと判断された。
こうして見ると、Nehalemでは、フロントエンドにボトルネックがそのまま残されているようだが、それは、設計の最初から織り込み済みなのかもしれない。x86 CPUの現実としては、3~4命令同時デコードは、限られたケースでしか現実的ではないと割り切っているという指摘もあるからだ。CPUアーキテクトとしてIBM時代から有名なGlenn Henry(グレン・ヘンリー)氏(President and Founder, Centaur Technology)は次のように語る。
「(x86 CPU設計者の)誰もが同意しているのは、3から4命令の同時デコードにはいくつかの制約があるということだ。常に3から4命令の同時デコードができるとは、皆、考えていない。そして、通常は、おかしなプリフィックス(Funny Prefixes)が、ついてない場合のみを想定している。Intelも、おかしなプリフィックスがない“ノーマル命令(Normal Instruction)”を、3から4命令ずつデコードすることを前提としているはずだ。これは、我々の『Isaiah』(VIA Technologies/Centaur Technologyの次期CPUアーキテクチャ)の場合でも同じだ。それ(ノーマル命令)以外のケースに(3~4命令の同時デコードを)拡張しようとすると、デコーダが極端に複雑になってしまうだろう」
Henry氏が指摘するのは、先端x86 CPUの3~4命令という命令デコード帯域は、イレギュラなプリフィックスがついていない命令を想定しており、それ以外のケースでは命令デコード帯域が落ちることは織り込み済みということだ。3~4命令のデコードは、あくまでもピーク帯域で、平均値は落ちると考えていると推定される。だとしたら、上流のフェッチ&プリデコードにボトルネックがあっても問題ではなくなる。
Nehalemの説明の通りだとすると、電力効率を考えた場合、無理に命令プリデコード&デコードを拡張することは得策ではないことになる。そうすると、当然、今後の解決策として想定されるのは、「命令フェッチからデコードまでをできるだけスキップすること」になる。将来のIntelのPC向けCPUの発展は、そうした方向へ向かってゆくのかも知れない。
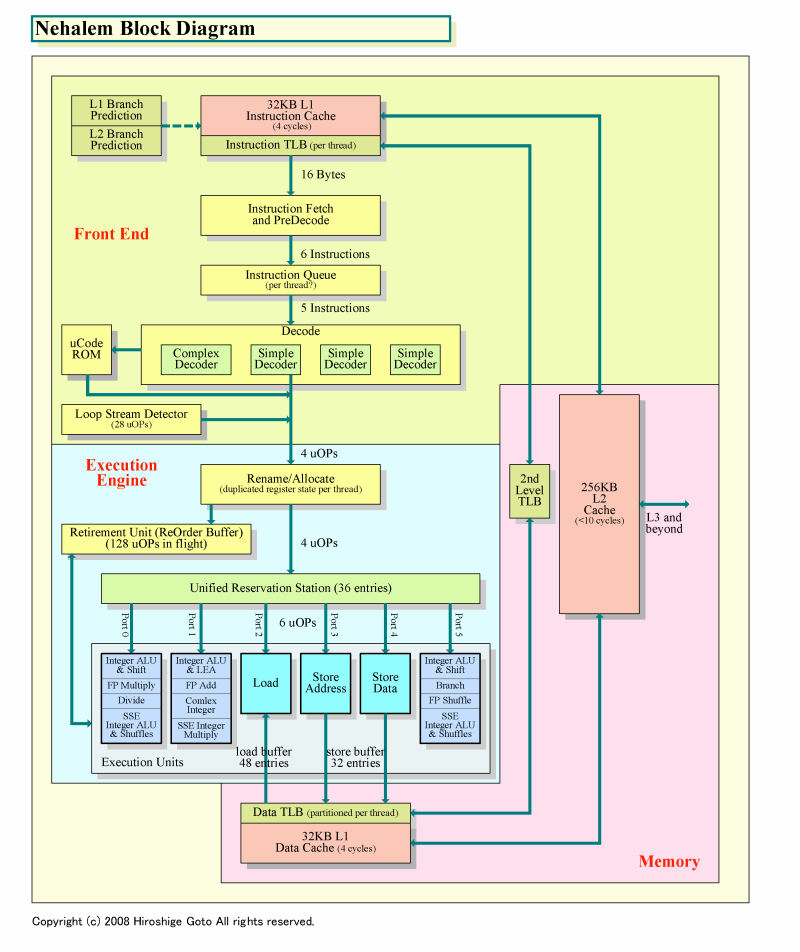 |
| Nehalemアーキテクチャのブロックダイヤグラム PDF版はこちら |
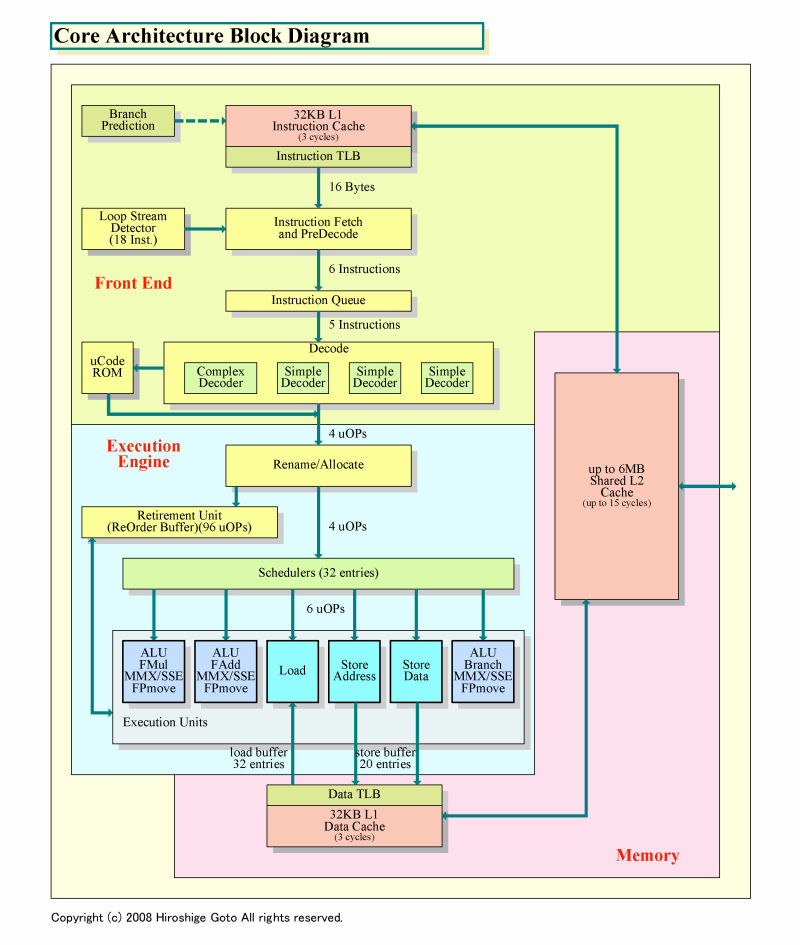 |
| Coreアーキテクチャのブロックダイヤグラム PDF版はこちら |
□関連記事
【4月24日】【海外】Intelの次期CPU「Nehalem」の設計思想は“1 for 1”
http://pc.watch.impress.co.jp/docs/2008/0424/kaigai437.htm
【4月10日】【海外】なぜIntelはSandy Bridgeに「AVX」を実装するのか
http://pc.watch.impress.co.jp/docs/2008/0410/kaigai435.htm
【4月7日】【海外】x86からの脱却を図るIntelの新ロードマップ
http://pc.watch.impress.co.jp/docs/2008/0407/kaigai434.htm
【3月21日】【海外】モバイルにもL3キャッシュをもたらすNehalem
http://pc.watch.impress.co.jp/docs/2008/0321/kaigai427.htm
【1月29日】【海外】2つのCPU開発チームに競わせるIntelの社内戦略
http://pc.watch.impress.co.jp/docs/2008/0129/kaigai412.htm
(2008年4月28日)
[Reported by 後藤 弘茂(Hiroshige Goto)]
【PC Watchホームページ】
PC Watch編集部 pc-watch-info@impress.co.jp ご質問に対して、個別にご回答はいたしません
Copyright (c) 2008 Impress Watch Corporation, an Impress Group company. All rights reserved.