 |


■後藤弘茂のWeekly海外ニュース■IDFで公開された「Nehalem」の内部アーキテクチャ |
●L2キャッシュまでを含んだCPUコアブロック
Intelは、4月2~3日にかけて中国上海で開催されている技術カンファレンス「Intel Developer Forum(IDF)」において、次期CPUマイクロアーキテクチャ「Nehalem(ネハーレン)」の概要を発表した。
Nehalemは一言で説明すると、現在のCore Microarchitecture(Core MA)の骨格に、新たにSMT(Simultaneous Multi-Threading)や3階層のキャッシュ、階層化したTranslation Lookaside Buffer (TLB)や分岐予測ユニットを始め、さまざまな機能を加えることでCPUコアのパフォーマンスアップを図ったCPUだ。加えて、高速インターコネクト「QuickPath Interconnect(QPI)」とDDR3 DRAMインターフェイスを実装し、システムアーキテクチャを一新した。
前回のNetBurst(Pentium 4)からCore MAへの転換は、マイクロアーキテクチャの基本部分の大革新だった。それに対して、今回のCore MAからNehalemへの移行は、基本部分での変化は小さいが、さまざまなテクニックを駆使することで、大幅なパフォーマンスアップを図っている。
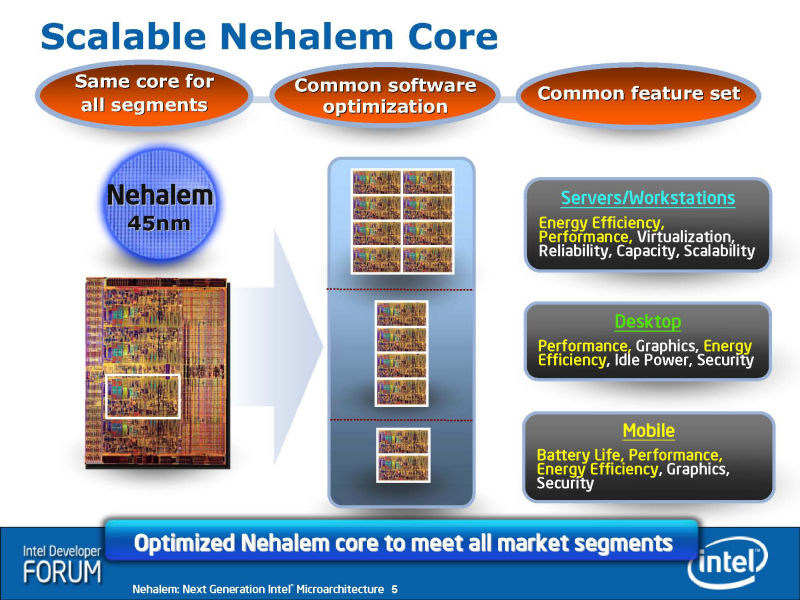
Intelによると、Nehalemのゴールは、レガシーアプリケーションと新しいアプリケーションの両方を高速化することだったという。しかも、パフォーマンスをアップするだけでなく、パフォーマンス/消費電力も向上させる。さらに、製品化ではモバイルやデスクトップ向けからサーバーまでスケーラブルに展開できるようにする。
IDFの技術セッションでは、NehalemのCPUコアブロックには、CPUコア占有のL2キャッシュも含まれていることが明らかにされた。つまり、Nehalemでは、各CPUコアに占有のユニット全てが、長方形のブロックにきれいにまとめられている。そのため、CPUコア設計をデュプリケイトすることで、デュアル、クアッド、オクタまでのマルチコア構成を比較的容易に設計することができる。
 |
 |
●類似性の強いCore MAとNehalemのブロックダイアグラム図
 |
上の図は、IDFで示されたNehalemのCPUコアのレイアウト図だ。このチャートでは、機能ブロックの分割が描かれているが、実は、これは全く正確ではない。よく見ると、下のユニットの境界と全然一致していない。あくまでも概念図ととらえてほしい。
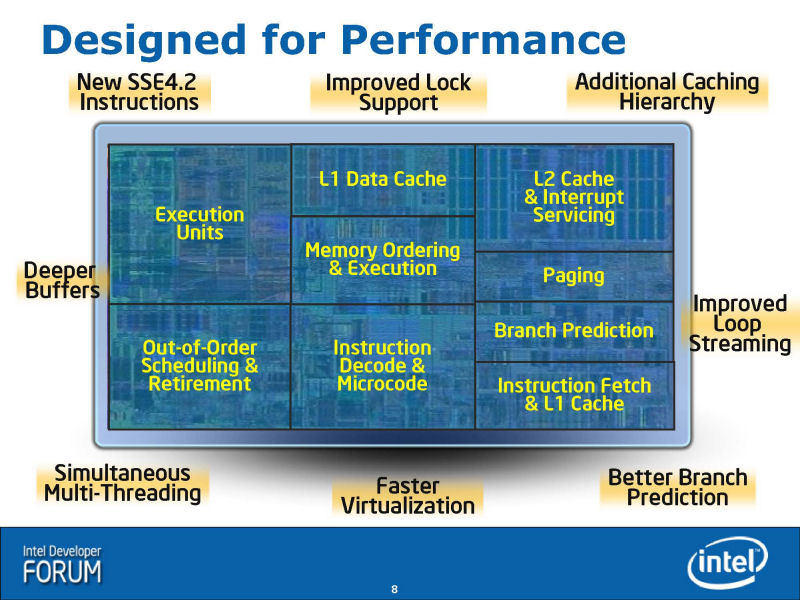
Nehalemで拡張された主な機能は、ダイレイアウトの周囲に書かれている通りだ。
- New SSE4.2 Instructions
- Improved Lock Support
- Additional Caching Hierarchy
- Deeper Buffers
- Improved Loop Streaming
- Simultaneous Multi-Threading
- Faster Virtualization
- Better Branch Prediction
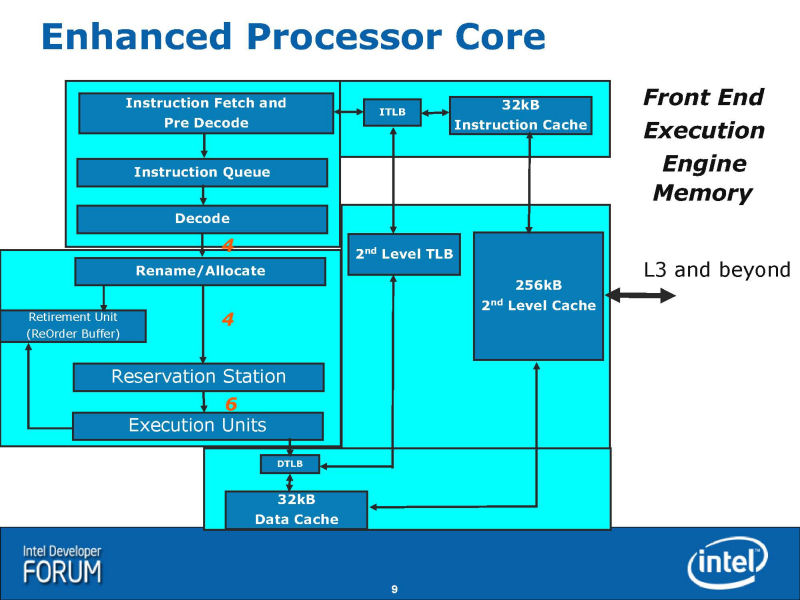 |
IDFでは、Nehalemの簡易なブロックダイアグラム図も公開された。上のスライドがそれだ。このスライドをベースに、他の要素を補完して作り直したのが下の図だ。Intelのオリジナルの図に欠けていた分岐予測やSMT(Simultaneous Multithreading)は、図に反映していない。
 |
| Nehalemブロック図 最新版 PDF版はこちら |
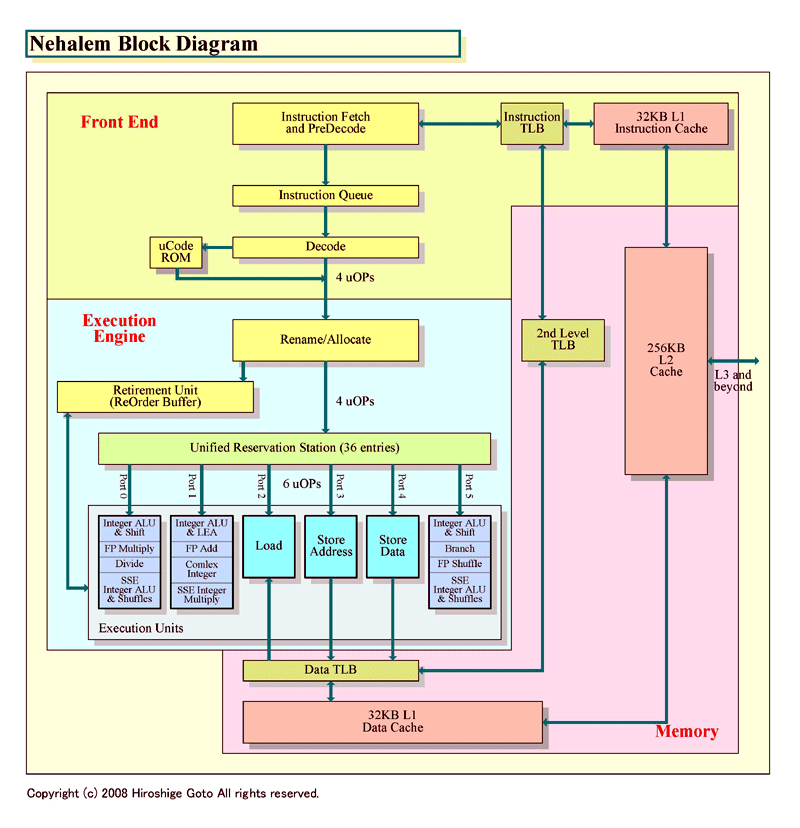
Nehalemのブロック図を一見して気がつくのは、Core MAのブロック図との類似性だ。Core MAのブロックダイアグラムをNehalemに合わせて、Intelのオリジナルの図から多少変更したのが下の図だ。両方の図で描写が統一されていない部分(TLBの表現など)は、Intelが示したそれぞれのCPUのオリジナルのブロック図に準じている。表現上の違いで、機能的な違いをこれで表しているわけではない。
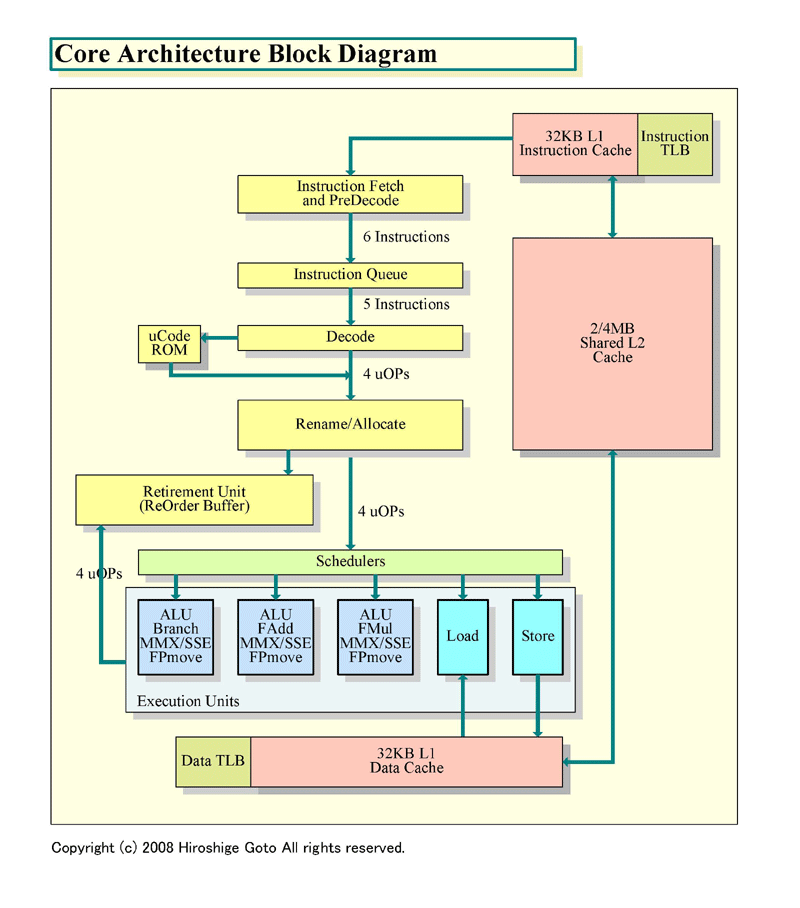 |
| Core Architectureブロック図 最新版 PDF版はこちら |
2つの図を見比べると、類似性は明瞭だ。全体の構成はよく似ている。これは、CPUマイクロアーキテクチャを貫くフィロソフィが共通していることも意味している。
●Pentium 4開発センターらしい改良が加えられたフロントエンド
上から見てゆくと、まず、フロントエンド回りは類似性が特に強い。デコーダでx86命令を1サイクルで最大4命令デコードして、内部命令である「uOPs(micro-operations:マイクロオプス)」に変換する。NetBurst(Pentium 4)では、デコード時にx86命令を細かなオペレーションに分割してしまう。それに対して、Core MAでは、複数のuOPsが融合した形の「Fused-uOPs(フューズドuOPs)」に、ほぼ1対1で変換する。Intelは、これを「Micro-OPs Fusion」と呼んでいるが、Nehalemでもこの特長はそのまま継承される。
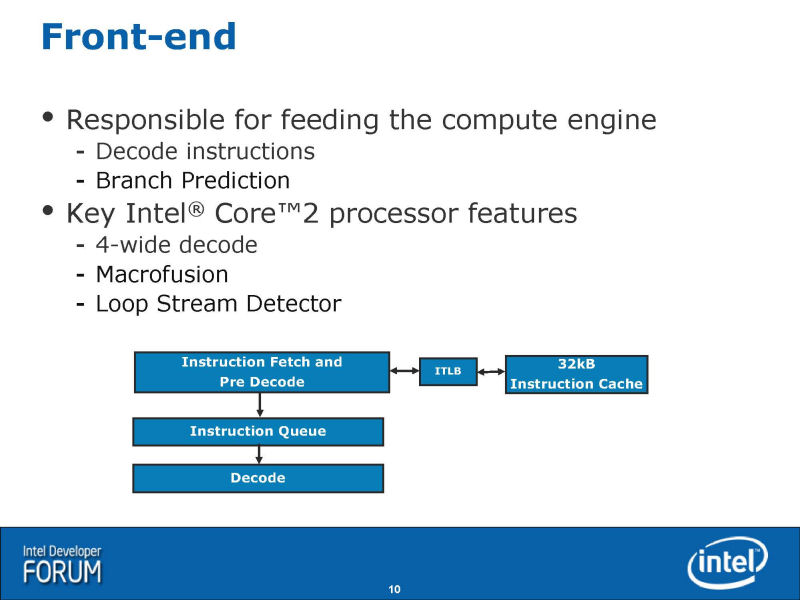 |
Core MAでは、特定のx86命令のペアを1個のFused-uOPに融合させるMacro-Fusionも実装された。Nehalemでは、この機能も継承するが、若干拡張している。Macro-Fusionできる命令の組み合わせが増やされた。また、Core MAでは、Macro-Fusionは32-bitモード時にしかイネーブルされなかったが、Nehalemでは64-bitモード時にもMacro-Fusionされるようになった。
 |
Nehalemを開発したのは、NetBurstを開発したオレゴン州ヒルズボロの開発チームだ。そのため、Nehalemにはところどころ、NetBurstを彷彿とさせる機能が見られる。その1つが「Loop Stream Detector(LSD)」だ。ループで同じ命令群が繰り返し実行される場合、Loop Stream Detectorは、命令フェッチと分岐予測をバイパスして、すでにフェッチしてあるループ内の命令を繰り返し実行させる。命令フェッチと分岐予測のロスがなくなり、パフォーマンスが上がる。
Core MAでは、Loop Stream Detectorは、命令デコーダの前になり、x86命令をバッファしてデコーダに送り込んでいた。それに対して、NehalemではLoop Stream Detectorが命令デコーダの後にあり、uOPsをストックする。そのため、x86アーキテクチャの最大の関門である命令デコードをバイパスし、パフォーマンスを引き上げることができる。下の図がCore MAのLoop Stream Detector、更にその下の図がNehalemのLoop Stream Detectorだ。デコーダのバイパスは、NetBurstの基本フィロソフィであり、Nehalemでは一部にそれが活かされている。
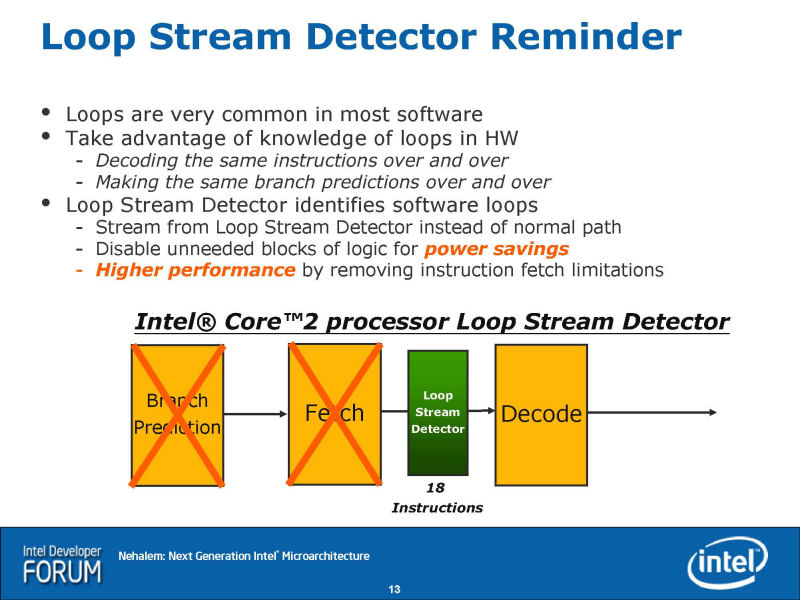 |
| Core MA Loop Stream Detector |
 |
| Nehalem Loop Stream Detector |
分岐予測では2レベルの「Branch Predictor(ブランチプレディクタ)」と「Renamed Return Stack Buffer (RSB)」が実装された。これは、IDFのプレビュカンファレンスでの説明通りだ。
 |
 |
●命令発行ポートは5から6へと増加
NehalemのエグゼキューションエンジンもCore MAより強化された。エグゼキューションエンジンに命令を発行するポート数が、Core MAの5からNehalemでは6ポートに増える。つまり、命令スケジューラは最大6uOPsを実行ユニット群に送ることができる。Core MAでは最大5uOPsだった。
6つの命令発行ポートは、3つのコンピュテーショナルオペレーションと、3つのメモリオペレーションに分かれる。Nehalemでは、浮動小数点演算パフォーマンスが飛躍するが、浮動小数点演算ユニット自体が増えているわけではない。浮動小数点SIMD演算の加算は1ユニット、乗算は1ユニットで、いずれも128bit幅。基本的なユニットの構成はCore MAと変わらない。
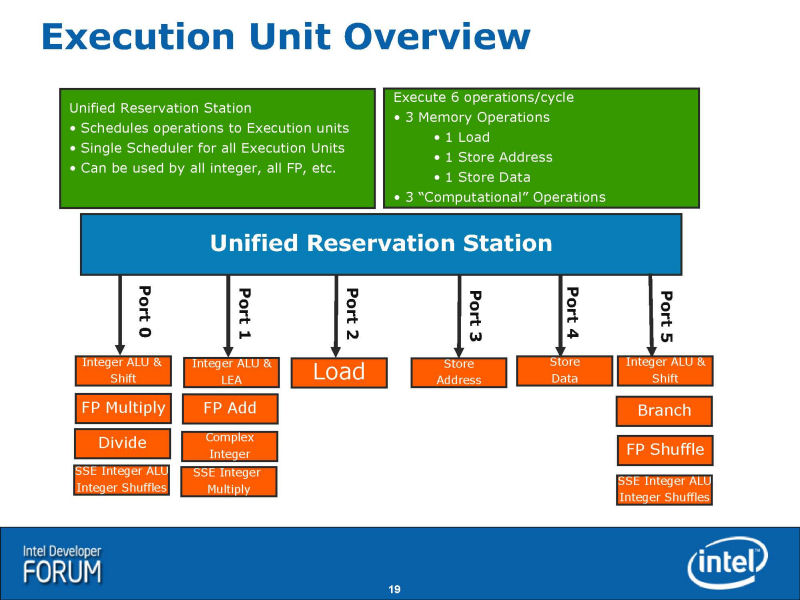 |
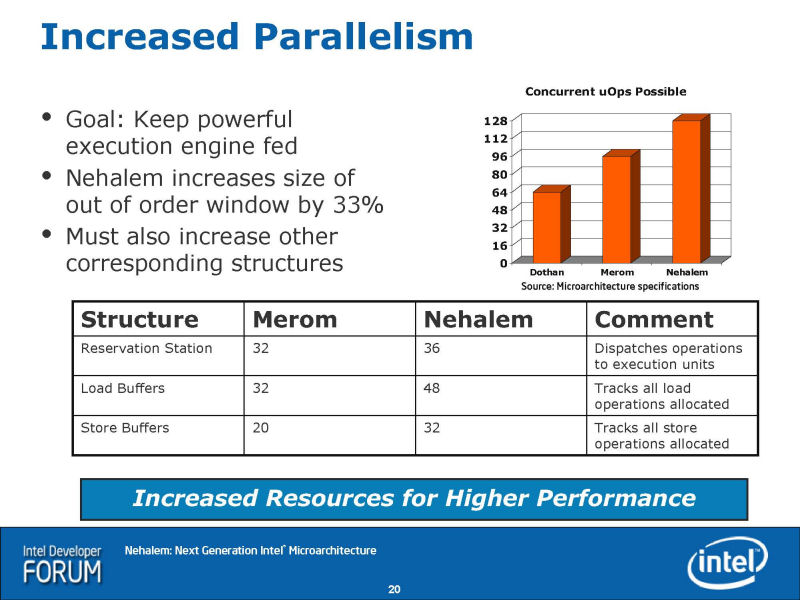 |
Nehalemでの改良点はいくつかある。1つは、アウトオブオーダウインドウの拡大で、Nehalemは128個のuOPsをオンザフライで制御できる。Core MAでは96個だった。Nehalemでは、それ以外のバッファも深くなっている。リザベーションステーションやロードバッファとストアバッファは、いずれもNehalemでエントリ数が増やされている。
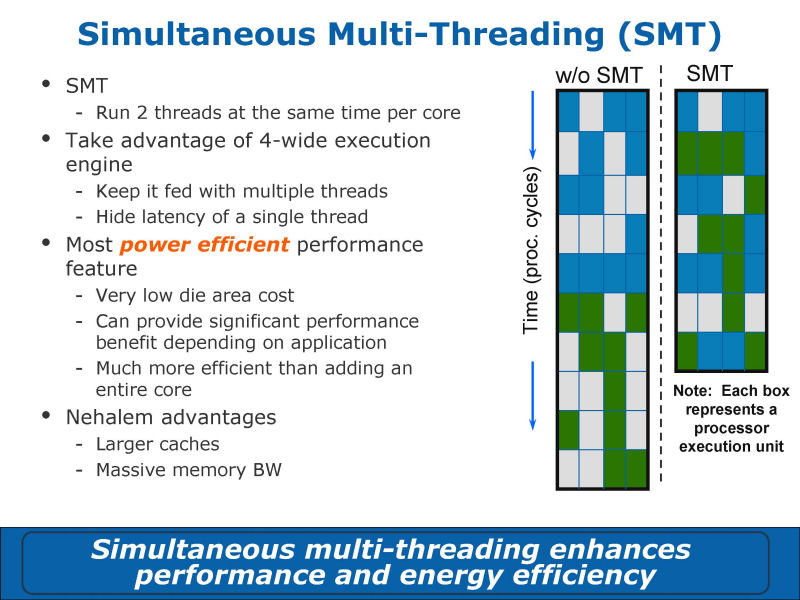
Nehalemで最も大きな拡張ポイントの1つは、SMT(Simultaneous Multithreading)だ。Hyper-Threadingのように、2つのスレッドを1つのCPUコアで走らせることができるSMTがNehalemには実装されている。
IntelでNehalem開発を担当したRonak Singhal氏によると、NehalemでのSMT開発に携わったのは、NetBurstにSMTを実装したのと同じチームだという。そのため、フィロソフィは同じで、Nehalemでは、メモリ帯域の余裕が増えた分、SMTによる性能向上がより顕著になるという。NehalemのSMTは、CPUコア部分のダイ面積の5~10%の増加分で実現しており、非常にパフォーマンス/消費電力の効率がいいという。
 |
 |
メモリ回りもNehalemでは強化された。物理メモリアドレスをキャッシュする「Translation Lookaside Buffer (TLB)」は2階層化される。アンアライン(unaligned)キャッシュアクセスの高速化と、マルチスレッドアプリケーションで重要となる同期プリミティブの高速化も実現される。
 |
 |
 |
●低いNehalemのメモリアクセスレイテンシ
Nehalemでは、L1、L2、L3の3階層のキャッシュ構成となった。各CPUコア毎に32KBのL1命令キャッシュとL1データキャッシュ、それに256KBの専用L2キャッシュを備える。さらに3層目として、CPU中の全てのCPUコアで共有する大容量のL3キャッシュを備える構成となる。Singhal氏によると、各CPUコア占有のL2キャッシュを導入した理由は、レイテンシの低減とスケーラビリティのためだという。キャッシュを小容量化することで高速アクセスを可能にし、スケーラビリティによる製品の差別化はL3の量で調整する。
Nehalemでは、CPUにメモリインターフェイスを統合したことで、メモリアクセスレイテンシは劇的に減少したという。Nehalemでは、CPUに直結されたDRAMにアクセスする場合だけでなく、マルチプロセッサ構成で他のCPUに接続されたDRAMにアクセスする場合もレイテンシが比較的短いという。下がそのチャートで、現在のサーバーCPU「Harpertown」と比べると、マルチプロセッサの他のCPUのメモリにアクセスするリモートアクセスですら、より高速であることがわかる。
 |
 |
 |
NehalemでCPU同士を直結しているのは、新しい高速インターコネクトQuickPath Interconnect(QPI)だ。QPIに実装されたと言われる、新しいキャッシュコヒーレンシプロトコル「MESIF」については今回は説明がなかった。ちなみに、前回のMESIFの説明では、表の一部が欠けていた。正確には下の表となる。
| Cache line states | |||||
|---|---|---|---|---|---|
| state | clean/dirty | write | forward | transition to | |
| M | modified | Dirty | OK | OK | |
| E | exclusive | Clean | OK | OK | M,S,I,F |
| S | shared | Clean | No | No | I |
| I | invalid | - | No | No | |
| F | forward | Clean | No | OK | S,I |
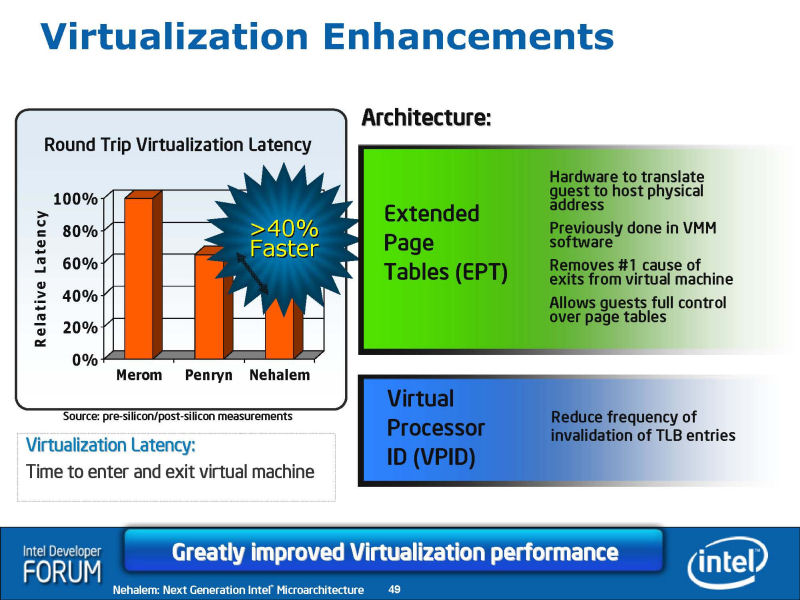
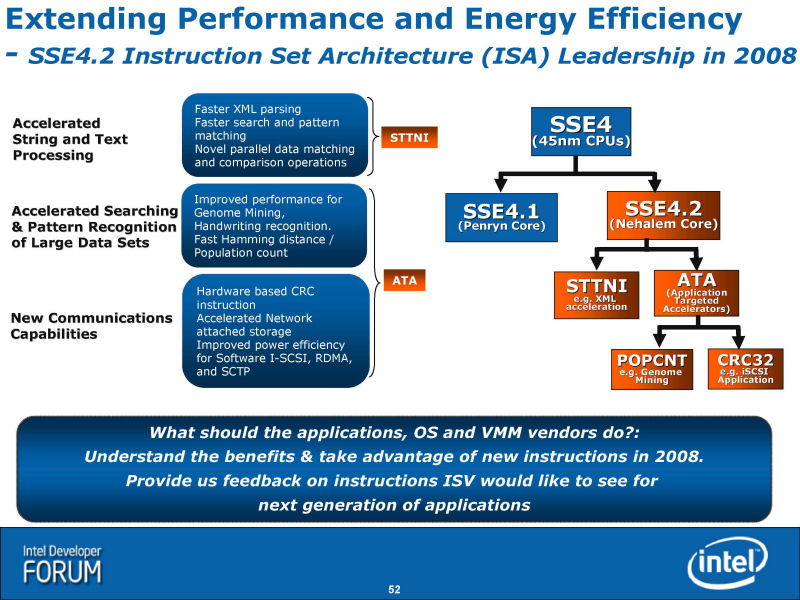
Nehalemでは、仮想化の際のレイテンシも低減され高速化が図られている。「Virtual Processor ID (VPID)」と「Extended Page Table (EPT)」が実装された。Nehalemでは、新たにSSE4の積み残しの命令群が「SSE4.2」として実装される。いずれも、非常に複雑な処理の命令群で、CPU内部でマイクロコードにより一連のuOPs群に分解されると推定される。
 |
 |
IDFで明らかにされたNehalemの概要を見ると、Core MAの時のような大きな転換はないものの、非常に多くのテクニックが集大成されていることがわかる。インターフェイス回りの改良に目を奪われがちだが、CPU内部のアーキテクチャ拡張も非常に多岐に渡っている。手堅くパフォーマンスを引き上げた、マイクロアーキテクチャだ。
□関連記事
【4月1日】【海外】NehalemとDiamondvilleが見えてきたIntelのモバイルロードマップ
http://pc.watch.impress.co.jp/docs/2008/0401/kaigai431.htm
【3月21日】【海外】モバイルにもL3キャッシュをもたらすNehalem
http://pc.watch.impress.co.jp/docs/2008/0321/kaigai427.htm
【1月29日】【海外】2つのCPU開発チームに競わせるIntelの社内戦略
http://pc.watch.impress.co.jp/docs/2008/0129/kaigai412.htm
(2008年4月3日)
[Reported by 後藤 弘茂(Hiroshige Goto)]
【PC Watchホームページ】
PC Watch編集部 pc-watch-info@impress.co.jp ご質問に対して、個別にご回答はいたしません
Copyright (c) 2008 Impress Watch Corporation, an Impress Group company. All rights reserved.