 |


■後藤弘茂のWeekly海外ニュース■大きく異なるRadeon HD 2000とGeForce 8000のアーキテクチャ |
●スカラ命令に適したアーキテクチャを求めて
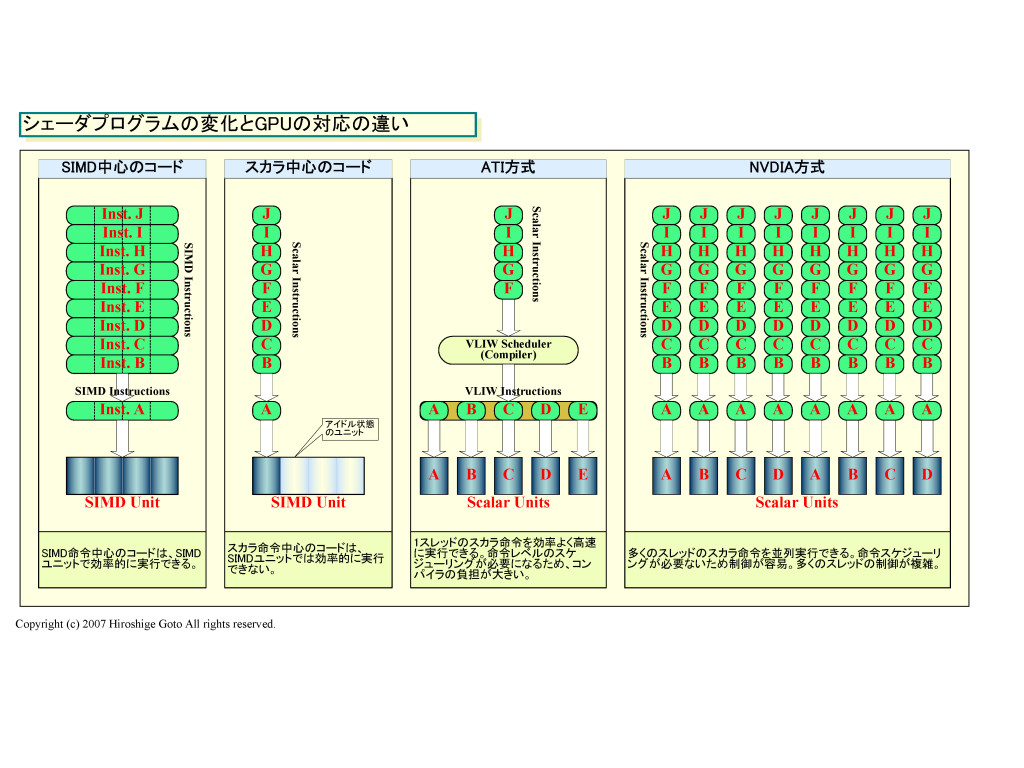
AMD(旧ATI)の「Radeon HD 2000(R6xx)」アーキテクチャとNVIDIAの「GeForce 8000(G8x)」アーキテクチャには、基本的な違いがある。それは、シェーダプロセッサの構成と制御だ。同じ問題に対して2社が出した回答は、全く逆のアプローチだった。両社のアプローチの違いを簡単に図式化したのが下のチャートだ。
 |
| シェーダプログラムの変化とGPUの対応の違い PDF版はこちら |
従来は、GPUの実行するコードは、1命令で複数のデータに対して同時に同じ処理をするSIMD(Single Instruction, Multiple Data)型処理が中心だった。命令の多くがSIMD命令なので、実行ユニットも1命令で複数データを処理するSIMD型ユニットが最適だった。
しかし、GPUが実行するコードの中にスカラ型命令が増えて来ると、SIMDユニットではムダが生じてしまう。例えば、典型的な4-wayのSIMDユニット(vec4)の場合、4個の演算ユニットが1セットとなっている。そのため、スカラ命令を実行すると、使われる演算ユニットは1個だけで、他の3個の演算ユニットはアイドルになってしまう。
そこで、前世代のGPUでは、SIMDユニットを、1-wayのスカラユニットと3-way SIMDユニットに分離するといった、MIMD(Multiple Instruction, Multiple Data)型の使い方もできるようにしていた。その場合は、2命令を同時に実行できるため、より効率的に実行ユニットを稼働させることができる。しかし、スカラ命令が連続するようなコードになると、それでもシェーダプロセッサは非効率になってしまう。
従来は、GPUが実行するプログラムはSIMD中心だったため、こうしたアーキテクチャでもよかった。しかし、GPUの実行するプログラムが変化しつつあるため、今後はGPUの効率が悪化してしまう。つまり、プログラムが進化するにつれて、同じGPUでも実効性能が下がって行ってしまう可能性がある。
そこで、GPUベンダーは、GPUのシェーダプロセッサを、SIMD型の処理に最適化したSIMDユニットにせずに、スカラ型命令に適したスカラ型演算ユニットにしようとし始めた。それが、DirectX 10世代のGPUに共通した特徴となっている。そして、AMDもNVIDIAも、スカラ化した演算ユニットをどう制御するかに工夫をこらした。
●命令レベルの並列性を持ち込んだR600
AMDのR600では、シェーダプロセッサである「5-wayスーパースカラシェーダプロッサ」の中に、スカラ演算ユニットである「ストリームプロセッシングユニット」を5個搭載した。
「5というユニット数は、前世代のバーテックスシェーダプロセッサの構成と一致する。前世代では、Vec4(4-way SIMDユニット)プラス1(スカラユニット)だった。R600でも、同じアレンジを維持することにした。しかし、今回はVec4フォーマットではなく、完全に独立したスーパースカラ構成にした。
各アレイ(シェーダプロセッサ)は、5種類の完全に分離された演算ユニット(ALU)と分岐ユニット、レジスタファイルからなる。各演算ユニットは、それぞれ独立したスーパースカラ方式で動作する」とR600のアーキテクトであるEric Demers氏(Senior Architect, AMD Graphics Products Group)は説明する。
R600のシェーダプロセッサの中の演算ユニットは、いずれも同じスレッドの中の別々な命令を並列に実行できる。分離されたスカラ演算ユニットとなっており、それぞれ個別のレジスタに対して個別のオペレーションが可能だ。例えば、演算ユニットAが命令AをレジスタAに対して、演算ユニットBが命令BをレジスタBに対して、それぞれ実行することができる。つまり、IntelやAMDのCPUと同じように、個々のユニットが個別に動作できる。よりCPU的になったと言える。
ただし、AMDは実行ユニットを動作させる命令のフォーマットにVLIW(Very Long Instruction Word)方式を採用した。VLIWでは、長い命令語の中に複数の命令を格納することができる。命令をコンパイルする際に、並列に実行できる複数の命令を抽出して、1個のVLIW語の中に納める。プロセッサ側では、VLIW命令の中から個々の命令を取りだして、複数の演算ユニットで並列に実行する。1個のVLIW命令に含まれる命令は、全てコンパイラにより並列実行が可能であることが検証されている。そのため、プロセッサ側には命令の依存性のチェックを行なって命令を並べ替える必要がない。プロセッサをシンプルに保つことができる。
図に従って説明すると、GPUが実行する命令ストリームの中から、コンパイラが依存性のない命令を抽出する。例えば、命令Aに続く命令B、命令C、命令D、命令Eがそれぞれ依存性がない場合には、A/B/C/D/Eの5命令を同時に実行することができる。すると、コンパイラが命令A、B、C、Dを1個のVLIW命令の中に納める。実行時には、シェーダプロセッサの中のスカラ実行ユニット群が、VLIWの中のそれぞれの命令を個別に実行する。図のケースでは、スカラ演算ユニットAがVLIWの中の命令Aを、演算ユニットBが命令Bを実行する。
 |
| R600の概要 PDF版はこちら |
●スレッドレベルの並列性にフォーカスしたG80
NVIDIAのG8xのアーキテクチャは、R6xxとは対極的だ。G8xでも演算ユニットをSIMDではなくスカラに構成している。各スカラ演算ユニットが、それぞれ個別のデータアイテムに対して命令を実行できる。ピクセルプロセッシングを例に取ると、G8xではスカラ演算ユニット、それぞれを別なピクセルに対して処理を行なうことができる。例えば、演算ユニットAがピクセルAを処理し、演算ユニットBがピクセルBを、といった具合だ。
しかし、G8xアーキテクチャの場合、1個のシェーダクラスタ(Streaming Multiprocessor:SM)の中の8個のスカラ演算ユニットは、同じクロックサイクルに同じ命令しか実行できない。つまり、サイクル0には演算ユニットAが命令AをピクセルAに対して、演算ユニットBが命令AをピクセルBに対して、実行する。演算ユニット自体はスカラ構成で独立動作が可能だが、命令実行の仕組み自体は、シェーダクラスタであるSM全体で見るとSIMD発行となっている。SIMD発行だが、各演算ユニットの処理自体は、別なデータアイテムに対するため、並列している。命令レベルの並列性ではなく、「スレッドレベルの並列性(TLP:Thread-Level Parallelism)」に、より寄ったアーキテクチャだ。
もっとも、実際には、NVIDIAのG8x系の演算プロセッサには、一般的な浮動小数点積和算ユニットの他に、より複雑な演算を行なうスーパーファンクションユニットがある。これは4個の積和算ユニット間での共有リソースで、別命令を実行できる構造となっている。しかし、積和算(MAD)については、シングルパイプとなっている。
 |
| G80の概要 PDF版はこちら |
●R600とG80にはそれぞれの利点と難点がある
AMDとNVIDIAのそれぞれの方式は、各々の利点と難点がある。AMD方式では1スレッドの命令ストリームの中の複数の命令を並列に実行できる。いわゆる「命令レベルの並列性(ILP:Instruction-Level Parallelism)」が高い。そのため、スーパースカラCPUと同様に、スカラ命令が中心のコードでも、比較的低い周波数で高いスレッドパフォーマンスを実現できる。
その反面、各命令間の依存性をチェックして並べ替える命令スケジューリングが必要になる。IntelやAMDのCPUは、ハードウェアで依存性をチェックして並列実行するが、その方式はプロセッサを複雑化してしまうためGPUでは採用しにくい。AMDはGPUではソフトウェアで並べ替える、VLIW方式を選択した。
問題は、コンパイラがヘビーワークになることだ。リアルタイムコンパイラが、命令の依存性をチェックして並べ替え、VLIWの中にパックしなければならない。これはシリアルタスクで重い処理となる。また、うまく命令をパックできない、依存性のある命令が続く場合には、理論値のピーク性能を引き出せない恐れがある。
それに対して、NVIDIA方式では、命令レベルの並列性にはフォーカスしていない。そのため、命令間に依存性のあるスカラコードを速く実行できる。また、コンパイラワークは従来のGPU同様に非常に楽だ。
しかし、その反面、G80のアプローチの場合、多くのスレッドを制御する必要がある。各スカラユニットがそれぞれ別のピクセルをプロセッシングするため、G8xアーキテクチャでは小さな単位でシェーダクラスタを組む必要がある。実際にNVIDIAは、8個のストリーミングプロセッサでクラスタである「Streaming Multiprocessor(SM)」を構成している。クラスタの粒度が小さくなるから、スレッド数が増える。例えば、R600は特定のクロック時に実行しているスレッドは4スレッドだが、G80場合は16スレッドになる。そのため、スレッド制御がより複雑になる。
●GPUでは必ずしも不利ではないVLIW
R600の抱えているハードルは、TransmetaのVLIW型CPU「Crusoe」や「Efficeon」に近い。Transmetaアーキテクチャでは、x86のシリアルの命令ストリームを、パラレルのVLIW命令フォーマットにリアルタイムコンパイルしている。この方式は、Transmeta CPUがPC市場から消えたためにイメージが悪い。
しかし、GPUの特性を考えるとVLIWへのコンパイルは必ずしも悪いアイデアではない。CPUの場合、場合によってはスパゲティのようになった複雑で長大な命令ストリームを、並列化しなければならない。また、シングルスレッド性能が重要で、短レイテンシが求められるためリアルタイムに最適化して行く必要がある。
それに対して、GPUでは、グラフィックスでも非グラフィックスでも、比較的短いプログラムで、膨大な数のデータに対する処理を行なう場合が多い。そのため、命令スケジュールにある程度時間をかけて最適化したVLIWコードで、一気に多くのデータを処理するといったスタイルが理にかなう。また、実行パイプが膨大な処理をこなしている間に、命令スケジュールを行なうことができる。命令スケジューリングが必要ないSIMD命令が多い場合には、さらにオーバーヘッドは減る。
また、CPU側の進歩もR600を助ける。CPUはどんどんマルチコア化を進めており、CPUの演算リソースも増大している。VLIW命令へのスケジューリングのようなシリアルタスクは、CPUの得意とするタスクだ。ドライバが重くなっても、マルチコア化したCPUには、それに応えられる余裕がある。
●シェーダコア全体の構成が大きく異なるR600とG80
こうした設計思想の違いから、R600とG80ではシェーダコアアレイ全体の構成が全く異なっている。R600方式では、シェーダのスカラ演算ユニットは5ユニットでシェーダプロセッサを構成している。このシェーダプロセッサの中では、命令はVLIWによってスーパースカラに発行される。
 |
| R600/G80のシェーダ構成 PDF版はこちら |
そしてシェーダプロセッサは16個づつでシェーダクラスタ「SIMDアレイ」を構成している。SIMDアレイの中では、各シェーダプロセッサに対してVLIW命令がSIMD発行される。つまり、同じVLIW命令が16個のユニットに対して発行される。1つのSIMDアレイの中の16個のシェーダプロセッサは、違うVLIW命令を実行することはできない。同時に同じVLIW命令を実行する。R600の場合は、このシェーダクラスタSIMDアレイが4個搭載されている。つまり、4スレッドが同時に走る構造となっている。
 |
| SIMD発行されるR600のVLIW命令 PDF版はこちら |
G80では、そもそも従来のようなシェーダプロセッサの構造は分解されてしまっている。シェーダクラスタに当たるStreaming Multiprocessor(SM)の中に、8個の演算ユニットであるストリーミングプロセッサがある。各々の演算ユニットがシェーダプロセッサのようなイメージだ。そして、8個のユニットに対して命令ユニットが、命令をSIMD発行する。R600と異なり、各ユニットは個別の命令を走らせることはできない。同じ命令をステップ毎に実行して行く。
G80の場合は、このクラスタStreaming Multiprocessorが2個で、1個のより大きなクラスタ「TPC(Texture Processor Cluster)」を構成している。G80全体では、TPCが8個含まれている。各Streaming Multiprocessorに含まれるプロセッサコアが8個なのは、分岐粒度を小さく保つためだ。
シェーダプロセッサでは実行レイテンシを隠蔽するために複数データアイテムに対する処理を連続して行なう。8個のプロセッサがそれぞれ4ピクセルに対する命令を4サイクルに渡って実行すると、32ピクセルが粒度となる。粒度を32までに保とうとしたら、8プロセッサ構成となってしまう。そのため、同時に制御しなければならないスレッド数が増えてしまう。
こうして概観すると、G80とR600はそれぞれの設計思想を追求した結果必然的に生まれたアーキテクチャだということがわかる。
□関連記事
【5月15日】【海外】ラディカルなAMDの「Radeon HD 2000」アーキテクチャ
http://pc.watch.impress.co.jp/docs/2007/0515/kaigai358.htm
【4月16日】【海外】スケーラブルに展開するNVIDIAのG80アーキテクチャ
http://pc.watch.impress.co.jp/docs/2007/0416/kaigai350.htm
【2006年11月19日】【海外】これがGPUのターニングポイントNVIDIAの次世代GPU「GeForce 8800」
http://pc.watch.impress.co.jp/docs/2006/1109/kaigai316.htm
【2006年7月27日】【海外】正反対の方法論で対決するATIとNVIDIA
http://pc.watch.impress.co.jp/docs/2006/0727/kaigai291.htm
(2007年5月18日)
[Reported by 後藤 弘茂(Hiroshige Goto)]
【PC Watchホームページ】
PC Watch編集部 pc-watch-info@impress.co.jp ご質問に対して、個別にご回答はいたしません
Copyright (c) 2007 Impress Watch Corporation, an Impress Group company. All rights reserved.