 |


■後藤弘茂のWeekly海外ニュース■全面改良ではなく、部分改良に留まったPenryn |
●ドライブされるPenrynファミリの普及
 |
北京で開催されたIntelのデベロッパ向けカンファレンス「Intel Developer Forum(IDF) Beijing 2007」。今回のIDFでは、PC向けCPUでは、45nmプロセスの「Penryn(ペンリン)」ファミリがクローズアップされた。Penrynファミリの動作デモが盛んに行なわれ、45nmプロセスで製造されるこの新CPUの準備が進んでいることが強調された。
実際、IntelはIDF前後に顧客に対するロードマップを変更。Penrynの普及計画をさらに加速させた。新プロセスCPUであるにもかかわらず、Penrynは2008年に入ると、デスクトップとモバイルのメインストリームCPUに一気に浸透する。IntelがPenrynの仕上がりに自信を持っていることがよくわかる。また、Penrynファミリのデスクトップ向けCPUである、デュアルコア「Wolfdale(ウルフデール)」とクアッドコア「Yorkfield(ヨークフィールド)」向けに、2008年第2四半期には次々世代チップセット「Eaglelake(イーグルレイク)」ファミリも登場する。
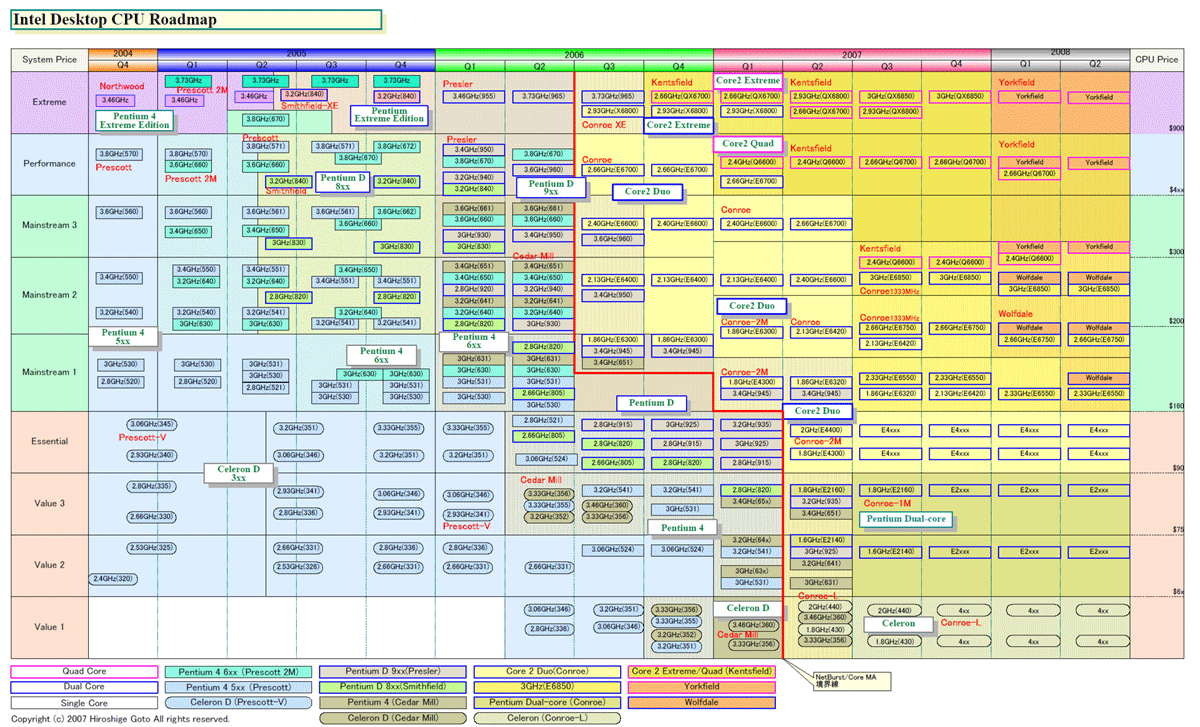 |
| Intel デスクトップCPUロードマップ(※別ウィンドウで開きます) PDF版はこちら |
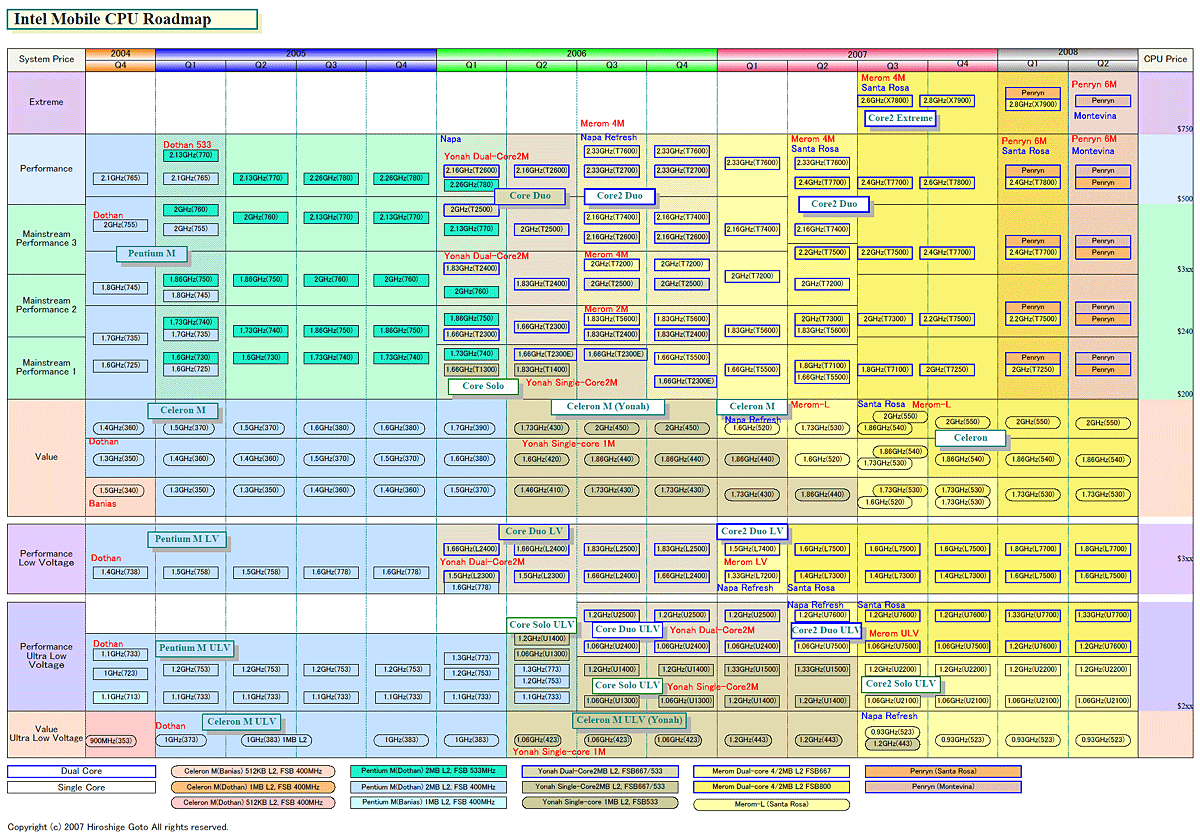 |
| Intel モバイルCPUロードマップ(※別ウィンドウで開きます) PDF版はこちら |
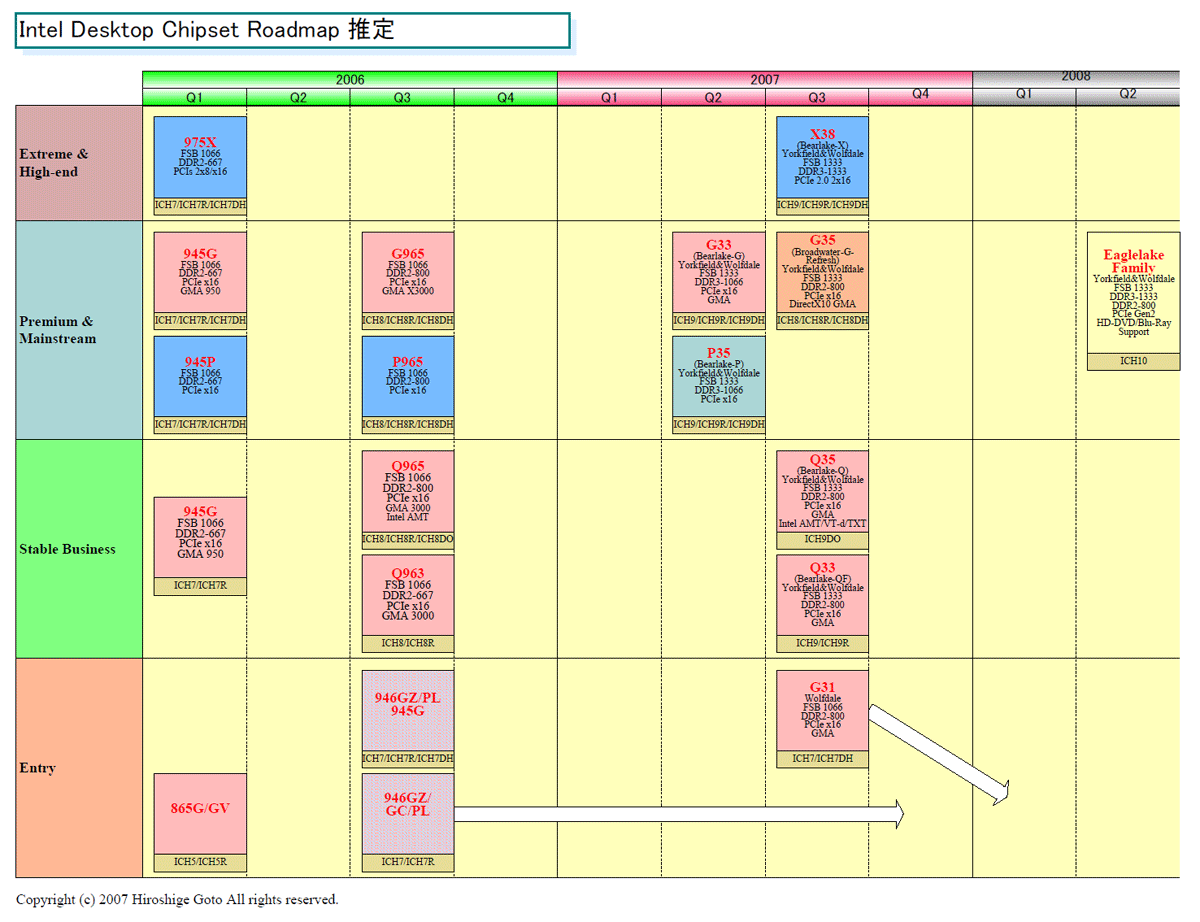 |
| Intel デスクトップ用チップセットロードマップ(推定)(※別ウィンドウで開きます) PDF版はこちら |
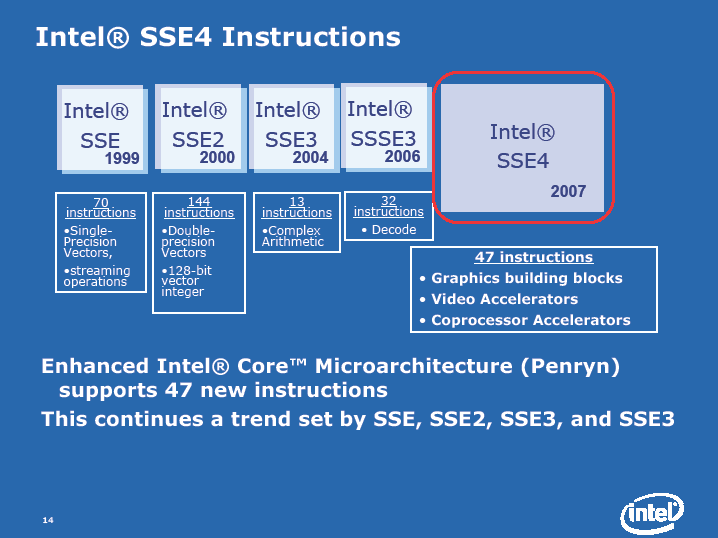
Penrynは45nmプロセスで製造されるだけではなく、SSE4命令が実装され、L2キャッシュもデュアルコアで6MBまで強化される。また、低リーク電流(Leakage)の45nmプロセスのおかげで、動作周波数もある程度向上するとされている。
しかし、Penrynは、基本的にはCore Microarchitecture(Core MA)の改良版であり、その次に控える「Nehalem(ネヘーレン)」のような、大拡張ではない。Core MAの弱点は、依然としてPenrynでも改善されないまま残る。バランスの悪い拡張に見える。しかし、その一方、モバイルでの低消費電力化と高クロック化では、効率的な改良が加えられている。
では、何がPenrynで加わり、何が欠けているのだろう。IDFで明らかになったPenrynの実態をレポートしたい。
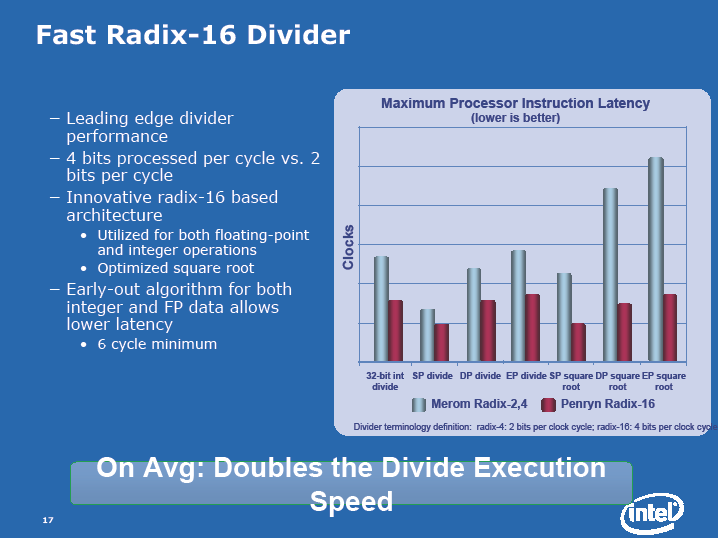
すでに報じられている通り、IntelはPenrynでいくつかのマイクロアーキテクチャレベルの拡張を実装した。特に、浮動小数点/SSE演算パイプでは2つの大きな拡張を行なった。1つは、SSEの128-bit SIMD(Single Instruction, Multiple Data)データの入れ替えやシフト、パック化といったオペレーションを高速化する「Super Shuffle Engine」。もう1つは整数、単精度/倍精度浮動小数点演算などでの除算オペレーションを高速化する「Radix-16 divider」だ。
概要はすでに報じられているので省くが、Penrynでは簡単に言えばSSE系浮動小数点演算に焦点を当てたパフォーマンス向上が図られている。整数演算性能を高めるよりも、浮動小数点演算性能を高める方向へトランジスタを割いた拡張だ。
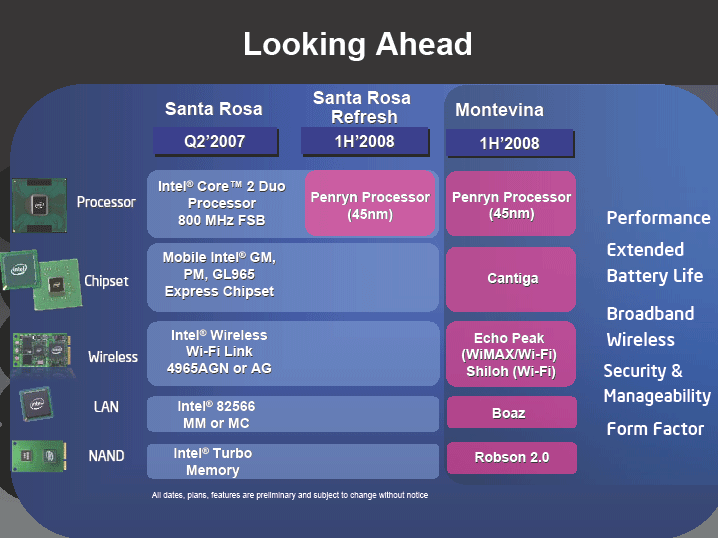 |
| 今後のリリース予定(※別ウィンドウで開きます) PDF版はこちら |
 |
| Super Shuffle Engine(※別ウィンドウで開きます) PDF版はこちら |
 |
| Fast Radix-16 Divider(※別ウィンドウで開きます) PDF版はこちら |
 |
| High-kを利用した次世代の45nmプロセス(※別ウィンドウで開きます) PDF版はこちら |
●SSE4のために実装したSuper Shuffle Engine
Penrynの浮動小数点/SSEパイプに加えられた2種類の拡張は、その目的が多少異なっている。「Super Shuffle Engine」は、SSE4命令のためという色彩が強い。
 |
| IntelのStephen L. Smith(スティーブ・スミス)氏 |
「Super Shuffle Engineは、レガシーSSE命令を含めてSSEタイプの命令の実行を助ける。基本的に、SSE4で得られるパフォーマンスは、Super Shuffle Engineなしには達成できないだろう。Super Shuffle Engineは、SSE4命令のパフォーマンスに直接貢献している。だから、我々はSuper Shuffle EngineとSSE4命令の2つを同時に実装した。
一方、Radix-16とSSE4命令については、もっと独立したものだと考えている。ソフトウェア側からの要請があって実装したが、SSE4命令との関係は、(Super Shuffle Engine)より独立したものだ」とIntelのStephen L. Smith(スティーブ・スミス)氏(Vice President Director, Digital Enterprise Group Operations, Intel)は説明する。
つまり、Super Shuffle Engineは、SSE4命令のPenrynに実装する必然性がある。それに対して、Radix-16は、なぜPenrynで実装するのか、その意図がいま1つ不鮮明だ。なぜMeromやNehalemといった、大きなマイクロアーキテクチャチェンジのタイミングではなく、中間世代のPenrynにRadix-16を実装したのだろう。
 |
| IntelのShmuel (Mooly) Eden(ムーリー・エデン)氏 |
IntelのShmuel (Mooly) Eden(ムーリー・エデン)氏(Vice President, General Manager, Mobile Platforms Group, Intel)は次のように説明する。
「まず最初に来るのは、トランジスタバジェットだ。45nmプロセスになり2倍のトランジスタバジェットになると、突然、『よし、必要なところにトランジスタはどんどん使おう』となる(笑)。
もう1つの理由は、設計上のものだ。ボトルネックを見つけてそれを手直しし始めたが、その部分の設計が間に合わないことがわかったとする。すると、(CPU全体の)設計を遅らせるか、それとも、その部分の実装は次の(CPU)設計に回すかという選択となる。こうした時、我々は常に妥協をしており、実装に間に合ったものを載せている。
Radix-16のケースについて、実際にどうだったかはわからない。しかし、明確なのは45nmプロセスではトランジスタバジェットが得られることだ。そして、一般論で言えば、(CPU)設計では常に妥協がつきまとう」
除算器はCPUの演算ユニットの中でもトランジスタ数を食うユニットだ。そのため、トランジスタに余裕ができる45nmまで実装が難しかったとしても不思議ではない。
 |
| Intel SSE4 Instructions(1)(※別ウィンドウで開きます) PDF版はこちら |
 |
| Intel SSE4 Instructions(2)(※別ウィンドウで開きます) PDF版はこちら |
●パイプラインの前半には手をつけなかったIntel
こうしたPenrynのマイクロアーキテクチャ上の改良箇所を見ると、いずれもパイプラインの後半であることがわかる。ところが、Core MAのアーキテクチャの場合、真の問題はじつはパイプラインのフロントエンドにある。命令フェッチ/命令プリデコード/命令デコードが、Core MAの大きなボトルネックになっている。
Core MAでは、32KBのL1命令キャッシュから命令フェッチユニット(Instruction Fetch Unit)が16 bytes単位のアライメントで命令をフェッチする。これは、32 bytesに命令フェッチを拡張しているAMDやCentaur Technologyの次のCPUと比べると狭い。AMDとCentaurは32 bytesのフェッチでなければ、実行パイプラインに十分な命令供給ができないケースがあると指摘している。
また、Core MAでは、プリデコーダがフェッチした命令群に対して、命令区分をマーキングする。プリデコーダは最大6個のx86命令を1サイクルでマークできるが、命令長やアドレス長を変化させる命令プリフィックスを使うと、途端に効率が悪化してしまう。
さらに、現在のMeromの実装では、64-bit OSの動作モードである「EM64T Long Mode」の時に、2個のx86命令を1個のCPU内部命令(uOPs)に統合する「Macro-Fusion」が効かない。Core MAのパフォーマンスを押し上げているキーテクノロジの1つだが、それが64-bitでは働いていない。
Meromのマイクロアーキテクチャには、フロントエンド部分にこうした大きな“穴”があるため、Penrynでそれをどこまで改善するのかが注目された。ところが、今回、Intelはパイプラインの前半のこれらの部分にはほぼ手をつけなかった。命令フェッチとプリデコード、デコードについては改善されたという情報はない。また、64-bit時のMacro-Fusionについても、「アーキテクトに確認する必要があるが、そのエリアでは顕著な変更は行なっていないと思う」とIntelのSmith氏は語る。
●Core MAの最大の弱点の改良は後回しに
こうして概観すると、Penrynでは、Core MAの一番のボトルネックはそのまま放置して、実行パイプライン側を集中して改良したように見える。Eden氏はその理由を次のように説明する。
「PenrynはマイクロアーキテクチャレベルではMeromによく似ている。Radix-16のような限定された調整を行なっただけだ。Meromより改良はされているが、それは限られたものだ。
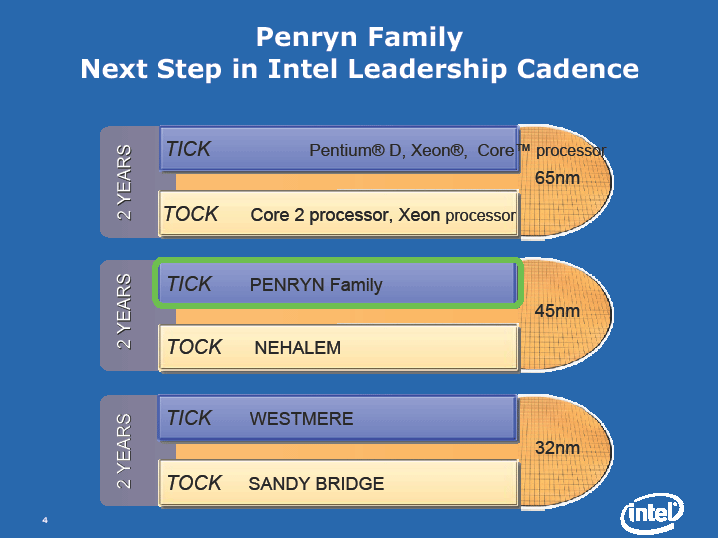
なぜなら、もし新アーキテクチャに切り替えた場合、加えて45nmプロセスに移行するのは、危険過ぎるからだ。新しいプロセステクノロジに、多くのリスク要素を加えることは望ましくない。Penrynでの改良は素晴らしいが、それは、あくまでも限定された“美容整形手術”のようなものだ。全てを再アーキテクチャする、“心臓手術”のような大きなものではない。大きな変更はNehalemで行なわれる。
これはチクタックモデルだ。新マイクロアーキテクチャを導入したら、次にそれを新プロセステクノロジに縮小して載せる。Penrynは、基本的にはMeromの縮小版により大きなキャッシュを載せたものだ。決してPenrynを軽く扱うわけではないが、Penrynに全く(Meromと)アーキテクチャの異なるブロックがあるわけではない」
つまり、Core MAのフロントエンドに手をつけようとすると、それは心臓手術並の再アーキテクチャになってしまうということだ。それだけ、フロントエンドの件は、アーキテクチャに深く依存している。それに対して、実行パイプラインに対する改良は、美容整形手術程度の軽いもので済む。それは、改良を加えても、パイプラインの構造に大きな変化を与えないからだと推測される。
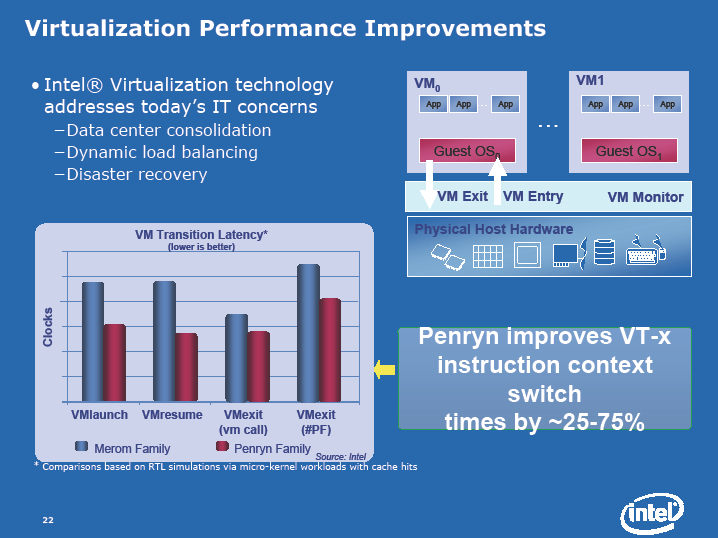
Penrynでは、このほか、キャッシュの利用効率を高めるためキャッシュラインを分割して使うことができる「Split Load Cache」や、Intel Virtualization Technologyの効率化も実装されている。これらも、マイクロアーキテクチャに大きな影響を与えない拡張だ。
Penrynでは、Santa Rosaプラットフォームの新フィーチャとして紹介された「Enhanced Dynamic Acceleration Technology」も若干最適化される。Enhanced Dynamic Accelerationでは、重いシングルスレッドアプリケーションの実行時に、片方のCPUコアがアイドル状態でC3ステイトに入った場合、アクティブCPUコアの周波数をブーストする機能だ。同じTDP(Thermal Design Power:熱設計消費電力)の枠内で、シングルスレッド性能を動的に引き上げる。Penrynでは、中間のPステイトでのオペレーションポイントを変化させずに、ブースト時の周波数を引き上げることができるように、バスとCPUコアの周波数の比率を修正した。この改良も、マイクロアーキテクチャに影響しない。
こうして見ると、IntelはPenrynにおいて、クリティカルな改良は巧妙に避け、影響の小さな部分だけに絞って効率的に改良を加えていることがよくわかる。大きな小改良、それがPenrynだ。
 |
| Penrynファミリーと今後の展開(※別ウィンドウで開きます) PDF版はこちら |
 |
| Virtualization Performance Impruvements(※別ウィンドウで開きます) PDF版はこちら |
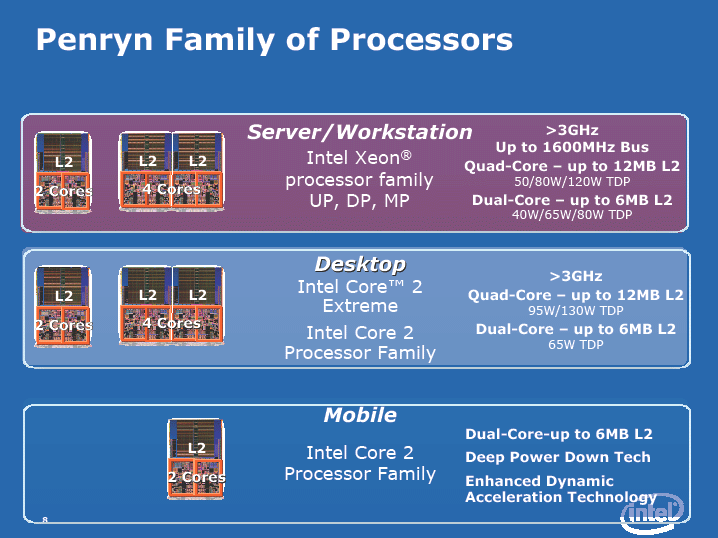 |
| Penrynファミリーのプロセッサ群(※別ウィンドウで開きます) PDF版はこちら |
□関連記事
【4月19日】【IDF】Penrynベンチマークセッションレポート
http://pc.watch.impress.co.jp/docs/2007/0419/idf06.htm
【4月19日】【IDF】マーク・ボーア氏基調講演
http://pc.watch.impress.co.jp/docs/2007/0419/idf07.htm
【4月18日】【元麻布】着々と進む45nmプロセスとクアッドコアへの道
http://pc.watch.impress.co.jp/docs/2007/0418/hot478.htm
(2007年4月20日)
[Reported by 後藤 弘茂(Hiroshige Goto)]
【PC Watchホームページ】
PC Watch編集部 pc-watch-info@impress.co.jp ご質問に対して、個別にご回答はいたしません
Copyright (c) 2007 Impress Watch Corporation, an Impress Group company. All rights reserved.