 |


■後藤弘茂のWeekly海外ニュース■NVIDIAがDirectX 10世代GPUの第2弾
|
●32プロセッサを搭載するGeForce 8600(G84)
NVIDIAがG8xアーキテクチャのGPUファミリを発表した。ミッドレンジ向けの「GeForce 8600 GTS/GT(G84)」と、メインストリーム&バリュー向けの「GeForce 8500 GT(G86)」だ。いずれも、マイクロアーキテクチャ的にはハイエンドのGeForce 8800(G80)の流れにあるが、GPU規模を縮小したバージョンだ。
G80は128個のスカラプロセッサ「Streaming Processor」をシェーダの演算ユニットとして搭載するのに対して、G84は32個、G86は16個のStreaming Processorを搭載する。前々回の記事「スケーラブルに展開するNVIDIAのG80アーキテクチャ」で説明したように、G8xアーキテクチャでは、16個のStreaming Processorで1個のシェーダクラスタ「Texture Processor Cluster」を構成する。G84では2個のTexture Processor Cluster、G86では1個のTexture Processor Clusterを備える。クラスタが1個のG86がG8xアーキテクチャの最小構成となる。
従来のプログラマブルシェーダアーキテクチャの場合、1個のシェーダプロセッサの中核は、通常、4way SIMD(Single Instruction, Multiple Data)型のプロセッサだった。G8x系アーキテクチャは、それを4個のスカラプロセッサに分解したイメージだ。そのため、G84とG86を旧来のShaderに換算すると、G84が8シェーダ、G86が4シェーダということになる。実際には、DirectX 10世代になるとシェーダプロセッサがよりスカラ命令中心となるため、単純には比較できないが、プロセッサの構成的にはG84が8シェーダ相当、G86が4シェーダ相当となる。
面白いのはこの点だ。ミッドレンジGPUとメインストリーム&バリューGPUは、これまで2~3年サイクルで内部の演算パイプの規模を増してきた。GeForce 7600 GT(G73)でバーテックスシェーダプロセッサが5個、ピクセルシェーダプロセッサが12個の構成だった。ところが、新しいG84はユニファイドシェーダで、旧来のシェーダプロセッサに換算すると8個相当の構成。バーテックスシェーダプロセッサは小型なので数から外すとしても、シェーダプロセッサの演算リソース自体は12から8へと減ってしまっている。ところが、GPUのトランジスタ数自体はG73の178M(1億7,800万)から、G84は289M(2億8,900万)と約1.6倍に増えている。
レジスタやキャッシュなどでも大幅にトランジスタが消費されていると見られるが、演算リソース当たりのトランジスタ数が大幅に増加している。これが、GPUのアーキテクチャ進化のコストだ。「スケーラブルに展開するNVIDIAのG80アーキテクチャ」で説明したように、G8x世代では、DirectX 10対応というだけでなく、フレキシビリティを高める様々な技術が投入されており、それがGPUコアを肥大させていることがわかる。
実際にはG84ではシェーダプロセッサコアはコアクロック675MHzの2倍以上の1,450MHzで動作させているため、演算リソースは減っても、生の演算パフォーマンスでは旧世代を上回る。シェーダの倍速動作は、シェーダの演算コアの分離化が進んだことで実現しやすくなった。アーキテクチャの進歩でパフォーマンスを上げているわけだが、そのアーキテクチャのためにトランジスタ数に対する演算リソース自体は減っている。
 |
| G84構成図 PDF版はこちら(別ウィンドウで開きます) |
●ハイエンドGPUとミッドレンジGPUのギャップが開いたG8x世代
G8x世代GPUファミリで最も顕著なことは、ハイエンドGPUのG80と、ミッドレンジGPUのG84/メインストリーム&バリューGPUのG86の間のギャップが開いていることだ。
G80が128プロセッサに対してG84は32プロセッサ、G86は16プロセッサ。シェーダプロセッサ数では、G80がG84の4倍、演算パフォーマンスでは3.7倍と差がついている。以前のように、ミッドレンジがハイエンドの1/2の構成&パフォーマンスという設定ではない。
GPUの規模も同様だ。トランジスタ数はG80が681M(6億8,100万)に対して、G84が289MでG86が210M(2億1,000万)。ダイサイズはG80が484平方mmに対して、G84が170平方mmを切る程度、G86が120平方mm程度と言われている。ダイサイズはまだ正確ではないが、トランジスタ数から見て大きくは違わないだろう。
いずれにせよ、今回、ハイエンドGPUとミッドレンジ以下のGPUでは、かつてないほどの差が開いている。一体、GPUに何が起こっているのだろう。
これが意味するのは、パフォーマンスの見せ玉(ハイエンドGPU)と、実際に稼ぐ玉(ミッドレンジGPUとメインストリーム&バリューGPU)の分離が進んでいることだ。
ミッドレンジGPUとメインストリーム&バリューGPUは一定コストで性能を伸ばすという半導体製品の性格に、ある程度沿って進化している。それに対してハイエンドGPUは、コストの激増という犠牲を払いながら、ムーアの法則を超えたパフォーマンスアップを続けている。GPUは二極化がますます明瞭になり、ハイエンドGPUはさらに特殊な位置づけの製品になりつつある。
この変化はGPUアーキテクチャの進化とも無関係ではない。GPUはDirectX 9以降、どんどん汎用性を高めている。しかし、GPUの柔軟性を高めることのトレードオフとして、伝統的なグラフィックス処理でのGPUの効率を悪化させている。つまり、トランジスタ数当たりの生パフォーマンスは低下している。それをカバーするためには、パフォーマンスフォーカスのハイエンドGPUは、チップ規模をより大きくするしかない。こうした背景から、GPUは過去5~6年間、二極化を続けてきた。
●一定の法則で進んできたGPUのファミリ構成とダイサイズ
もともと、GPUのダイサイズ(半導体本体の面積)とトランジスタ数には一定の法則があった。2002年頃までは、メインストリーム&バリューGPUに対して、ハイエンドGPUはトランジスタ規模が2倍。ダイサイズはメインストリーム&バリューGPUが80~90平方mm、ハイエンドGPUが120~150平方mmと、1.5~2倍弱だった。
この法則の根拠は非常に簡単だ。GPUメーカーは、プロセス世代毎に、新アーキテクチャのGPUを開発していた。プロセスが1世代微細化すると、同程度のダイサイズのチップに2倍のトランジスタを搭載できる。そのため、新アーキテクチャのハイエンドGPUは、旧世代の2倍のトランジスタ規模となる。
それと同時にGPUメーカーは旧世代GPUの製造プロセスもシュリンクする。すると、旧世代GPUは原理的には半分のダイサイズ(実際には半分まで行かない)の、小型のチップになる。GPUメーカーは、シュリンクした旧世代GPUを、廉価なメインストリーム&バリューGPUとして販売していた。メーカーによる違いがあるものの、こうした過程によって、ハイエンドGPUとメインストリーム&バリューGPUの間の関係が決まっていた。
ところが、DirectX 9 Shader Model 2.0世代になって状況が一変した。従来のハイエンドGPUよりさらにダイが大きな、200~220平方mmのダイのハイエンドGPUが登場したためだ。DirectX 9世代からは、大手GPUメーカーのGPUは、3ラインに分かれることになった。200平方mmクラスのハイエンドGPU、150平方mm前後のダイのミッドレンジGPU(従来のハイエンド)、90~110平方mmのダイのメインストリーム&バリューGPUだ。
その後ハイエンドGPUのダイサイズは、DirectX 9 Shader Model 3.0世代で300平方mmクラスへ、そしてDirectX 10 Shader 4.0世代ではついに450平方mm前後にまで到達した。ところがミッドレンジGPUとメインストリーム&バリューGPUは、大きくなりつつあるが、ある程度のラインを維持している。つまり、ハイエンドGPUと、下位のGPUでは、完全にダイサイズ増加のベクトルが異なっている。そのため、ハイエンドGPUとの乖離がどんどん顕著になってきた。
ダイサイズの比率としては、大まかには、DirectX 9 SM 2.0の頃はハイエンドGPUがミッドレンジGPUの1.4倍程度、メインストリーム&バリューGPUの2倍程度だった。DirectX 9 SM 3.0のダイでは、ハイエンドGPUはミッドレンジGPUの2倍、メインストリーム&バリューGPUの3倍となった。DirectX 10では、ハイエンドGPUはミッドレンジGPUの3倍、メインストリーム&バリューGPUの4倍となりつつある。ミッドレンジGPUとメインストリーム&バリューGPUはある程度のカーブを保っているのに、ハイエンドGPUだけが暴走している。
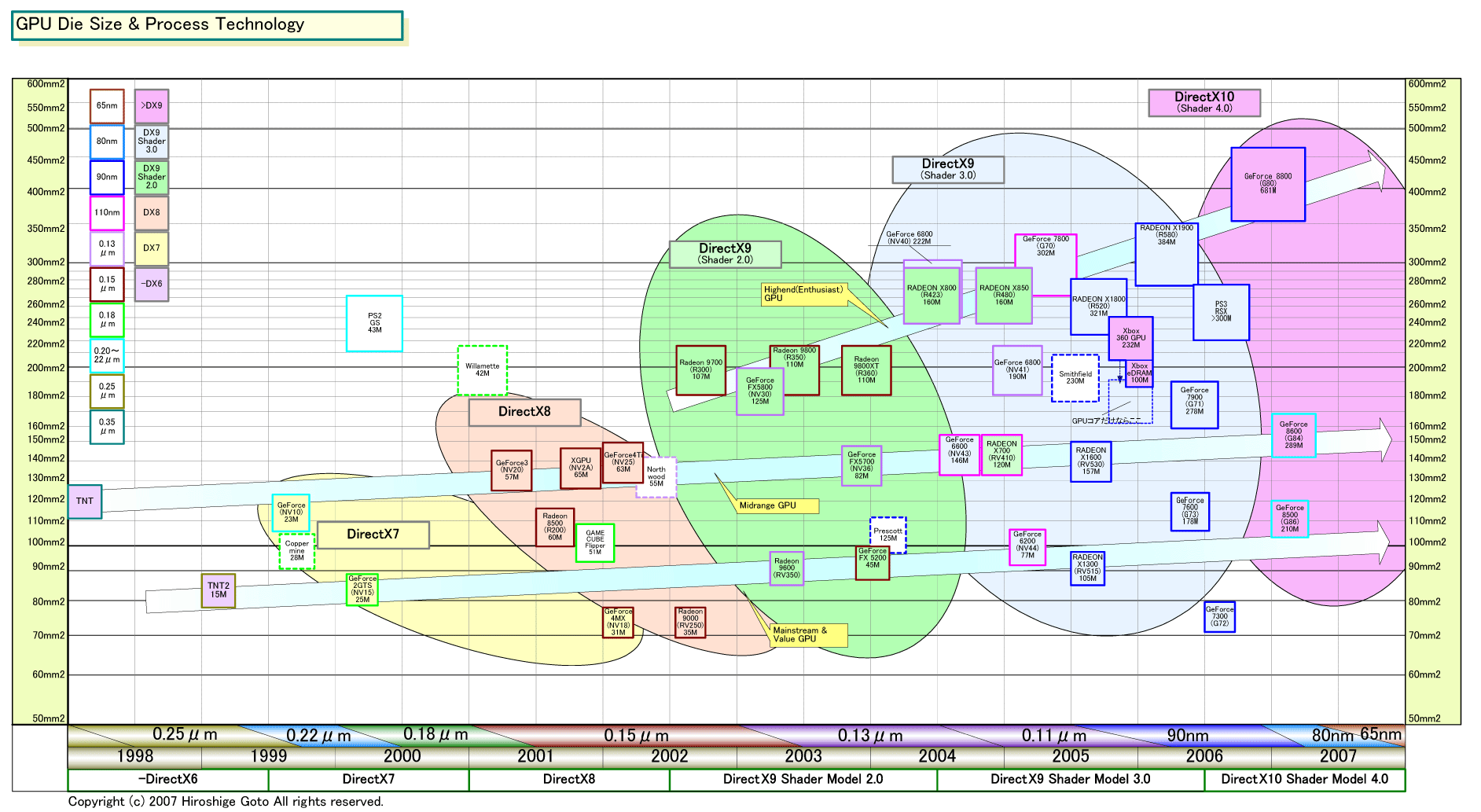 |
| GPUのダイサイズの変遷 PDF版はこちら(別ウィンドウで開きます) |
●GPUのビジネスモデルから生まれるダイサイズの差
もっとも、これはGPUのビジネスモデルにフィットしている。
GPUベンダーにとってハイエンドGPUは、先進アーキテクチャを見せ、パフォーマンスを誇るショウケースだ。それによって、そのメーカーのGPUのイメージを高め、ソフトウェア開発者を引きつける。それによって、消費者のブランド認知度を高め、ソフトウェア側の対応を促し、結果としてミッドレンジGPUとメインストリーム&バリューGPUのビジネスを軌道に乗せる。
そのため、ハイエンドGPUは高コストで利幅が薄くなってもGPUメーカーとしては構わない。ミッドレンジGPUとメインストリーム&バリューGPUが稼いでくれるからだ。だから、ミッドレンジGPUとメインストリーム&バリューGPUは、ハイエンドGPUのように無制限にダイサイズを増やすことができない。一定のダイサイズに納めるという制約を課されている。
こうしたビジネス上の理由から、ダイサイズは次第に離れつつある。現在、ミッドレンジGPUのダイサイズは、メインストリームCPUのダイサイズとほぼ同程度。メインストリーム&バリューGPUのダイサイズは、バリューCPUやグラフィックス統合チップセットとほぼ同程度。それに対して、ハイエンドGPUのダイサイズは大容量キャッシュを載せたサーバーCPUと同レベルにまで達している。ハイエンドGPUを搭載したPCなら、システムの中で最も巨大なチップはGPUだ。
●プロセス技術とアーキテクチャのバランス
もっとも、意外なことにトランジスタ数を見ると、各セグメントのGPUの規模はそれほど大きく乖離していない。トランジスタ数の増加は今回のDirectX 10世代までは、ハイエンドGPUもほぼ一定のペースを保ってきた。トランジスタ数の増加が一定のペースなのに、ダイサイズがそれを上回るペースで肥大化するのは奇異に見えるかもしれない。しかし、これには明確な理由がある。
ハイエンドGPUの規模が比較的小さかった頃は、GPUベンダーはハイエンドGPUを先端プロセス技術で製造していた。先端プロセスを使えば、チップを小型化できる。プロセスは立ち上げ期には不良率が高く、歩留まりが悪いが、ダイサイズが一定レベルなら、ある程度のレベルの歩留まりは維持できる。
ところが、DirectX 9以降は、ハイエンドGPUの規模が拡大し、先端プロセスを使ってもダイサイズが大きくなってしまったことで状況が変わった。プロセスの不良率が高いと、ダイが大きな場合には、歩留まりが激減してしまう。それなら、よりダイが大きくなっても、成熟したプロセスで製造した方が歩留まりは上がる。
こうした事情から、GPUベンダーはハイエンドGPUに先端プロセス技術を使わなくなりつつある。先端プロセスを使うのは、ハイエンドGPUより一歩遅れて登場し、ダイも小さなミッドレンジGPUとメインストリーム&バリューGPUからというのが最近の典型的なパターンだ。今回も、G80がTSMC 90nmプロセスに対して、G84/G86はどちらも80nmプロセスだ。
そのため、同じアーキテクチャ世代では、ハイエンドGPUが古いプロセスでトランジスタ数の割に巨大なダイ、ミッドレンジ以下のGPUが新しいプロセスでトランジスタ規模に対して小さなダイと、ダイサイズの差がより開く傾向にある。
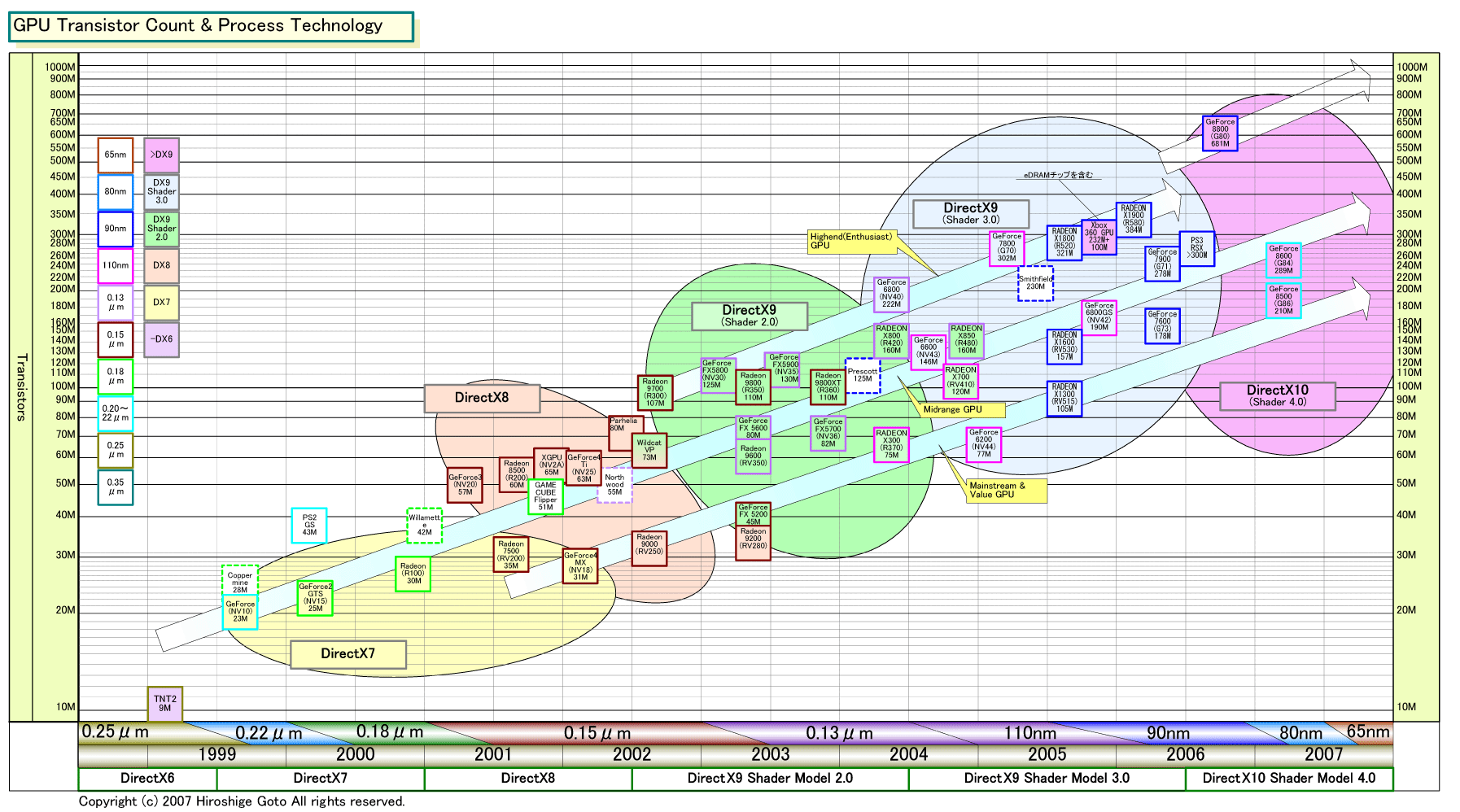 |
| GPU製造プロセスの変遷 PDF版はこちら(別ウィンドウで開きます) |
●64プロセッサ構成のG8xを作らなかった理由
こうして背景を見ると、G84がなぜ64プロセッサ構成や48プロセッサ構成ではなく、32プロセッサ構成なのか見えてくる。ミッドレンジGPUとして経済的に成り立つダイサイズに納めるには32プロセッサ構成にするしかなかったというのが現実だろう。
では、NVIDIAはハイエンドGPUとミッドレンジGPUの間に、さらに中間の規模のGPUを作らないのだろうか。その可能性は極めて低い、なぜなら市場性が薄いからだ。GPUメーカーが必要としているのは、パフォーマンスで王者となれるGPUと、実際の利益を生み出すことができるGPUだ。その中間にはそれほど必要がない。
また、現在のハイエンドGPUの場合、必然的に中間を埋めるGPU製品が派生してしまうという事情もある。ハイエンドGPUはダイ大きいため、ダイ上に不良が含まれる率が高い。一方、今のハイエンドGPUは、モジュール化されており、モジュール自体の数が多い。
例えば、G80クラスになると、シェーダクラスタTexture Processor Cluster(TPC)が8個ある。そのため、1個または2個のクラスタモジュール上に不良があっても、そのモジュールをディセーブル(無効)にして製品化できる。つまり、不良があってもチップを破棄しないで、派生品として販売できるというわけだ。その場合は、クラスタ数を減らした、下位モデルの派生品となる。ダイが大きくなり、モジュール数が増えれば増えるほど、こうした傾向は強まる。
次のクエスチョンは、ハイエンドGPUの肥大化は、まだ進むのか、それともここで打ち止めになるのかという点だ。NVIDIAのDavid B. Kirk(デビッド・B・カーク)氏(Chief Scientist)は、G80の発表時に、次の世代では1TeraFLOPSのパフォーマンスに達すると予告している。つまり、G80の2倍の演算パフォーマンスを目指している。そうなると、プロセスを微細化しても、GPU規模は大きくなる。
とはいえ、G80のダイは、製造上はほぼ限界に近い。いくら不良箇所のクラスタをディセーブルにして派生品を作れると言っても、500平方mm以上のチップは製造リスクが大きすぎる。GPUメーカーがどのレベルで肥大化を止めるのかはまだ見えない。しかし、限界へと近づいていることだけは確かだ。
□関連記事
【4月16日】【海外】スケーラブルに展開するNVIDIAのG80アーキテクチャ
http://pc.watch.impress.co.jp/docs/2007/0416/kaigai350.htm
【4月18日】【多和田】ついに登場したGeForce 8のミッドレンジ向け「GeForce 8600 GTS」
http://pc.watch.impress.co.jp/docs/2007/0418/tawada100.htm
(2007年4月18日)
[Reported by 後藤 弘茂(Hiroshige Goto)]
【PC Watchホームページ】
PC Watch編集部 pc-watch-info@impress.co.jp ご質問に対して、個別にご回答はいたしません
Copyright (c) 2007 Impress Watch Corporation, an Impress Group company. All rights reserved.