 |


■後藤弘茂のWeekly海外ニュース■Intelのマイクロアーキテクチャ改革「Nehalem」 |
●IntelがIDF前にNehalemの概要を公開
Intelが次世代マイクロアーキテクチャのCPU「Nehalem(ネハーレン)」の概要を明らかにした。
Nehalemはメモリインターフェイスを統合し、シリアル技術のインターコネクト「CSI」を複数実装する。CPUコア数は1から8コアまでのスケーラビリティを持つ。また、各CPUコアは、Hyper-Threadingと同種の技術で2スレッドを実行できる。そのため、8コアのNehalemでは16スレッドを実行できる。
 |
| Nehalemのフィーチャ (※別ウィンドウで開きます) PDF版はこちら |
CPUコアは、現在の「Core Microarchitecture(Core MA)」と同様に4命令をデコード&発行&リタイヤできるアーキテクチャとなっている。また、複数レベルの共有キャッシュを備える。クライアント向けには、GPUコアを統合したバージョンも提供する。Nehalemは45nmプロセスで製造し、最初の生産は2008年中となる。
 |
 |
| Nehalemは45nmプロセスで製造 (※別ウィンドウで開きます) PDF版はこちら |
2008年中に生産を開始 (※別ウィンドウで開きます) PDF版はこちら |
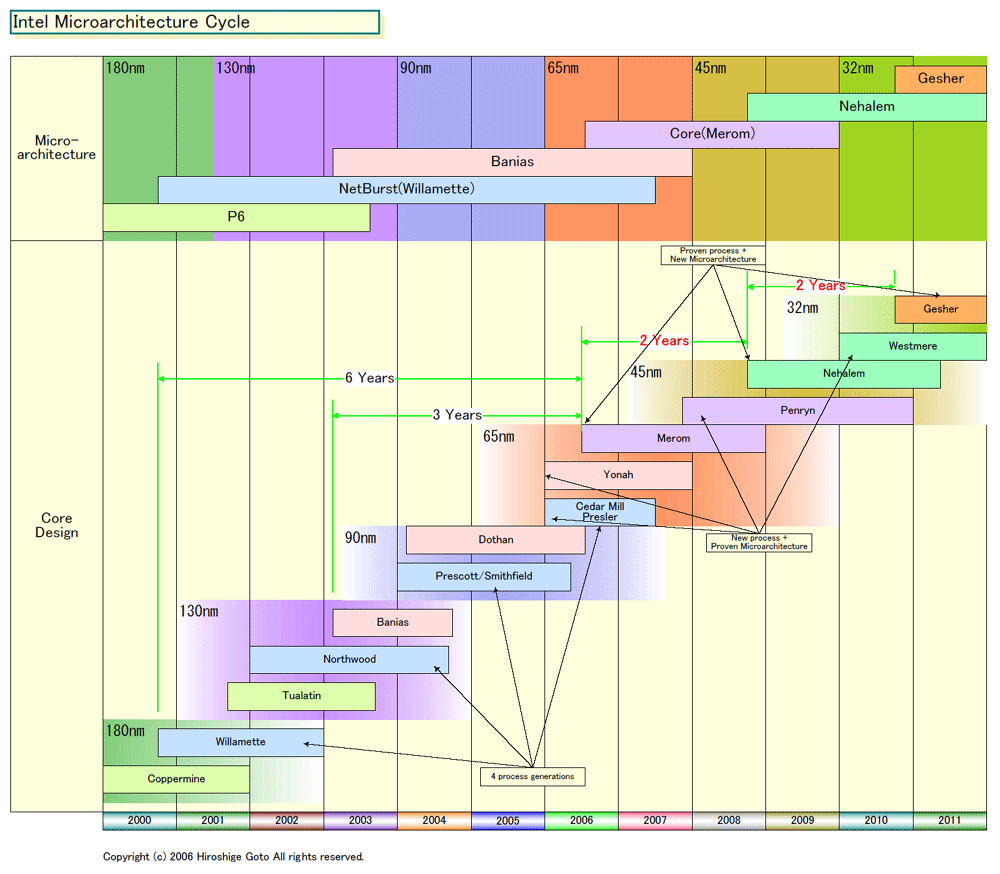 |
| Intel Microarchitecture Cycle (※別ウィンドウで開きます) PDF版はこちら |
●Nehalemではオクタコアが登場
Nehalemはシングルコアからオクタコア(Octa-core)までのスケーラビリティを持つという。1個のCPUに搭載されるCPUコア数は1~8コアまでのバリエーションがある。2のべき乗のシングルコア、デュアルコア、クアッドコア、オクタコアの製品構成になると推定される。
Nehalemのオクタコアについては、1個のCPUダイ(半導体本体)に統合したシングルダイなのか、2個のCPUダイをパッケージ上で接続したデュアルダイなのかは、まだ明確にされていない。
「(オクタコアの)実装のディテールはまだ明かすことができない。我が社は、今日の製品に見られるように、パッケージテクノロジで2個のシリコンダイを統合する能力も持っている。こうした能力は今後も使って行く」とIntelのStephen L. Smith氏(副社長兼デスクトップ・プラットフォーム・オペレーションズディレクター、Intel)は説明する。
 |
| Nehalemのオクタコアの推定図 (※別ウィンドウで開きます) PDF版はこちら |
IntelとAMDの65nmプロセスのクアッドコアは、ほぼ同サイズだ。AMDの「Barcelona(バルセロナ)」系が283平方mm、IntelのKentsfield(ケンツフィールド)系が286平方mm。だが、AMDはシングルダイにまとめているのに対して、Intelは143平方mmのダイ2個をパッケージ内で統合している。
複数ダイを1パッケージに収めるマルチチップモジュール(MCM)技術は、以前は歩留まり上の不利があったが、Intelは現在ではその問題は解消したとしている。MCM化での歩留まりの不利が少ないなら、2ダイの方が生産性は高くなる。しかし、1個のダイに統合した方が、パフォーマンス/消費電力では有利になる。
このトレードオフの考え方が、AMDとIntelでは異なる。Intelは現在、MCMでマルチコア化を先行させ、次のプロセスでシングルダイへと移行させるという戦略を取っている。そうすれば、CPU自体の設計も共有化できるため、設計のコストや期間も短縮できる。
それに対してAMDは、シングルダイに統合したネイティブマルチコア化のアドバンテージにこだわっている。そのため、CPU設計自体をモジュラー化し、マルチコアの派生設計を簡単に開発できるようにしつつある。Intel CPUはモジュラー設計となっていないため、派生設計には、AMDより時間がかかると推定される。
IntelとAMDのこの2分化がNehalem世代でも続くとすると、IntelのNehalemのオクタコアは、シングルダイではなくデュアルダイになる可能性が高い。これまでの流れを考えると、2ダイが自然な方向だ。Nehalemの新FSBであるCSIも、マルチダイ化では有効に作用する。
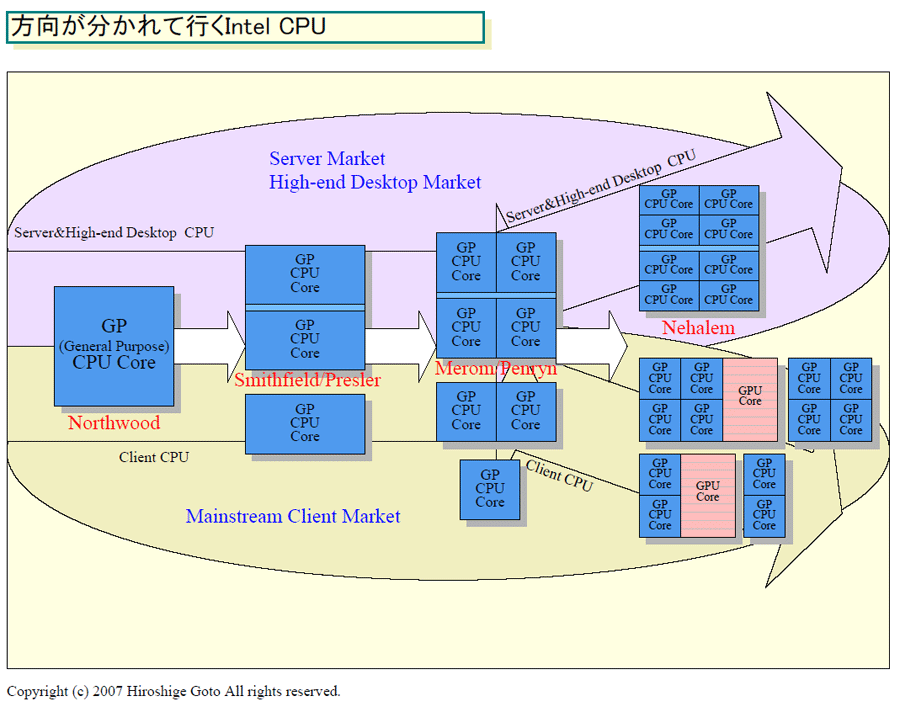 |
| 方向が分かれて行くIntel CPU (※別ウィンドウで開きます) PDF版はこちら |
●パッケージ内でCSIで接続することでデュアルダイが容易に
Nehalemは、シリアル技術のチップ間高速インターコネクトを実装する。従来のパラレル技術のFSB(Front Side Bus)から、一気にシリアル技術へとジャンプする。このシリアルインターコネクトCSIは、Intel CPUの共通のインターコネクトになって行くと言われている。
「Nehalemに実装するのは高速なシリアルインターコネクトだ。今日のシステムのものより広帯域になる。また、プロセッサ間を接続する場合にはコヒーレンシを取ることが可能だ。1から4リンクの間で。また、I/Oデバイスとの接続も行なう。依然として柔軟なI/Oリンクが必要だからだ」とSmith氏は説明する。
現在のIntelのマルチダイ型のマルチコアCPUの場合、共有バス型のFSBをパッケージ内で分岐させて2つのCPUダイを接続している。これが、FSBの高速化の障壁の1つとなっている。しかし、CSIになるとこの問題は解決する。
CSIベースのCPUの場合、CPUパッケージの中でCPUダイ同士をCSIの1リンクを使って接続することができる。逆を言えば、CSIはポイントツーポイント接続なので、そうしなければマルチダイ化ができない。
Nehalemは複数のCSIを備えるため、1リンクをCPU同士のコヒーレント接続に使用、他のリンクをI/O接続やCPU間接続に使う。マルチプロセッサ版の場合は、2個のダイのCSIリンクをそれぞれ外に出してマルチリンクを実現する。シングルプロセッサの場合は、複数のCSIリンクのうち1つをダイ間の接続に、別なリンクを1つI/Oチップ接続に出すことで対応できる。こうした構成が推定される。
Intelは、次々期のIA-64 CPUである「Tukwila(タックウイラ)」でも、同様にCSIによる2ダイ接続を行なうと言われている。
CSIでのダイ間接続は、MCM設計上でも利点がある。マルチダイの場合、冷却を考えると、できるだけ2つのダイを近くに配置してヒートシンクの中央に位置させる方がいい。現在のパラレルFSBの場合、配線面積が大きいため、こうした構成は難しい。しかし、CSIの場合は配線が容易になるため、2つのダイの配置が、より容易になると推定される。
●メモリコントローラをCPU側に内蔵
Nehalemではメモリコントローラを統合する。PC向けではDDR3メモリインターフェイスを、サーバー向けではFB-DIMMインターフェイスを統合すると見られる。
JEDEC(米国の電子工業会EIAの下部組織で、半導体の標準化団体)のDRAMロードマップでは、DDR3世代がやや長くなる可能性が予想されている。そのため、Nehalemアーキテクチャ(32nmのWestmereも含む)のクライアントPCではDDR3がスタンダードになると予想される。DDR3では、デュアルメモリチャンネルになると推定される。広インターフェイス幅のDDR3アーキテクチャでは、デュアルチャネルより広いインターフェイスを、低コストに実装することが難しいからだ。
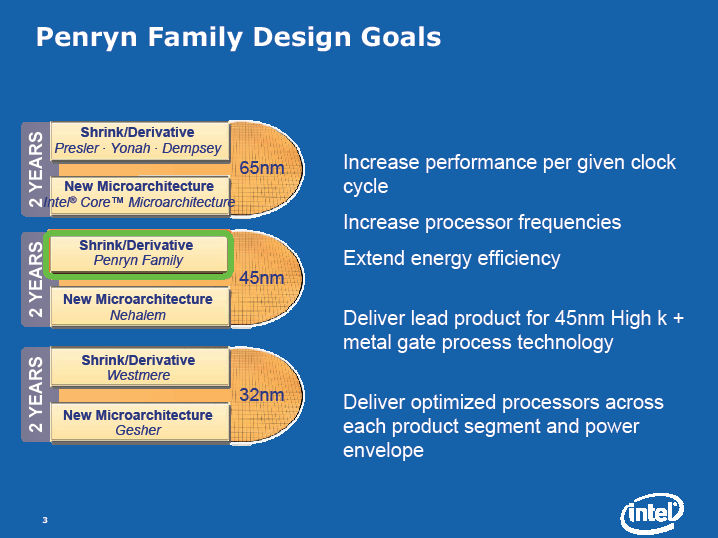 |
| 小型化していくプロセス (※別ウィンドウで開きます) PDF版はこちら |
DRAMは、データ転送レートが上がってもメモリレイテンシは改善されて行かない。そのため、CPU側の性能が上がるにつれてメモリレイテンシがCPUパフォーマンスの足を引っ張る原因となっている。DRAMインターフェイスの統合は、CPUにとって必然の流れだ。
一方、サーバーでは、システムのメモリ搭載量が必要とされる。そのため、デイジーチェーンでDIMMを接続できるFB-DIMMインターフェイスが有用となる。FB-DIMMではメモリレイテンシは犠牲になるが、その代わりメモリ搭載量とメモリ帯域の両方が確保できる。
もっとも、Nehalem世代ではメモリインターフェイスをCPU側に統合するため、トポロジが変わる。AMDのOpteronと同様、CPU個数を増やすと、それに連動してメモリチャネル数が増えることになる。そのため、FB-DIMMではなくても、システムのメモリ搭載量を増やしやすい。DDR2/DDR3インターフェイスという選択肢もあるが、今のところIntelはサーバーではFB-DIMM路線を堅持している。
もともと、CSI世代CPUでは、IntelはIA-32とIA-64の両サーバーCPUのソケットとチップセットを統合する予定だった。その時のプランでは、IA-32とIA-64の両CPUで、CSIとFB-DIMMのインターフェイスを共有化することで、プラットフォーム統合を可能にすることになっていた。現在もチップセットレベルでは互換のプランとなっているという。
マルチダイでオクタコアを実現する場合は、メモリインターフェイスを一部ディセーブルにすると推定される。PC向けのシングルコアの場合、DDR3ならマスター側CPUダイの方を使い、スレイブ側CPUダイのメモリインターフェイスはディセーブルにすると推定される。サーバー向けのFB-DIMMの場合は、パフォーマンスを最大にするなら、それぞれのダイから2チャネルづつ出して、4つのFB-DIMMチャネルを使うと考えられる。
●Hyper-Threadingが復活するNehalemコア
NehalemのCPUコアは、Core MAと同様に4命令発行。Intelは命令発行数を増やして、命令レベルの並列性(ILP:Instruction-Level Parallelism)を上げようとは試みなかった。これは、4命令発行以上にしても、命令スケジューリングが追いつかないため、実効ILPを引き上げることができないためと推定される。
しかし、Nehalemでは、各CPUコアにHyper-Threadingと同種の「SMT(Simultaneous Multithreading)」が実装される。「それぞれのコアが2スレッドを実行できる」(Smith氏)という。サイマルテニアスなので、2つのスレッドの命令を、同時にCPUの実行パイプラインに混在させて実行できる。
SMTはメモリレイテンシを隠蔽し、CPUコア内部の実行ユニットの空きを埋めることで、CPUコアをビジーに保つことを可能にする。SMTを持たない場合、キャッシュミスでメモリアクセスのストールが発生した場合は、CPUコアがかなりのサイクルに渡ってアイドルになってしまう。しかし、SMTによってアイドル状態を別スレッドで埋めることができる。もちろん、それだけアクティブスレッドがあればという前提となる。
SMTは、ヒルズボロで設計したNetBurstアーキテクチャで導入された技術。同じヒルズボロで設計するNehalemが採用するのは自然な流れだ。Core MAの一部が明かされた2005年秋のIDFで、IntelのPatrick(Pat) P. Gelsinger(パット・P・ゲルシンガー)氏(Senior Vice President and General Manager, Digital Enterprise Group)は、Core MAにHyper-Threadingが含まれない点について次のように語っていた。
「Hyper-Threadingが有効でないということではない。消費電力や効率などのトレードオフで(Core MAにHyper-Threadingを実装しないという)決定を下した。しかし、将来にはHyper-Threadingは依然として有用で、ある時点で戻ってくるだろう。
現在のアプリケーションは、まだスレッド化への移行の早い段階にある。それに対して、デュアルコアでデュアルプロセッサ構成では4コアで、4つ以上のアクティブスレッドがなければ、Hyper-Threadingを実装しても効果が薄い。しかし、4コアで8アクティブスレッドになれば、Hyper-Threadingは非常に効率的だ。そして、アプリケーションのスレッド数は、将来増えてゆくと予想している」
ヒルズボロは、Gelsinger氏のDigital Enterprise Groupに含まれている。そのため、こうしたスレッド化の予測の元にSMTを実装してきたと推定される。
各CPUコアが2スレッドを実行できるため、デュアルコアのNehalemは4スレッド、クアッドコアは8スレッド、オクタコアは16スレッドを同時実行できる。オクタコアの4wayシステムでは、64のアクティブスレッドを実行できることになる。
同時実行できるスレッド数が増えるため、Nehalem世代では4wayより2wayデュアルプロセッサシステムへの傾斜が、より強くなると推定される。マルチコア+SMTでスレッド並列性が上がっても、ソフトウェア側がついて来れない場合は意味が薄くなる。
また、Nehalemのパイプラインが、Core MAと同様に、比較的効率の高い構造となっていた場合は、実行ユニットのアイドル状態が少ないことになる。パイプラインの効率が悪いNetBurstアーキテクチャよりは、SMTのベネフィットは少ないと推定される。
●Application Targeted Accelerators(ATA)命令を備えるNehalem
Intelは、45nm世代のCore MAのCPU「Penryn(ペンリン)」でSSE4命令を追加する。NehalemではPenryn同様にSSE4命令を実装し、さらに「Application Targeted Accelerators(ATA)」命令も備える。
Gelsinger氏は前回のIDFで、45nm世代では、アプリケーションに特化した特殊なアクセラレータ命令ATAを加えることを明かしていた。Intelが最初に実装しようとしているのは「Cyclic Redundancy Check (CRC:巡回冗長検査)」のアクセラレーション。CRCは、データの完全性、つまり、データが破損しているかどうかをチェックする仕組み。対象とするデータから生成されるCRCバリューのチェックを行う命令「CRC32」を実装するという。
CRCは通信やストレージでよく使われており、Intelもネットワークストレージをターゲットとすると説明している。Intelによると、「iSCSI(Internet Small Computer System Interface)」や「RDMA(Remote Direct Memory Access)」といったストレージのデータトランスファプロトコルのアクセラレートが主目的だという。現在は、こうしたプロトコル処理をCPUオフロードする専用アクセラレータがある。Nehalemでは、そのアクセラレータを内蔵することになる。
前回発表された、2つ目のアクセラレータ命令は、大規模データセットのサーチ向け命令「POPCNT」。Population Count命令で、オペランド中のビットセットの数を数える。Intelは応用例としてゲノムマイニング、手書き認識、ハミングアルゴリズムなどを挙げている。Intelは、アクセラレータの統合を、この2つから始めるようだ。
●複数レベルの共有キャッシュを備えるNehalem
Nehalemコアのその他のフィーチャについては明らかになっていない。しかし、以前、IntelのJustin R. Rattner(ジャスティン・R・ラトナー)氏(Intel Senior Fellow, Director, Corporate Technology Group)は、「Macro-Fusionが今後のベースとなって行く」と語っており、Core MAで導入されたMacro-Fusionなどのテクニックはそのまま継続されると見られる。
Intelは、マルチコア上でのマルチスレッド実行を容易にするための「Transactional Memory」の研究も熱心に勧めている。Transactional Memoryは、ソフトウェアでも実装できるが、CPUのキャッシュハードウェア側にも対応する機能を備えた方が、ずっと効率がアップする。Transactional Memoryは、次のマルチコアの大きなマイクロアーキテクチャ上の改革だが、Nehalemに間に合うかどうかはわからない。
NehalemではCPU側にマルチレベルの共有キャッシュ(Multi-Level Shared Cache)を搭載するという。L1キャッシュは共有にしにくいため、L2とL3を共有キャッシュとして備えると予想される。AMDは次の「Barcelona(バルセロナ)」世代でもデスクトップとサーバーCPUでは、L2キャッシュをコア単位で持ち、L3を共有キャッシュとする。Intelのキャッシュ構成はこれとは異なるが、デスクトップでもL3キャッシュが入ってくる可能性がある。
コンピュータのメモリ階層は、メモリアクセスとCPU性能のギャップが広がるにつれて拡大している。一定のレイテンシでアクセスできるキャッシュ量には限界があるため、キャッシュを増量しようとすると、キャッシュ階層を深くすることになる。Nehalem世代のキャッシュが、全てSRAMなのか、別なメモリアーキテクチャを考えているのかは、まだ明らかになっていない。しかし、Intelの場合はこれまでの研究などを見るとSRAMである可能性が高い。
この他、IntelはNehalemにGPUコアを統合することも明かしている。しかし、AMDのCPUとGPU統合プロジェクト「FUSION(フュージョン)」とは、微妙にスタンスの違いが見える。次回は、その点を明らかにしたい。
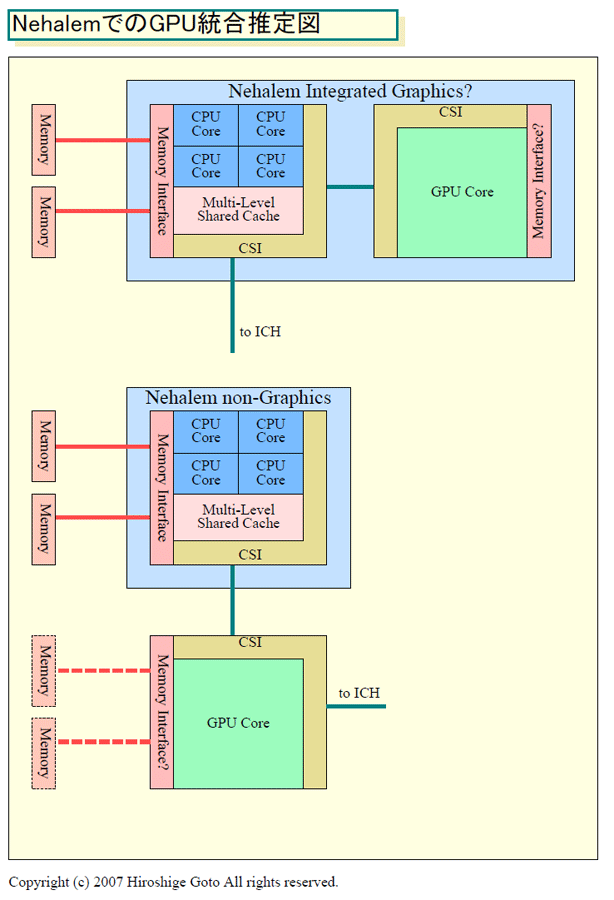 |
| NehalemでのGPU統合推定図 (※別ウィンドウで開きます) PDF版はこちら |
□関連記事
【2月21日】【海外】テラフロップスメニイコア時代のIntel CPUの姿
http://pc.watch.impress.co.jp/docs/2007/0221/kaigai339.htm
【2月6日】【海外】45nmプロセスの利点を活かすIntelの次世代CPU「Penryn」
http://pc.watch.impress.co.jp/docs/2007/0206/kaigai334.htm
(2007年3月30日)
[Reported by 後藤 弘茂(Hiroshige Goto)]
【PC Watchホームページ】
PC Watch編集部 pc-watch-info@impress.co.jp ご質問に対して、個別にご回答はいたしません
Copyright (c) 2007 Impress Watch Corporation, an Impress Group company. All rights reserved.