 |


■後藤弘茂のWeekly海外ニュース■テラフロップスメニイコア時代のIntel CPUの姿 |
●メニイコアに向けてのIntelの試行錯誤
コンピュータ向けのパフォーマンスCPUは、数十コア、数百コアのメニイコア(Many-core)時代に向かおうとしている。そして、メニイコア時代のCPUは、1個のCPUの中に、アーキテクチャが全く異なる複数のプロセッサコアが混在する「ヘテロジニアス(Heterogeneous:異種混合)型」マルチコアになる。これが、ここ数年で、急速にCPU業界の共通認識となった(ように見える)未来展望だ。現在主流の汎用(General Purpose)CPUコアをホモジニアス(Homogeneous:同質)で数個程度搭載するマルチコアとは、全く異なるCPUへと進化しようとしている。
しかし、まだ見えないのは、メニイコア時代のCPUに、具体的にどんなアーキテクチャが採用されるのかという点だ。これについては、まだ決定的な解が見いだされておらず、各社とも試行錯誤の最中。そして、Intelは試行錯誤の1ステップとして、先週米サンフランシスコで開催された半導体学会「ISSCC(IEEE International Solid-State Circuits Conference) 2007」で、実験チップ「Network-on-Chip(NoC)」を発表した。
NoCは、その技術が直接製品につながるものではなく、リサーチプロジェクトという位置づけだ。しかし、そのアーキテクチャはそれなりに練られており、Intelが考えているメニイコアのヒントが隠されている。
NoCは80個の小さな浮動小数点演算専用プロセッサコアを、メッシュネットワークで結んだタイルプロセッサ構成となっている。各タイルには、「プロセッシングエンジン(PE)」とクロスバールーターが含まれる。クロスバールーターは5wayのルーターで、上下左右の隣接するタイルのルーターと接続してメッシュネットワークを構成している。
NoCのマイクロアーキテクチャをもう少し詳しく見ると、各プロセッサをソフトウェアパイプライニングで連携させて処理を行なうことを意図していることがわかる。隣接するタイル同士を連携させることで、配線ディレイを最小に抑えながら複数パイプラインを並列させるものと推測される。
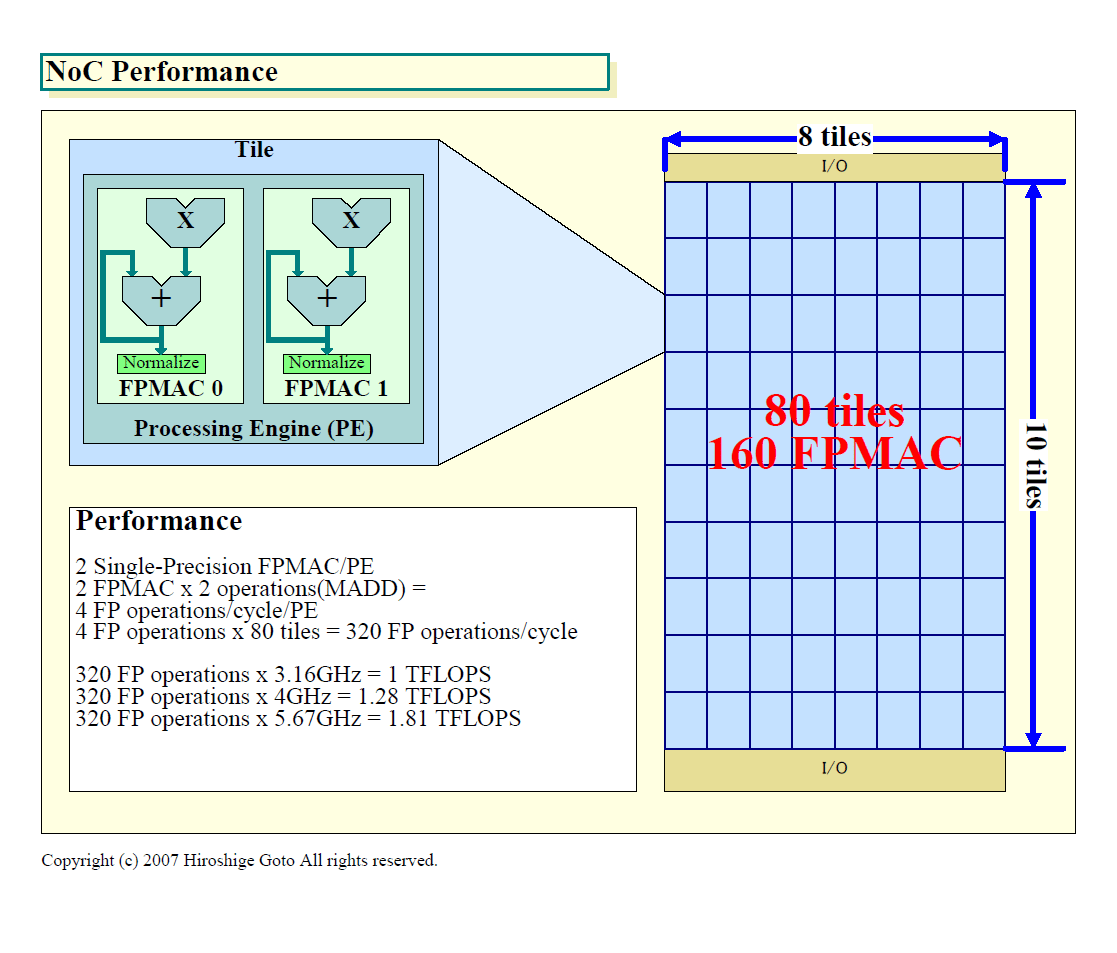 |
| NoCのパフォーマンス(※別ウィンドウで開きます) PDF版はこちら |
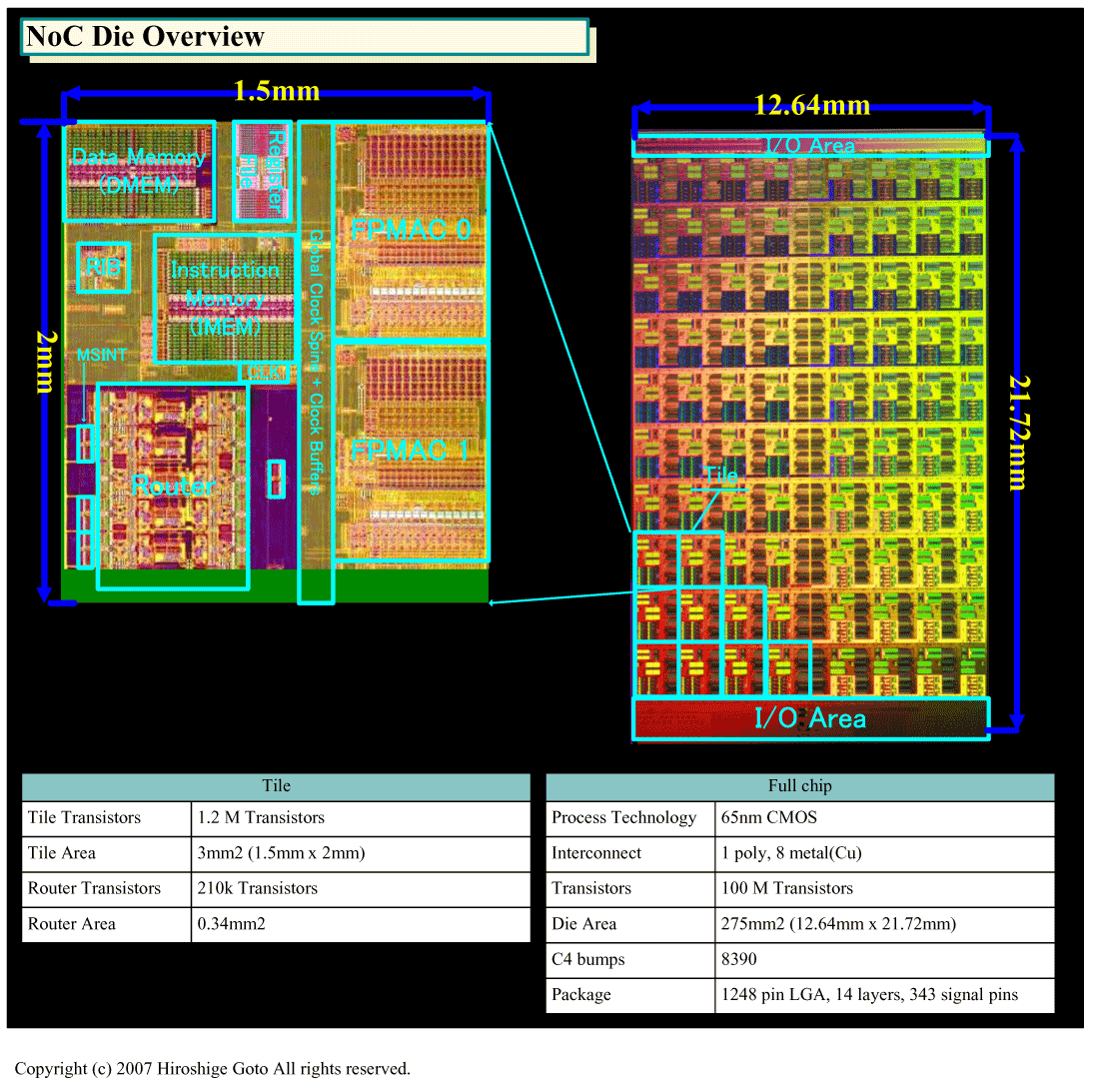 |
| NoCダイの概観(※別ウィンドウで開きます) PDF版はこちら |
●研究が相次ぐタイルプロセッサ
タイル型にプロセッサアレイを並べるアーキテクチャは、NoCに独特のものではない。タイルプロセッサの研究は、大学レベルで近年盛んに行なわれており、過去数年間にもいくつかの発表がされている。例えば、ISSCC 2003ではMIT(Massachusetts Institute of Technology)が「Raw microprocessor」の発表を行なっている。下がその時に示されたRaw microprocessorのタイルの図だ。
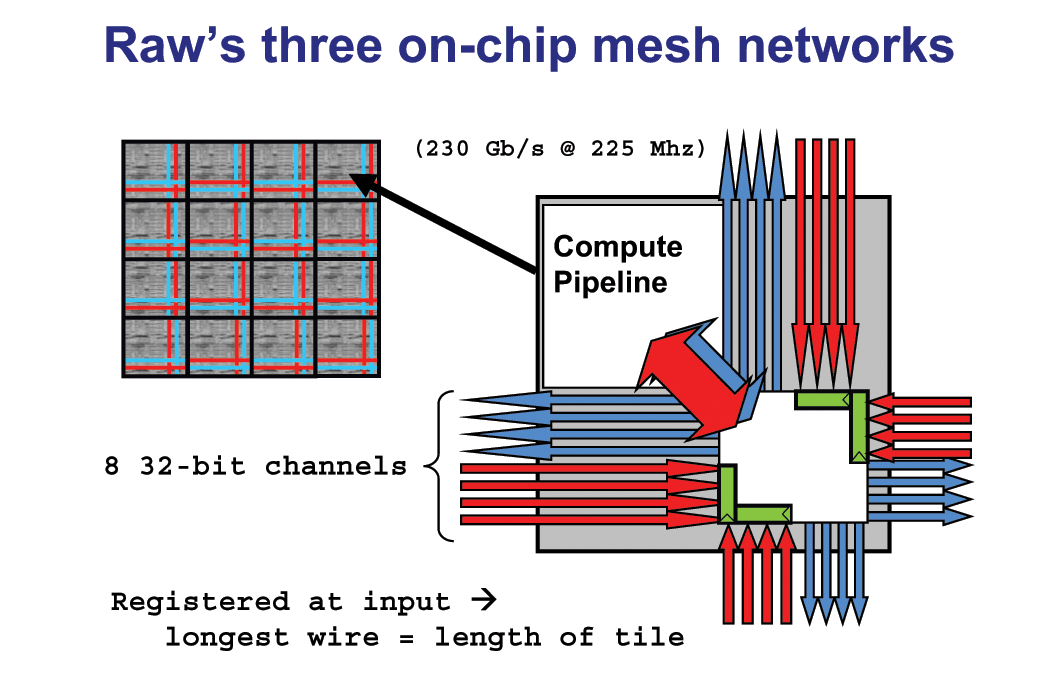 |
| Raw microprocessor概要(※別ウィンドウで開きます) PDF版はこちら (Michael Bedford Taylor, Jason Kim, Jason Miller, David Wentzlaff, Fae Ghodrat, Ben Greenwald, Henry Hoffman, Paul Johnson, Walter Lee, Arvind Saraf, Nathan Shnidman, Volker Strumpen, Saman Amarasinghe, Anant Agarwal, "9.7 A 16-Issue Multiple-Program-Counter Microprocessor with Point-to-Point Scalar Operand Network", ISSCC 2003, February 2003) |
タイルの中にオンチップルーターとプロセッサコアが配置されている点は、IntelのNoCと非常によく似ている。Rawでは4×4の16タイルでプロセッサを構成している。下の図のように、複数のタイルで処理をパイプライン化することを想定している。これも、NoCで想定されるタイルのパイプライン化に近い。
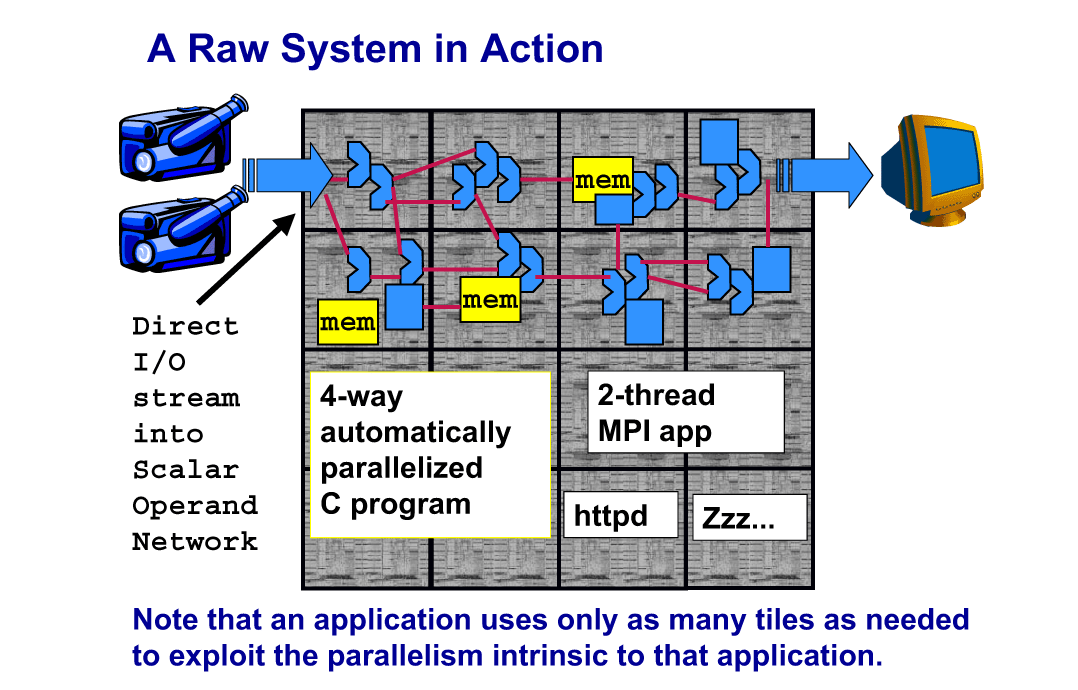 |
| 複数のタイルで処理をパイプライン化することを想定(※別ウィンドウで開きます) PDF版はこちら |
The University of Texas at Austinもタイルプロセッサ「TRIPS」の研究を行なっており、2005年のCPUカンファレンス「HotChips 17」などで発表している。こちらは、もっとアグレッシブで、レジスタやメモリも個別のタイルになっている。各タイルは、演算コアのアレイだ。ただし、演算アレイをタイル構造に並べてる点では同じだ。
 |
| レジスタやメモリも個別のタイルに(※別ウィンドウで開きます) PDF版はこちら (Robert McDonald, Doug Burger, Steve Keckler, Computer Architecture and Technology Laboratory Department of Computer Sciences, The University of Texas at Austin, "The Design and Implementation of the TRIPS Prototype Chip," HotChips 17, August 2005) |
NoCのアーキテクチャには、こうした先駆がある。またIntel自身も、タイル型に演算アレイを並べるクラスタードマイクロアーキテクチャに関する論文を出している。これは、演算バックエンドをクラスタ化しておいて、切り替えることでホットスポットなどを避けるというアプローチだ。
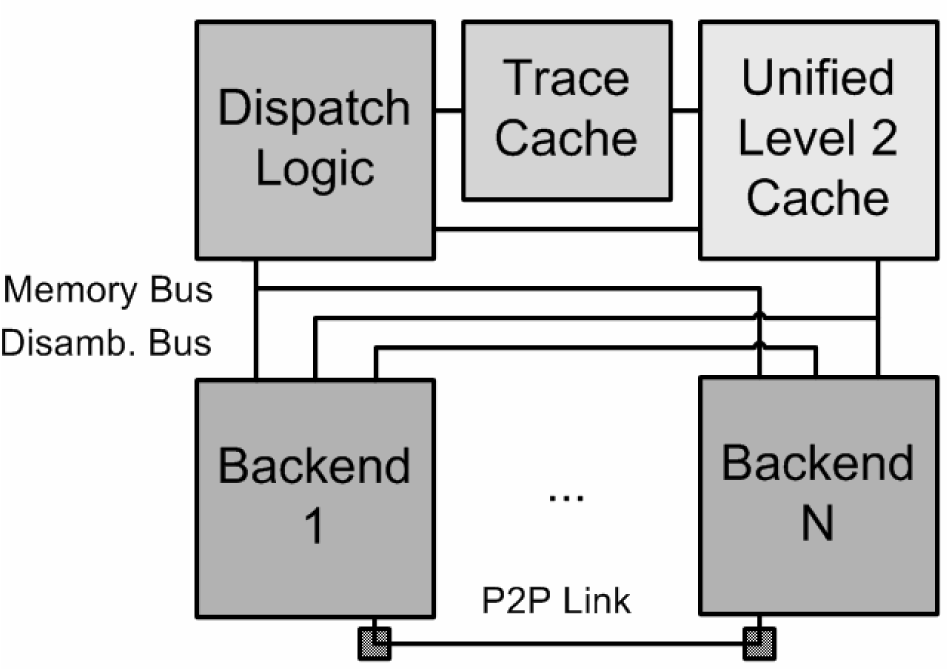 |
| 演算バックエンドをクラスタ化し、切り替えることでホットスポットなどを避ける(※別ウィンドウで開きます) PDF版はこちら (P. Chaparro, J. Gonzalez, and A. Gonzalez. "Thermal-effective clustered microarchitectures". In First Workshop on Temperature-Aware Computer Systems (TACS-1), 2004.) |
RAWやTRIPSといったタイルプロセッサのアプローチでは、アレイ型に並んだ演算コアに、命令フローを分散して割り当てる。従来、1個のプロセッサの中で複数の演算ユニットでアウトオブオーダ型に実行していた命令フローを、タイル単位に分かれた演算コア群で実行するようなイメージだ。各CPUコアがスレッド単位で並列化する、従来のコンピュータのマルチコアとは異なる。より小さな粒度で、タイルに割り当てる。その場合、タイル間でデータ依存が頻繁に発生するため、タイルプロセッサではレジスタバリューをオンチップネットワーク経由でフォワードする仕組みなどを備える。また、複数タイルを使ったプレディケーションで、分岐予測ミスのペナルティを抑えることも行なわれる。
しかし、NoCのアーキテクチャは、これら研究タイルプロセッサ群と比べると違いがある。今見えている範囲では、こうしたタイルプロセッサのようなアグレッシブなアプローチは取らないように見える。タイルは、もっと緩い連携を行なうと推定される。
●ネットワークとのデータ入出力
NoCの命令セットは96bit長の変則的なVLIW(Very Long Instruction Word)命令セット。IA-64などの場合、VLIWに含まれる個々のオペレーションの命令長は固定長だ。それに対して、NoCのVLIW命令では可変長命令を格納していると見られる。命令用メモリ領域が極めて限られているため、VLIWの弱点であるコードエクスパンションを抑えられるように、コンパクトで効率が高い命令セットに工夫したと推定される。
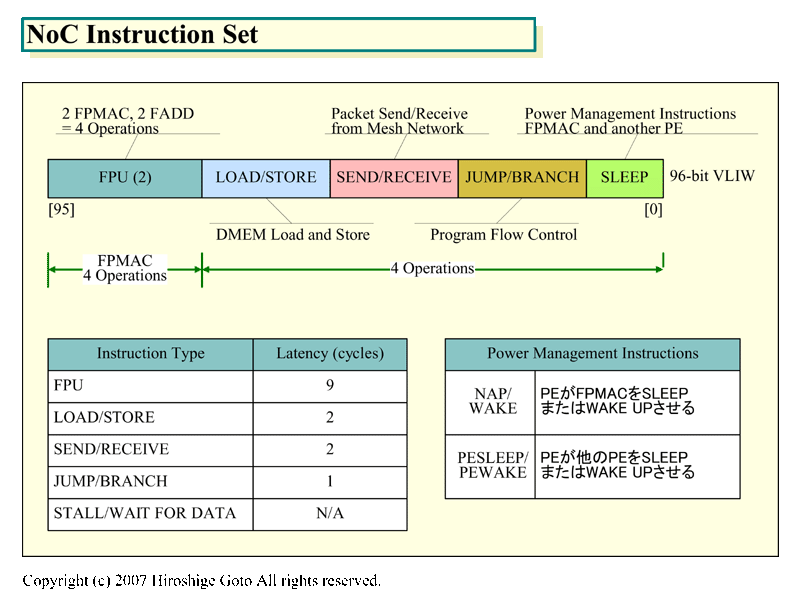 |
| NoC Instruction Set(※別ウィンドウで開きます) PDF版はこちら |
レジスタファイル数も32個と比較的少ないため、オペランドも各5 bitsと小さくてすむ。また、VLIWで命令スロットが決め打ちになっているので、オペコードも小さくできる。例えば、パワーマネージメント命令が4個しかない場合はNOPを含めても3bitsで表すことが可能だ。
PEのロード/ストア命令は2サイクルレイテンシで、PE内部のDMEMからレジスタへのロードとストアを行なう。PEのロード/ストア命令でアクセスできるのはDMEMだけと見られ、DMEMは外部メモリのキャッシュではなく、演算コアからアドレス空間として見える構造となっているようだ。
DMEMからのレイテンシが極めて小さいのは、DMEMがわずか2KBと容量が小さいためと見られる。DMEMからレジスタへは、ブロック図では64bitポートとなっているが、レジスタが4ライトポートとなっていることから、32bitポート2つとして使えると推定される。
NoCのI/Oに接続された外部メモリにアクセスするためには、メッシュネットワークを経由する。ネットワークルーターには、パケットを生成するRouter Interface Block (RIB)を経由する。
レジスタからRIBへの読み出しは、32bit 1ポート。パケットで送ることができるデータは32bits/サイクルなので、これで釣り合っている。Rawの場合はPEの特定レジスタに格納されたデータは、アウトプットFIFOへと入力され、ネットワークでセンドされる。つまり、レジスタ書き込みだけで、他のタイルへとレジスタ値を送ることができる構造となっている。これに近いアーキテクチャは、ネットワークプロセッサなどにも見られる。しかし、NoCではそうしたアーキテクチャの説明はされていない。RIBへの転送はレジスタを指定して、SEND命令で明示的に行なうと推定される。
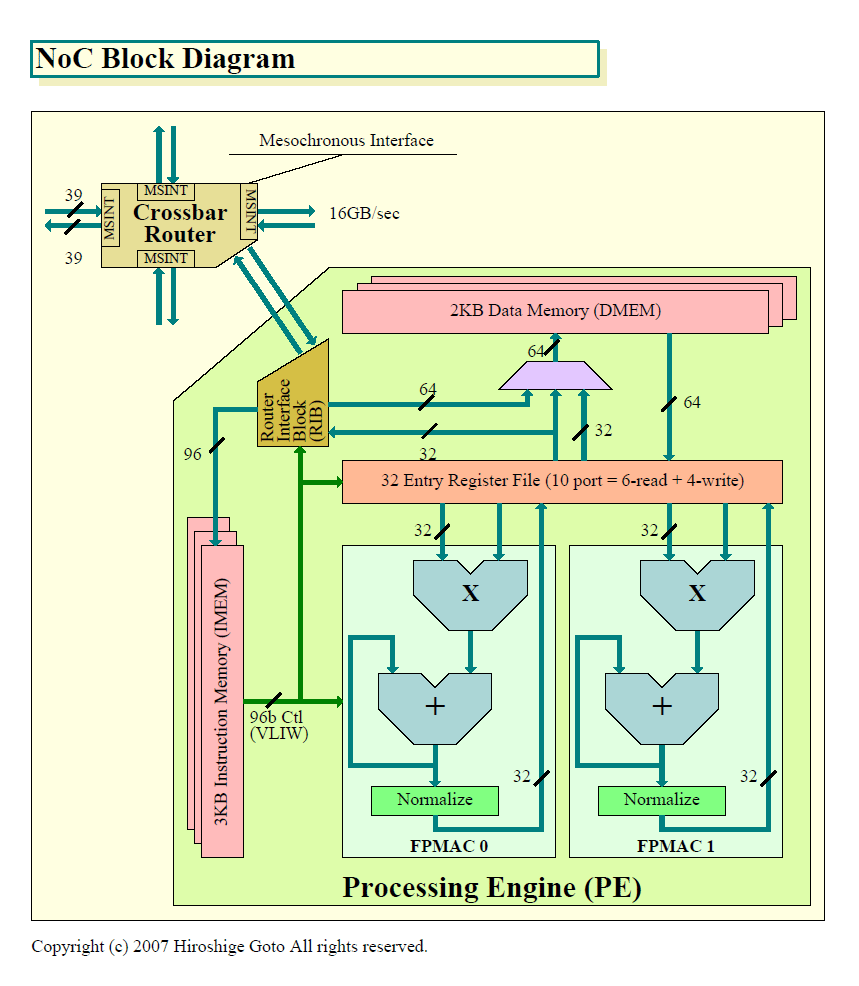 |
| NoC Block diagram(※別ウィンドウで開きます) PDF版はこちら |
また、ブロック図を見る限り、RIBへ送ることができるデータはレジスタからだけとなっている。DMEMからRIBへの読み出しポートがないため、DMEMのアドレスを指定してDMEM上のデータを直接パケットに格納することはおそらくできないと見られる。この点は、タイルプロセッサ的だ。
一方、パケットで送られてきたデータは、DMEMに格納される図となっている。つまり、外部メモリから直接レジスタにロードする命令は持たない可能性が高い。Rawの場合はレシーブしたデータがインプットFIFOに入り、演算コアからはレジスタからの読み出しとして扱える構造になっている。NoCでは、こうした演算コアへのバイパスパスは持っていない可能性が高い。レシーブしたデータは、DMEMからのロード命令でレジスタに読み込むものと推定される。ちなみに、RIBからDMEMへのポートは64bit幅となっているが、その理由はわからない。
●ルーティングを指定できるパケット
こうした構造からすると、いわゆるタイルプロセッサと比べると、NoCはタイルが緩い連携を取るように見える。そういう意味では、より普通のコンピュータ向けマルチコアの形態に近い。むしろ、パケットプロトコルネットワークでタイル間を制御・連携させることに主眼を置いたように見える。
NoCのパケットは「FLIT (FLow control unIT)」と呼ばれるスライスを複数束ねたフォーマットとなっている。それぞれのFLITは6bitsのコントロール部と、32bitsのデータ部分で成り立っている。パケットの最小サイズは2 FLITで、最大サイズの制限はない。コントロール部にパケットのヘッドとテイルをそれぞれ示すビットがあり、そこで連続するパケットかどうかが表される仕組みだ。コントロール部には、パケットのレーンなどの情報も格納される。ルーターは各ポート2レーンを備えている。
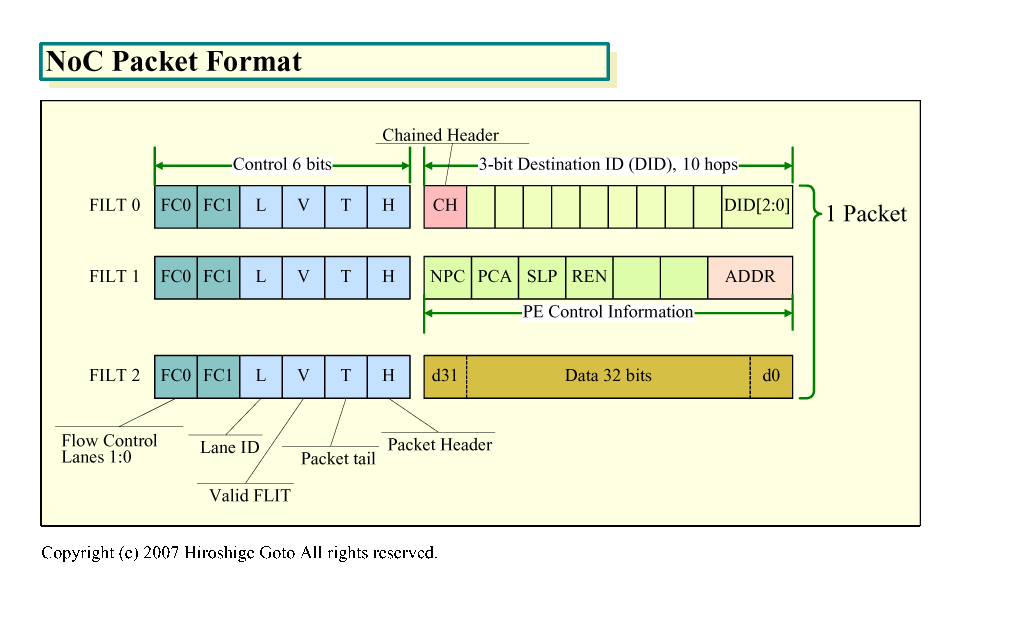 |
| NoC Packet Format(※別ウィンドウで開きます) PDF版はこちら |
最初のFLITはルーティングに必要な「Destination ID (DID)」と「Chained Header」で成り立っている。DIDは各3bitsで10個。1つのFLITには10個のDIDが格納できるため、最大10ホップのルーティングが可能だ。
3bitsでは当然80個のタイルと上下のI/Oインターフェイスを表すことはできない。80個のタイルとI/OにIDを振るには7bitsが必要だ。この3bit DIDは、パケットをセンドするルーターの出力ポートを表すという。
NoCのルーターは、そのルーターのタイルのPEへのポートと、上下左右(南北東西)の隣接するタイルのルーターへのポート、合計5ポートを持つ。もっとも、チップのエッジにあるタイルは少ない数のポートしか持たないため、最大で5ポートという意味だ。将来は、これに3DスタックするSRAMチップへのポートが加わり6ポートになる。Intelは2006年のIntel Developer Forum(IDF)時には、NoCではSRAMチップをプロセッサに重ねて、低レイテンシアクセスが可能なメモリとして使うと説明している。5(6)ポートのルーターの、どのポートからセンドするかを指示するだけなら3bitsで足りる計算だ。
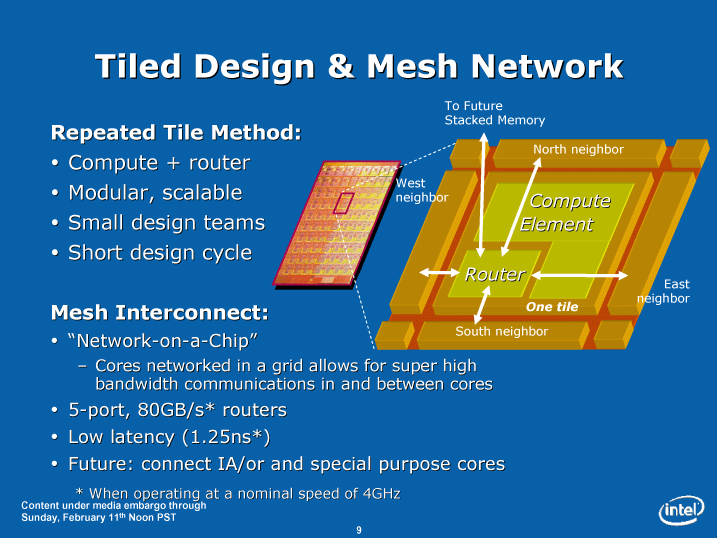 |
| Tiled Design & Mesh Network(※別ウィンドウで開きます) PDF版はこちら |
タイルにIDを振って直接ID指定しなかった理由の1つは、ルーティングをソフトウェア制御しやすくするためだと推測される。NoCのパケットの構造では、タイルAからタイルBまでのルートをDIDで指定することができると見られる。DIDがルーターのポートを指定するのなら、最短ルートだけでなく、例えば特定のタイルを迂回するといったルーティングも可能になる。ルーティングを統合制御するハードウェア機構が見あたらない以上、NoCではこうしたルーティングはソフトウェアで制御すると推定される。ルーティングの実験を行ない易くするために、DIDでの制御を採用した可能性がある。
実際、IntelはNoCの説明ムービーの中では、そうしたルーティングの説明をしている。障害が発生したタイルのルーターを迂回してルーティングをする、あるいは、ダイ(半導体本体)上で電力密度が高まった場合には、アクティブなタイルを離すことで分散させるといったアプローチだ。後者は先ほど触れたIntelの論文Thermal-effective clustered microarchitecturesと、基本的な考え方は近い(実現方法はかなり異なっている)。
●10ホップでI/Oまでアクセスが可能
ルーター毎にポートを指定してホップすると、全てのタイルが10ホップのネットワークでメモリとI/Oにアクセスできる。下が外付けメモリのインターフェイスから最も遠いタイルからホップした場合の図だ。最もメモリから遠い最下段のタイルでも、10ホップ目でメモリインターフェイスに到達する。他のタイルも、10ホップ目で出力された先のルーターで、デフォルトがPEへの転送となっていれば11ホップ目のタイルにアクセスすることもできる。
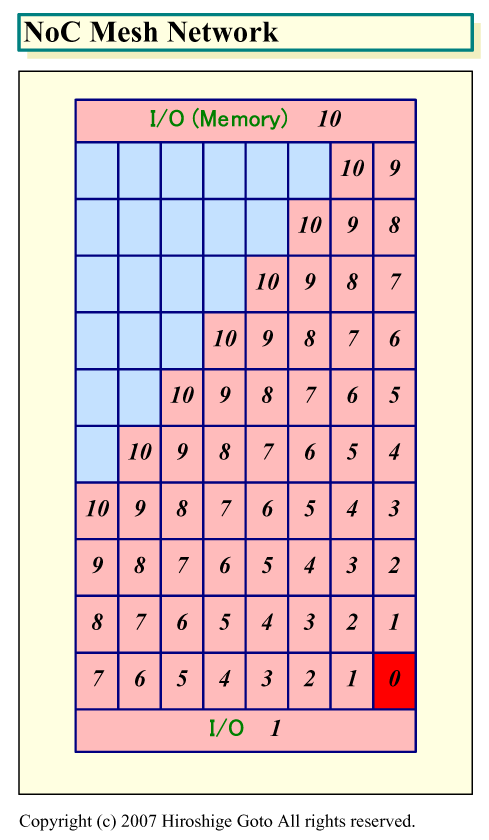 |
| NoC Mesh Network(※別ウィンドウで開きます) PDF版はこちら |
他のタイルについては、10ホップでは全てにアクセスできるわけではないが、DID群の頭には2bitsのChained Headerがつくので、10以上のホップも可能となっている。いずれにせよ、1つのFLITのDIDでタイル-メモリまたはI/O間の最小限のホップは可能だ。
2つ目のFLITはデスティネーションのPEを制御する命令とアドレスで占められる。PESLEEP/PEWAKEも実際にはここに埋め込まれると推定される。
さらにFLITに32bit長に区切られたデータを格納することもできる。パケット長に制限はないため、データFLITをつなげて、ある程度の粒度のデータを一度に転送することも可能だ。
NoCのパケットの構造だと、あるタイルが、他のタイルをウエイクアップさせて、処理を渡すことが可能になる。一連の処理を、タイル00から連なるタイル01、タイル02、タイル03といった隣接したタイルで連携させれば、最小の配線レイテンシでパイプライニングすることができる。これは、Cell Broadband Engine(Cell B.E.)のSPE(Synergistic Processor Element)のパイプライニングとも通じるアプローチだ。その上で、例えば、電力密度を下げるためにタイルのアロケーションを変更するといった制御を行なうと推定される。
●メモリダイスタッキングが次のフェイズ?
NoCから見えるのは、Intelが現在考えている、メニイコアの演算コアアレイの方向性だ。NoCを見ると、タイルプロセッサのようにCPUのエレメントを分解してタイルに再構成する大胆なアプローチは、今のところまだ見えない。しかし、GPUコアのように、データパラレルだけに特化した方向性とも大きく異なる。Cell B.E.のSPEのように、単体での独立性が強いコアを連携させる手法に見える。今のところは、コアアレイの制御については、より穏当なアプローチを目指しているように見える。
NoCのメモリアーキテクチャは、現状ではややアンバランスな構成となっている。DMEMの容量が2KBと極めて小さい。にも関わらず、チップ外のDRAMへのアクセスパスは長い。各タイルのPEがDRAMにアクセスするためには、メッシュネットワークを経由しなければならない。メモリから最も遠いタイルは、メッシュネットワークで10ホップ分のメモリアクセスレイテンシがある。また、ネットワーク構造上、レイテンシも読みにくいと推定される。さらに、高い演算能力が要求するメモリ帯域も膨大だ。
こうしたメモリ構造でも、プロセッサのローカルに大容量のテンポラリメモリがあれば、かなりレイテンシは隠蔽できる。しかし、NoCの場合はDMEMが小さいため、あらかじめ大きなデータブロックをPE内に転送して置くこともできない。演算コアをフル稼働させようとすると、メモリの制約がきつい。
こうした構造を見ると、NoCはSRAMチップのダイスタッキングを前提にして設計されていると推定される。ダイスタックしたSRAMチップは、各タイルのオンチップルーターにポートで接続される。そのため、どのタイルからも1ホップでアクセスが可能になる。このSRAMのアーキテクチャも、メニイコアのカギの1つだ。
IBMも、2006年のISSCCのキーノートスピーチでは、ダイスタッキングを将来のカギとなる技術の1つとして挙げていた。組み込み系ではすでに浸透しているメモリダイのスタッキングが、将来はコンピュータ向けパフォーマンスCPUにも浸透して来るのかもしれない。さらに先では、PCでもDRAMメモリがスタックされるのが当たり前になる日が来るかもしれない。ただし、拡張性とアクセス性のトレードオフとなるが。
 |
| What's Next?(※別ウィンドウで開きます) PDF版はこちら |
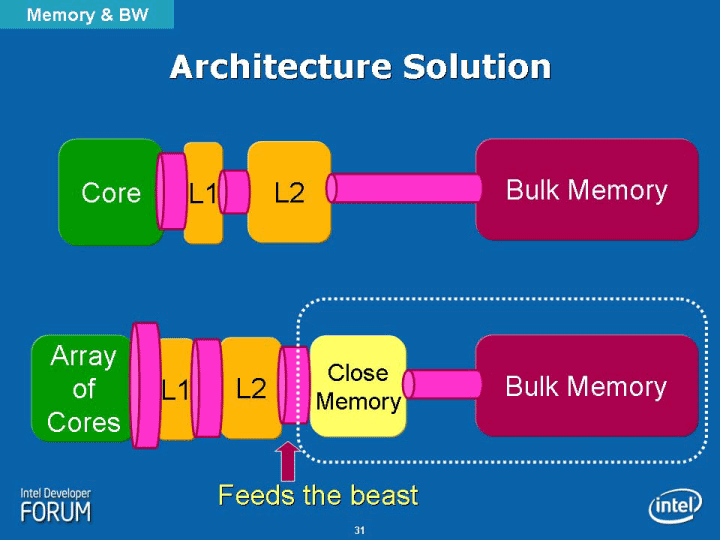 |
| Architecture Solution(※別ウィンドウで開きます) PDF版はこちら |
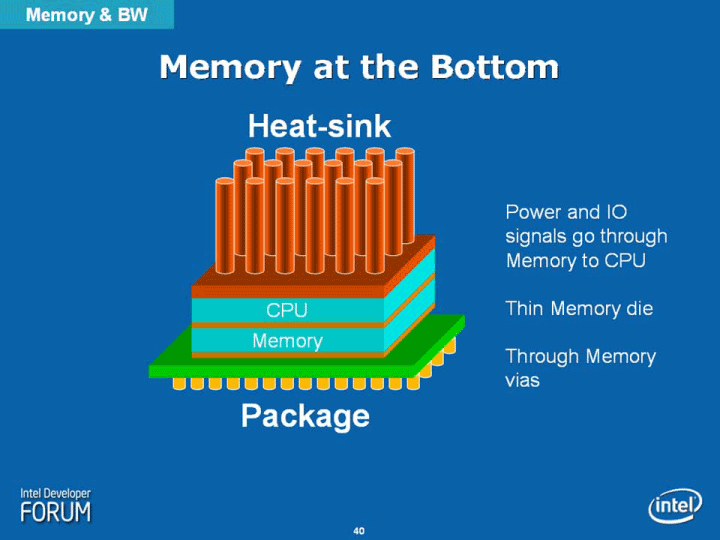 |
| スタッキングを前提とした設計(※別ウィンドウで開きます) PDF版はこちら |
□関連記事
【2007年2月15日】【海外】Intel CPUの未来が見える80コアTFLOPSチップ
http://pc.watch.impress.co.jp/docs/2007/0215/kaigai337.htm
(2007年2月21日)
[Reported by 後藤 弘茂(Hiroshige Goto)]
【PC Watchホームページ】
PC Watch編集部 pc-watch-info@impress.co.jp ご質問に対して、個別にご回答はいたしません
Copyright (c) 2007 Impress Watch Corporation, an Impress Group company. All rights reserved.