 |


■後藤弘茂のWeekly海外ニュース■45nmプロセスの利点を活かすIntelの次世代CPU「Penryn」 |
●チップのダイの小ささが利点のPenrynファミリ
Intelは「Core Microarchitecture (Core MA)」の第2世代CPU「Penryn(ペンリン)」を、モバイル、デスクトップ、サーバーまで3市場それぞれに投入する。45nmプロセスで製造されるPenrynファミリは2008年頭から登場する。コードネーム的にはモバイルCPUはPenryn、デスクトップCPUはデュアルコアが「Wolfdale (ウルフデール)」、2ダイのクアッドコアが「Yorkfield(ヨークフィールド)」、サーバーCPUがWolfdaleとクアッドコアの「Harpertown(ハーパータウン)」となる。
【2月8日訂正】記事初出時、サーバー向けクアッドコアCPU「Harpertown(ハーパータウン)」のコードネームが誤っておりました。お詫びして訂正します。
Penrynのポイントのひとつは、ダイ(半導体本体)の小ささ。Intelの新アーキテクチャCPUは、従来、200平方mmのダイサイズ(半導体本体の面積)で登場し、次のプロセス世代で140平方mm程度にシュリンク、3プロセス世代目で100平方mmクラスに到達するのがパターンだった。
ところがCore MAでは、最初のMeromが143平方mmと従来より1世代分小さく、Penrynでは100平方mm程度にシュリンクする。そのため、Penrynコアを2個載せるクアッドコアの「Yorkfield(ヨークフィールド)」でも、2個のダイで合計200平方mm程度とダイを小さく抑えられる。Merom/Penrynの方向性では、CPUコアは小さく留め、コア数を増やしてパフォーマンスを上げる方向への転換が明確となっている。
CPUダイサイズのトレンドをチャートにすると、Intelの変化がよくわかる。Core MAの方向性からは、今後のIntelのCPUアーキテクチャの道筋が見える。Core MAの次に登場する「Nehalem(ネハーレン)」、Core MAの後継となる「Gesher(ゲッシャー)」、これらのCPUも、おそらくCPUコア自体はある程度の規模に留める可能性が高い。
●Meromとそれほど変わらないPenrynのダイレイアウト
Penrynファミリについては、まだ詳細は明らかになっていない。ただし、Intelは、今週米国で社員向けのカンファレンスを開催している。Penrynに隠し機能がある場合は、Intel社内的にはそこで明らかにされる可能性が高い。話題になっていたPenrynコアがHyper-Threadingを実装しているかどうかの件についても、もし実装されているのなら、ここで社員には明かされるかもしれない。ただし、今のところPenrynにHyper-Threadingという情報は、具体的には一切出ておらず、可能性は低いと見られている。
もちろん、社内カンファレンスの情報はダイレクトに社外には出てこない。しかし、内部的に情報が出るなら、近いうちにPenrynの正体が見えてくる可能性は高い。
また、MeromとPenrynのダイの比較からも、Penrynについて、ある程度のことはわかる。
Penryn-6Mのトランジスタ数はIntelの説明では約4億1千万。Merom-4Mの2億9,100万と比較すると、Penrynでは、ほぼキャッシュSRAMの増量分だけトランジスタ数が増えたことがわかる。L2以外のデュアルCPUコアやインターフェイス部分のトランジスタ数は、依然として約5,000万弱と推定される。つまり、CPUコア部分にトランジスタを大量に投入する拡張は行なわれていないと見られる。
Penrynのダイレイアウトは、Meromと比較するとわかる通り、ほとんど変わっていない。実際の製品版のPenrynは、現在公開されているPenrynのダイ写真と異なる場合もありうる。しかし、すでにサンプルチップが完成しており、2008年頭にリリースするPenrynのスケジュールを考えると、現在公開しているダイ写真が製品版である可能性は高い。
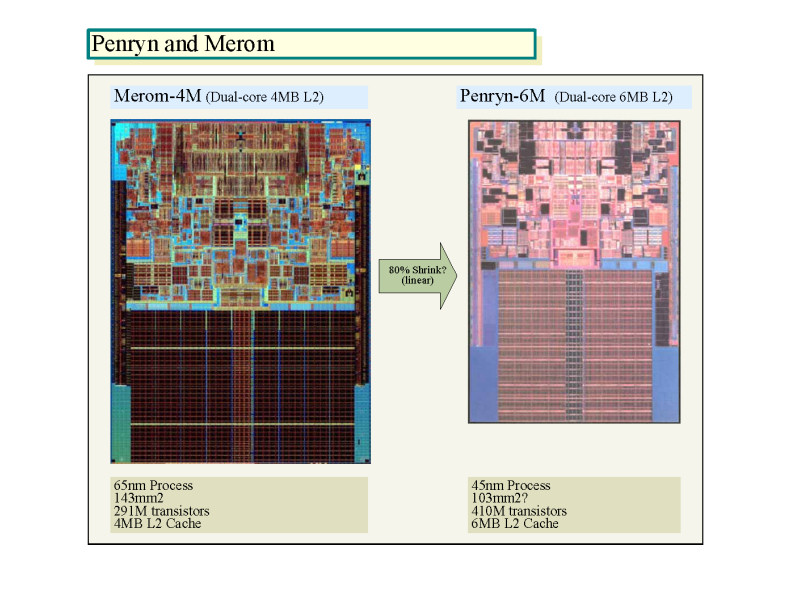 |
| MeromとPenrynのダイの比較 PDF版はこちら |
Penrynの各ブロックの配置は、光学シュリンクに見えるほどMeromと似通っている。これは、Intelの常套パターンで、新プロセスでのCPUは、まず、前プロセス世代のレイアウトを大きく変更しないで設計し、生産をスムーズに立ち上げる。次に、設計を最適化してダイサイズを縮小する。将来的にはPenrynのダイレイアウトは大きく変わる可能性が高い。
この点も、Penrynでレイアウトに大きなインパクトを与えるほどの拡張が行なわれていない可能性を示唆している。ただし、小幅の拡張で済むような改良は行なわれている可能性は高い。実際、PenrynではSSE4命令のある程度が組み込まれる。SSE4命令の多くは、それほどコアの大がかりな拡張を必要としないからだ。
また、PenrynにHyper-Threadingなどが実装されているかどうかも、ダイのラフな比較だけでは判断できない。アウトオブオーダー型CPUの場合、Hyper-Threadingの実装コストはそれほど大きくないからだ。トランジスタをそれほど増やさなくても実装できる。
また、Intelの場合、ある機能を有効にする時には、その前の世代で実装してテストを行なっている場合が多い。実際、Hyper-Threadingは0.18μm版Pentium 4(Willamette:ウイラメット)時から組み込まれていた。Penrynでイネーブルされる機能も、Merom時から実装されていている可能性がある。
●Meromの弱点がどこまで解決されるかがポイント
Merom世代のCore Microarchitectureの最大の弱点は、入り口だ。命令キャッシュからのフェッチと、命令のプリデコード/デコードにボトルネックがある。
Meromでは、32KBのL1命令キャッシュからフェッチユニット(Instruction Fetch Unit)が16 bytes単位で命令をフェッチする。それに対して、AMDの次の「Barcelona(バルセロナ)」系CPUやCentaur Technologyの「CN」といった次期CPUはいずれも32 bytesで命令フェッチを行なう。プリフィックスで長くなった命令を、パイプラインを充填するのに十分な数フェッチするには32 bytesが必要だとAMDやCentaurは主張する。Intelの16 bytesフェッチは、狭すぎる可能性がある。
フェッチの次に位置するプリデコーダは、フェッチした命令ストリームの中の命令区分をマーキングする。プリデコーダは最大6個のx86命令を1サイクルで処理できるが、命令個数が少ない場合だけでなく多い場合もピーク値が出せない。例えば、7命令が含まれているケースでは、6命令までを1サイクル、次の1命令を1サイクルで切り出すため2サイクルが必要となる。また、命令長を変化させる命令プリフィックス「LCP (Length Changing Prefixes)」を使うと、劇的にプリデコードが遅くなってしまう。
デコードステージでは、4基ある命令デコーダが「Complex-Simple-Simple-Simple」の構成になっている。そのため、uOPs変換が「4-1-1-1」となる4命令並びの場合は1サイクルでデコードできるが、例えば「2-2-2-1」の場合はデコードに3サイクルかかってしまう。また、Meromでは64bitモードの「Intel 64」ではMicro-Fusionがサポートされていない。
Penrynでは、Meromのこうした弱点がどこまで改善されるかもポイントとなる。問題は、これらの件の多くが、複雑なx86命令セットの体系に起因するため、解決にコストがかかることだ。Penrynのレイアウトが大きく変わっていないことは、これらアーキテクチャ改良の大半は実装されないことを意味しているのかもしれない。
●ムダスペースの多いPenrynのダイ
Penrynのダイにはかなりムダな部分が見える。例えば、ダイの左右の下部は、空きスペースだ。これは、Penryn-6Mのダイが、キャッシュSRAM部分を1/2サイズにしても対応できる設計にしてあるからだ。ダイの下半分を占めるL2キャッシュSRAMのうち、下半分の3MBをカットすればPenryn-3Mになると見られる。
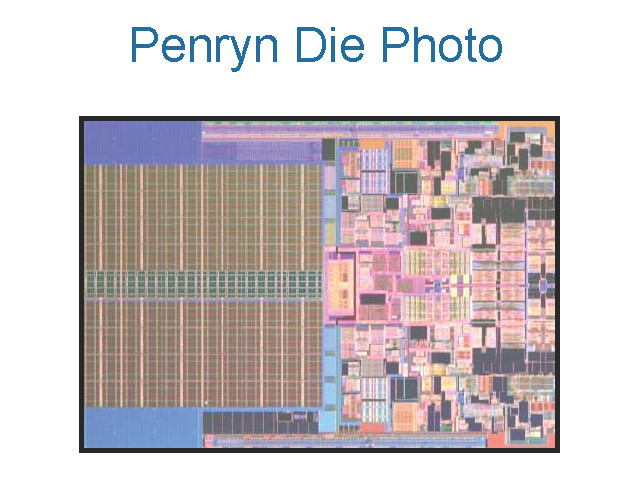 |
| Penrynのダイ写真 PDF版はこちら |
この設計は、Merom-4Mと同様だ。Meromも4MBのL2キャッシュSRAMのうち、下半分をカットすればMerom-2Mになる設計だった。SRAMサイズの変更で派生チップを作ることを容易にした設計だ。そのためにダイにムダが生じても、仕方がないと判断したと思われる。ちなみに、「Penryn-L」または「Penryn」とも呼ばれるシングルコア版のPenrynは、シングルコアのMerom-Lと同様に別設計となると見られる。
IntelはPenrynのダイサイズは公開していない。しかし、IntelはPenryn-6Mの熱設計に関して、ダイが100平方mm程度に縮小するため熱密度が高くなることを顧客に昨年(2006年)伝えている。CPUコア部分がMeromからリニアに80%縮小だと推定すると、Penryn-6Mのダイはほぼ103平方mm程度となり計算が合う。最近では、新プロセスに移行した場合も、最初は縮小幅が70%に達しない場合が多いので、80%縮小は納得できる数字だ。
この想定に従ってスケールしたのが、下の図だ。この想定では、コア部分は60数%の面積に縮小、キャッシュが増えてダイサイズは約72%の縮小となる。正確な数字はまだわからないが、おそらく、大きくは外れないだろう。
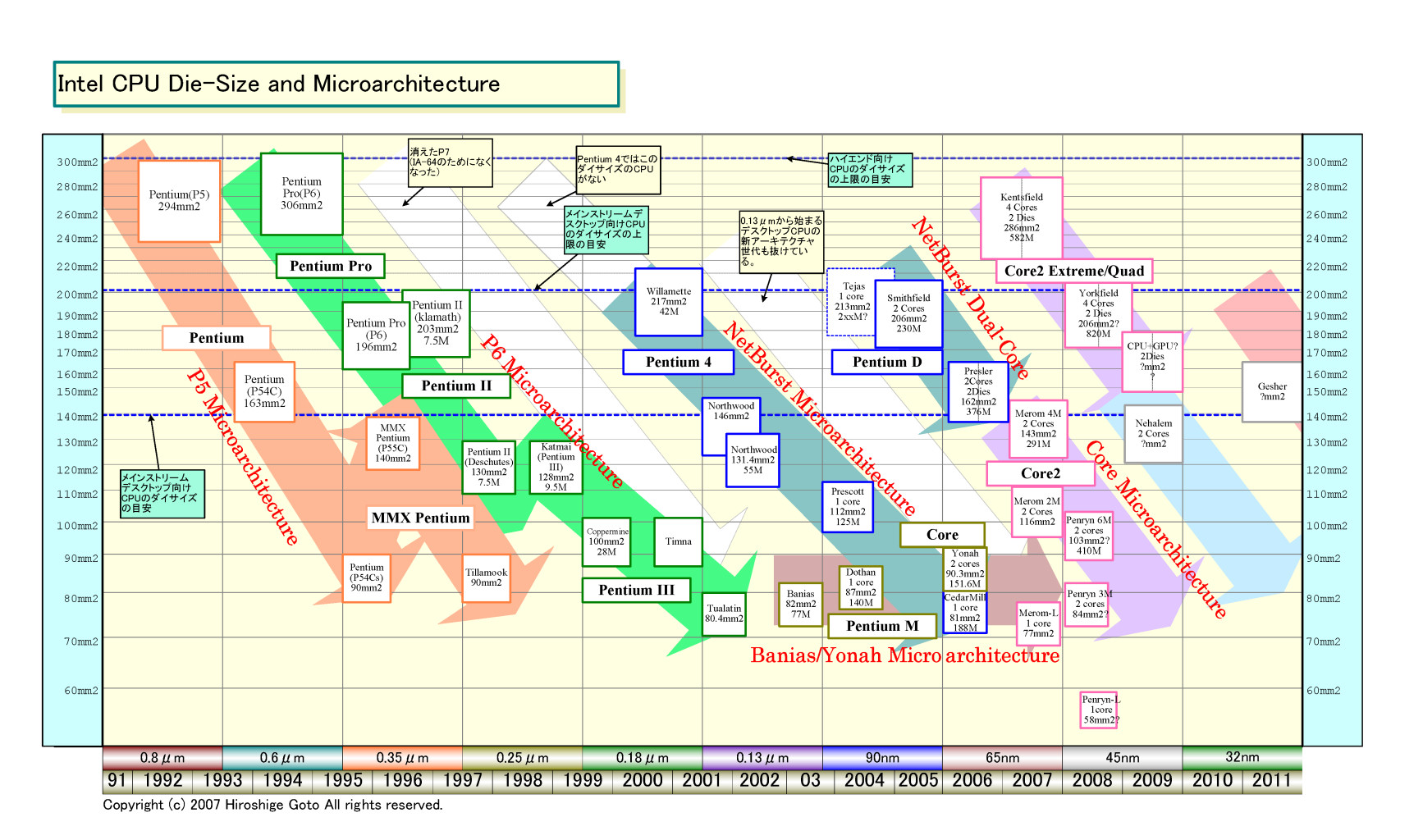 |
| Intel CPUのダイサイズとマイクロアーキテクチャの移行図 PDF版はこちら |
ダイの小さなPenrynの最大の問題は、明らかに電力密度/熱密度だ。ダイの縮小に比例するだけ消費電力が下がらなければ、面積当たりの消費電力と発熱量が増える。そのため、Penrynでは、原理的にMeromより熱設計が困難となる。Intelのイスラエル設計のCPUはコアが小さいことが大きな利点となっているが、熱設計ではそれがアダとなっている。そのため、IntelはモバイルのPenrynの通常電圧版ではTDP(Thermal Design Power:熱設計消費電力)を下げると言われている。ただし、Meromと同レベルの熱設計で対応できるようにするために、TDPを下げるという方法だ。
また、IntelはモバイルのPenrynではより熱抵抗の小さなTIM(Thermal Interface Material)などの採用を呼びかけている。TIMなどを改良しないと、CPUパッケージに対する冷却モジュールの接着にかける圧力を高めなければならなくなる。しかし、その場合は、破損などの問題が発生する可能性がある。Penrynの高い電力密度は、他にも問題を発生させる。ダイ上でのホットスポット間がより近接し、特定ポイントの発熱が周波数の制約となりやすくなる。
●45nmプロセスがブーストするPenryn
プロセス技術的に見るとPenrynはIntelの45nmプロセス「P1266」の利点を活かすことができる。45nmプロセスは、一言で言えば、過去数年の半導体プロセスの暗いトンネルからの出口。Intelのみならず半導体業界は90nmプロセスからリーク電流(Leakage)の急増という壁に悩まされてきた。Intelの45nmは、そのトンネルからの出口の兆候であり、再びCPUの動作周波数が上がる可能性も示している。
Penryn以降は、緩やかではあるが、再びCPUの周波数は向上カーブを描いて行く可能性が高い。ただし、CPUのシングルスレッド性能向上の壁は、半導体プロセスだけではないので、マルチコア化がこれで鈍化するとは考えられない。
Intelの45nmプロセスでのリーク電流低減のポイントは、トランジスタに高誘電率(High-k)のゲート絶縁膜とメタルゲートの組み合わせを採用したことにある。トランジスタのリーク電流のうち、最大の問題になりつつあるのは、ゲートからのゲートリーク電流。ゲートリーク電流は、90nmプロセス頃からゲート絶縁膜が微細化によって原子数個分にまで薄くなってしまったことで急増した。その結果トランジスタのスイッチングがなくても電流が流れる、いわば水道の蛇口が閉まらない状態になってしまっている。CPUの消費電力が上がった一因は、リークによるムダな電力消費が増えたことにある。
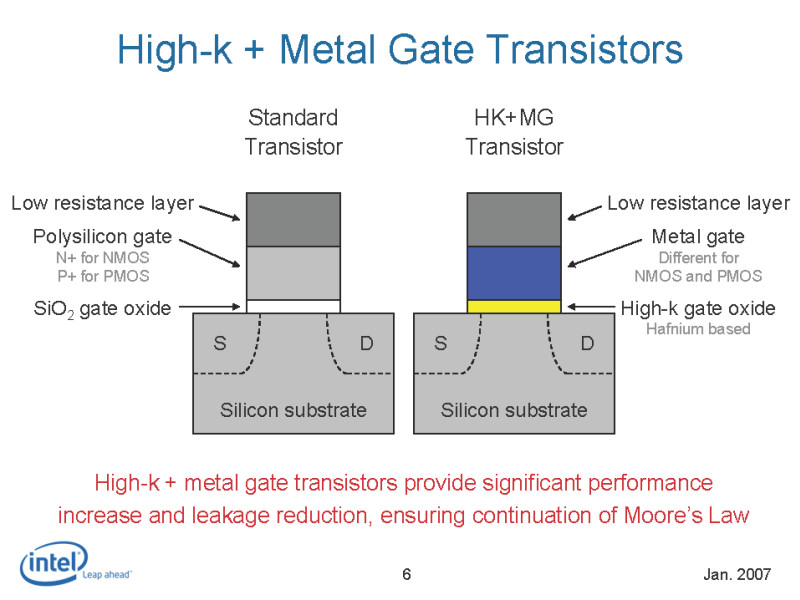 |
| 従来のトランジスタ(左)とHigh-k+金属ゲートのトランジスタ(右) PDF版はこちら |
そこで、5~6年前から研究が盛んになったのが、従来のゲート絶縁膜の二酸化ケイ素(SiO2)に代わる、High-k材料だ。High-kを使うと、膜厚をより厚くすることで量子トンネル効果を抑圧できる。その結果、ゲートリーク電流を劇的に低減して、タダ漏れ状態を改善して、ムダな電力消費を抑えることが可能になる。Intelの説明によると、45nmプロセスでは65nmプロセスに対して、ゲートリーク電流は1/10以下に低減するという。また、もうひとつのリーク電流であるソース-ドレインリーク電流は1/5以下に低減するか、または同じソース-ドレインリーク電流で20%トランジスタスイッチング速度の向上が見られるという。
 |
| High-k 45nmプロセスのメリット PDF版はこちら |
電力のムダが少なくなることは、CPUのパフォーマンス/消費電力の向上を意味する。Penrynでは、その分、同じTDPの枠内で周波数を向上させる余地ができる。ちなみに、メタルゲートはHigh-kとの組み合わせで必須になると見られている技術だ。
High-kが、いかにカギとなる技術かは、2003年の半導体カンファレンス「2003 ISSCC (IEEE International Solid-State Circuits Conference)」での、ゴードン・ムーア氏のキーノートスピーチを振り返ればよくわかる。ムーア氏は、スピーチの中でリーク電流の問題に触れ、解決策としてHigh-kを挙げた。つまり、ムーアの法則を継続させるカギが、High-kというわけだ。ちなみに、ムーア氏はさらにその先の技術として三次元構造トランジスタや完全空乏型のSOI(silicon-on-insulater)にも言及している。High-kの先にも、まだ対策が待っている。
整理すると次のようになる。半導体産業は、90nmプロセスで予想を超えるリーク電流の急増に遭遇。その結果、チップの消費電力が劇的に増大してしまい、CPUアーキテクチャはマルチコアへと戦略を転じる大変革期を迎えた。
Intelでは90nm製品がこの問題のために立ち上げがもたつき、65nmでは改善されたものの、まだ抜本策は見えていなかった。しかし、45nmでは、ついにトンネルを抜ける気配が見えてきたというわけだ。今後も、3次元構造のトライゲートトランジスタなどの採用が順調に進んで行けば、リーク電流の問題は、解決して行くことになる。
□関連記事
【1月29日】Intel、45nmプロセスの次期CPU「Penryn」の試作に成功
http://pc.watch.impress.co.jp/docs/2007/0129/intel.htm
【2006年10月10日】【海外】Intelの次世代モバイルCPU「Penryn」が見えてきた
http://pc.watch.impress.co.jp/docs/2006/1010/kaigai309.htm
【2006年10月4日】【海外】SSE4命令とアクセラレータから見えるIntel CPUの方向性
http://pc.watch.impress.co.jp/docs/2006/1004/kaigai307.htm
(2007年2月6日)
[Reported by 後藤 弘茂(Hiroshige Goto)]
【PC Watchホームページ】
PC Watch編集部 pc-watch-info@impress.co.jp ご質問に対して、個別にご回答はいたしません
Copyright (c) 2007 Impress Watch Corporation, an Impress Group company. All rights reserved.