 |


■後藤弘茂のWeekly海外ニュース■メモリアクセス粒度が課題となるG80時代のGPUメモリ |
●100GB/secに近づきつつあるGPUのメモリ帯域
GPUのメモリ帯域は100GB/secに近づきつつある。NVIDIAの最新GPU「GeForce 8800 GTX」(G80)では、メモリ帯域は86.4GB/secに達する。メモリチップはGDDR3 900MHz(転送レート1.8Gbps)で、DRAMインターフェイスは384bit幅。従来の256bit幅インターフェイスより1.5倍インターフェイスを広くするブルートフォースな(力まかせの)手法で帯域を広げた。
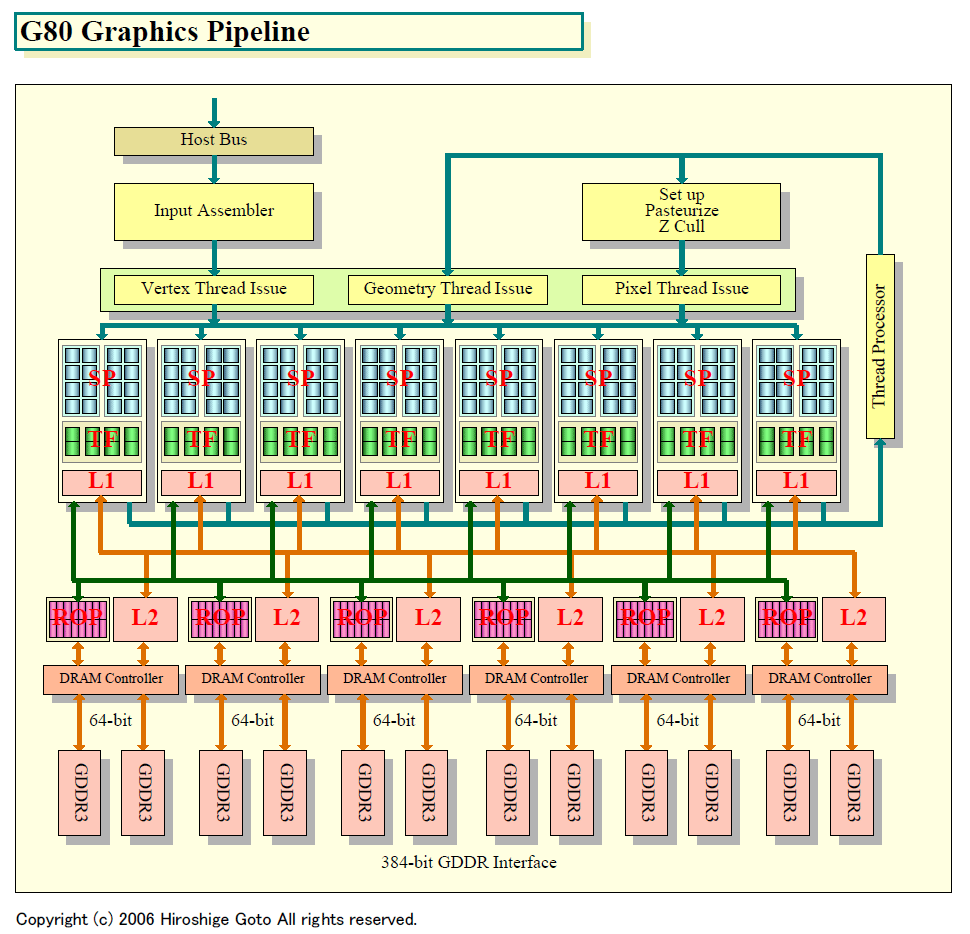 |
| G80 Graphics Pipeline(※別ウィンドウで開きます) PDF版はこちら |
G80のメモリインターフェイスは、1つのメモリコントローラに統合された設計で、ウワサされていたような用途別の2つのメモリコントローラを持つわけではない。演算コアは、384bit幅のインターフェイス全体に渡ってシームレスなアクセスが可能だ。コンピューティングパフォーマンスを上げると、それに見合うだけのメモリ帯域が必要になる。そのため、G80ではメモリ帯域を広げる必要があった。
ただし、G80では生コンピューティングパフォーマンスの劇的な向上と比例するほどメモリ帯域を上げていない。これは、3Dグラフィックスの進化につれて、コンピューティングとメモリアクセスのバランスが変わってきているためだ。テクスチャ中心からシェーダ中心へと、3Dグラフィックスが変わったことで、グラフィックスパフォーマンス当たりのメモリ帯域の必要量は減少しているという。
以前は、ピクセルシェーダプログラムは非常に短く、ピクセルにテクスチャを貼って数命令のシェーディングをしてアウトプットというパターンだった。その場合、コンピューティングサイクルに対して、テクスチャリードとピクセルアウトの比率が高く、コンピューティング能力に対して多くのメモリ帯域が必要だった。
しかし、現在/将来の3Dグラフィックスは、シェーダコンピューティング中心へとどんどん向かっている。シェーダプログラムが長くなれば、コンピューティングサイクルに対するピクセルアウトの比率が少なくなる。つまり、シェーダプログラムが10命令から1,000命令になれば、Shaderの10サイクルに1回ピクセルが出力されていたのが、Shaderの1,000サイクルに1回しかROPに対してピクセルが出力されなくなる。
反面、ROPの高機能化にともなってROPのメモリアクセスは増える。しかし、ShaderからROPに対する出力が減るため、シェーディング処理に対するメモリ帯域は相対的に減ることになる。また、長いシェーダプログラムはテクスチャ中心ではなく、コンピューティング中心となり、テクスチャフェッチの比率も少なくなる。そのため、テクスチャフェッチのメモリ帯域の必要量も減ることになる。
結果、相対的にコンピューティングパフォーマンスの向上分ほど、メモリ帯域は上げる必要がない。G80のメモリでは、そうした傾向が顕著に見て取れる。
●DRAMの高速化を支えるPrefetch技術
NVIDIAはG80ではGDDR4メモリをサポートしない。対応するのは、GDDR3までだ。これは、GDDR4をいち早くサポートしたAMD(旧ATI Technologies)との大きな姿勢の違いだ。GDDR4のサポートは、じつは単純にDRAMコントローラをGDDR4対応にするだけでは済まない。もっと根本的な対応が必要となる。それは、アクセス効率の問題があるためだ。
NVIDIAがGDDR4を選ばなかった理由はコストとパフォーマンスのバランス、そしてメモリアクセス粒度の増大によるメモリアクセス効率の悪化のためだ。
「GDDR4を選ばなかった理由は、色々な要素が絡んでいる。まず、理由の1つは、GDDR4が十分に高速ではなく、またずっと高価格であることだ。今の時点では、GDDR4は正しい選択ではないと考えた。多分、しばらく後になればGDDR4も正しい選択になるだろう。しかし、(価格と速度が見合ったとしても)メモリ(アクセスの)粒度は問題だ。この問題については、業界全体で、いいソリューションを作り出す必要があると思う」とDavid Kirk氏は語る。
GDDR4はGDDR3よりも、同じメモリインターフェイス幅でアクセスした場合のメモリアクセス粒度が高くなってしまうため、処理によってはメモリ効率が悪くなる。
この問題の背景には、DRAMテクノロジの根本的な問題がある。DRAMは世代毎にメモリコアのセル集積度は上がるが、メモリコアに対するアクセス速度はほとんど上がっていない。しかし、DRAMインターフェイスの転送レートは、プロセッサの性能にできるだけ合わせて向上させることが求められている。そのため、現在の高速DRAMは「Prefetch」と呼ばれる手法で、メモリコアとインターフェイスの速度のギャップを埋めている。
例えば、現在のDDR2やGDDR3は、Prefetch4テクニックを使っている。Prefetch4では、4n bitのデータを1クロックでメモリコア読み書きすることで、メモリコアの4倍のバス転送レートを可能にしている。つまり、メモリコアの周波数はバスの周波数の1/4ですむため、同じメモリコア技術を使った場合はSDRAMの4倍の転送が可能になる。
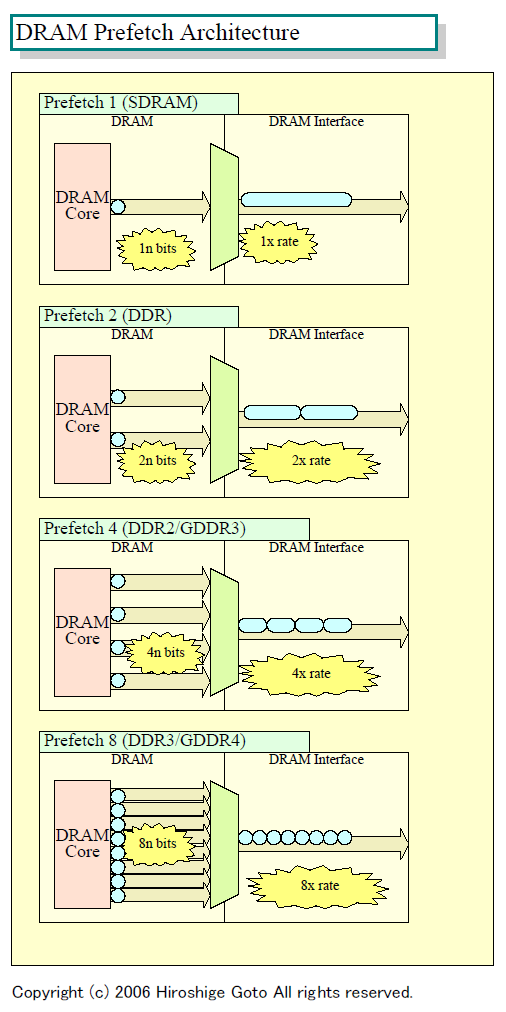 |
| DRAM Prefetch Architecture(※別ウィンドウで開きます) PDF版はこちら |
DRAMのメモリコアの速度はあまり変わらないため、DRAMはPrefetch幅をどんどん広げてインターフェイスを高速化してきた。実質Prefetch1だったSDRAMから、Prefetch2のDDR、Prefetch4のDDR2/GDDR3。そして、DDR3/GDDR4はこれをさらに押し進め、Prefetch8でメモリコアへのアクセスを行なう。
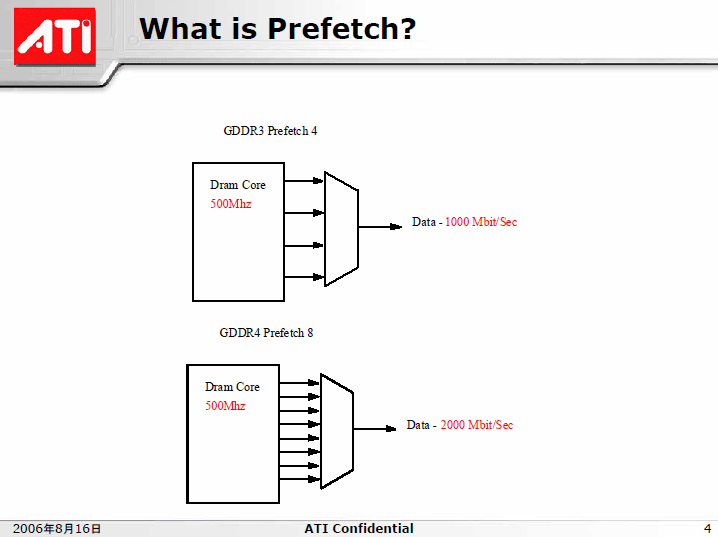 |
| What is Prefetch?(※別ウィンドウで開きます) PDF版はこちら |
GDDR4のPrefetch8では、メモリコアに8n単位でアクセスするため、“原理的”にはメモリコアの8倍の転送、GDDR3の2倍の転送レートが可能となる。もちろん、インターフェイス側の技術的な限界はあるが、少なくともメモリコアとの比率では倍速化が可能だ。そのため、帯域が必要なグラフィックスでは、GDDR4はいいソリューションとなるというのが基本のアイデアだ。
●メモリアクセス粒度を押し上げるPrefetch技術
いいアイデアのように見えるPrefetch技術だが、そこには難点もある。それはメモリアクセス粒度が上がってしまうことだ。例えば、Prefetch4なら、メモリセルからは4n bits単位で読み出す。だから、64bit幅のインターフェイスなら64bits × Prefetch 4の256bitsがアクセスの最小単位になる。つまり、1回のアクセスで256bits(32Byte)をDRAMメモリから読み出すわけだ。
現在のGPUにとって、このGDDR3のPrefetch4での256bitsメモリアクセス粒度は一応、ロスが少なく使える範囲だ。問題はGDDR4のPrefetch8だ。Prefetch8となるとアクセスは8bits単位となり64bit幅のDRAMインターフェイスなら最小単位が512bitsになってしまう。これはGPUにとってもさすがに大きすぎる。
Kirk氏が指摘しているGDDR4のメモリ粒度の問題というのはこのことだ。メモリアクセス粒度が大きくなると、当然、アクセスの際にムダが生じる可能性が出てくる。256bitsのデータアクセスが支配的な場合、512bitsのアクセス粒度では、フェッチするデータの半分がムダになってしまう。
特にG80が目指している、汎用的なコンピューティングでは問題が大きくなる可能性が高い。アプリケーションによっては、ストリームタイプではなくランダムタイプのメモリアクセスが支配的な場合があるからだ。例えば、32bitsデータへのランダムアクセスが支配的なアプリでは、512bitsのアクセス粒度になると、最大480bits分がムダになってしまう可能性がある。
GPUにとって256bitsまでの粒度が都合がいいのは、Shaderプロセッサなどの構造に起因する。GPUのShaderプロセッサは、通常はSIMD型プロセッサが4個で1セットになったShaderクアッドを最小単位として構成されている。すると、Shaderプロセッサがデータフェッチを行なう場合、fp16なら、1エレメント16bitsで4way SIMDとなり64bitsのデータが基本単位となる。Shaderクアッドで4倍の256bits粒度。これがfp32になると512bits粒度。実際には、テクスチャフェッチの場合は、きっちりこの粒度の数字になるわけではないが、2x2の4ピクセルを1単位とすることで、ある程度のデータアクセス粒度を保ってることがわかる。また、Shaderクラスタが4個より大きくなる場合には、アクセス粒度はさらに大きくなる。
ちなみに、G80もスカラプロセッサに分解されているものの、グラフィックス処理では、この基本粒度は維持していると思われる。そうしないと、データアクセスの粒度が小さくなり、メモリアクセスや内部バス転送でもムダが生じてしまう。
●AMDはDRAMインターフェイスを32bits単位にしてGDDR4に対応
GDDR4で上がってしまうメモリアクセス粒度。そこで、AMDは、この問題を解決するためにDRAMコントローラに工夫をした。X1000(R5xx)世代からは、DRAMコントローラを32bit単位に分離して制御している。具体的にはリングバスで接続された各ノードに、2つの32bit DRAMコントローラが接続されている。DRAMには32bits単位でアクセスする仕組みだ。NVIDIA GPUの半分のインターフェイス幅でメモリにアクセスしていることになる。
32bit幅なら、Prefetch 8のGDDR4でもメモリアクセスの粒度は256bitsになる。つまり、64bit幅でPrefetch 4のGDDR3の粒度である512bitsの半分になる。ここからわかるのは、AMD系のDRAMコントローラの設計は、もともとGDDR4を見据えたものということだ。そして、G80の64bitインターフェイスは、GDDR4はまだ考えていないことを示している。
 |
| R520 Memory Controller(※別ウィンドウで開きます) PDF版はこちら |
しかし、この解決方法にもトレードオフがある。DRAMインターフェイスを細分化すると、当然、それだけ制御が煩雑になる。回路とオーバーヘッドが増えることになる。AMDは、それだけのトレードオフを払ってもGDDR4に対応した方が得策と考えた。この先のGDDR4の高速化を考えればいち早く対応した方がいいという読みもあるだろう。背景には、JEDEC(米国の電子工業会EIAの下部組織で、半導体の標準化団体)でGDDR3/4の策定を推進しているのがAMDだったという事情があるかもしれない。
一方、NVIDIAは、今のGDDR4には、まだ、それだけのトレードオフを払う価値がないと判断したことになる。NVIDIAの判断の理由は明快だ。GDDR4がGDDR3の2倍速いのなら、DRAMコントローラを複雑にするトレードオフを払うだけの価値がある。しかし、GDDR4がGDDR3より少しだけ速いだけなら、それだけの価値はない。それなら、DRAMインターフェイス自体の数を増やして高速化を図った方がいいというのがG80でのNVIDIAの判断だ。
GDDR4ではR5xxのような解決法がまだ残されている。しかし、GPUではDRAM側がx32(32bitインターフェイス)であるため、32bitのDRAMコントローラはGPUにとって最小単位となる。つまり、R5xxの現在の実装よりもアクセス粒度を小さくする手法はない。そのため、DRAM側アーキテクチャとしてPrefetch16は、かなりハードルが高い。次はなく、Prefetchのアプローチは壁に当たってしまったことになる。
●DRAMの次の大きな課題はメモリアクセス粒度
メモリアクセス粒度の問題は、DRAMの次の大きな課題で、Kirk氏の指摘のように業界全体を巻き込んだ議論になって行くと思われる。
じつは、すでにメモリアクセス粒度の問題を解決する技術自体は発表されている。Rambusが次世代メモリ「XDR2 DRAM」に実装する予定の「Micro-Threading」がそれだ。Micro-Threadingでは、メモリコア内のバンク群がそれぞれ、異なるrow/columnコマンドに対して独立して動作できるようにする。そして、1回のアクセスで、複数のrowとcolumnコマンドを送り、異なるバンク群に同時にアクセス。複数のrow/columnからデータを同時に読み出し、または書き込みする。この手法なら、メモリコアからの読み出しのPrefetch幅を広げても、複数の異なるデータを内包できるため、実質的にメモリアクセス粒度を下げることができる。アクセスのムダがなくなるわけだ。
JEDEC内部でも、この問題に対する議論が始まっているという。DDRやGDDRメモリの標準化を行なっているJEDECでは、次世代メモリとしてNew Generation(NG) Memoryとそれまでの中継ぎになるDDR4の技術的な議論を行なっている。そこでも、アクセス粒度の解決策につていの提案が行なわれているという。
GDDRは、汎用DRAM技術をベースしているため、DDR4/NGでの技術が将来的に反映されると予想される。ただし、Micro-threadingのような技術をもしJEDECスタンダードに取り込もうとすると、おそらく、特許問題の解決が必要となる。
 |
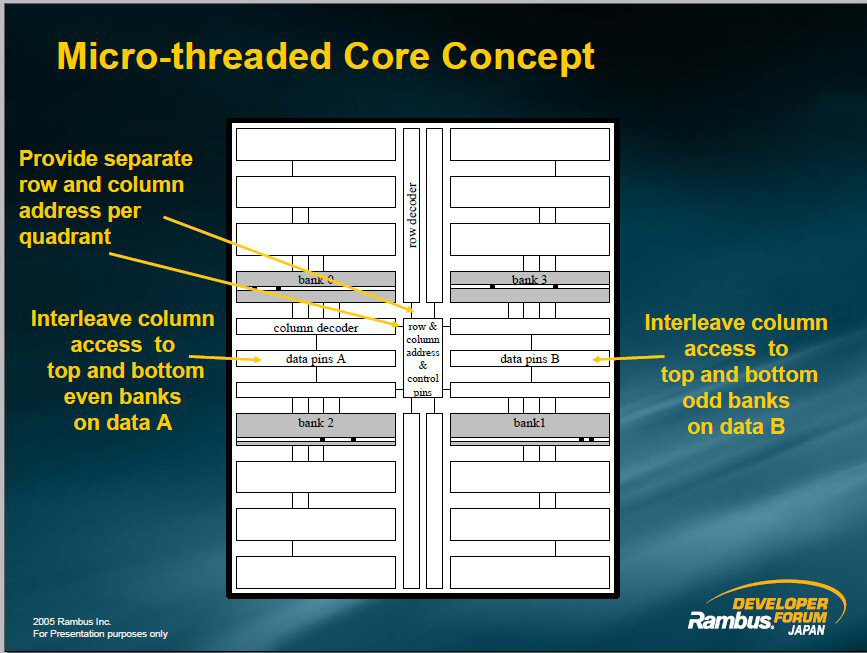 |
| Microthreading:Achieving High Bandwidth and Small Access Granularity | Micro-threaded Core Concept |
□関連記事
【11月27日】【海外】シェーダプログラムの進化と連動するGPUのマルチスレッディング化
http://pc.watch.impress.co.jp/docs/2006/1127/kaigai321.htm
【11月21日】【海外】G80とG7xの最大の違いはマルチスレッディング
http://pc.watch.impress.co.jp/docs/2006/1121/kaigai320.htm
【11月14日】【海外】GeForce 8800世代のキーとなるマルチスレッディング
http://pc.watch.impress.co.jp/docs/2006/1114/kaigai317.htm
(2006年12月1日)
[Reported by 後藤 弘茂(Hiroshige Goto)]
【PC Watchホームページ】
PC Watch編集部 pc-watch-info@impress.co.jp ご質問に対して、個別にご回答はいたしません
Copyright (c) 2006 Impress Watch Corporation, an Impress Group company. All rights reserved.