 |


■後藤弘茂のWeekly海外ニュース■Intel CPUの未来が見えるPARROTアーキテクチャ |
●高パフォーマンスと低消費電力を両立させる
Intelは、マルチコアと電力効率(Power Efficiency)の高いCPUアーキテクチャへと舵を切った。2006~7年のCPUは、NetBurst(Pentium 4系CPUアーキテクチャ)よりもずっと電力効率が高い新世代のCPUコアを複数搭載するようになるだろう。Intelは、2006~7年のCPUコアとして、モバイル向けには「Merom(メロン)」を開発しており、デスクトップ向けにも高電力効率コアを開発している(Meromベースという情報もある)。これらのCPUコアは、現在3命令/クロックの帯域のNetBurstよりも拡張され、4命令/クロックの帯域を備えるようになると推定される。つまり、クロック当たりの性能がさらに拡張されるわけだ。そして、Merom世代の先には、さらにアグレッシブに電力効率の向上を図った、次世代CPUアーキテクチャが計画されているとみられる。
ここへ来て、Intelは、こうした次世代CPUのヒントを示し始めている。学会やIntel Developer Forum(IDF)で、電力効率を追求した、新しいマイクロアーキテクチャの研究結果を発表し始めている。特に重要だと思われるのが「Power AwaReness thRough selective dynamically Optimized Traces(PARROT)」だ。PARROTは、Intelの研究機関であるMicroprocessor Labの研究者が発表した、電力効率にフォーカスした斬新なCPUアーキテクチャだ。
「我々は、電力効率のいいアーキテクチャにフォーカスしている。PARROTこそがその例だ。PARROTのようなテクニックは、将来のプロセッサにおいて、パフォーマンスを高めながら、電力効率も同時に高めることができる」とIntelのJustin R. Rattner氏(Senior Fellow, Corporate Technology Group, Senior Director, Systems Technology Lab)はPARROTの重要性を語る。
Intelは、Pentium Mから電力効率が高く、制限された熱設計枠(Thermal Envelope)の中で最大の性能を発揮できるCPUアーキテクチャ開発を始めた。PARROTは、そうした研究の最新の例だ。
では、PARROTはどうやってパフォーマンス向上と省電力化という、矛盾する要求を両立させるのだろう。
●アグレッシブな最適化によって性能を上げる
まず、PARROTでは、マイクロアーキテクチャ上の作業をできる限り再利用する。Pentium 4では、IA-32命令からデコードした内部命令(μOPs)をキャッシュすることで、デコード処理を再利用できるようにした。PARROTではそれをさらに押し進め、コードの最適化結果も再利用できるようにする。CPUが命令を実行する前の作業をできるだけ減らすことで、効率化を図る。CPUの性能は、ラフに言うと「動作周波数×IPC÷実行される命令数」に比例する。従来のIntelのアプローチは、動作周波数にフォーカスしつつ、ある程度IPC(1サイクルで実行できる命令数:instruction per cycle)も向上させるという方向だった。投機的な実行によって実行する命令数自体は増やしてしまうが、それは周波数とIPCの向上でカバーするという考え方だ。命令をより多く、より速く実行することに、アーキテクチャのポイントを置いてきた。
それに対してPARROTは、IPCの増大と命令数の削減などにフォーカスする。CPU内部で実行される内部命令(μOPs)の数を減らし、同時にスケジューリングの向上によって命令の並列度を高める。命令をより少なくして、効率よく実行することに焦点を置いている。命令を高速に実行するよりも、命令そのものを削除してしまう方が確実に高速だ。
そのため、同じ動作周波数でもPARROTの方が従来アーキテクチャよりパフォーマンスがアップする。また、実行される命令数が減ることで実行パイプラインのリソースの消費を減らすため、性能当たりの消費電力も抑えることができる。その結果、パフォーマンス向上と消費電力の低減の両方を同時に図ることができる。
高パフォーマンスと低消費電力の実現のために、PARROTでは従来のCPUよりもずっと高度な実行コードの最適化を行なう。コード最適化によって、不要なμOPsを削除したり、μOPsを融合またはSIMD化することでμOPs数を減らす。また、μOPs間の依存性のうち解消できるもの(真の依存でないもの)は解消し、レジスタのリネーミングを単純化することで、スケジューリングを向上させる。
ただし、こうした高度なコード最適化を、全てのコードに対して行なおうとすると、膨大な手間がかかりオーバーヘッドが大きくなり消費電力も増えてしまう。そこで、PARROTでは、コードによってCPU側のスケジューリングの手法を変える。具体的には、頻繁に使われるプログラムコードのシーケンスだけを最適化する。また、コードの最適化はCPUのパイプライン内では行なわない。バックグラウンドで平行して最適化を行なうことで、フォアグラウンドのパイプラインの動作に影響しないようにする。
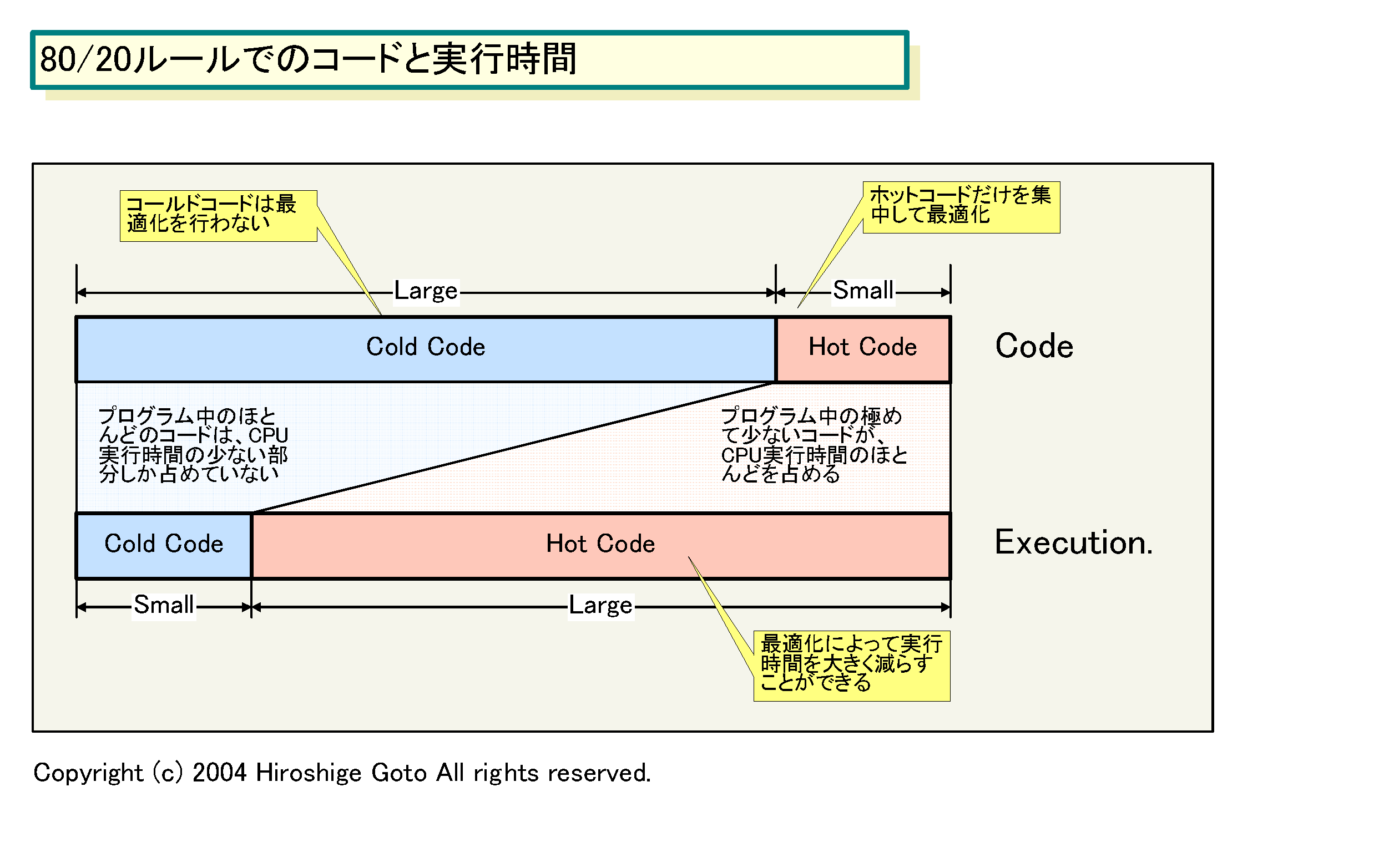
「PARROTの基本となっている観測は、長いプログラムのうち、実際にクリティカルな部分は少ないという事実だ。80/20ルールがここでも当てはまり、ごく少数の命令が、全マシンの実行を大幅にスローダウンさせている。そのため、賢いアプローチは、それらを区分けして実行することとなる。PARROTでは、これをコールドパイプ(Cold Pipe)とホットパイプ(Hot Pipe)と呼んでいる。80%の(クリティカルでない)命令は、低パフォーマンスと低パワーをターゲットにしたコールドパイプに送る。一方、20%の(クリティカルな)命令は高パフォーマンスで高パワーなホットパイプに送る。これで、効率よく性能を向上させることができる」とIntelのPatrick P. Gelsinger(パット・P・ゲルシンガー)CTO兼上級副社長(CTO & Senior Vice President)はPARROTの基本アイデアを説明する。
●80/20ルールを使って最適化
「80/20ルール」とGelsinger氏が言っているのはパレートの法則として知られている一般的な経験則。この場合は、プログラムのうち20%のコードセグメントがCPUの実行時間の80%を占め、残りの80%のコードは実行時間の20%程度しか占めないという意味となる。もちろん、プログラムの種類によってもこの比率は異なり、PARROTの論文では90%対10%とされている。重要なことは、プログラムの中で頻繁に使われるコードはごく一部という点だ。ごく一部のコードセグメントが、何度も反復して実行され、プログラムのワーキングセットのほとんどの時間を占める。これは、コードの“局所性”として知られており、頻繁に使われるコード部分は“ホットスポット(Hot Spot)”と呼ばれることもある。PARROTの論文では、頻繁に使われる部分は“ホットコード(Hot Code)”と呼ばれている。
PARROTはこのホットコードを、CPUの動作時にダイナミックに段階的に最適化して、最適化したコードをキャッシュしておく。さらにそのコードがより頻繁に使われるようなら、今度はもっとアグレッシブなコード最適化を施す。より頻繁に使われるコードほど、より最適化されるようになる。最適化されたコードはより速く実行できるため、頻繁に使われるコードほど高速実行が可能になる。
80/20ルールに従えば、このようにして20%のホットコードを最適化すれば、80%の実行時間をある程度短縮できるようになるわけだ。残りの80%のあまり頻繁に使われないコードは、PARROTではコールドコード(Cold Code)と呼ばれる。コールドコードは最適化しても意味が薄いため、従来通りに処理をする。80%のコールドコードは実行時間の20%しか占めないため、最適化しなくても性能に影響は少ない。
PARROTの論文によると、頻繁に使われるホットコード部分の振る舞いは、ほかのコールドコード部分とは異なることが多いという。より規則的で、予測しやすく、そのために、命令レベルの並列化がしやすいという。つまり、最適化がしやすいコード部分でもあるわけだ。
 |
| 80-20ルールでのコードと実行時間 PDF版はこちら |
●コールドとホットの2つのパイプを備える
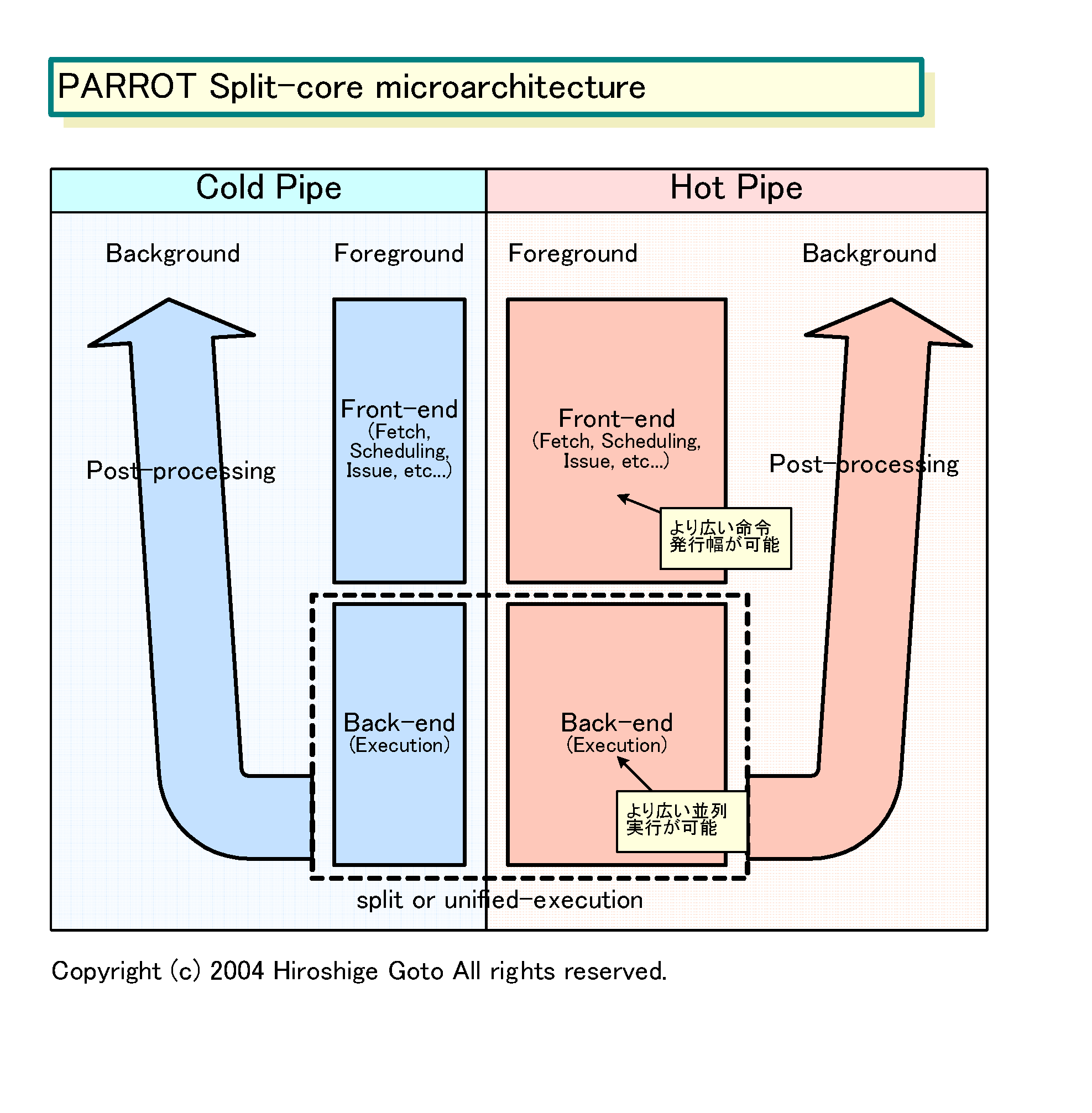
PARROTではこのホットコードを、CPUハードウェアで最適化する。効率のいい最適化のために、トレースキャッシュと分離されたパイプライン、バックグラウンドでのコード最適化といった手法を使う。CPUのマイクロアーキテクチャ全体を、ホットコードの最適化に合わせて構築するわけだ。PARROTでは、まず、パイプラインをコールドパイプとホットパイプに分けてしまう。コードルパイプが従来のCPUのパイプライン、ホットパイプがPARROTで新設されたパイプラインとなる。このパイプラインの切り分けが、PARROTの大きな特徴だ。
概念的には、下の図のようになる。コールドパイプとホットパイプは、並列して動作し、それぞれ実行パイプラインのフロントエンドとバックエンドを持つ。フロントエンドでは、命令スケジューリングや命令発行などを行なう。バックエンドの実行エンジンが、発行された命令を実行する。
ただし、両パイプはそれぞれの用途に合わせてチューンされている。Gelsinger氏が説明したように、ホットパイプによりCPUリソースを割いて高パフォーマンスにすると、非対称のパイプとなる。シングルパイプよりホットパイプの方が、命令の並列度も高くなるため、より多くの命令発行が可能になる。そのため、ホットパイプの方の帯域を広げることが可能になる。
実際の実装では、バックグラウンドの実行ユニット群は両パイプで共有される可能性がある。共有実行コアの方が、ダイサイズ(半導体本体の面積)を縮小できるからだ。しかし、パイプラインのうちのフロントエンド(フェッチやスケジューリングなどの部分)は完全に分離されることになる。
また、両パイプは従来のフォアグラウンドの実行パイプライン以外に、バックグランドのパイプを持つ。コールドパイプでは、バックグラウンドフェイズで実行済みのコードの中から頻繁に使われる部分を抜き出して、それをホットパイプに送る。一方、ホットパイプのバックグラウンドフェイズでは、実行済みのコードの中から、もっとも頻繁に使われるコードを見つけて、さらに最適化を施す。つまり、頻繁に使うコードの選択と最適化は、実行パイプラインのバックグランドで処理され、実行パイプの処理を阻たげない。
 |
| コールドパイプとホットパイプ PDF版はこちら |
●トレースキャッシュを中心に構築
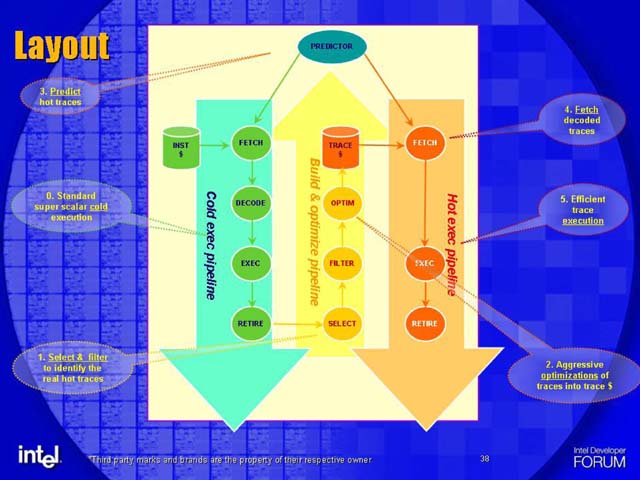
PARROTではトレースキャッシュをベースにホットパイプを構築している。トレースキャッシュは、Pentium 4でも採用されている命令キャッシュ方式で、プログラムの中の実際に使われるコードのトレース(実行されるパス)にそって命令をキャッシュする。プログラムの命令順序に従ってキャッシュする従来の命令キャッシュよりも効率がいい。Pentium 4では、IA-32コードではなく、いったんデコードした内部命令(μOPs)をトレースキャッシュに格納していたが、PARROTでも同様にμOPsをトレースキャッシュに格納する。つまり、トレースキャッシュにヒットする限り、命令の再デコードは必要がない。また、可変長のIA-32命令ではなく、固定長のμOPsをキャッシュするため、キャッシュからのフェッチやデコードも容易になる。
PARROTでは、コールドパイプは単純な命令キャッシュ、ホットパイプはトレースキャッシュと2つのキャッシュを使い分ける。コールドコードについてはトレースを選択する手間を省く。逆に、ホットコードについてはPentium 4よりもずっとスマートなトレース選択機構によって、より効率のいいトレースキャッシュを実現するようだ。ちなみに、キャッシュが分離されるため、分岐予測機構も、コールドの分岐予測と、ホットのトレース予測に分離される。
トレースキャッシュによって、PARROTではμOPsへのデコードとコードのトレースを再利用できる。キャッシュ効率の向上とデコーダの負担を減らすことで、消費電力を下げることができる。ホットパイプで最適化した場合も、並べ替えた命令順序や命令変換の結果などをトレースとしてキャッシュする。つまり、トレースキャッシュは、最適化の結果をキャッシュする役目も果たす。
 |
| PARROTのパイプラインコンセプト PDF版はこちら |
 |
| IDF044FallでのPARROTのプレゼンテーション |
●トレース選択
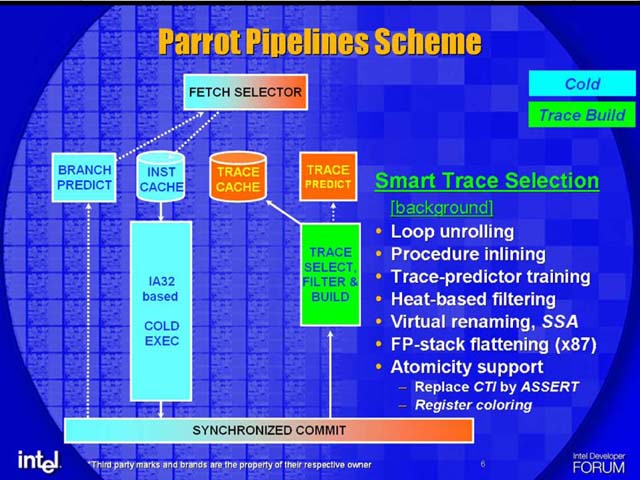
コールドパイプのバックグラウンドでは、トレースの選択とフィルタリング機構が働き、ホットコードを選別する。トレース構築は、PARROTでは非常に重要だ。というのは、PARROTでのコード最適化はトレースの中で行なうため、より大きなトレースを構築できれば、潜在的に最適化の幅が広がるからだ。トレースの最小単位は、分岐命令などコントロールトランスファー系命令(CTI)で終わるシーケンスであるベーシックブロックだが、PARROTではベーシックブロックを超えたトレースを構築する。トレースは最大64μOPsとされている。ちなみに、同じようなトレース構築をソフトウェアで行なうTransmetaのコードモーフィングソフトウェア(CMS:Code Morphing Software)は、Efficeonの場合で最大100命令のトレースを構築する。PARROTはそれに近い。
IntelがSmart Trace Selectionと呼ぶこのフェイズでは、次のような処理を行なう。
・ループアンローリング(Loop unrolling)
・プロシージャインライニング(Procedure inlining)
・バーチャルリネーミング(Virtual renaming, SSA)
・浮動小数点スタックフラッタリング(FP-stack flattening)
・CTI命令のASSERT命令への置き換え(Replace CTI by ASSERT)
 |
| PARROTのパイプラインスキム |
トレースセレクタ/フィルタ/ビルダで構築されたトレースはトレースキャッシュに格納される。次にそのコード部分が実行される時は、トレースキャッシュからフェッチされホットパイプで実行されることになる。そして、同じトレースが頻繁に使われる場合には、トレースオプティマイザが、そのトレースに対してさらにアグレッシブな最適化をバックグラウンドでかける。
オプティマイザは、汎用の最適化とCPUコアに特化した最適化の両方を行なう。以下の最適化が挙げられている。
・ロジックと演算の簡素化(Logic, arithmetic simplifications)
・値、レジスタ、コンディションなどの伝搬(Propagation of values, registers, conditions)
・デッドコードエリミネーション(Dead code elimination)
・マイクロオプスフュージョン(μOPs fusion)
・複数の非SIMD命令のSIMD命令化(SIMDification)
・μOPsのスケジューリング(Semi-dynamic scheduling)
 |
| 最適化されたPARROTのパイプラインスキム |
最適化によって、CPUコアが実行するμOPsを減らし、命令間の依存性を解消し、リネーミングを単純化し、スケジューリングを向上させる。それによって、演算ユニット、スケジューラ、レジスタなどの使用を減らし、メモリアクセスの回数を減らす。リソースの使用を減らすわけで、そのため、性能を向上させながらも、消費電力の軽減が可能になる。
では、PARROTアーキテクチャでどれだけの効率化が図れるのだろう。また、PARROTが採用されるとしたら、どの世代のCPUになるのだろう。次のレポートでは、そのあたりを説明したい。
□関連記事
【11月5日】【海外】ポラックの法則を破るためのマルチコア
http://pc.watch.impress.co.jp/docs/2004/1105/kaigai131.htm
【10月30日】【海外】3ステップでマルチコア化を進めるIntelのサーバー&ワークステーション系CPU
http://pc.watch.impress.co.jp/docs/2004/1030/kaigai130.htm
【10月22日】【海外】デュアルコアCPU“Smithfield”は来年第3四半期に登場
http://pc.watch.impress.co.jp/docs/2004/1022/kaigai128.htm
【6月9日】【海外】AMDが2005年にデュアルコアCPUを投入
http://pc.watch.impress.co.jp/docs/2004/0609/kaigai095.htm
(2004年11月8日)
[Reported by 後藤 弘茂(Hiroshige Goto)]
【PC Watchホームページ】
PC Watch編集部 pc-watch-info@impress.co.jp 個別にご回答することはいたしかねます。
Copyright ©2004 Impress Corporation, an Impress Group company. All rights reserved.