 |


■後藤弘茂のWeekly海外ニュース■NVIDIAがデュアルGPUソリューション「NVIDIA SLI」を発表 |
●PCI Expressカードを2枚接続してデュアル構成に
 |
| Quadro FX 3400をSLI化したイメージ |
NVIDIAは、複数のグラフィックスカードを接続して、マルチGPU構成にできるアーキテクチャ「NVIDIA SLI(Scalable Link Interface)」を発表した。
PCI Express対応のハイエンドGeForceシリーズとQuadroシリーズで対応(最初はGeForce 6800 Ultra、GeForce 6800 GT、Quadro FX 3400)。今年中に登場する、SLI対応のPCI Expressカードを複数接続することで、マルチ構成ができるようにする。
SLIへの対応は、ハードウェア的にはカードの上部に、もう1枚のカードとの接続用のコネクタをつけるだけだ。具体的には、マザーボードに挿した2枚のPCI Expressグラフィックスカードの上部のコネクタ同士を、ブリッジコネクタで接続することでデュアルGPU化する。
NVIDIA SLIでは、GPU同士の接続に専用インターフェイスを使うが、インターフェイス自体はGPUに内蔵している。そのため、ボードでの対応は、機械的にはコネクタ部分とそこへの配線だけで済む。NVIDIAでは、ハイエンドPCI ExpressカードのリファレンスデザインにSLIのサポートを含めているという。つまり、原則的にはほとんどのベンダーが対応し、どのカードもデュアル化が可能になることになる。
 |
 |
| マザーボード搭載時のイメージ | |
ただし、NVIDIAのホームページでは、SLIの組み合わせで同社がサポートするのは、同じベンダーの同じモデルのカードに限るとしている。つまり、異なるベンダーや異なるコンフィギュレーションのカードのデュアル化はサポートしない。
もっとも、NVIDIAのDavid B. Kirk(デビッド・B・カーク)氏(Chief Scientist)は、技術的には異なるコンフィギュレーションでもSLIでのデュアル化が可能だと説明していた。つまり、同ベンダーの同モデルという縛りは、NVIDIAの保証の範囲ということで、技術上の制約ではない。
NVIDIAの今回のソリューションは、ネーミングといいデュアルカードという構成といい、一見、3Dfx InteractiveのVooDoo SLIのリバイバルのように見える。しかし、NVIDIAは大きく違うと主張する。
NVIDIAが指摘するのは、まず、広帯域で双方向のPCI Expressによって、複数のGPUに必要な帯域をバスが供給できるようになったこと。「AGPでは複数デバイスを接続するには帯域が狭すぎた。しかし、PCI Express x16では必要な帯域が確保できた」、「そもそもAGPは、スペック上複数デバイスの接続を許可していなかった。しかし、PCI Express規格では、同一チャネル上に複数デバイスを接続できる。だから、2 GPUを論理上問題なく配置できる」とKirk氏は説明する。
アーキテクチャ的にも変わった。NVIDIA SLIでは、デュアルGPUにした場合には片方がマスターGPU、もう片方がスレーブGPUとなり、マスターGPUが画面をコンポーズしてスキャンアウトする。3DfxのSLIのような、スキャンラインのインタリービングは行なわない。
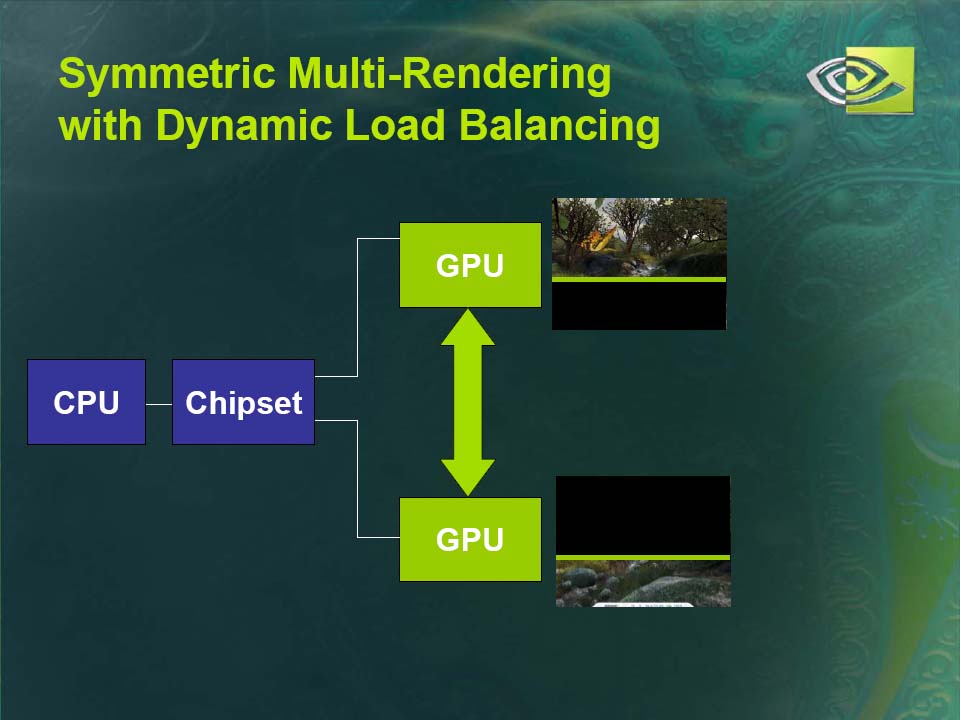
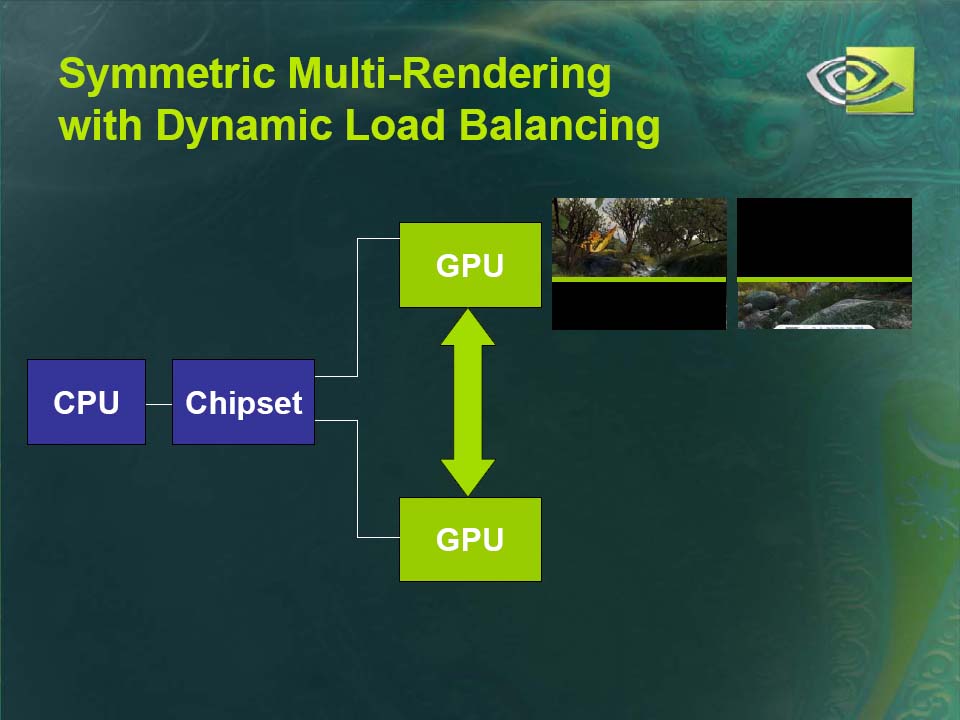
例えば、1フレーム毎に2つのGPUが異なるフレームをレンダリングする、フレームベースのインタリービングを行なうなど、フレキシブルに2個のGPUに処理を分散させることができる。ソフトウェアがGPU間のロードバランシングを行なう仕組みになっている。
 |
 |
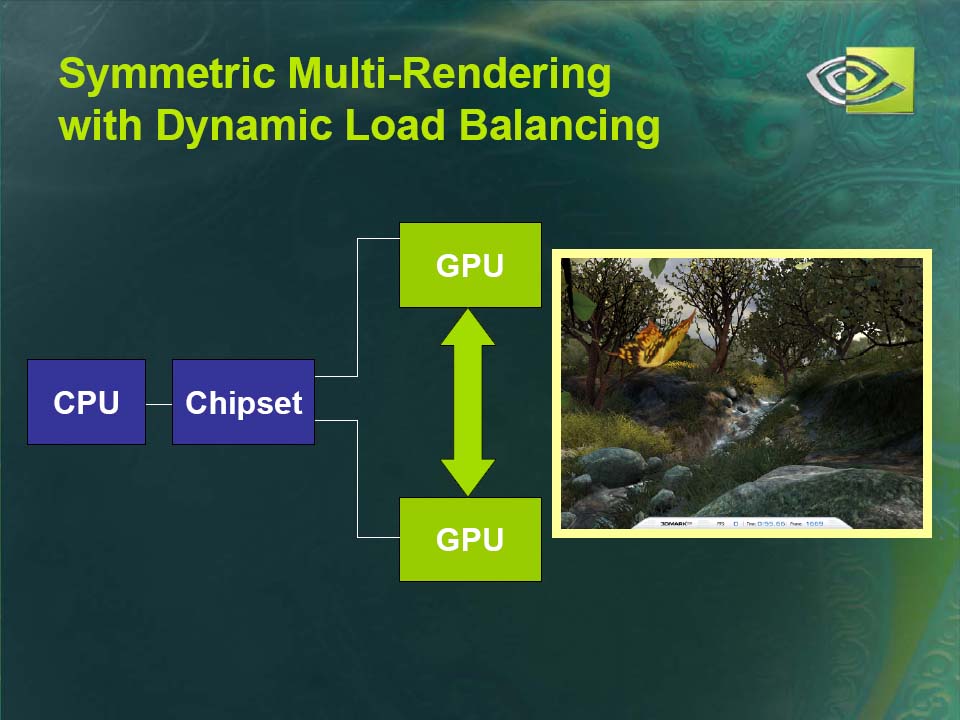 |
| SLI利用時のGPU間ロードバランシングの仕組み | ||
さらに、NVIDIA SLIでは、GPU同士を専用の広帯域ポートで接続することで、GPU間のデータ転送を高速化している。NVIDIAはそのために、専用インターフェイスをGPUに内蔵した。このインターフェイスが、カード上部に設置されるマルチGPU接続用のコネクタに配線される。そして、カードのコネクタに、専用のブリッジ型のコネクタを接続することで、GPU間で高速データ転送ができるようにする。PCI Express側の接続を使うことなく、GPU同士で通信できるため、PCI Expressの帯域を無駄に消費しないというわけだ。
GPU同士を専用ポートで接続する点は、XGIの「Volari」シリーズと同様だ。Volariの専用インターフェイス「BitFluent」は、32bit幅、133MHz駆動、4bit/クロックで、最大2.13GB/secとAGP 8Xと同等の帯域だった。しかし、実際には2.13GB/secでも、ケースによっては帯域は不足し、性能は大幅に削がれた。
GPUに詳しいライターの西川善司氏によると、Volariのアプローチでは「リアルタイムエンバイロメントマッピングのように大容量の共有テクスチャの書き換えが頻繁に生じる場合には、帯域が共有データの転送で食われて性能が出ない」と指摘する。それに対してKirk氏は次のように答える。
「それはありえる。アプリケーションによっては(デュアルGPUで)2倍の性能を達成できるが、そうでないアプリケーションもあるだろう。どれだけ(データを)共有するかで決まってくる」、「しかし、我々のソリューションではボトルネックは少ない。これまでの(デュアルGPU)ソリューションはAGPだったが、我々はPCI Expressの広帯域を利用できる」、「(GPU間の接続でも)我々は十分な帯域を提供する。我々のSLIでは、論理的には、少なくともPCI Expressより速くなければならない」
NVIDIAは、同社のSLIソリューションで平均1.87倍(3DMark03 @16x12 4x/8x (GT2、3、4)、Unreal Engine3 @10x7)のパフォーマンスアップが実現できると主張する。まず、ホストとのデータ転送がPCI Expressにより2~4倍へと高速化。さらに、Volariと比べるとチップ間のデータ転送を高速にしてボトルネックを排除するというわけだ。そして、アプリケーション側が、データ共有量が少ないものなら性能を発揮できる。
 |
 |
 |
| SLI用のブリッジ型コネクタ | カード上部にマルチGPU接続用コネクタを装備 | GPU(NV40)に内蔵されたSLI用インターフェイス |
長い目で見ると、マルチGPUは、ハイエンドグラフィックスでは、理にかなったソリューションだ。というのは、グラフィックス処理は原理的には並列性が高く、論理的に考えればマルチプロセッサ構成にして並列化することが容易だからだ。実際、業務向けのハイエンドグラフィックスコンピュータシステムでは、グラフィックス用プロセッサをマルチ構成にするのは普通だった。
しかし、PCベースのシステムでマルチGPUを実現するには課題がいくつもあった。最大の問題は、バスとトポロジで、FSB(フロントサイドバス)の帯域をぐいぐい引き上げることができるCPUと異なり、GPUはこれまでAGPの呪縛に縛られていた。同じ理由で、トポロジ的には相互メモリアクセスにネックがあるなどの問題があった。グラフィックス処理はメモリへの圧迫が強いため、これは大きな問題になる。こうしたハードルのために、これまでPCではマルチGPU構成は、コストに見合う性能を発揮できないケースが多かった。
NVIDIAの方向は、PCI Expressへの移行を機に、こうした問題を解決してマルチGPU構成への道を開こうというものだ。また、そこには、GPUの処理のうち、データフローとコンピューティングパワーのバランスでは、シェーダのコンピューティングの方が重くなりつつあるという背景もある。シェーダプログラムは当然メモリアクセスも要求するのだが、比重としてコンピューティングパワーの方がより要求されるようになる。そうすると、GPUのプロセッシングパワーを容易に増やすことができるマルチGPUは理にかなった方法となってくる。
つまり、PCI Expressとシェーダセントリックへのアーキテクチャ変更が重なったからこそ、マルチGPUへの好機になったというのがNVIDIAの判断だと思われる。NVIDIAは過去数年間、マルチGPUソリューションを検討していたという。「GeForce FXでもじつはハードウェア的にはサポートしているが、そうした製品は作らなかった」、「PCI Expressで、初めて現実的になったと考えている」とKirk氏は言う。
●PCI Express x16“スロット”が2基必要
 |
| PCI Express x16スロットは2つ必要だがx16インターフェイスは1つで対応可能 |
NVIDIA SLIでは、現在の説明では、2枚のPCI Expressグラフィックスカードを2つのPCI Expressスロットに挿す。つまり、原則的には“PCI Express x16スロット”が2つあるマザーボードが必要となる。じつは、この点が一番のハードルだ。ただし、PCI Express x16インターフェイスが2つある必要はない。
「PCI Expressの構成はマザーボードによって異なる。中には、多くのPCI Expressチャネルを持つマザーボードもある。例えば、PCI Expressが合計20レーンなら、マスター(のグラフィックスカード)をPCI Express x16に挿し、もう1枚はPCI Express x4に挿すことができる」とKirk氏は説明する。
つまり、物理的(&電力的)にはPCI Express x16スロット2基が必要だが、信号的にはPCI Express x16は1つで、あとはx8やx4ですむ。GPU間のデータ転送にはこのPCI Expressスロットは使わないため、帯域が狭くても問題は生じない。ただし、NVIDIA側は今のところはx4までしか言及しておらず、x1には言及していない。
ちなみに、現状では、IntelのデスクトップチップセットではPCI ExpressはMCH側に16レーン、ICH側に4レーンの構成となっている。そのため、周辺デバイス用にPCI Express x1コネクタを用意すると、x4ですら用意できない。
しかし、Intelが本日発表したチップセット「Intel E7525(Tumwater:タムウォータ)」や「Intel E7520(Lindenhurst:リンデンハースト)」になると、ノース側にコンフィギュラブルな24レーンを備えている。そのため、例えばE7525なら、PCI Express x16にプラスしてPCI Express x8を確保できる。NVIDIAが、Intelのサーバー&ワークステーション用チップセットと同時にSLIを発表した理由は、このあたりになりそうだ。
●SLIはGPUサーバーへの布石の1つ
マルチGPUソリューションを投入するNVIDIAの目的は? それはコンシューマやワークステーションといった分野のためだけではない。大きな目的のひとつはGPUサーバーだ。
GPUサーバーは、1~2個のCPUと複数個のGPUを搭載し、GPU上でオフラインレンダリングや科学技術演算を行なうシステム。NVIDIAは以前からこうしたGPUサーバーの実現にも取り組んで来た。Pixel Shaderの内部演算精度を32bitに引き上げた理由のひとつはそれだった。
従来CPUで行なってきたオフラインレンダリングや科学技術演算をGPUに移すには、CPUと同レベルの32bit精度が必要だったからだ。NVIDIAは、実際にレンダーファーム(映画用のレンダリングを行なうサーバーを多数備えたスタジオ)や科学技術演算コミュニティとも接触を持ってきた。
また、NVIDIAが最初に計画していたPCI Express版nForceは、PCI Expressブリッジチップが独立した構造で、明らかに複数個のGPUの接続を意識したものだった。
そして、今回のNVIDIA SLIのソリューションなら、NVIDIAはマルチGPUサーバーを比較的低コストに作ることができる。GPUサーバーに搭載する複数のGPUを、全てPCI Express x16に接続する必要がなくなるからだ。NVIDIAのKirk氏も、SLIがGPUサーバーにも有効だと認める。演算中心のアプリケーションでは効力を発揮するというSLIの特長も、GPUサーバーに合っている。
GPUサーバーでは、デュアルGPUだけでなく、もっと多数のGPUを搭載する構成が想定されている。SLI自体、デュアルGPUのための技術ではなくもっと多数のマルチGPU構成もサポートしている。「アーキテクチャ的には最大8個までのGPUをサポートできる。そうしたシステムが登場するかどうかは断言できないが、技術的には可能だ」とKirk氏は語る。
確かに、いきなり8個のGPUをSLIで接続するとは思えない。おそらく、最初に登場するGPUサーバーは、2~4個程度のGPUを搭載したものになるだろう。それをクラスタ接続すれば、大規模な構成も可能になる。
「我々は、映画レンダリングの世界では、マルチGPUサーバーが登場すると予想している」、「人によっては、単なるマルチGPUシステムだけではなく、プロフェッショナル向けのビジュアライゼーションシステム向けにクラスタシステムを望むだろう」とKirk氏は言う。
NVIDIAは、汎用GPUへのステップを、また1つ進めたことになる。
□関連記事【6月24日】【海外】GPU戦争の次のフェイズは“NV48対R480”
http://pc.watch.impress.co.jp/docs/2004/0624/kaigai097.htm
(2004年6月29日)
[Reported by 後藤 弘茂(Hiroshige Goto)]
【PC Watchホームページ】
PC Watch編集部 pc-watch-info@impress.co.jp 個別にご回答することはいたしかねます。
Copyright (c) 2004 Impress Corporation All rights reserved.