 |


■後藤弘茂のWeekly海外ニュース■NVIDIA GeForce 6800(NV40)のウイークポイント |
●300平方mmの超巨大なダイサイズ
現時点では最高パフォーマンスを誇るNVIDIAの「GeForce FX 6800(NV40)」。しかし、NV40の高いパフォーマンスには大きなトレードオフがある。それは2億2,200万という膨大なトランジスタ数と、巨大なダイサイズ(半導体本体の面積)だ。
NVIDIAは今回、NV40のパッケージとウェハの写真を公開した。NV40のパッケージは40mm角なので、フリップチップ実装されているダイのサイズは計算できる。現在のところダイサイズは約18.5mm×約16.5mmで約300平方mmと推定される。これは、300mmウェハと見られるウェハの写真から計算できるダイサイズともほぼ一致する。
 |
 |
| NV40のパッケージ(左)とウェハ | |
また、2億2,200万という数字と0.13μmという製造プロセスを考えても、その程度のダイサイズは不思議はない。そのため、NV40が300平方mm前後のダイであるのは、ほぼ間違いないと思われる。ちなみに、NV40はIBMの0.13μmプロセスを使っている。
NV40のダイ(半導体本体)を従来のGPUと比べると、いかに巨大かがわかる。例えば、前世代のGeForce FX 5800/59x0(NV30/35)系列ではダイは約198.7平方mmだったので、NV40が300平方mmだとすると1.5倍にダイが増えたことになる。ATIのR300/350系列も約200平方mmちょっとなので、それに対してもNV40は1.5倍のサイズとなる。
CPUと比較してもNV40は巨大だ。例えば、初代Pentium 4(Willamette:ウイラメット)は217平方mmなので、NV40の方がはるかに大きい。つまり、NV40のダイサイズは、デスクトップCPUのサイズではなく、サーバー&ワークステーション向けCPUの大きさだ。
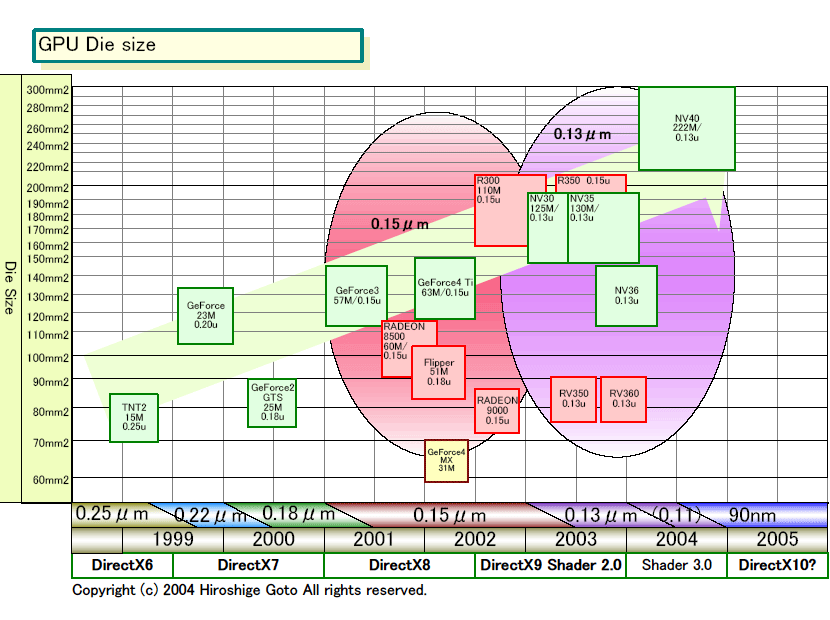 |
| ダイサイズ推定図 PDF版はこちら |
トランジスタ数では2億2,200万は、GeForce FX 5900(NV35)の1億3千万から70%増。NVIDIAのDavid B. Kirk氏(Chief Scientist)は、以前のインタビューで次世代アーキテクチャでは2億トランジスタに達すると示唆していたが、その通りだった。これをCPUと比べると、90nm版Pentium 4(Prescott:プレスコット)の1億2,500万がようやくNV30/35相当。つまり、CPUと比べると1世代分トランジスタ数が多いことになる。しかも、CPUは大容量のキャッシュを搭載しての数字。CPUと比べるとGPUはキャッシュが少ない(増えつつはある)ので、ロジック部分のトランジスタ数ならさらに差が開くことになる。
トランジスタ規模&ダイサイズでは、NV40は、おそらくワンチップでは最大のコンシューマ向けGPUだろう。もっとも、NV40をコンシューマ向けと呼んでいいのかどうかという点から疑問は残る。それは、巨大ダイと膨大なトランジスタによって、様々な問題が発生するからだ。
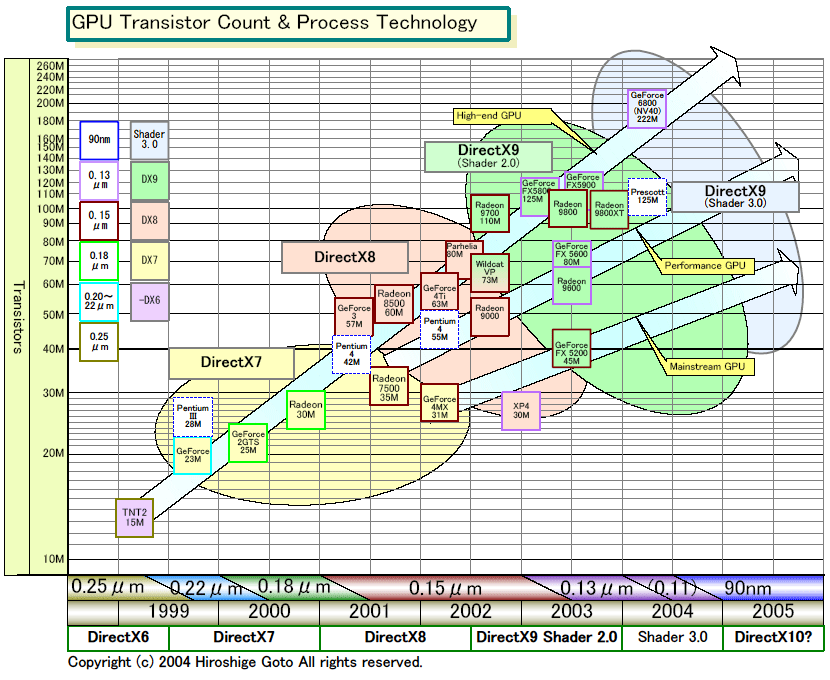 |
| トランジスタ数推定図 PDF版はこちら |
●ホットなNV40が問題に
GPUのトランジスタ数とダイサイズが大きくなると、(1)発熱量と消費電力が大きくなる、(2)製造コストが上がる。(3)設計上の難度が高くなる。(4)同アーキテクチャの下位バージョンGPUのコストや発熱量も大きくなる。といった問題が生じる。
NV40の消費電力は、リファレンスカードの外部電力入力が2系統になっていることでわかる通り非常に大きい。NVIDIAは消費電力やTDPを公開していないが、半導体規模を考えるとPrescott並かそれ以上と推定される。だから、GeForce FX 6800 Ultraでは、電源に500Wクラスが必要になってしまうわけだ。
電力消費の増加分、発熱量も増えるため、NV40ではより高効率の冷却機構が必要になる。特にこれがクリティカルなのは、90nm版Pentium 4(Prescott:プレスコット)になってPC筺体内の温度のスペック(Ta)が38度Cにまで下げられたことだ。これはプロセッサ温度との差を広げることで、サーマルバジェット(廃熱機構に要求される熱抵抗値)を稼ぐためだ。つまり、CPUも含めて能力をフルに発揮できるようにするには、NV40を冷却して、なおかつ筺体内の温度が38度以下になるようにしなければならない。
この問題がさらにクリティカルなのは、従来のようにプロセス技術の移行で解決できないことだ。現在ではプロセスが微細化しても消費電力があまり下がらない。原因は2つある。(1)チップの駆動電圧のスケールダウンの比率が下がっていること。(2)リーク電流が増大し続けていること。
そのため、同アーキテクチャで微細化すれば消費電力が下がるという、従来のパターンは、今後はそれほど期待ができない。例えば、今年末か来年にNV4x系の90nmプロセス版GPUが出てきても、多少は低消費電力化は期待できるが、以前ほど劇的には消費電力は減らない。
この問題は、少なくとも90nmプロセス世代では根本的に解決されない。High-kゲート絶縁膜やトランジスタ構造の改革が必要だからだ。NVIDIAがNV40を生産委託しているIBMでも、NVIDIAが使っているもうひとつのファウンドリTSMCでも事情は同様だと思われる。つまり、今後数年は、GPUは電力=熱との戦いに苦しむことになる。
もっとも、こうした半導体技術側の事情を考えると、GPU内部の並列処理度を高めること自体は間違えた方向ではない。GPUを高周波数化して性能を上げるよりも、処理を並列化して周波数は抑えて性能を上げた方が、消費電力と熱の観点からすると有利だからだ。
Intelも、まさにそのためにモバイルCPU「Yonah(ヨナ)」でデュアルコアを採用する。その意味では、パイプライン構成を広げるのは、間違えた方向ではない。問題は、それが行き過ぎているから、消費電力がPCに適切な枠を超えてしまっているところにある。つまり、熱設計の観点からは2004年のGPUは8パイプ程度が適切なのに、16パイプへ広げてしまったというわけだ。
●疑問が残るNVIDIAの高コスト体質
製造コストも問題だ。GPUの製造コストは、1枚のウェハから生産できるチップ個数で大きく左右される。ダイが大きくなればなるほどウェハ上に配置できるチップ数が減り、歩留まりも悪くなる。つまり、1チップあたりの製造コストが跳ね上がることになる。原理的にはNV40はNV30/35/38といった従来のNVIDIAハイエンドチップよりも製造コストがかなり高いはずだ。
そのため、NVIDIAが戦略的な価格でGeForce FX 6800を提供したとしても、その場合はNVIDIAのマージンが圧縮されてしまう。結果、NVIDIAはあまり大量には製品を出さない可能性もある。実際、NVIDIAはNV30(GeForce FX 5800)の時はあまり出さないうちに、NV35(GeForce FX 5900)へと切り替えた。
また、現在、GPUベンダーはフラッグシップモデルから機能を削ってパフォーマンスモデルとメインストリーム/バリューモデルを作っている。NVIDIAも今回のNV40に続いて、パフォーマンス版GPUとメインストリーム版GPUを計画している。問題は、これら廉価GPUも、同アーキテクチャで揃える限り、やはり比較的ダイサイズが大きくなってしまうことだ。
もしパフォーマンス8パイプ、メインストリーム4パイプの構成にするのなら、どちらも、パフォーマンスGPUやメインストリームGPUとしては、ダイが大きくなってしまうだろう。一方、パフォーマンス4パイプ、メインストリーム2パイプの構成にするのなら、性能的に競争上不利になってしまう。どちらに転んでも不利だ。
実際にはGPUの主戦場は、パフォーマンスとメインストリーム/バリュークラス。そこでコスト面または性能面で不利になるのは、NVIDIAにとっていい話ではない。特に、物理設計面で、NVIDIAよりも優れるATIを相手にすることを考えた場合、これは問題だ。同じランクのGPUで、今回もまた、NVIDIAの方がATIよりも製造コストが高くなってしまう可能性がある。
さらに問題なのは、NV40の熱・消費電力が大きいと、その下のクラスのパフォーマンスGPUとメインストリーム/バリューGPUでも消費電力と発熱が大きくなってしまうことだ。PCのデジタルホーム化が進むという前提で考えると、今後は静音化が重要な要素になる。発熱量が増えることは、静音化では明確に不利になる。特に、PCベンダーはファンレスGPUを求めるため、下位のクラスのGPUでは熱は大きな問題になる。そして、熱の問題は、モバイルへの展開ではさらに重要となる。
また、一般にチップのロジック部分が大きくなればなるほど、バグが増える。クリティカルパスの最適化などにも、余計時間がかかるようになるという。その分、デバッグに時間がかかるようになる。つまり、開発上でのリスクがますます増える。
こうしてみると、NV40は、言ってみれば、レギュレーションを無視して排気量の巨大なエンジンを積んでレースに出るようなものであることがわかる。NV40には他にもいくつかの弱点があるが、このトランジスタ数とダイサイズの問題は、もっとも重大だ。
●トランジスタ投資と得られる絵の関係
性能向上のためにトランジスタ数とダイをどんどん肥大化させているNVIDIA GPU。そこには、現在のGPUの根本的な問題も見える。それは、トランジスタを増やすことと、それによって得られる効果のバランスが取れていないように見えることだ。
あるゲーム機向けチップの開発者は「今のGPUの問題は、トランジスタ数を倍増させて機能を増やしても、それによって得られる絵自体が、それ(トランジスタ数)に見合うほど進歩しないことにある」と指摘する。
つまり、3Dグラフィックスが一定レベルのしきい値を超えてしまったため、トランジスタを70%増やしても、普通のユーザーが70%も進歩したとは思ってくれないわけだ。ここ数年のプログラマブルGPUの進化は、CG技術者側から見ると長足の進歩なのだが、外側から見ると、投入したトランジスタに見合うだけの進歩が見えにくい。確かに、ずっと発展したグラフィックスを実現はできるが、コスト面からそれが妥当なのかどうか、難しいところだ。
これと全く同じ話は、CPUでもこの5~6年語られてきた。例えば、Intelでは、CPUの性能は増えたダイサイズの平方根分しか向上しないという法則(ポラックの法則)があると指摘している。それと同じフェイズに、GPUも突入したのかもしれない。
また、絵を美しくするにはGPUのプログラム性を高めなければならない段階に3Dグラフィックスが突入したことも大きく影響していると思われる。プログラマブルハードウェアの効率は、固定ハードウェアよりも低い。そのプログラマブルユニットを怒濤のように増やしているのが現在のGPUの姿だ。
いかにプログラマブルハードウェアを効率化するか。GPUもCPUと同じ問題にぶちあたりつつある。
□関連記事
【4月16日】「GeForce 6800はNVIDIA史上最大の性能向上」
~NVIDIA担当マネージャがGeForce 6の技術を解説
http://pc.watch.impress.co.jp/docs/2004/0416/nvidia.htm
【4月15日】【海外】NVIDIAが16パイプラインの強力GPU「GeForce 6800(NV40)」を発表
http://pc.watch.impress.co.jp/docs/2004/0415/kaigai083.htm
【4月15日】NVIDIA、GeForce 6シリーズを発表
http://pc.watch.impress.co.jp/docs/2004/0415/nvidia.htm
(2004年4月21日)
[Reported by 後藤 弘茂(Hiroshige Goto)]
【PC Watchホームページ】
PC Watch編集部 pc-watch-info@impress.co.jp 個別にご回答することはいたしかねます。
Copyright (c) 2004 Impress Corporation All rights reserved.