 |


■後藤弘茂のWeekly海外ニュース■NVIDIAが16パイプラインの強力GPU「GeForce 6800(NV40)」を発表 |
●16本のフル機能ピクセルパイプラインを搭載
 |
| GeForce 6800 Ultra リファレンスカード |
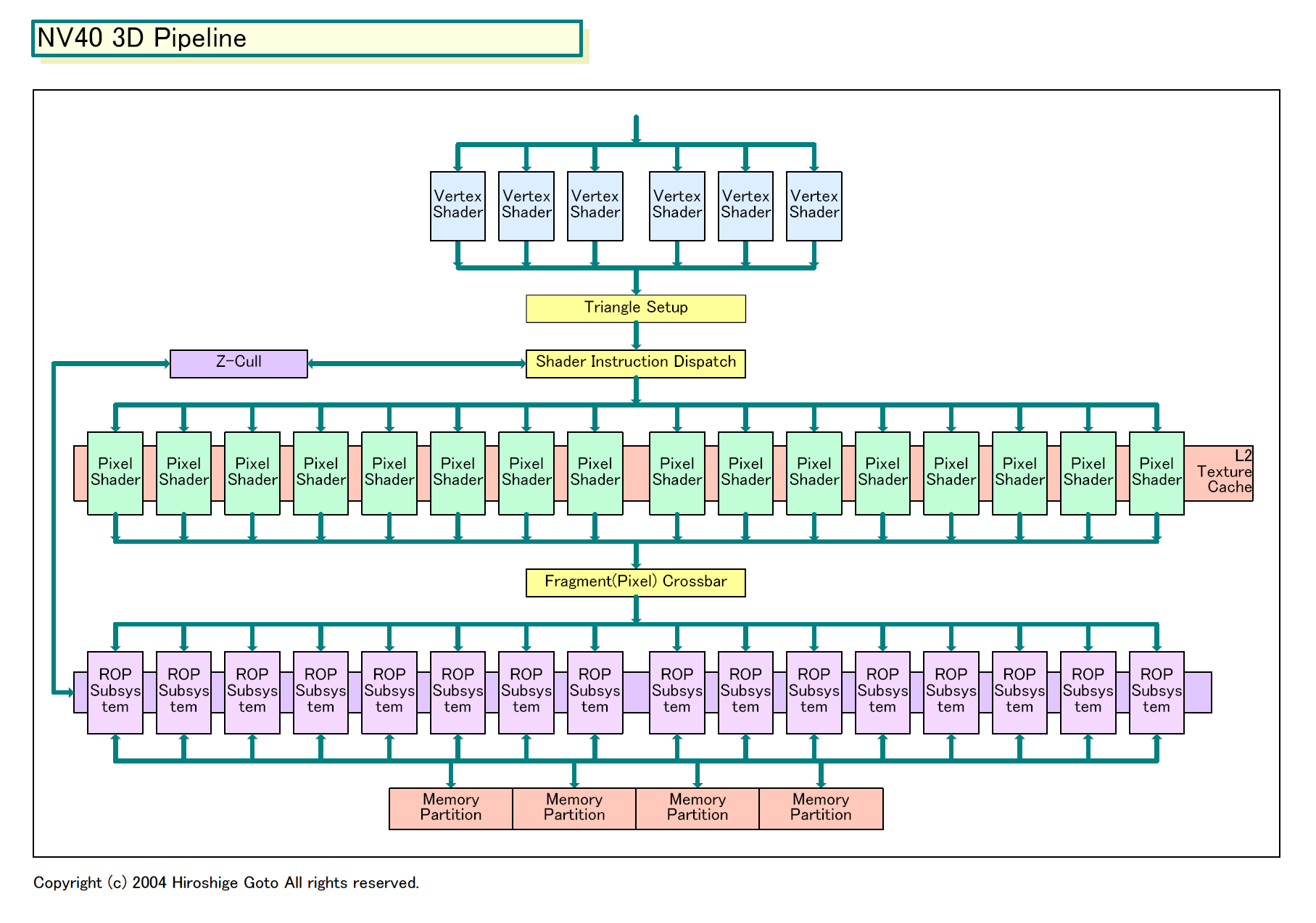
NVIDIAの次世代GPU「NV40」=「GeForce 6800」がいよいよ姿を現した。GeForce FX(NV3x)ファミリから、内部アーキテクチャは完全に一新。2億2,200万トランジスタ、DDR3メモリ(1.1Gtps)、“トゥルー”16ピクセルパイプライン(6Vertex Shader/ 16Pixel Shader)、16x1/32x0(16パイプ1テクスチャ/32パイプ)構成、DirectX 9 Programmable Shader 3.0、MPEGエンコード、FPテクスチャ/フレームバッファサポートというスペックだ。
つまり、簡単に言うと、NV40は、これまでNV3x系の弱点と言われていた部分をほぼ全部改良し、なおかつShader 3.0に先んじて対応し、ピクセルパイプはライバルの現行GPUの2倍に増やしたわけだ。その結果できあがったのは、旧来的な数え方で言えば16パイプというモンスターGPUだ。まさに、ブルートフォース(力業)NVIDIAの面目躍如といったところだ。
まず、全体の構成を見るとVertex Shaderが6、Pixel Shaderが16とNV40は極端にPixel Shader側の構成の方がリッチになっている。つまり、機能拡張のためのリソースの大半はピクセル側につぎ込んだことになる。3Dグラフィックスのトレンドとしては、Pixel Shaderで走らせるシェーダプログラムの方がどんどん複雑になりつつあるので、Pixel Shader側へと偏重すること自体はおかしくはない。ただし、構成のバランスについては、実際のアプリケーション性能が出てこないとわからない。
 |
 |
| GeForce 6800 Ultra | GeForce 6800 Ultraのダイ |
 |
|
| NV40 3D Pipeline Block図 PDF版はこちら |
|
 |
 |
| DirectX 9.0cフルサポート | GeForce 6800の概要 |
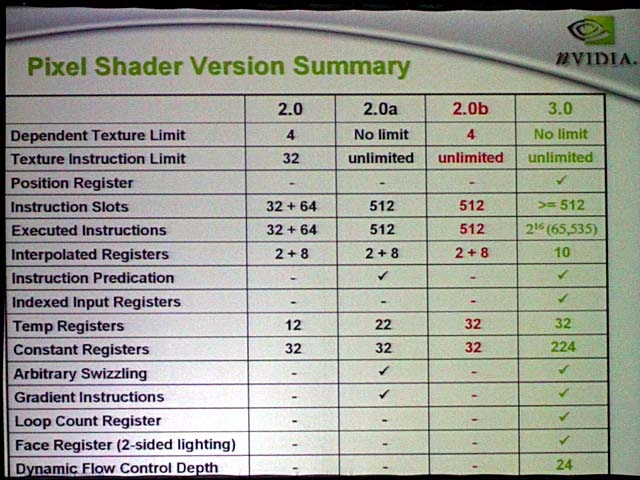
●Shader 3.0に対応したVertex Shader
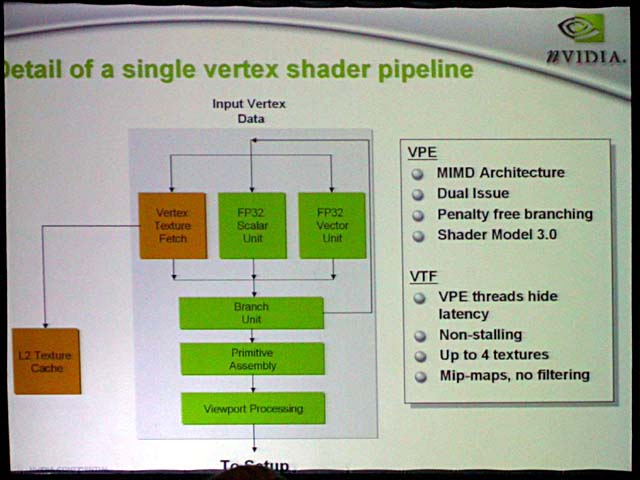
Vertex Shaderは6ユニット。構成で目立つのは(1)頂点テクスチャフェッチ(Vertex Texture Fetch)ユニットが入ったこと、(2)ベクタユニットとスカラユニットが並列化されていること、(3)独立したブランチユニットを備えるように見えること、など。
テクスチャフェッチユニットが備えられたのは、NV40がDirectX 9のProgram Shader 3.0に対応したからだ。Shader 3.0の目玉は、Vertex Shaderにテクスチャアクセス機能が加わることと、Pixel Shaderにフローコントロール系命令が加わること。そのため、NV40は必然的にVertex Shader内にテクスチャフェッチユニットを備えた。ただし、バーテックステクスチャフェッチユニットでサポートするのはMIPマッピングだけで、各種フィルタリングはサポートしない。テクスチャフェッチユニットはL1キャッシュを備え、さらに共有のL2テクスチャキャッシュも備える。
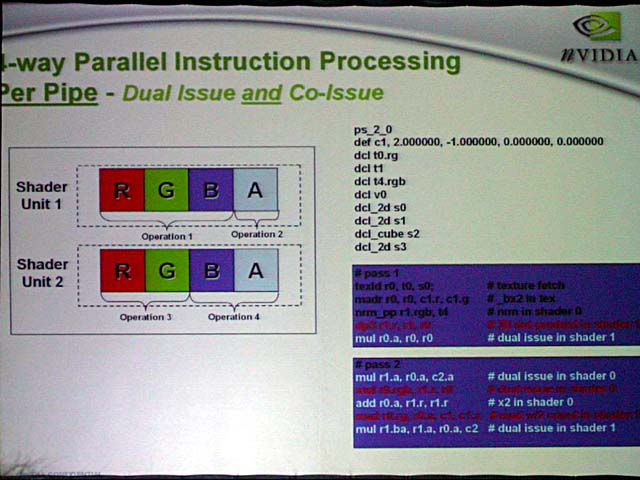
ベクタ演算ユニットはSIMD(Single Instruction, Multiple Data)ではなくMIMD(Multiple Instruction, Multiple Data)で、より柔軟性が高い。また、ベクタとスカラの両ユニットにインストラクションを並列して発行できるデュアルイシューになっている。
面白いのは、これだけリソースを強化したにも関わらずNV40は依然としてテッセレータ(平面分割ユニット:Tessellator)ハードウェアを備えないことだ。ATIやMatrox Graphicsはテッセレータを搭載、頂点データを変位(Displace)させテッセレートすることで、少ない頂点データから複雑な形状を作り出すディスプレイスメントマッピング(Displacement Mapping)が可能になっている。
NV40もディスプレイスメントマッピングをサポートするが、専用ハードのテッセレータを持たないため、パフォーマンスなどは不明だ。ただし、Vertex Shaderにテクスチャユニットが備えられたために、頂点を増やさずに頂点データを変位させるだけのディスプレイスメントマッピングは容易に可能だ。
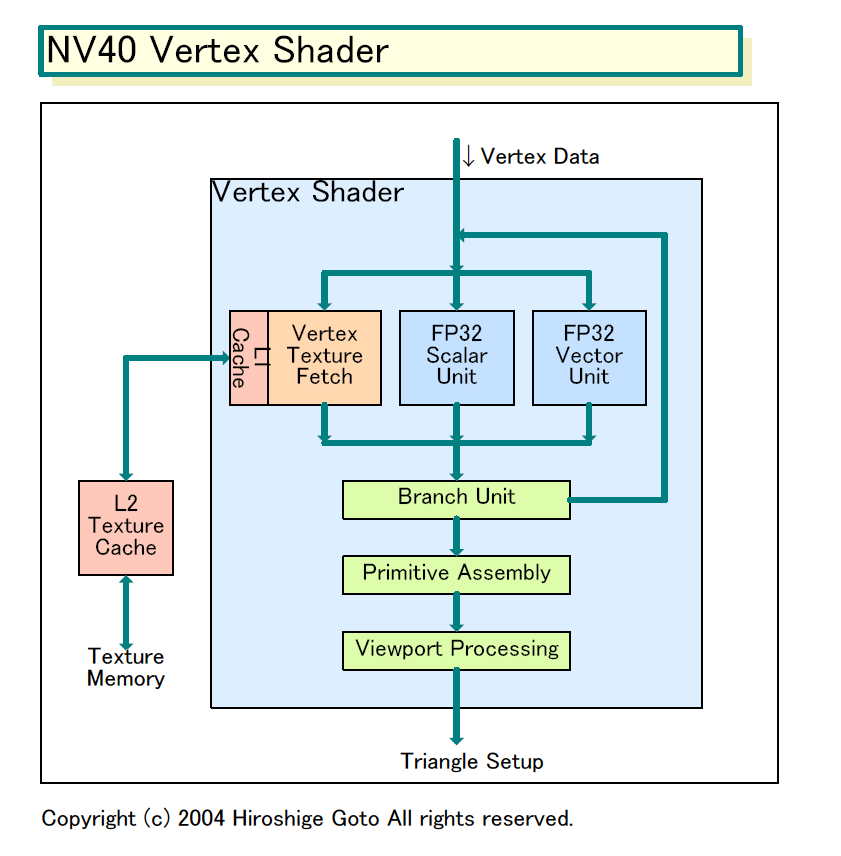 |
| NV40 Vertex Shader図 PDF版はこちら |
 |
 |
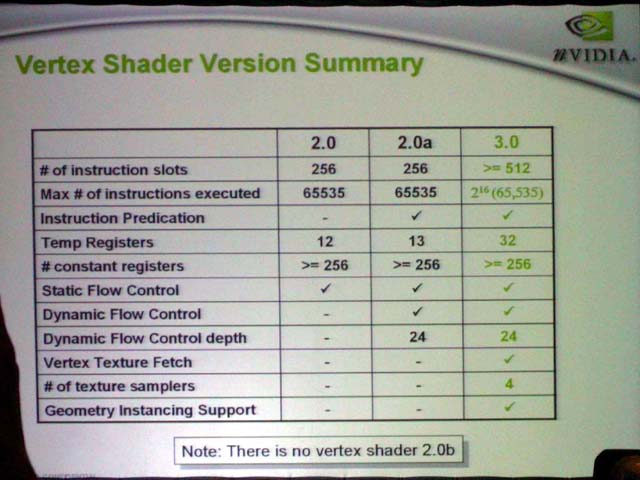 |
| Vertex Shader詳細 | NV40のVertex Shader | Vertex Shaderバージョン比較 |
●Pixel Shader内に演算ユニットを2系統搭載
NV40では、Pixel ShaderとROP(Rasterizing OPeration)サブシステムはいずれもフル機能が16ユニットずつの構成だ。NV30/35系列のようにベース4パイプで、トリッキーに8パイプを主張しているわけではない。NVIDIAは、NV40発表ではこの点を強調。NV40は真の16パイプラインだと宣言した。前回、“偽”8パイプラインと揶揄されたことが、相当こたえたようだ。このコラムで予想した仮想16パイプは誤りだったことになる。
もう少し詳しく説明すると、NV30/35系はカラー+Zの場合は4ピクセル/クロックで、テクスチャ処理は8テクスチャ/クロックの性能だった。また、Zまたはステンシルの場合は8ピクセル/クロックだった。そのため、NV30/35系は4x2(4パイプ2テクスチャ)/8x0アーキテクチャと呼ばれていた。NVIDIAはこの点を自ら指摘、NV40を同様の方法で形容するなら「16x1/32x0」アーキテクチャになると説明した。つまり、1テクスチャユニットを備えたPixel Shaderが16基あるというわけだ。
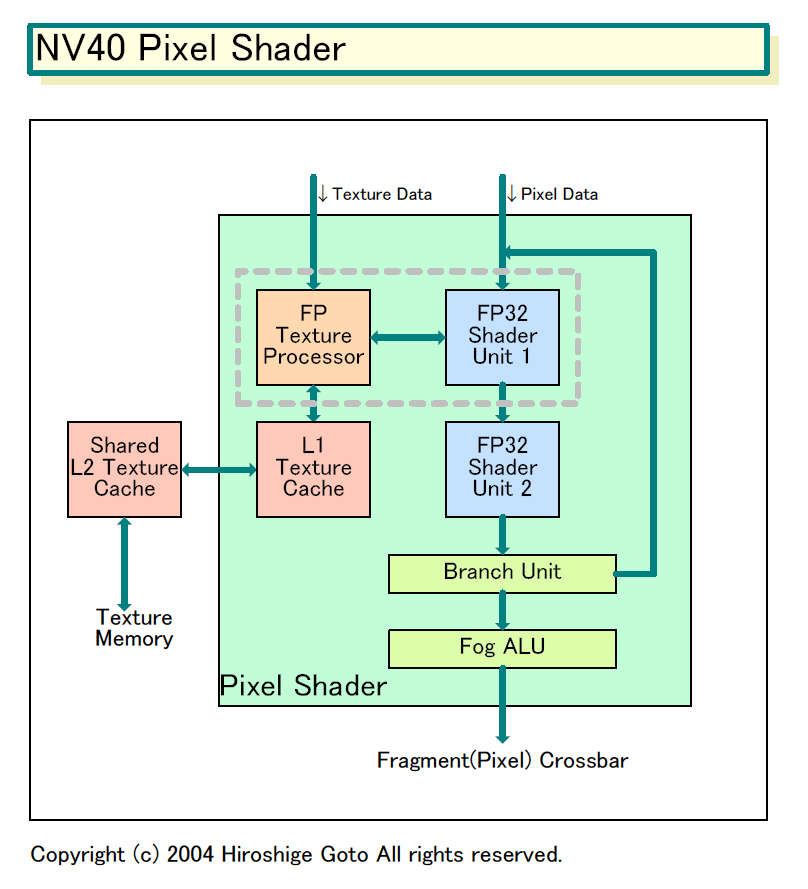
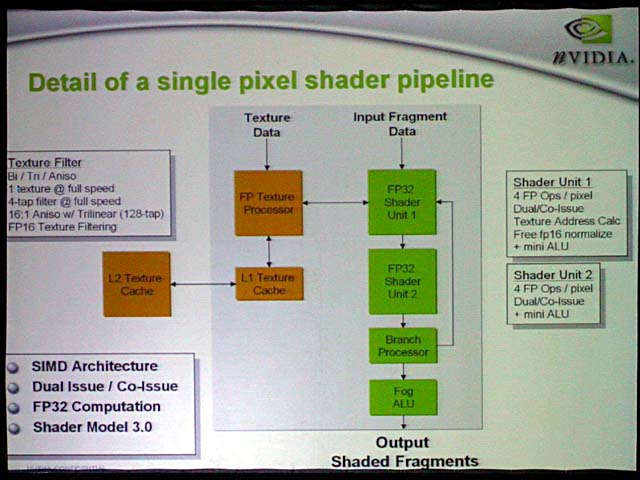
NV40のPixel Shaderは、かなりユニークだ。最大の特徴は、1つのPixel Shader内で4インストラクション/クロックと非常に高い並列度を実現していること。まず、各Pixel Shader内には2つの演算ユニットが備えられている。両ユニットとも32bit浮動小数点データを4wayで扱うことができるSIMD演算ユニットだ。そのため、通常のPixel Shaderと比べると、2倍のオペレーションを1クロックで行なうことができる。
もっとも、これにはじつは多少トリックがある。というのは、下図のShader 1でカラー演算を行なっている時には、テクスチャプロセッシングができないからだ。つまり、現実的にはNV40のPixel Shaderは、テクスチャプロセッシングユニットでカラー演算なども行なえるようにしたと考えた方がよさそうだ。つまり、Pixel Shader内の演算ユニット数は実際には従来のアーキテクチャと同様だが、テクスチャ処理がない場合には他の演算を行なうことができると推定される。
NV30/35系列では、1Pixel Shaderに対して2つのテクスチャユニットを備えていた。2ユニットが並列に動作できるため、テクスチャリッチなシェーダプログラムの場合には利点があった。しかし、これはリソースが無駄になっていることも意味していたわけだ。今回、NVIDIAはこうした演算リソースを有効利用するアーキテクチャを考えてきたようだ。
 |
| NV40 Pixel Shader図 PDF版はこちら |
 |
 |
 |
| Pixel Shader詳細 | NV40のPixel Shader | Pixel Shaderバージョン比較 |
 |
 |
 |
| Centroid Sampling | 旧世代Shaderアーキテクチャ | スーパースカラーShader |
●DirectX 9に最適化して大きく変わったPixel Shader
Shader自体の内部演算精度はNV30同様にFP32(32bit浮動小数点データ、4wayでは128bit SIMD)。FP16(16bit浮動小数点データ)とFP32は、ともに同じユニットで同様に処理するため両データタイプで性能にはほぼ差がないという。
さらにNV40のPixel Shaderは、演算ユニットを2分割できる。DirectX 9では基本的に4wayのSIMDを、3コンポーネント対1コンポーネントに分割して、それぞれに異なるオペレーションを行なうことができる。NV40はさらに2/2の分割も可能にした。そのため、1つのPixel Shader内では、2つのShaderで2インストラクションずつを平行して行なうことができる。つまり、合計で4インストラクション/サイクルの並列処理が可能となっている。NVIDIAは、こうしたアーキテクチャの結果、NV35では12パスかかっていたシェーダプログラムを、NV40では6パスで実行可能だと、サンプルプログラムで説明した。
NVIDIAのGeForce FX(NV3x)シリーズは、これまで、DirectX上では浮動小数点テクスチャを全くサポートしてこなかった。しかし、今回のNV40では浮動小数点テクスチャがサポートされ、FP16(16bit浮動小数点)テクスチャについてはテクスチャフィルタリングもサポートされた(FP32はフィルタリングはなし)。実際には、NVIDIAがNV3xで浮動小数点テクスチャをサポートしなかったのは、ハードウェア自体の制約ではなくドライバソフトウェア側の制約だったが、そこにはサポートできない理由があった(処理が遅い?)と推測されている。しかし、今回のNV40ではNVIDIAは、明確にサポートを打ち出した。
テクスチャユニットはL1キャッシュをShader内に内蔵。さらに、Shader間で共有のL2テクスチャキャッシュを備える。これは、Vertex Shaderがアクセスするキャッシュとも共有になっている可能性がある。
このほか、Shader 3.0でサポートされた動的フローコントロールもサポート。そのためにユニット内にブランチユニットを備えている。
 |
 |
 |
| NV40のDual-IssueとCo-Issueの比較 | Shaderの見本 | サンプルShaderのパフォーマンス |
 |
 |
 |
| Dual-IssueとCo-Issueの4wayインストラクション | ご都合主義のインストラクション実行 | インストラクションプロセスvs計算作業 |
●ラスタオペレーションも16並列が可能
NV40ではラスタオペレーションを行なうROPサブシステムは、Pixel Shaderから分離されている。ROPが16ユニットあるため、NV40ではシェーダパフォーマンスだけでなく、ピクセルアウトプットのパフォーマンスも高い。NVIDIAは、NV35ではシングルテクスチャフィルのピクセル性能は約4(3.99)ピクセル/クロックだったと説明。それがNV40では、12.27ピクセル/クロックと3倍以上に向上したと説明した。
もっともPixel ShaderもROPも16ユニットずつあるのだから、論理的にはピクセル出力は16ピクセル/クロックになっていいはずだが、そうならないのはメモリ帯域の制約のためだという。ピクセルパフォーマンスはメモリ帯域とバランスが取れている必要があるが、NV40では明らかにGPUのピクセルパフォーマンスが得られるメモリ帯域を上回っているわけだ。これは、将来のメモリ帯域の向上を見越した設計なのかもしれない。
ちなみに、NV40ではDDR3メモリをサポート、登場時に1.1Gtps(transfer per second)のメモリ転送レートが実現される。メモリインターフェイスは256bitなので、メモリの生帯域は35.2GB/secとなる。
また、NV40ではMultiple Render Target(MRT)やFP16ベースのフレームバッファもサポートされた。
 |
| NV40 Pixel Engine(ROP)図 PDF版はこちら |
 |
 |
| ラスタオペレーション詳細 | NV40のROPサブシステム |
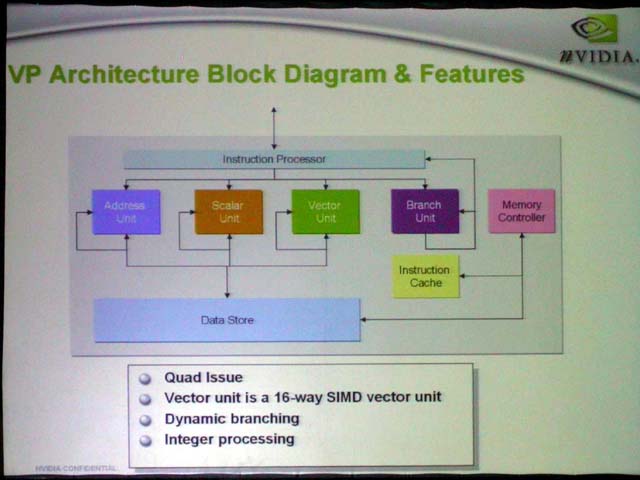
NV40はプログラマブルなビデオプロセッシングユニットも備える。ユニット自体は、クアッドイシューのSIMD+スカラユニットで、これがShaderパイプラインと連携して、ビデオのデコード/エンコードを支援する仕組みとなっている。NVIDIAによると、HD解像度も含むMPEG-2のデコード&エンコード、MPEG-4/DivXのデコード&エンコード、HDを含むWMV9のデコード&エンコードなどがサポートされるという。例えば、MPEG-2エンコードでは、約60%以上の処理をGPU側で行なうことで、CPUオフロードが可能になるという。
 |
 |
 |
| NV4xビデオアーキテクチャ | ビデオプロセッシングユニット | プログラマブルビデオプロセッサの機能 |
 |
 |
| MPEG-2エンコード | MPEG-2デコード |
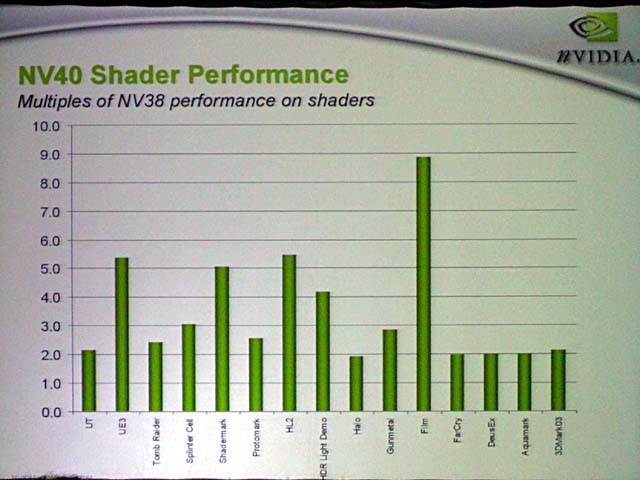
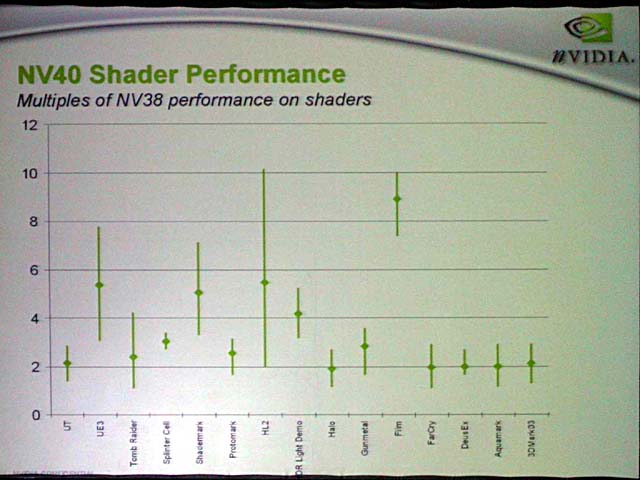
待望のNV40(GeForce 6800)シリーズ発表で、ついに反攻に出るNVIDIA。NVIDIAは、渾身の力を込めたと言うべき今回のNV40には相当自信を持っているようだ。そのため、パフォーマンスも打ち出してきた。NVIDIAは説明会では、社内ラボでのテストで3DMark03で12,000を超えたことを示唆。また、多くのシェーダで、Shader性能がNV38より2~9倍のびたことを説明した。実際、アーキテクチャを考えると、NV38から数倍性能が伸びても不思議ではない。
NV3xファミリで劣勢だった過去1年を取り戻すことが当初の目的となる。しかし、NV40には性能追求の代償として、様々なトレードオフがある。また、ATI Technologiesも、次世代フラッグシップとして「R420」シリーズを開発中で、近いうちに発表することを、昨年10月のアナリストミーティングで明らかにしている。NVIDIAとしては、まだ安心できる状況にはないだろう。
 |
 |
 |
| Shaderのパフォーマンス | ||
 |
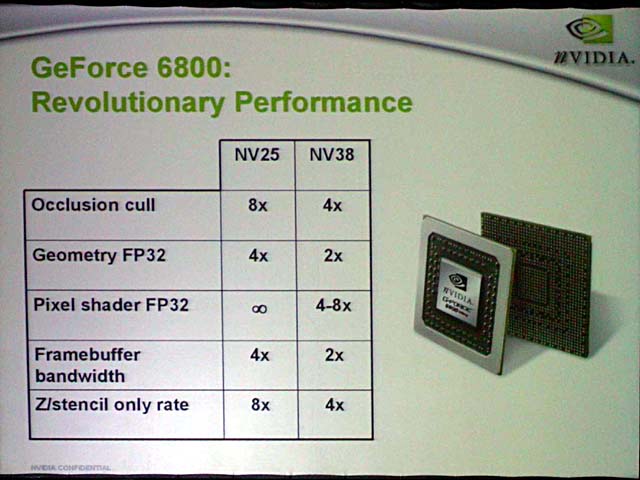 |
| 3DMark03のスコアと思われる数字 | NV25、NV38からの性能向上 |
□関連記事
【2003年10月3日】【海外】NV40は8ピクセル出力/16バーチャルパイプで来年頭に登場
http://pc.watch.impress.co.jp/docs/2003/1003/kaigai029.htm
【2003年5月27日】【海外】CPUをはるかに追い抜くGPUのトランジスタ数
~NV40/R400は2億、NV50/R500は3億クラス?
http://pc.watch.impress.co.jp/docs/2003/0527/kaigai01.htm
(2004年4月15日)
[Reported by 後藤 弘茂(Hiroshige Goto)]
【PC Watchホームページ】
PC Watch編集部 pc-watch-info@impress.co.jp 個別にご回答することはいたしかねます。
Copyright (c) 2004 Impress Corporation All rights reserved.