 |


■後藤弘茂のWeekly海外ニュース■2006年のIntel CPUアーキテクチャは4T+マルチコア |
●2006年のCPUのコードネーム
Intelは、2006年に次々世代モバイルCPU「Merom(メロム)」をデスクトップにももたらす。
現在のところ、このMeromベースデスクトップCPUのコードネームは明確になっていない。というのは、同じ2006年のCPUとして「Merom」「Merom DC」「Conroe」の3つのコードネームの情報が混在しているからだ。Merom DCは当然、MeromのDual Core版の意味で、このことから2006年のデスクトップCPUはデュアルコア(クアッドコアやシングルコアではなく)であることがわかる。
順当に考えればMerom世代のデスクトップCPUは、Merom/Merom DCからConroeに変わった可能性が高いが、まだ確証はない。ただし、2006年にIntelが導入する次世代ソケットの名称が「Socket C」であるらしいことから、現在のコードネームはConroeになっている可能性は非常に高い。ちなみに、mPGA478はSocket-N(Northwood用Socket)、LGA775はSocket-T(Tejas用Socket)と、いずれもCPU名がベースになっている。ただし、Meromベースの前の65nm版Tejasのコードネームは「Cedarmill(シーダミル)」であり、“C”はそこから取られた可能性も捨てきれない。ちなみに、Cedarmillも、当初はTejas Compaction(Tejas-C)と呼ばれていた。
というわけで、現状では2006年CPUの正式なコードネームの確実な情報はない。わかっていることは、デュアルコアで、モバイルCPUと共通アーキテクチャになることだ。では、ConroeまたはMeromデスクトップCPUは、どんなアーキテクチャになるのだろう。
●粒度の小さなμOPsに砕くアーキテクチャ
ここに面白い比較がある。ある情報ソースによると、μOPs(MicroOPs:CPUの内部命令)の帯域、つまりCPUコアが処理できるμOPsの量を比較すると、デスクトップ版Meromと推定される2006年CPUのμOPsピーク処理量は、Tejasより70%ほど多いとIntelは説明しているという。もし、MeromベースCPUの動作周波数がTejasよりやや高い程度で、両コアのμOPs帯域が同周波数のTejasと同程度と考えるなら、デュアルコアで70%増しというのは納得できる数字だ(バスなどがボトルネックになるので100%増にはならない)。ちなみに、Cedarmillとの比較ではMerom世代のμOPs帯域は25%増程度だという。このことからMeromベースのデスクトップCPUの周波数は、前世代のCedarmillより低くなることが予想できる。
IntelがμOPsの処理数で両世代のCPUの性能を比較しているということは、重要なことを示唆している。それは、MeromベースCPUも、NetBurst(Pentium 4系)アーキテクチャと同様に細かなμOPsに砕くアーキテクチャを取るということだ。
これがなぜ重要かというと、Pentium M(Banias/Dothan)系アーキテクチャはできる限りμOPsの数を減らす方向へ向いているからだ。Pentium M系はマイクロオプスフュージョン(Micro-Ops Fusion)やスタック専用マネージャ(Dedicated Stack Manager)などのテクニックで、NetBurstよりもμOPsの数を減らすようにしている。
例えば、Pentium Mでは、メモリアクセスをともなう演算命令を、メモリ操作と演算の2つのオペレーションを含む1個のuOPに変換する。実際に実行ユニットにμOPsを発行する段階で、2つに分解して、実行する。これは、デコードの段階で、メモリ操作uOPと演算uOPの2つに分解してしまう“ロードストア型”のNetBurstとは異なる。BaniasではμOPsの数を減らすことで、内部リソースを節約し、効率化を図っているわけだ。
だが、Intelが、次世代CPUについてもμOPs処理数でNetBurst系CPUと比較しているということは、このCPUも、NetBurstと同様にμOPsに細かく砕くアプローチを取ると見られる。つまり、Banias系ほどはμOPsを積極的に削減するアプローチは取らない可能性が高い。そうすると、NetBurstをベースに、より効率化を図ったアーキテクチャである可能性などが考えられる。ちなみに、現在のBaniasはP6(Pentium Pro/II/III)をベースに、大幅な効率化を図ったアーキテクチャだ。
●2006年にはデスクトップもモバイルも64bitが必須
Merom世代CPUの機能はどうなるのだろう。IntelはNetBurstに4つの拡張テクノロジを加えた。
| HT(Hyper-Threading Technology) | Simultaneous Multithreading:SMT |
| LT(LaGrande Technology) | Hardware based Security |
| VT(Vanderpool Technology) | Hardware based Virtual Machine |
| CT(Clackamas Technology) | 64bit Extension |
この4テクノロジはいずれも現在のPentium M(Banias/Dothan)には実装されていない。では、Merom世代では実装されるのだろうか。答えはおそらくイエスだ。
Meromアーキテクチャがデスクトップとモバイルの両方にまたがるとすれば、4つのTは必ず実装されなければならない。というのいずれもは2006年のCPUの必須要素かそれに近い要素だからだ。
まず、64bit拡張のCT(通称IA-32e)については、Merom世代での必要性は明白だ。それは2006年のMicrosoftのOS「Longhorn(ロングホーン)」が64bitにフル対応するからだ。MicrosoftはLonghornを32bitから64bitへの橋渡しOSと位置づけているらしい。実際、64bit版を32bit版と平行して開発している。そのため、CPU側は2006年には64bit拡張をフルラインナップでイネーブルにする必要がある。モバイルでは実際には64bitアドレッシングはまだ必要がないが、OSの移行を考えると同時期に64bit化を始める必要がある。
ハードウェアセキュリティを実現するLTも同様だ。MicrosoftはLonghornに、ハードウェアベースセキュリティを利用できる「Next-Generation Secure Computing Base (NGSCB)」を実装する。そのため、2006年のCPUには、NGSCBに対応したハードウェアセキュリティ機能が必要になる。LTは必須だ。
仮想マシンに対するハードウェア支援機能VTは、第1段階ではLTと同じハードウェアベースを利用する。そのため、LTの実装はほぼイコールVTの実装を意味する。しかし、IntelはVTには2ステップがあることを説明している。Prescott/Tejasに実装されるのはVT1と呼ばれるファーストステップのVTらしい。そして、Merom世代に実装されるのはVT2と呼ばれる第2世代のVT実装になるようだ。より堅固で柔軟性の高いバーチャルマシンマネージャ(VMM:Virtual Machine Manager)ソフトウェアが可能になると見られる。
●Hyper-Threadingもおそらく実装
IntelのPentium 4は、現在「サイマルテニアスマルチスレッディング(Simultaneous Multithreading:SMT)」技術のHyper-Threadingを実装している。しかし、Merom世代ではCPUはデュアルコアになる。つまり、SMTのように仮想的にCPUコアが複数存在するように見せるのではなく、物理的にCPUコアを2つ備えるのだ。では、IntelはSMTからデュアルコア/マルチコアに移行しようとしているのだろうか。SMTは将来は実装しなくなるのだろうか。おそらくそうではない。
IntelのWilliam M. Siu(ウィリアム・スー)副社長兼事業本部長(Vice President General Manager, Desktop Platforms Group)は、次のように語っている。
「“マルチコア・アンド・マルチスレッディング”は、次の論理的なステップだ。マルチコアなら、2つの同じハードウェアを持つため、性能はさらに上がる」
つまり、IntelはSMT+マルチコアへと進もうとしているのだ。それには2つの理由がある。(1)SMTは実装コストが低い、(2)SMTにはマルチコアと異なる用途がありうる、
out-of-order(アウトオブオーダ)型(の順序を組み替えて実行可能なものから実行する)のマシンでは、SMTの実装のコストは低い。というのは、単一スレッドに対する命令レベルのスケジューリングを、複数スレッドに拡張するだけだからだ。一般に数%程度のトランジスタをout-of-order型CPUに追加すれば、SMTは実現できると言われる。つまり、Intelにとっては、安上がりでおいしい機能拡張なわけだ。また、もし、MeromがNetBurstをベースにしているのなら、SMTは基本設計の段階で実装されていることになる。
現在、IntelはSMTを、OSが割り当てる複数のスレッドの同時実行に使っている。つまり、OS側からはデュアルプロセッサに見えるような使い方をしている。しかし、将来的にはSMTをもっと異なる使い方をする可能性がある。そのひとつは「投機マルチスレッディング(Speculative Multithreading)」だ。
●SMTを投機マルチスレッディングで活用か
2月のIDFで、IntelのPatrick P. Gelsinger(パット・P・ゲルシンガー)CTO兼上級副社長(CTO & Senior Vice President)は、キーノートスピーチで、投機マルチスレッディングの一手法「Speculative Pre-computation(スペキュレイティブプリコンピュテイション)」を静的コンパイリングで実現するデモを行なった。
Speculative Pre-computationでは、投機スレッドを使うことで、メモリのレイテンシを隠蔽する。どういうことかというと、プログラムがデータのロード待ちでストールするのを避けるために、プライマリスレッドとは別なスレッドを生成してしまう。そして、プライマリスレッドと平行して、サブスレッドが先のコードの中のロード命令をどんどん実行してしまう。そうすると、プライマリスレッドがロード命令を実行する時には、L1キャッシュにすでにデータが入っていることになる。つまり、必ずL1データキャッシュにヒットすることになり、L1キャッシュミスがなくなるわけだ。
投機マルチスレッディングがIntelにとって重要なのは、この手法がシングルスレッドアプリケーションの性能を向上させることができるからだ。特に、最大のボトルネックとなるメモリロード待ちを削減できる意味は大きい。アプリケーション側でマルチスレッド化しなくても、CPUまたはランタイムがスレッドを自動生成して性能を上げることが可能になる。そして、この手法を使う場合にはSMTの方が向いている。上の例の場合はSMTでないとキャッシュウォームアップの効果が薄い(マルチコアでL2を共有していればL2はウォームアップできる)。また、こうした投機スレッドには、コンテクストを共有するLightweight threadを使うことも、Intelは示唆している。そうなると、ますますSMTでないと意味がなくなってしまう。
そう考えると、将来のIntel CPUは、OS側からのスレッド割り当てはマルチコアの各CPUコアに対して行ない、SMTはその中での投機スレッド処理などに使う(投機スレッドのハンドルをどのレイヤーで行なうかはともかく)といったことが想定できる。IntelがSMTの実装を捨ててマルチコアだけになるとは思えない。
●マルチコア化のハードルは
マルチコア+SMTへと向かうIntel CPUが抱える大きな問題は2つ。(1)マルチコアCPU上でソフトウェアが性能を引き出せるようにする、(2)マルチコアCPUの相対パフォーマンスをエンドユーザーに理解させる。
ソフトウェアのマルチスレッド化は大きなハードルで、簡単には解決できない。これは、また別な機会にレポートするが、Intelにとって最大の壁となるだろう。
しかし、CPU性能の相対化も、Intelにとって頭の痛い問題だ。シングルコアCPUとデュアルコアCPUの性能の差は、もちろんGHzでは測りようがないからだ。そのために、IntelはProcessor Numberを使うことで、アーキテクチャの異なるCPU同士の性能をGHzで比較できないようにしようとしている。Processor Numberなら、将来のデュアルコアCPUを700番台、シングルコアCPUを500番台、バリューCPUを300番台に据えればそれで差別化ができる。
しかし、そのためにはIntelは中立的なパフォーマンス計測の尺度を設ける必要がある。それはどうするのだろう。
ひとつ想定できるのは、一般的なユーセージモデルでの単位時間当たりの命令実行数で相対化する方法だ。例えば、CPUの内部命令μOPsの処理量で測ることはできるかもしれない。“Giga μOPs”といった単位で示すわけだ。それなら、CPUコア数が増えるとG-μOPsが数十%づつアップするわけで、処理量を比較的正確に反映することができる。冗談のようだが、Intelという企業はそういった主張をしかねないところがある。
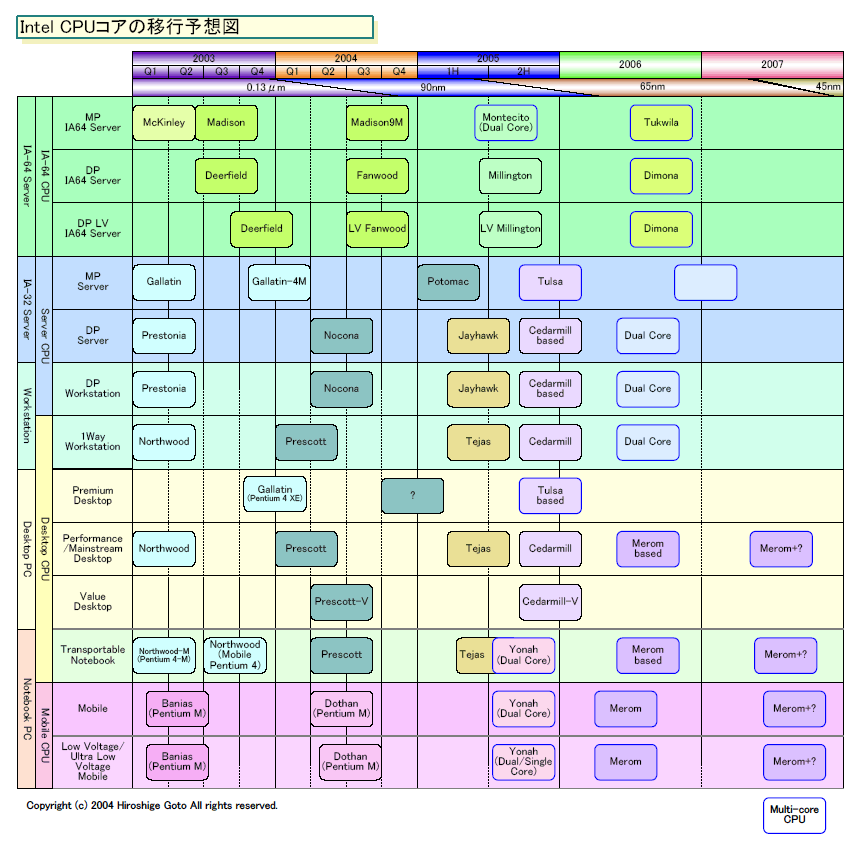 |
| Intel CPUコア移行図 PDF版はこちら |
□関連記事
【3月19日】【海外】Intel、「プロセッサナンバー」の詳細
http://pc.watch.impress.co.jp/docs/2004/0319/kaigai075.htm
【3月12日】【海外】Intelがなぜモデルナンバーを採用するのか
http://pc.watch.impress.co.jp/docs/2004/0312/kaigai073.htm
【2月27日】【海外】Intelの次々世代モバイルCPU「Jonah」はデュアルコアで登場
http://pc.watch.impress.co.jp/docs/2004/0227/kaigai069.htm
(2004年3月24日)
[Reported by 後藤 弘茂(Hiroshige Goto)]
【PC Watchホームページ】
PC Watch編集部 pc-watch-info@impress.co.jp 個別にご回答することはいたしかねます。
Copyright (c) 2004 Impress Corporation All rights reserved.