

|
|
●まだ出ていない製品のコード名が、サーバー向けだけで7個も
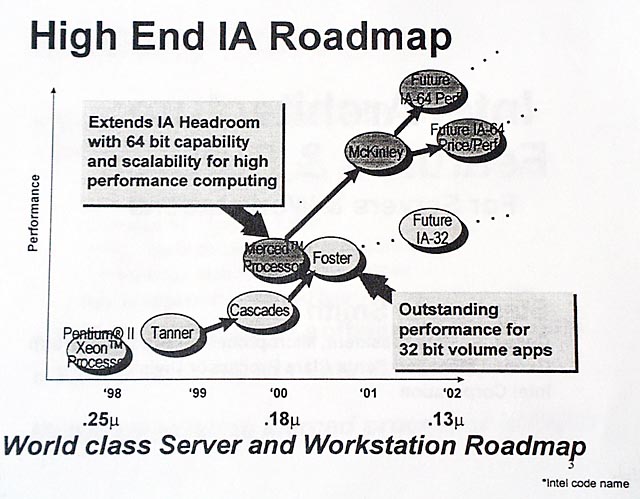
Intelは、サーバー/ワークステーション市場に関して、なんと4年分、MPUの数にして8個のロードマップを、米国サンノゼで開催されている「Microprocessor Forum98」で発表した。コードネームだけで7個が並ぶという“大盤振る舞い”だ。
 |
 |
【最新ハイエンドIAロードマップ】 |
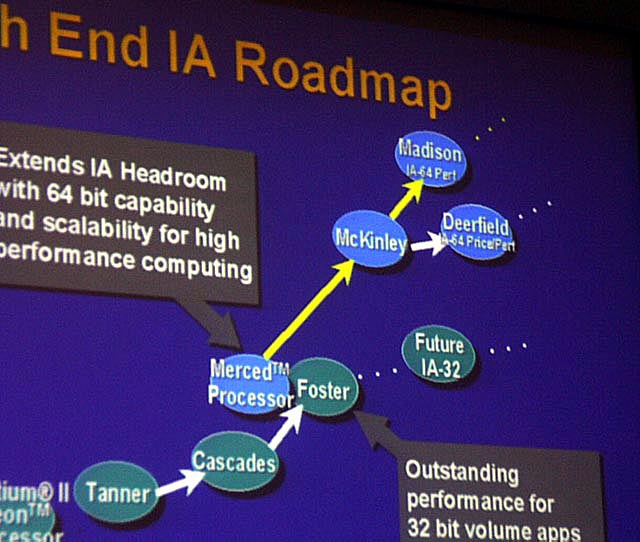
【MADISONとDEERFIELDがロードマップに登場】 |
とりあえず、概要を説明すると、次世代アーキテクチャ「IA-64」系では、「Merced(マーセド:コード名)」の次に「McKinley(マッキンリー:コード名)」が2001年後半に登場する。ここまでは、先月のIntelのカンファレンス「IntelDeveloper Forum (IDF)」で発表済みだが、今回は、新たにMcKinley後継の2つのMPUをロードマップに加えた。ハイパフォーマンス版の「Madison(マディソン:コード名)」と、高プライスパフォーマンス版の「Deerfield(ディアフィールド:コード名)」だ。一方、IA-32では、Pentium II Xeonプロセッサ後継の「Tanner(タナー:コード名)」と「Cascades(カスケイド:コード名)」のあと、「Foster(フォスター:コード名)」が2000年の遅くか2001年初めに登場する。そして、その後にも、Fosterコアでより高性能なMPUが続くという。
これを整理すると下のようになる。
| IA-64 | IA-32 |
| Madison Deerfield | Future IA-32 |
| ↑ ↑ | ↑ |
| McKinle | ↑ |
| ↑ | Foster |
| Merced | ↑ |
| Cascades | |
| ↑ | |
| Tanner | |
| ↑ | |
| Pentium II Xeon |
●1GHz以上で動作するFoster
もう少し詳細に説明すると、FosterはPentium II Xeonと同じIA-32アーキテクチャのMPUだが、まったく新しいMPUコアになり、マイクロアーキテクチャ(内部のインプリメンテーション)が一新される。つまり、PentiumからPentium Pro/II系に代替わりしたのと同じように世代がひとつ変わるわけだ。
パイプラインはより深くなり、Pentium II系よりも高い動作周波数を実現できるようになる。Intelによれば、Fosterは0.18ミクロンの設計ルールで1GHzで登場する見込みで、さらに高速化するという。また、深いパイプラインをカバーするために分岐予測をさらに強化、また命令デコードのトレースキャッシュを新たに備える。
また、サーバーやワークステーションの要求に見合う、かなりサイズの大きな1次キャッシュと2次キャッシュをオンチップで搭載する。つまり、Celeronのように、2次キャッシュを統合したワンチップになる。また、バスの帯域も上げる。フロントサイドバスの帯域は3.2GB/秒になるという。これに見合うのは、128ビット幅のバスを200MHzで駆動した場合などだ。ちなみに、2次キャッシュの帯域は8GB/秒になるという。
●Madisonは0.13ミクロンで製造
一方、Merced後継のMcKinleyも、マイクロアーキテクチャを一新したMPUになる。つまり、Pentium→Pentium IIのように、完全に次の世代のMPUに変わる。
McKinleyでは、Mercedより実行ユニットの数を増やして、同時に実行できる命令数を増やす。そのため、同じ0.18ミクロンで製造した場合でも、Mercedの2倍の性能になるという。これはかなりの性能ジャンプだ。動作周波数は1GHz以上をターゲットにしている。また、Foster同様に、非常にサイズの大きな2次キャッシュをチップに統合するという。MPUの性能向上に合わせて、フロントサイドバスの帯域も拡張する。バスはMercedの3倍の帯域になる。また、Merced同様に、IA-32との互換性は維持する。
McKinleyの次のMadisonは、2002年頃の登場で、0.13ミクロンルールで製造されるという。時期的に見て、おそらくMcKinleyとコアのアーキテクチャは同じになるだろう。Deerfieldは、Madisonの廉価版となる。IA-64は、Merced、McKinleyまではハイエンド市場だけをターゲットにするが、Deerfieldからは、その下のミッドレンジのワークステーションやサーバーも市場に入り始める。つまり、今のXeonが占めている位置にDeerfieldが入ってくることになる。
●MercedとFosterの性能は同じ
さて、ここで興味深いのは、Mercedのパフォーマンスレンジが、Fosterと並んだことだ。これまで、IntelはIA-64でパフォーマンスがブーストすると言っていたが、今回の発表では、IA-32の最高峰FosterとMercedは、同列に並んでしまうことになる。Intelでは、64ビットアドレッシングといったMercedの利点を挙げているが、1年半後には2倍の性能のMcKinleyが登場することを考えると、Mercedの存在価値はゆらいでくる。McKinleyでは、明らかにIA-32との性能差が出るが、Mercedでは出ないとなると、あえてMercedに移行しなければならないという理由は、少なくなる。しかも、32ビットコードでは、おそらくFosterの方が高速になるわけだ。Mercedが有効なのは、64ビットアドレッシングやマッシブマルチプロセッシングが欲しいといったケースに限られてくるだろう。
すでに、多くのメディアが、IA-64の本命はMercedではなくMcKinleyだという報道をしている。今回のパフォーマンスレンジの発表で、Intelも暗にそれを認めた格好となった。Microprocessor Forumで講演を行なった米Intel社のStephen L. Smithコーポレイト副社長兼ジェネラルマネージャ(Santa Clara Processor Division)も、「MercedはIA-64のエントリーポイント」「性能のヘッドルームがある」と微妙な言い方をする。
逆を言えば、Intelが、今回、「4年分のロードマップを公開するのは初めて」(Smith氏)という大盤振る舞いをしたのは、Mercedの遅れと、性能が期待を下回ることが明らかになった状況で、IAアーキテクチャへの期待をつなぐためだと見ることもできる。
●Mercedについても一部が明らかに
 |
 |
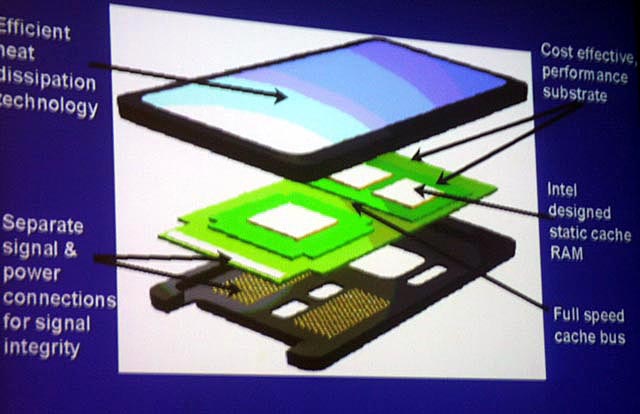
【Mercedのパッケージの実物と図解を公開】 |
【より細かなフロアプランも公開】 |
というわけで、期待が薄らいできたMercedだが、製品開発は一応順調に進んでいるようだ。今回は、Mercedに関しても新たにいくつかのことが明らかにされた。例えば、浮動小数点演算はMercedでは大幅に強化され、1サイクルで単精度浮動小数点演算なら最大8個、倍精度浮動小数点演算なら4個を同時実行できるようになる。
また、IA-32命令の実行のメカニズムの一部明らかにされた。それによると、インストラクションキャッシュにフェッチされた命令は、IA-64命令なら「IA-64Instruction Delivery & Controlユニット」に送られ、IA-32命令なら「IA-32Instruction Delivery & Controlユニット」に送られる。IA-32 InstructionDelivery & Controlユニットは、IA-32命令セットをデコードするだけでなく、Pentium IIが内蔵するようなDynamic Execution(Out-of-Orderで命令を実行させる機構)を備えている。つまり、命令を実行できる順序と組み合わせで、実行ユニットに送り、レジスターをリネーミングし、またリオーダーすることができる。ここで、デコードされたIA-32命令は、IA-64と同じ実行ユニット群に送られる。IA-32専用の実行ユニットは持たない。それによって、最小限のダイサイズでIA-32互換を実現するという。
また、Mercedではキャッシュは3階層構成になる。「L0キャッシュ」とIntelが呼ぶ命令、データに分かれたキャッシュがまずある。従来の1次キャッシュにあたると思われるが、違いは明確にはされなかった。次に、より大きな「1次キャッシュ」が、チップ上に統合される。そして、最後に数MBの2次キャッシュが、チップの外に専用バスで接続される。これは、Xeonと同様にフルスピードのバスになる。
Mercedのシステムバスについても言及があった。Mercedのバスは、Pentium IIと同様にトランザクションタイプのバスになり、もっと多くのトランザクションをできるようになる。MercedがPentium II Xeonよりさらに大規模なマルチプロッサ構成をターゲットにしていることを考えるとこれは当然だろう。
また、Smith氏は、Mercedの設計中のRTLデータを見せて、各機能ブロックの説明も初めて行なった。さらに、Mercedのパッケージの実物も、今回初めて公開した。カートリッジタイプになるが、Slot 2よりやや小さめとなる。
('98年10月16日)
[Reported by 後藤 弘茂]
