
|
|


●分岐予測とメモリレイテンシとスケジューリングがHammerの強化点
AMDは「Microprocessor Forum(MPF) 2001」で、次世代CPU「Hammer(ハマー)」の基本的なアーキテクチャを明らかにした。Hammerは、AMDの64bitアーキテクチャ「x86-64」をインプリメントする。しかし、それ以外にも、マイクロアーキテクチャでAthlonから大きく変わった点が多い。アーキテクチャを見る限り、HammerはAthlonと比べて同じクロックでも性能が大幅に上がる、高IPC(instruction per cycle:1サイクルで実行できる命令数)プロセッサとなりそうだ。
IntelがPentium III→Pentium 4でクロックの向上に焦点を置いたのに対して、AMDはAthlon→HammerでIPCの向上に焦点を置いた。Hammerもクロックは上がるだろうが、Pentium 4ほどではない。アーキテクチャのポイントは、明らかに高効率という点にある。
現在のプロセッサで性能向上の大きな障害になっているのは、パイプラインのストール。そして、パイプラインをストールさせる2大原因は、分岐予測ミスとメモリロード待ちだ。Hammerは、この2つを徹底的に減らすためのアーキテクチャになっている。また、Hammerでは、Athlonと比べてスケジューリング機能も強化された可能性が高い。こうした変化は、Hammerのアーキテクチャを図解するとよくわかる。
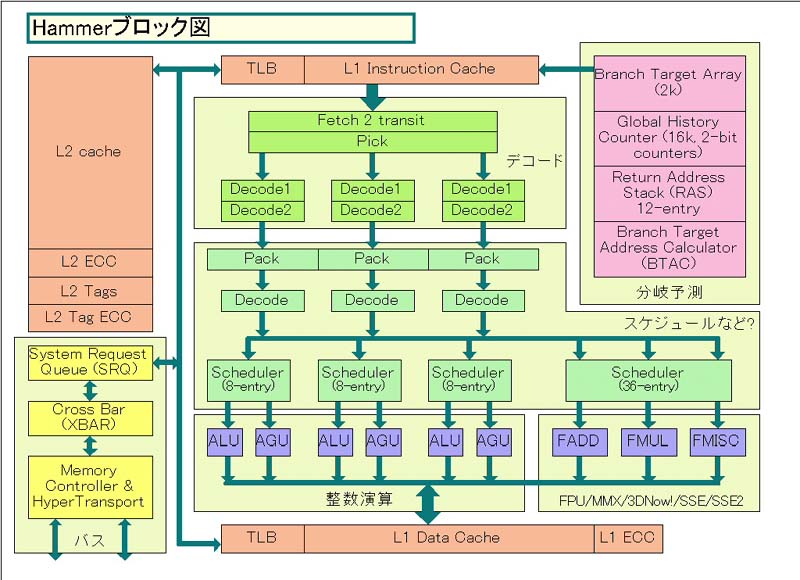
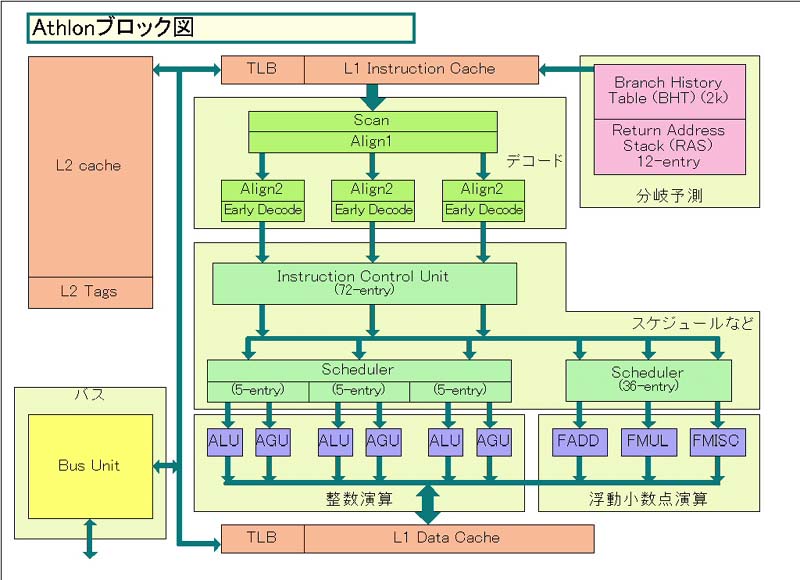
左が「Hammerのブロック図」、右がHammerの図に合わせたスタイルにアレンジした「Athlonのブロック図」だ。これを見ると、基本的な構成はAthlon/Duronと似ているが、変わった点も多いことに気がつく。
 |
 |
| Hammerのブロック図 | Athlonのブロック図 |
●演算ユニットの構成は似ているAthlonとHammer
まず同じ点を先に説明すると。AthlonとHammerは、実行ユニットの構成が似ている。どちらも、実行ユニット群は大きく2つのグループに分かれている。整数演算ユニット群は整数演算を担当するALUとロード/ストアのアドレス生成を担当するAGUが3ペア。浮動小数点演算/マルチメディアユニット群は、役割の異なる3つの演算ユニットで構成される。Schedulerも、浮動小数点演算ユニットは完全に分離しており、この点もAthlonと同じだ。9つの演算ユニットに対して命令の発行ポートは9つで、これも同じ。デコーダがx86命令を最大3命令フェッチ&デコードする点も同じだ。ただし、演算ユニットはすべて64bitに拡張されている。
AMDがデコード命令数と実行ユニット数を増やさなかったのは、おそらくそこにリソースを割いても効果が薄いからだ。まず、x86 CPUの場合、3命令以上をフェッチ&デコードしても、あまり効果的ではないと言われている。ボトルネックは命令フェッチにあるわけではなく、パイプラインハザード(実行パイプラインが停まってしまうこと)にあるからだ。むしろ、3命令フェッチ&デコードの中で効率を上げた方が性能が上がると言われている。
実行ユニットも同じだ。そもそも、Athlonの時点から実行ユニットは非常に多かった。Pentium 4と比べても、ALU、AGU、FPUのそれぞれが1個ずつ多い。そのため、ユニット数をこれ以上増やしても意味は薄いと思われる。
ちなみに、AMDは32bitの演算ユニットの個数をそのままで64bitに拡張した。つまり、64bitの演算器で32bit命令を2個演算するといったアーキテクチャを取らなかった。そうしたアーキテクチャを取るとトランジスタは節約できる。しかし、Hammerはそうしなかった。これは、32bit時にもフルの性能を発揮できるようにするためだという。
●圧倒的に有利なDRAMアクセス
では、HammerとAthlonの違う点は何なのか。
まず、比較してすぐに気がつくのは、Hammerでは図の右上の分岐予測関連の機能が大きく強化されている点だ。単純に、分岐予測のテーブルのサイズだけを見ても、異常な強化ぶりで、Hammerは非常に分岐予測精度が高いと想像される。また、あとで詳しく説明するが、予測精度を上げるだけではなく、分岐予測のアドレスをミスした時のペナルティの低減と、分岐予測できるコードの範囲の拡大をする仕組みも組み込んでいる。
Hammerの次のポイントは左下のバス関連のユニットだ。HammerはここにDRAMコントローラを統合している。そのため、万が一L2キャッシュをミスした場合でも、ペナルティが他のCPUと比べてかなり小さい。これには2つの理由がある。
(1) DRAMアクセスのレイテンシが20サイクルと異常に少ない。
(2) DRAMアクセスがL2キャッシュアクセスとオーバーラップ実行可能で、パイプライン化されている(レイテンシが予測できる)
CPUにDRAMインターフェイスを統合すると、メモリレイテンシは劇的に減少する。これは下のチャートを見るとよくわかる。
◎HammerのDRAMアクセス
・CPUコア
↓
・キュー&クロスバー(CPUと同クロック)
↓
・メモリコントローラ(CPUと同クロック)
↓
・DRAM
◎Athlon/Pentium 4のDRAMアクセス
・CPUコア
↓
・バスユニット(CPUと同クロック)
↓
・FSB(CPUより低速)
↓
・ノースブリッジ(CPUより低速)
バスユニット
↓
・DRAMコントローラ(CPUより低速)
↓
・DRAM
HammerはDRAMアクセスに至るまでのステップが少なく、しかもそれぞれがCPUコアと同クロックで動作しているためトータルのゲートディレイが非常に少ない。それに対して、AthlonやPentium 4では、まず低速のFSB(フロントサイドバス)に同期してそれからCPUより低速なノースブリッジにアクセス、低速なDRAMコントローラでDRAMにアクセスする。つまり、DRAMアクセスまでに必要なステップ数が多い上に、それぞれのユニットのゲートディレイが大きい。そのため、DRAMアクセスのレイテンシは数倍以上になってしまう。
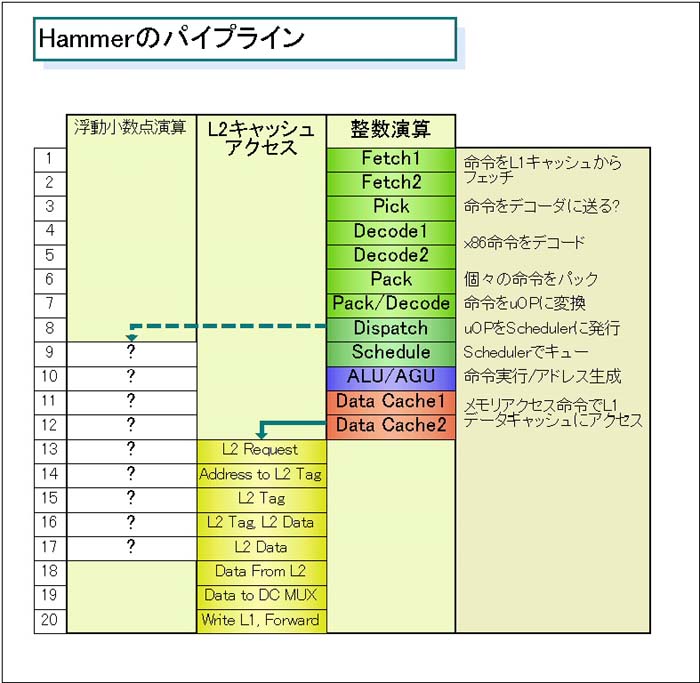
また、HammerはL2キャッシュアクセスとDRAMアクセスをほとんどオーバーラップさせる。MPFでプレゼンテーションをしたAMDのフレッド・ウェバー(Fred Weber)副社長兼CTO(Computation Products Group)によると、エグゼキューションステージから数えて「24サイクル、12nsec(2GHz時)でDRAMからデータを取り出せる」という。DRAMアクセス自体のパイプラインは、プレゼンテーションでは20ステージになっていた。下の「Hammerのパイプライン」から逆算すると、L2アクセスの3ステージ目の“L2 Tag”からオーバーラップすることになる。つまり、L2ミスを待たないでDRAMアクセスが始まることになる。
次回はHammerのパイプラインの詳細について解説する。
 |
| Hammerのパイプライン |
(2001年11月1日)
[Reported by 後藤 弘茂]